进程创建,进程终止
- 1.进程创建
- 1.1写时拷贝
- 1.2fork常规用法
- 1.3fork调用失败的原因
- 2.进程终止
- 2.1退出码
- 2.2进程退出场景
- 2.3进程如何退出
1.进程创建
在前面创建子进程的时候就学过了fork函数,它能从已经存在进程中创建一个新进程,新进程为子进程,而原进程为父进程。
当进程调用fork,当控制转移到内核中的fork代码后,内核做:
分配新的内存块和内核数据结构给子进程
将父进程部分数据结构内容拷贝至子进程
添加子进程到系统进程列表当中
fork返回,开始调度器调度
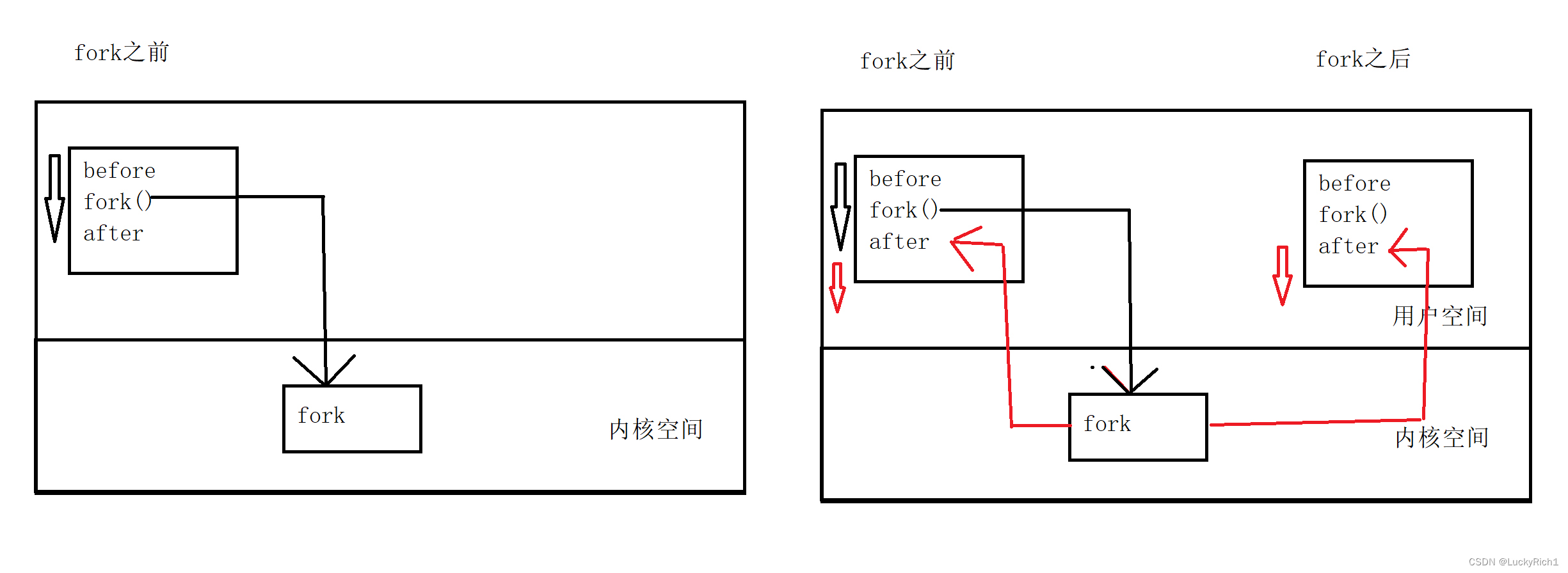 fork之前父进程独立执行,fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定。
fork之前父进程独立执行,fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定。
1.1写时拷贝
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。具体见下图
