我们最近听到越来越多的关于Cloudflare的服务。
我对Clouflare D1特别感兴趣,所以我决定研究一下。
与这次我想使用的 Remix 一起,我想介绍 Remix + Cloudflare Pages + D1 的第一步。
我只是稍微地了解一下,但我所做的在下面的仓库中: https://github.com/creamstew/remix-cloudflare-pages-d1
文章目录
- 准备
- 创建 Remix 项目
- 创建 Cloudflare D1 绑定
- 查询执行
- 在 Remix 中查看数据
- 与 Cloudflare Pages 集成
准备
您需要先做两件事:
- 获取 Cloudflare帐户
- 安装Wrangler,一种Cloudflare Workers CLI工具
创建 Remix 项目
使用以下命令创建项目:
npx create-remix@latest
输入项目名称后,系统会提示您选择部署方法。选择Cloudflare Pages!
$ cd <YOUR_PROJECT>
npm run dev
当您访问 http://127.0.0.1:8788 时,将出现以下屏幕。

创建 Cloudflare D1 绑定
为 D1 创建数据库很容易。
wrangler d1 create <DATABASE_NAME>
就是这样。 现在,您有一个本地 D1 数据库。
创建数据库时,应会看到以下配置已添加到辅助角色的配置文件 wrangler.toml:
[[ d1_databases ]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "<DATABASE_NAME>"
database_id = "<UUID>"
此设置允许 D1 数据库绑定到辅助角色。文档: https://developers.cloudflare.com/workers/platform/bindings/
查询执行
创建数据库后,可以创建一些表和数据了。
直接在 Remix 项目下创建一个名为 schema.sql 的文件。
DROP TABLE IF EXISTS Customers;
CREATE TABLE Customers (CustomerID INT, CompanyName TEXT, ContactName TEXT, PRIMARY KEY (`CustomerID`));
INSERT INTO Customers (CustomerID, CompanyName, ContactName) VALUES (1, 'Alfreds Futterkiste', 'Maria Anders'), (4, 'Around the Horn', 'Thomas Hardy'), (11, 'Bs Beverages', 'Victoria Ashworth'), (13, 'Bs Beverages', 'Random Name');
运行在本地创建的 SQL 文件。
wrangler d1 execute <DATABASE_NAME> --local --file=./schema.sql
如果执行正确,抛出如下所示的 SELECT 语句,结果将被返回。
wrangler d1 execute <DATABASE_NAME> --local --command='SELECT * FROM Customers'
┌────────────┬─────────────────────┬───────────────────┐
│ CustomerID │ CompanyName │ ContactName │
├────────────┼─────────────────────┼───────────────────┤
│ 1 │ Alfreds Futterkiste │ Maria Anders │
├────────────┼─────────────────────┼───────────────────┤
│ 4 │ Around the Horn │ Thomas Hardy │
├────────────┼─────────────────────┼───────────────────┤
│ 11 │ Bs Beverages │ Victoria Ashworth │
├────────────┼─────────────────────┼───────────────────┤
│ 13 │ Bs Beverages │ Random Name │
└────────────┴─────────────────────┴───────────────────┘
在 Remix 中查看数据
现在您已经验证了查询可以执行,让我们访问 Remix 中的 D1 以查看检索到的数据。
首先,重写一些 package.json 设置。
wrangler pages dev ./public
---
wrangler pages dev ./public --local --persist
持久选项将数据保存到 .wrangler/state 子目录。
接下来,编辑 routes/_index.tsx 文件。
在更改之前,它应该看起来像这样。
import type { V2_MetaFunction } from "@remix-run/react";
export const meta: V2_MetaFunction = () => {
return [{ title: "New Remix App" }];
