论文链接:
https://arxiv.org/pdf/2307.08621.pdf
代码链接:
https://github.com/microsoft/unilm/tree/master/retnet
引言
transformer的问题就是计算成本太高
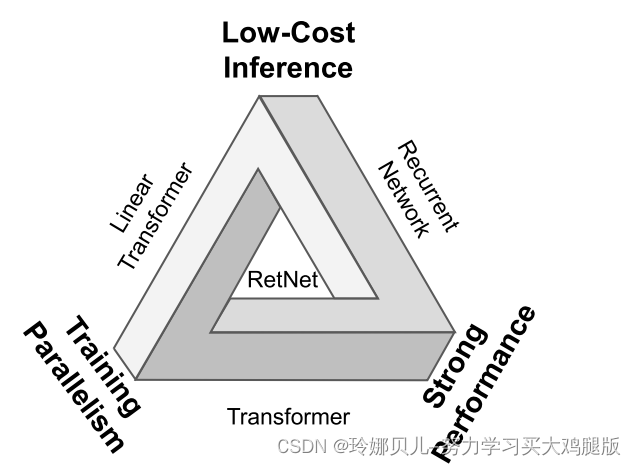
RetNet使“不可能三角形”成为可能,同时实现了训练并行性,良好的性能和低推理成本。
在这项工作中,我们提出了保持网络(RetNet),实现低成本的推理,高效的长序列建模,变压器可比的性能,并行模型训练同时。具体地,我们引入了一个多尺度保留机制来取代多头注意,它有三个计算范式,即,并行、循环和块循环表示。首先,并行表示使训练并行性能够充分利用GPU设备。其次,递归表示在内存和计算方面实现了高效的O(1)推理。可以显著降低部署成本和延迟。此外,实现大大简化,没有键值缓存技巧。第三,分块递归表示可以执行高效的长序列建模。我们并行编码每个局部块以提高计算速度,同时循环编码全局块以保存GPU内存。
我们进行了大量的实验,比较RetNet与Transformer及其变体。在语言建模上的实验结果表明,RetNet在缩放曲线和上下文学习方面具有较强的竞争力。此外,RetNet的推理成本是长度不变的。对于7 B模型和8 k序列长度,RetNet的解码速度比带键值缓存的Transformers快8.4倍,内存节省70%。在训练过程中,RetNet还实现了25-50%的内存节省和7倍的加速比标准的Transformer和一个优势,高度优化的FlashAttention [DFE+22]。此外,RetNet的推理延迟对批处理大小不敏感,允许巨大的吞吐量。这些有趣的特性使RetNet成为Transformer在大型语言模型方面的强有力的继承者。
相关工作
保留网络(RetNet)堆叠有L个相同的块,其遵循类似的布局(即,残余连接和pre-LayerNorm),如Transformer [VSP+17]中所示。每个RetNet块包含两个模块:多尺度保持(MSR)模块和前馈网络(FFN)模块。我们将在以下几节中介绍MSR模块。给定输入序列x = x1 · · · x| X|,RetNet以自回归方式对序列进行编码。输入向量{xi}| X| i=1首先被打包成X 0 = [x1,· · ·,x| X|] ∈ R| X| ×dmodel,其中dmodel是隐藏维度。然后我们计算上下文化向量表示Xl = RetNetl(Xl−1),l ∈ [1,L]。