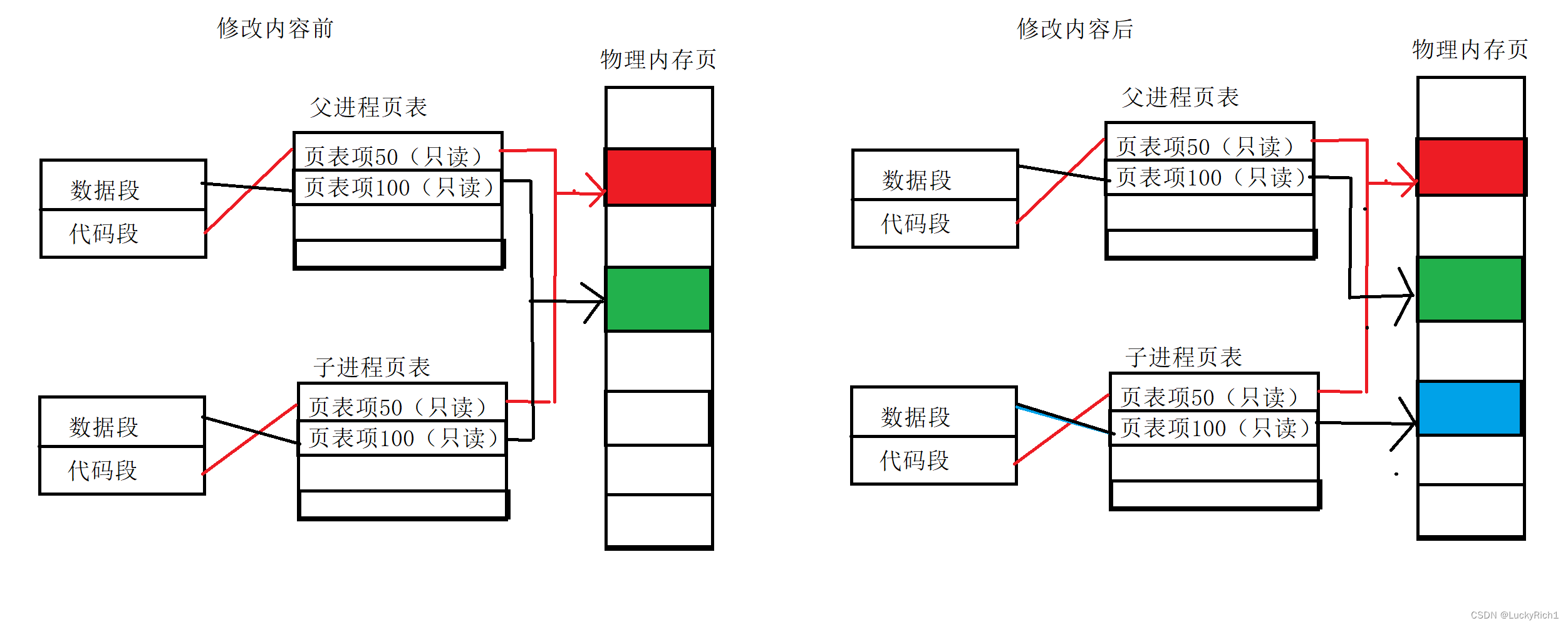
写时拷贝在进程地址空间详细讲述了,这里不再细说。
这里主要讲解fork返回值的问题。
1.如何理解fork返回之后,给父进程返回子进程的pid,给子进程返回0。
父亲:孩子-----> 1:n的关系。
一个父亲有一个或者n个孩子,如果想找到某个孩子,必须知道孩子的名字。
孩子有且只有以恶搞父亲,想要找父亲的时候,有操作系统提供的getppid()。
2.如何理解fork函数有两个返回值问题。
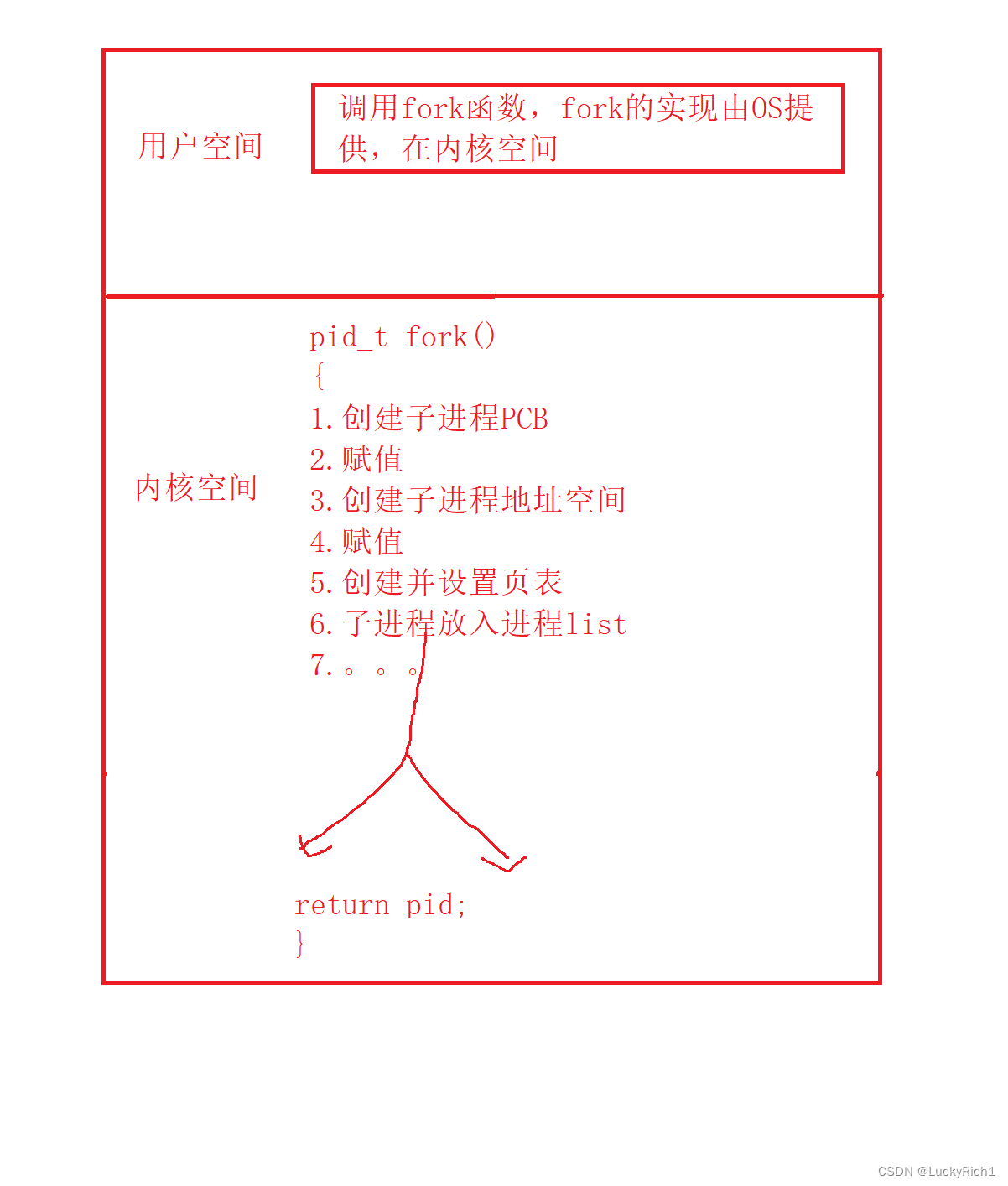
当一个函数准备return的时候,核心代码已经执行完了,所以子进程早已经创建好了,并且可能在OS运行队列中,准备被调度了。
前面所说父子进程共享fork之后的代码,其实不准确,在fork函数之内父子进程就已经分流共享了,所以父子进程各自执行return。
3.如何理解同一个id值,怎么可能保存两个不同的值。让if else同时执行
pid_t id = fork();返回的本质就是写入,所以谁先返回,谁就先写入id,因为进程具有独立性,所以写时拷贝,因此同一个id,地址是一样,但是内容是不一样。