};
export default function Index() {
return (
<div style={{ fontFamily: "system-ui, sans-serif", lineHeight: "1.4" }}>
<h1>Welcome to Remix</h1>
<ul>
<li>
<a
target="_blank"
href="https://remix.run/tutorials/blog"
rel="noreferrer"
>
15m Quickstart Blog Tutorial
</a>
</li>
<li>
<a
target="_blank"
href="https://remix.run/tutorials/jokes"
rel="noreferrer"
>
Deep Dive Jokes App Tutorial
</a>
</li>
<li>
<a target="_blank" href="https://remix.run/docs" rel="noreferrer">
Remix Docs
</a>
</li>
</ul>
</div>
);
}
按如下方式编辑此文件:
import type { LoaderArgs } from "@remix-run/cloudflare";
import { json } from "@remix-run/cloudflare";
import { useLoaderData } from "@remix-run/react";
type Customer = {
CustomerID: number;
CompanyName: string;
ContactName: string;
};
export const loader = async ({ context }: LoaderArgs) => {
const db = context.DB as D1Database;
const { results } = await db
.prepare("SELECT * FROM Customers")
.all<Customer>();
return json({
customers: results ?? [],
});
};
export default function Index() {
const { customers } = useLoaderData<typeof loader>();
return (
<div style={{ fontFamily: "system-ui, sans-serif", lineHeight: "1.4" }}>
<h1>Welcome to Remix</h1>
<ul>
{customers.map((customer) => (
<li key={customer.CustomerID}>
{customer.CompanyName}, {customer.ContactName}
</li>
))}
</ul>
</div>
);
}
编辑后
npm run dev
如果您再次访问 http://127.0.0.1:8788,将出现以下屏幕。

您应该能够确认可以检索和显示 D1 的数据。
让我们快速浏览一下编辑后的代码。
type Customer = {
CustomerID: number;
CompanyName: string;
ContactName: string;
};
表示通过运行 SQL 创建的表的内容。
export const loader = async ({ context }: LoaderArgs) => {
const db = context.DB as D1Database;
const { results } = await db
.prepare("SELECT * FROM Customers")
.all<Customer>();
return json({
customers: results ?? [],
});
};
加载程序使用绑定。
[[ d1_databases ]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "${DATABASE_NAME}"
database_id = "${DATABASE_ID}"
正在直接访问数据库。
剩下的就是在SQL中获取数据并使用MAP扩展它!
本地的第一步到此结束。
与 Cloudflare Pages 集成
我也想轻描淡写地谈一谈这个问题。
请参阅下文,了解如何部署到 Cloudflare 页面: https://developers.cloudflare.com/pages/framework-guides/deploy-a-remix-site/
您所做的很简单,并播放您之前在生产环境中本地播放的 SQL。
wrangler d1 execute <DATABASE_NAME> --file=./schema.sql
确保可以将 SQL 流式传输到生产环境。
wrangler d1 execute <DATABASE_NAME> --command='SELECT * FROM Customers'
验证后,打开 Cloudflare 页面>设置>函数,选择在变量名称 DB 中创建的数据库,绑定完成。
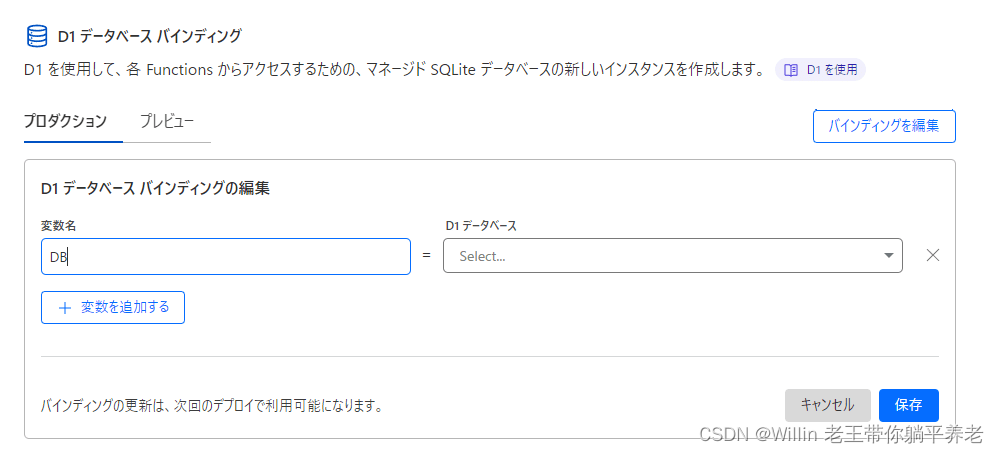
您现在应该也可以在Cloudflare Pages中看到D1的数据。