文章目录
- 一、SQL简介
- 二、数据类型讲解
- 三、创建表和约束
- 1.表结构
- 2. 更新表结构
- 3.约束
- 四、DML语句
- 1.INSERT
- 2.序列号
- 3.UPDATE
- 4.删除语句
- 5.多行插入
- 五、DQL语句
- 1.简单查询语句
- 1.1 知识点讲解
- 1.2 案例讲解
- 2.聚合函数
- 3.分组查询
- 4.多表查询
一、SQL简介
SQL是结构化查询语言(Structured Query Language),专门用于数据存取、数据更新及数据库管理等操作。

在Oracle开发中,客户端把SQL语句发送给服务器,服务器对SQL语句进行编译、执行,把执行的结果返回给客户端。Oracle SQL语句由如下命令组成:
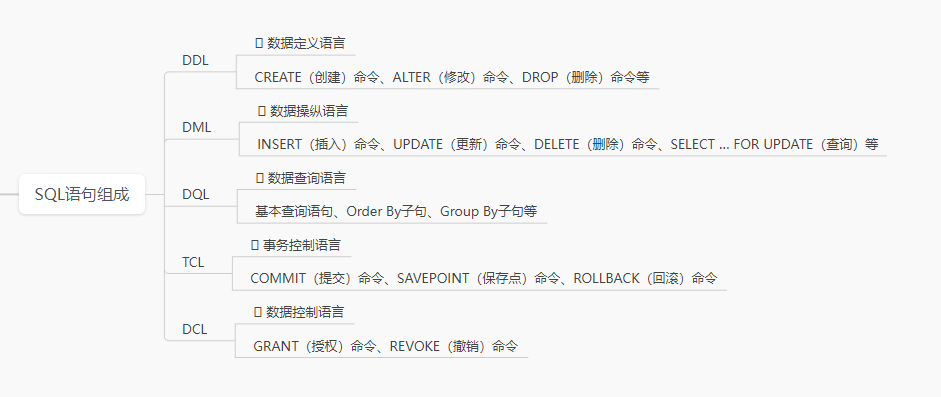
目前主流的数据库产品(比如:SQL Server、Oracle,MySQL)都支持标准的SQL语句。数据定义语言,表的增删改操作,数据的简单查询,事务的提交和回滚,权限的授权和撤销等,Oracle与MySQL在操作上基本一致。
二、数据类型讲解
Oracle数据库的核心是表,表中的列使用到的常见数据类型如下:
| 类型 | 含义 |
|---|---|
| CHAR(length) | 存储固定长度的字符串。参数length指定了长度,如果存储的字符串长度小于length,用空格填充。默认长度是1,最长不超过2000字节。 |
| VARCHAR2(length) | 存储可变长度的字符串。length指定了该字符串的最大长度。默认长度是1,最长不超过4000字符。 |
| NUMBER(p,s) | 既可以存储浮点数,也可以存储整数,p表示数字的最大位数(如果是小数包括整数部分和小数部分和小数点,p默认是38为),s是指小数位数。 |
| DATE | 存储日期和时间,存储纪元、4位年、月、日、时、分、秒,存储时间从公元前4712年1月1日到公元后4712年12月31日。 |
| TIMESTAMP | 不但存储日期的年月日,时分秒,以及秒后6位,同时包含时区。 |
| CLOB | 存储大的文本,比如存储非结构化的XML文档 |
| BLOB | 存储二进制对象,如图形、视频、声音等。 |
对应NUMBER类型的示例:
| 格式 | 输入的数字 | 实际的存储 |
|---|---|---|
| NUMBER | 1234.567 | 1234.567 |
| NUMBER(6,2) | 123.4567 | 123.46 |
| NUMBER(4,2) | 12345.67 | 输入的数字超过了所指定的精度,数据库不能存储 |
对于日期类型,可以使用sysdate内置函数可以获取当前的系统日期和时间,返回DATE类型,用systimestamp函数可以返回当前日期、时间和时区。
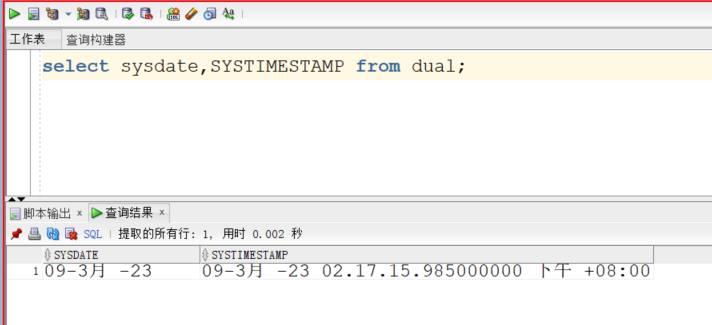
Oracle的查询中,必须使用“select 列… from 表”的完整语法,当查询单行函数的时候,from后面使用DUAL表,dual表在系统中只有一行一列,该表在输出单行函数时为了select…from的语法完整性而使用。
三、创建表和约束
1.表结构
Oracle中的建表的语法
CREATE TABLE 表名(
字段名称 类型 约束,
字段名称 类型 约束,
字段名称 类型 约束
)
在数据库中的不区分大小写
建表和注释的相关案例
-- 创建一张用户表。用来存储用户信息
CREATE TABLE t_student(
id number(5) , -- 学生编号
name varchar2(20) , -- 学生的姓名
age number(2) , -- 学生的年龄
address varchar2(100) -- 学生的地址
); -- SQL语句结束 我们添加一个 英文状态下的 ;
-- 给 table 添加注释:
COMMENT ON TABLE t_student is '学生表'; -- 给表添加注释
COMMENT ON COLUMN t_student.id is '学生编号' ; -- 给表中的字段添加注释
COMMENT ON COLUMN t_student.name is '学生姓名' ;
COMMENT ON COLUMN t_student.age is '年龄' ;
COMMENT ON COLUMN t_student.address is '学生住址';
2. 更新表结构
我们创建一个表结构后可能需要对表做出修改调整
-- 对表结构的操作
-- 1.删除表
DROP TABLE t_student;
CREATE TABLE t_student(
id number(5) , -- 学生编号
name varchar2(20) , -- 学生的姓名
age number(2) , -- 学生的年龄
address varchar2(100) -- 学生的地址
); -- SQL语句结束 我们添加一个 英文状态下的 ;
-- 添加字段
ALTER TABLE t_student ADD gender char(3);
-- 修改字段类型