1.2fork常规用法
一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
后面再程序替换具体讲exec函数。
1.3fork调用失败的原因
系统中有太多的进程
实际用户的进程数超过了限制
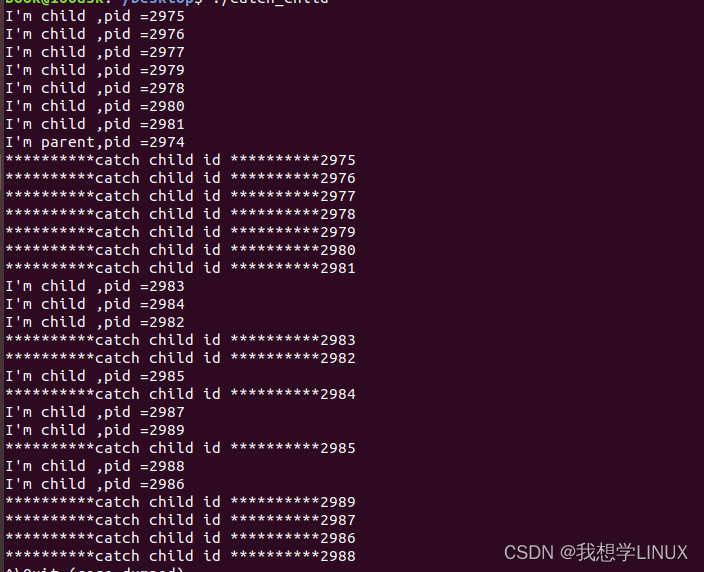
这是一段一直创建子进程的代码,等到不能创建子进程了就退出,会看见创建子进程个数。
#include <stdio.h>
#include <unistd.h>
int main()
{
int cnt = 0;
while(1)
{
int ret = fork();
if(ret < 0){
printf("fork error!, cnt: %d\n", cnt);
break;
}
else if(ret == 0){
//child
while(1) sleep(1);
}
//partent
cnt++;
}
return 0;
}
2.进程终止
2.1退出码
int main()
{
//...
return 0;
}