ALTER TABLE t_student MODIFY gender varchar2(3);
-- 修改字段名称
ALTER TABLE t_student RENAME COLUMN gender to sex;
-- 删除字段
ALTER TABLE t_student DROP COLUMN sex;
3.约束
1.非空约束 该字段的内容不允许为空
DROP TABLE t_student;
CREATE TABLE t_student(
id number(5) , -- 学生编号
name varchar2(20) not null, -- 学生的姓名
age number(2) default 18, -- 学生的年龄
address varchar2(100), -- 学生的地址
gender char(3) default '男'
); -- SQL语句结束 我们添加一个 英文状态下的 ;
2.默认值:如果该列的值为null就会用默认值来填充
DROP TABLE t_student;
CREATE TABLE t_student(
id number(5) , -- 学生编号
name varchar2(20) not null, -- 学生的姓名
age number(2) default 18, -- 学生的年龄
address varchar2(100), -- 学生的地址
gender char(3) default '男'
); -- SQL语句结束 我们添加一个 英文状态下的 ;
3.唯一性约束:有数据的情况下。该列不能出现重复的记录。null 不包括
DROP TABLE t_student;
CREATE TABLE t_student(
id number(5) unique , -- 学生编号
name varchar2(20) not null, -- 学生的姓名
age number(2) default 18, -- 学生的年龄
address varchar2(100), -- 学生的地址
gender char(3) default '男'
); -- SQL语句结束 我们添加一个 英文状态下的 ;
– 非空+唯一约束
DROP TABLE t_student;
CREATE TABLE t_student(
id number(5) unique not null , -- 学生编号
name varchar2(20) not null, -- 学生的姓名
age number(2) default 18, -- 学生的年龄
address varchar2(100), -- 学生的地址
gender char(3) default '男'
); -- SQL语句结束 我们添加一个 英文状态下的 ;
4.主键约束:能够唯一标识该字段的约束 主键修饰的字段是不能重复且不能出现空值的
– 而且一张表中只能出现一个注解【联合主键:一个主键包含多个字段】
DROP TABLE t_student;
CREATE TABLE t_student(
id number(5) primary key , -- 学生编号
name varchar2(20) not null, -- 学生的姓名
age number(2) default 18, -- 学生的年龄
address varchar2(100), -- 学生的地址
gender char(3) default '男'
); -- SQL语句结束 我们添加一个 英文状态下的 ;
– 建表周再添加主键
DROP TABLE t_student;
CREATE TABLE t_student(
id number(5) , -- 学生编号
name varchar2(20) not null, -- 学生的姓名
age number(2) default 18, -- 学生的年龄
address varchar2(100), -- 学生的地址
gender char(3) default '男'
); -- SQL语句结束 我们添加一个 英文状态下的 ;
alter table t_student add constraints pk_student_id primary key(id);
5.外键:表于表之间的关联关系
– 外键:就是在主表中可以重复出现,但是他的值是另一个表的主键,外键使两个表关联
drop table t_class;
create table t_class(
id number(3) primary key,
name varchar2(30)
);
drop table t_student ;
create table t_student(
id number(3) primary key,
name varchar2(30) ,
classid number(3)
);
– 维护外键关联关系
alter table t_student add constraints fk_student_classid foreign key(classid) references t_class(id);
6.check约束:在字段类型的基础上。更进一步的提升数据的精度
DROP TABLE t_student;