通常main函数最后都要有一句return 0;其实这是进程退出的时候,对应的退出码,标定进程执行的结果是否正确。
#include<stdio.h>
#include<string.h>
int AddtoTarget(int from,int end)
{
int sum=0;
for(int i=from;i<end;++i)
{
sum+=i;
}
return sum;
}
int main()
{
//写代码是为了完成某件事情,我们如何得知事情完成的怎么样呢?
//进程退出码
int num=AddtoTarget(1,100);
if(num == 5050)
return 0;
else
return 1;
return 0;
}
echo $? //查看进程退出码
$? 该符号永远记录最近一个进程在命令行中执行完毕时对应的退出码。
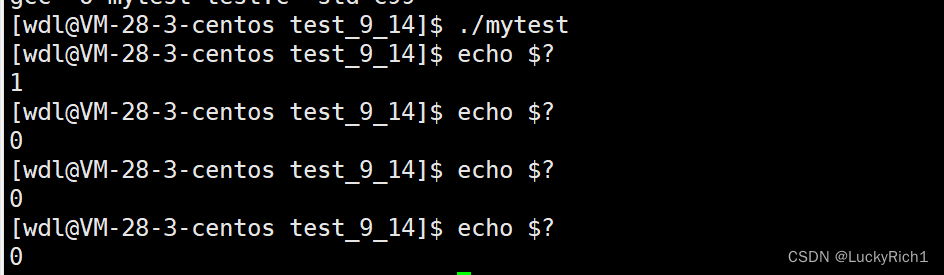
这里下面显示0是怎么回事呢?
这是因为echo 也是一个子进程,因此剩下的三个的是echo &?是一个echo子进程的退出码。
既然知道退出码。那如何设定main函数的返回值呢?