CREATE TABLE t_student(
id number(5) unique not null , -- 学生编号
name varchar2(20) not null, -- 学生的姓名
--age number(2) check(age > 1 and age < 25), -- 学生的年龄
age number(2) check(age between 1 and 25), -- 学生的年龄
address varchar2(100), -- 学生的地址
gender char(3) check (gender in ('男','女'))
); -- SQL语句结束 我们添加一个 英文状态下的 ;
四、DML语句
DML数据操作语言:通过SQL来实现数据的插入、修改和删除操作,在Oracle中常用的数据操作语音有
- INSERT
- UPDATE
- DELETE
- SELECT … FOR UPDATE
1.INSERT
数据插入语句
INSERT INTO 表名(fieldName1,fieldName1,...fieldNameN)values(value1,value2,...,valueN)
-- 案例
insert into t_class(id,name)values(1,'计算机');
简略的语法:如果我们插入的记录需要给表中的每一个字段都添加信息。那么我们可以省略 字段列表,但是后面的值列表必须和表结构中的字段顺序保持一致
INSERT INTO 表名 values(value1,value2,...,valueN)
INSERT INTO t_class values(2,'计算机');
-- 下面是错误示范
INSERT INTO t_class values('英语',3);
2.序列号
主键:我们插入数据的时候就需要保证他的唯一性
- Orlace中提供的序列号的方案来解决
- MySQL中提供了主键自增的方案
- 在分布式环境下。我们可以通过分布式ID来解决
序列号的语法:
CREATE SEQUENCE 序列名称
[INCREMENT BY] -- 每次自增的数量
[START WITH 1] -- 从1开始计数
[NOMAXVALUE] -- 不设置最大值
[NOCYCLE] -- 一直累加,不循环
CACHE 10; -- 缓存10
案例应用
create sequence s_class; -- 从1开始 每次增长1个
-- currval是在执行了nextval之后才会生效
select s_class.currval from dual;
select s_class.nextval from dual;
插入语句的应用
INSERT INTO t_class values(s_class.nextval,'计算机');
3.UPDATE
需要对已经插入到表结构中的数据做出调整。对应的语法结构
UPDATE 表名 SET field1=value1,field2=value2 ... [where 条件]
update t_class set name = '软件' ;
update t_class set name = '计算机1班' where id = 15;
-- 更新id为18 19 21的记录为 '计算机2班'
update t_class set name = '计算机2班' where id = 18 or id=19 or id=21 ;
update t_class set name = '计算机3班' where id in (14,16,17) ;
update t_class set name = '英语1班' where id >= 100 and id <=200 ;
update t_class set name = '英语2班' where id between 100 and 130 ;
update t_class set name = 'test' where id != 24 ;
update t_class set name = 'test666' where id <> 22 ;
4.删除语句
DELETE FROM 表名 [where 条件]
delete from t_class where id = 17;
-- 对于null的查询我们是用 is null 来匹配的
delete from t_class where name is null;
-- delete 删除会做数据的缓存
delete from t_class ; -- 会删除表中的所有的数据。 删库跑路 要小心使用
-- 删除全表的数据,直接删除数据。不做缓存处理。 效率高。风险大
truncate table t_class ;
5.多行插入
-- 多行插入
insert into t_class_copy(id,name)
select id,name from t_class
select * from t_class_copy1
-- 复制表
create table t_class_copy as select * from t_class where 1 != 1;
-- 复制表 带有数据的情况
create table t_class_copy1 as select * from t_class ;
五、DQL语句
DQL:数据查询语言。
查询语句的语法结构
--语法结构
SELECT <列名>
FROM <表名>
[WHERE <查询条件> ]
[ORDER BY <排序的列名>[ASC或者DESC] ]
[GROUP BY <分组字段> ]
1.简单查询语句
1.1 知识点讲解
全表查询中的内容:
create sequence s_student;
insert into t_student(id,name,age,address,gender)values(s_student.nextval,'王五',18,'湖南长沙','女') ;
-- 1.查询学生表的所有信息 * 表示查询表中的所有的列
select * from t_student;
-- 2.查询特定的列
select id,name,age from t_student;
-- 3.查询信息使用别名来标识,别名不能用' 我们得使用 "
select
id as "学生编号",
name as "学生姓名",
age as "学生年龄"
from t_student;
-- 我们可以省略 ""
select
id as 学生编号,
name as 学生姓名,
age as 学生年龄
from t_student;
-- 我们还可以省略 as 关键字
select
id 学生编号,
name 学生姓名,
age 学生年龄
from t_student;
-- 如果别名中有特殊符号的情况。那么不能省略""
select
id "【学生编号】",
name as 学生姓名,
age as 学生年龄
from t_student;
-- 4.常量的处理
select id,name,age ,29 体重 from t_student
-- 5.查询学生信息。 id 和 name 拼接起来 ||
select id,name,age , '【'||id||'-'||'name'||'】' 组合 from t_student
带条件的查询:
drop table t_student ;
create table t_student(
id number(3) primary key,
name varchar2(30) ,
gender char(3) ,
age number(2),
class_id number(5)
)
Insert into DPB.T_STUDENT (ID,NAME,GENDER,AGE,CLASS_ID) values (1,'张三','男 ',18,1001);
Insert into DPB.T_STUDENT (ID,NAME,GENDER,AGE,CLASS_ID) values (2,'李四','女 ',22,1002);
Insert into DPB.T_STUDENT (ID,NAME,GENDER,AGE,CLASS_ID) values (3,'小明','男 ',35,1003);
Insert into DPB.T_STUDENT (ID,NAME,GENDER,AGE,CLASS_ID) values (4,'小花','女 ',16,1001);
Insert into DPB.T_STUDENT (ID,NAME,GENDER,AGE,CLASS_ID) values (5,'张三疯','男 ',18,1001);
Insert into DPB.T_STUDENT (ID,NAME,GENDER,AGE,CLASS_ID) values (6,'王张妮','女 ',25,1002);
-- 6.查询出年龄在18到25之间的学生
select *
from t_student
where age >= 18 and age <= 25
select * from t_student where age between 18 and 25;
-- 7.查询出班级编号为1001或者1002的学生信息
select * from t_student where t_student.class_id = 1001 or t_student.class_id = 1002
select * from t_student t where t.class_id = 1001 or t.class_id = 1002
select * from t_student t where t.class_id in (1001,1002)
-- 8.查询出不在班级编号为1001和1002的学生信息
select * from t_student where class_id not in (1001,1002) or class_id is null
-- 9.查询出所有姓张的学员的信息 模糊查询: like
select * from t_student where name like '张%'
select * from t_student where name like '%张%'
-- 10.查询所有姓张的学生信息。并且名字又两个字组成
select * from t_student where name like '张_'