如果不关心进程退出码,return 0就行。
如果未来我们要关心进程退出码的时候,要返回特定的数据表明特定的错误。
退出码的意义: 0 标识success , !0 标识失败,!0具体是几,标识不同的错误。
但是数字对人不友好,对计算机友好。
所以一般而言,退出码都必须有对应退出码的文字描述
1.可以自定义
2.可以使用系统的映射关系
C库给我们提供一个函数,查看进程退出码对应的信息

#include<stdio.h>
#include<string.h>
int main()
{
for(int i=0;i<200;++i)
{
printf("%d: %s\n",i,strerror(i));
}
return 0;
}
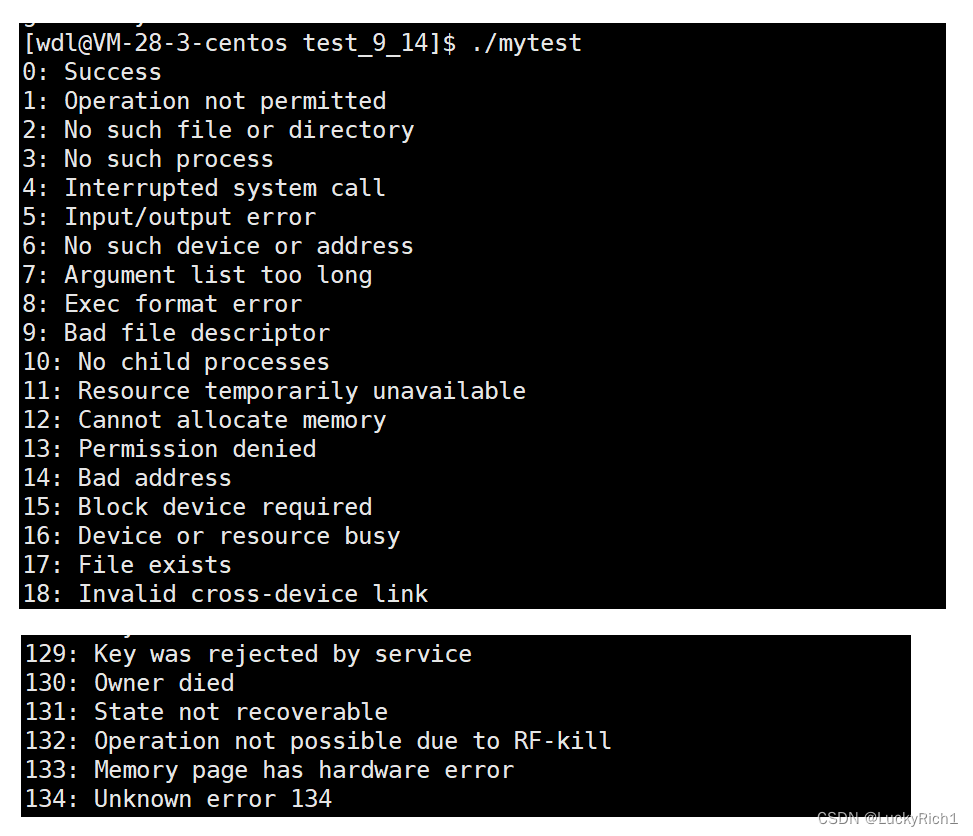
strerror记录了对应的退出码的映射信息,总共135个,这里截取了一小部分。
2.2进程退出场景
1.代码跑完,结果正确--------return 0;
2.代码跑完,结果不正确--------return !0;
3.代码没跑完,程序异常了,退出码无意义;(比如野指针,越界等等)
2.3进程如何退出
1.main函数return返回,其他函数return是调用结束。
2.任意地方调用exit。
1 #include<stdio.h>
2 #include<string.h>
3 #include<unistd.h>
4 #include<stdlib.h>
5 int AddtoTarget(int from,int end)
6 {
7 int sum=0;
8 for(int i=from;i<=end;++i)
9 {
10 sum+=i;
11 }
12 exit(12);
13 // return sum;
14 }
15
16 int main()
17 {