-- 11.查询所有的学生信息。按照年龄升序排列 asc 升序 可以省略
select * from t_student;
select * from t_student order by age ;
select * from t_student order by age desc;
-- 11.查询所有的学生信息。按照班级升序。如果班级相同则按照年龄降序
select * from t_student order by class_id , age desc
-- 12.查询学生表中的所有的班级编号 distinct 关键字可以帮助我们去掉重复的记录。
-- 如果后面有多个列。去掉的是多个列组合中相同的记录
select distinct class_id,age from t_student
1.2 案例讲解
SQL练习讲解:
表结构
Emp----员工信息表
Ename varchar2(30), --姓名
Empno number(5), --编号
Deptno number(5), --所在部门
Job varchar2(20), --工种(人员类别),如:manager 经理,clerk 办事员
Hiredate Date, --雇佣日期
Comm number(6,2), --佣金
Sal number(6,2) --薪金
Mgr number(5) --员工上司编号
Dept-----部门表
Dname varchar2(30), --部门名
Deptno number(5), --部门号
Loc varchar2(50) --位置
准备数据:
create table emp --–创建员工信息表
(
Ename varchar2(30), --姓名
Empno number(5), --编号
Deptno number(5), --所在部门
Job varchar2(20), --工种(人员类别),如:manager 经理,clerk 办事员
Hiredate Date, --雇佣日期
Comm number(7,2), --佣金
Sal number(7,2) , --薪金
Mgr number(5) --编号
);
insert into EMP (ENAME, EMPNO, DEPTNO, JOB, HIREDATE, COMM, SAL, MGR)
values ('张三', 1, 10, '办事员', null, 500, 2000, null);
insert into EMP (ENAME, EMPNO, DEPTNO, JOB, HIREDATE, COMM, SAL, MGR)
values ('李四', 2, 10, '办事员', null, 650, 2333, null);
insert into EMP (ENAME, EMPNO, DEPTNO, JOB, HIREDATE, COMM, SAL, MGR)
values ('王五', 3, 20, '办事员', null, 1650, 1221, null);
insert into EMP (ENAME, EMPNO, DEPTNO, JOB, HIREDATE, COMM, SAL, MGR)
values ('小张', 4, 20, '经理', null, 980, 3200, null);
insert into EMP (ENAME, EMPNO, DEPTNO, JOB, HIREDATE, COMM, SAL, MGR)
values ('小刘', 5, 10, '办事员', null, 500, 2000, null);
commit;
create table dept --部门表
(
Dname varchar2(30), --部门名
Deptno number(5), --部门号
Loc varchar2(50) -- 部门位置
);
insert into DEPT (DNAME, DEPTNO, LOC)
values ('市场部', 10, '大连');
insert into DEPT (DNAME, DEPTNO, LOC)
values ('研发部', 20, '沈阳');
insert into DEPT (DNAME, DEPTNO, LOC)
values ('人事部', 30, '深圳');
insert into DEPT (DNAME, DEPTNO, LOC)
values ('人事部', 40, '广州');
commit;
2.聚合函数
聚合函数的作用:解决我们对于数据的统计的需求
-- 聚合函数和分组函数
-- 1.统计学生的人数 count(字段名称) 统计该列中数据不为空的记录条数
select count(*),count(name),count(gender),count(age),count(1)
from t_student ;
-- count(*) 和 count(1) 的区别
select t_student.*,1
from t_student ;
-- 2.其他常用的统计函数
select count(1),max(age),min(age),sum(age),round(avg(age))
from t_student ;
3.分组查询
分组函数 group by
-- 1> 不和聚合函数一块使用,作用和distinct是一样。可以去掉重复的记录
select * from emp ;
select deptno from emp group by deptno ;
select distinct deptno from emp;
select deptno,job
from emp
group by deptno , job
order by deptno;
-- 2>和聚合函数一块使用的场景,聚合函数统计的数据就不是查询的所有的数据了。而是分组后的数据
-- 分组后的数据中我们不能直接出现非分组的字段
-- a.统计出学生表中男生和女生的人数
select gender,count(1) from t_student group by gender;
-- b.统计出学生表中每个班级的人数
select class_id,count(1) from t_student t group by t.class_id;
-- c.统计出学生表中每个班级中的男生和女生人数 聚合函数统计的是分组后的最小单位的数据
select class_id,gender,count(1) from t_student group by class_id ,gender ;
-- d.统计出学生表中年龄大于18的男生和女生的人数
select gender,count(1)
from t_student
where age > 18 -- where 的位置,必须是要在group by 之前。作用呢是筛选要分组的数据
group by gender
-- e.统计出学习表中年龄大于18的班级人数大于1的记录
select class_id,count(1)
from t_student
where age > 18
group by class_id
having count(1) > 1 -- 在group by 之后。和group by 配合使用。作用是过滤分组后的数据
4.多表查询
Oracle和MySQL都是关系型数据库。【关系】指的就是表和表之间的数据是有关联关系的。
多表查询
-- 1.交叉连接:获取两张表的笛卡尔乘积
select * from t_class ;
select * from t_student;
-- 查询出学生信息和对应的班级信息
select t1.*,t2.*
from t_student t1,t_class t2
-- 等值连接:在交叉连接的基础上添加过滤条件
select t1.*,t2.*
from t_student t1,t_class t2 -- 1000 * 1000 = 100W
where t1.class_id = t2.id -- where 关键是在结果集之后做的条件筛选
-- 内连接:左边表结构中的记录和右边表结构中的记录连接的时候会根据on中的条件判断。如果满足就获取。否则都丢失
select t1.*,t2.*
from t_student t1
inner join t_class t2
on t1.class_id = t2.id
-- 查询出学生表中的所有的记录。同时显示学生对应的班级名称
select t1.*,t2.*
from t_student t1
inner join t_class t2
on t1.class_id = t2.id
-- 左连接:在内连接的基础上。保留左侧不满足条件的数据
select t1.*,t2.*
from t_student t1 left outer join t_class t2
on t1.class_id = t2.id
-- 右连接:在内连接的基础上。保留右侧不满足条件的数据
-- 查询所有的班级信息。同时查询相关的学生信息
select t2.*,t1.*
from t_student t1 right outer join t_class t2
on t1.class_id = t2.id
-- 全连接:在内连接的基础上保留左右两侧不满足条件的数据
select t1.*,t2.*
from t_student t1 full join t_class t2
on t1.class_id = t2.id
-- union union all 合并结果集
select t1.*,t2.*
from t_student t1 left outer join t_class t2
on t1.class_id = t2.id
union -- 合并结果集。会去掉重复的记录 和 全连接差不多
select t1.*,t2.*
from t_student t1 right outer join t_class t2
on t1.class_id = t2.id
select t1.*,t2.*
from t_student t1 left outer join t_class t2
on t1.class_id = t2.id
union all -- 合并结果集。不会去掉重复的记录
select t1.*,t2.*
from t_student t1 right outer join t_class t2
on t1.class_id = t2.id