18 int ret=AddtoTarget(1,100);
19 if(ret == 5050)
20 return 0;
21 else
22 return 1;
23 }

3._exit(了解)
1 #include<stdio.h>
2 #include<string.h>
3 #include<unistd.h>
4 #include<stdlib.h>
5 int AddtoTarget(int from,int end)
6 {
7 int sum=0;
8 for(int i=from;i<=end;++i)
9 {
10 sum+=i;
11 }
12 // exit(12);
13 _exit(12);
14 // return sum;
15 }
16
17 int main()
18 {
19 int ret=AddtoTarget(1,100);
20 if(ret == 5050)
21 return 0;
22 else
23 return 1;
24 }

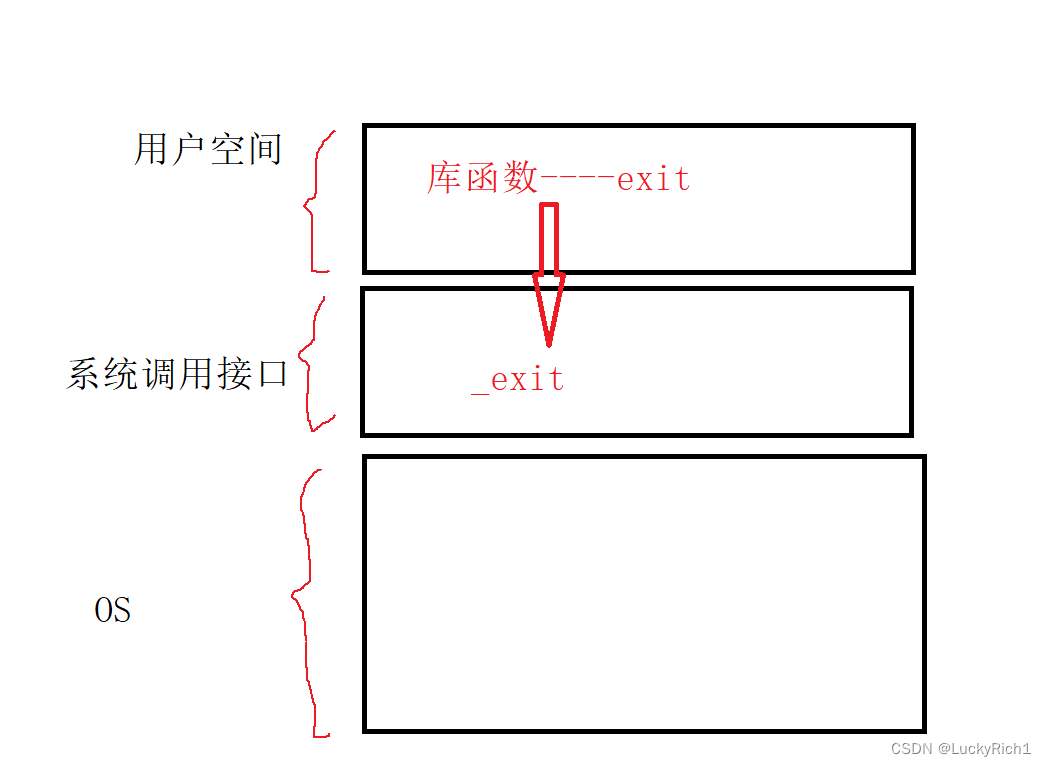
对比exit和_exit发现,都可以使进程再任意地方结束。
exit是库函数,_exit是系统调用。
库函数在系统调用上面。(操作系统哪里画过图)
再看一段代码
int main()
{
printf("hello linux");
sleep(2);
exit(1);
}

int main()
{
printf("hello linux");
sleep(2);
_exit(1);
}

对比发现,exit会刷新缓存区,而_exit并不会刷新缓存区。
这里要说明的是exit会调用_exit。
问缓冲区在哪?
如果在内存,exit调用_exit去终止进程,exit/_exit都应该会刷新缓冲区。
所以缓冲区在用户空间,是用户级的缓冲区。