一)位图:
首先计算一下存储一下10亿个整形数据,需要多大内存呢,多少个G呢?
2^30=10亿,10亿个字节
byte kb mb gb
100000000个字节/1024/1024/1024=1G
所以10亿个字节就是1G,所以40亿个字节就是4G,也就是10个整形数据
给定40亿个不重复的无符号整数,没有排过序,给定一个无符号整数,如何可以快速地判断出一个数是否在这40亿个数中?
解法1:哈希表,10亿个字节,大概是1G,一个int型占4字节,10亿就是40亿字节很明显就是4GB,也就是如果完全读入内存需要占用4GB,40亿个整数是16G,一般运行内存存不下,所以说使用哈希表进行遍历时间复杂度是O(N)
解法2:排序+二分查找,O(N+logN),内存也是存不下的,二分查找必须是在内存中进行二分查找
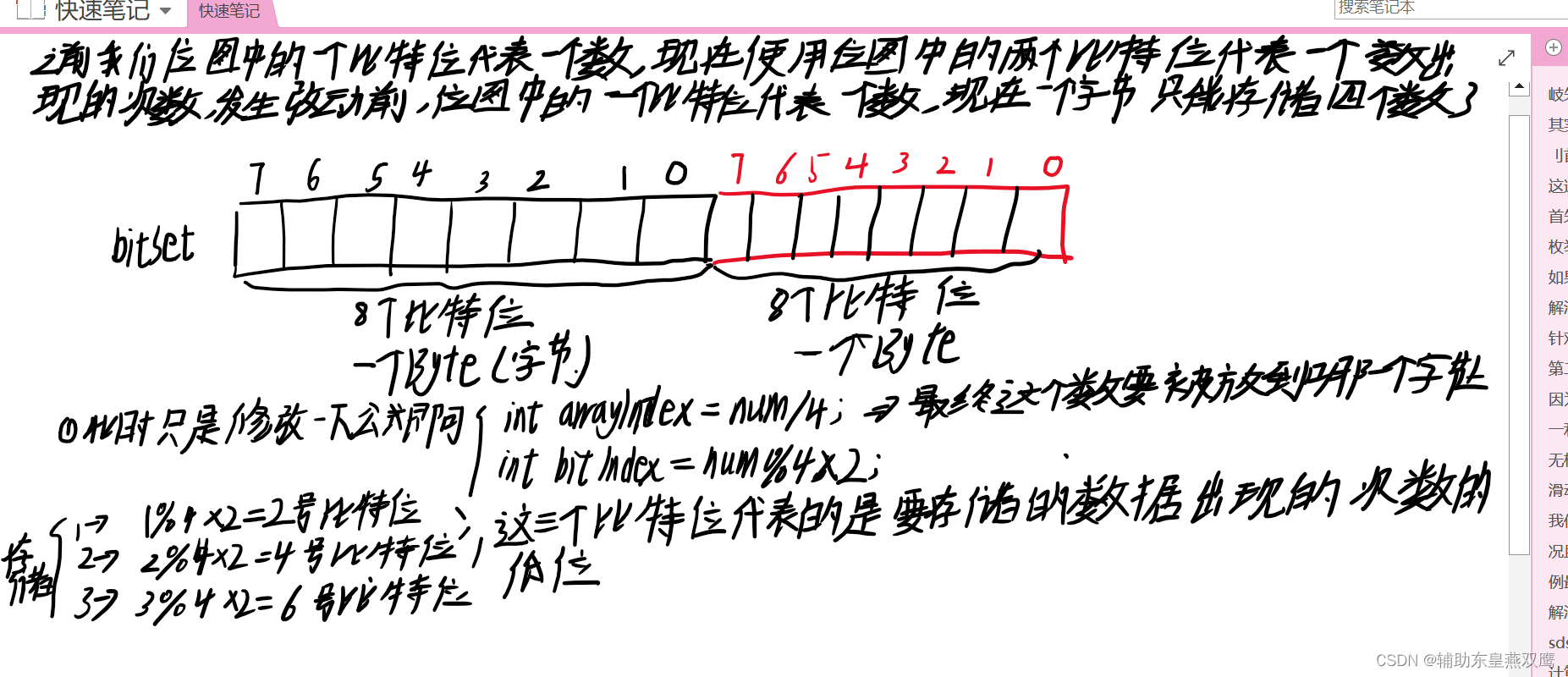
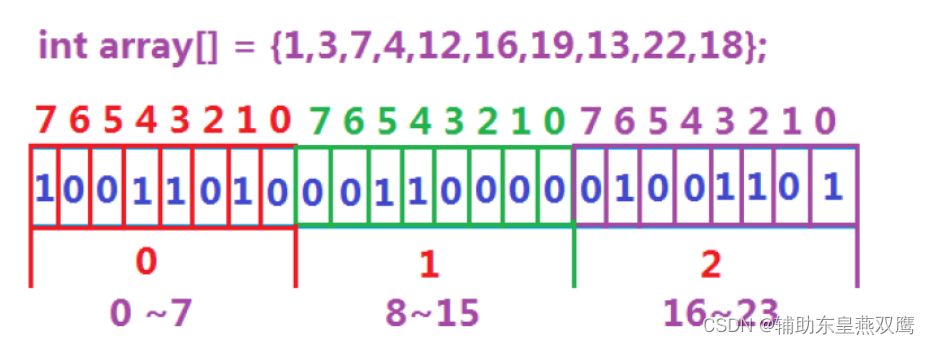
解法3:位图,假设40亿个数据放到了40亿个比特位里面,2^32=40个亿,40亿除8等于X字节,X字节/1024=YKB,YKB/1024=ZMB=512M,1个位占用一个数据,所以仅仅使用512M内存就可以把这些数据全部存储起来,位图有的资料也称之为是bitMap
1)数据是否在给定的整形数据中恰好是在与不在,刚好是两种状态,那么此时就可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,那么代表存在,为0表示不存在,比如说下面这个例子
2)array[index]/8确定的是在那一段区间
array[index]%8确定在那一段区间的哪一个位置
3)也可以很方便进行排序:从左到右输出二进制比特位是1的数据,但是有多个重复的数字就不好处理了,所以位图适用于整形况且没有重复的数据
4)所谓位图,就是用每一位来存放某种状态,适用于海量数据,整数,数据无重复的场景。通常是用来判断某个数据存不存在的
5)位图天然是可以去重的,JAVA当中有一个类叫做BitMap,也叫做位图,也是JAVA.util的类,BitMap底层实现的是long[],但是我们所实现的是byte[]数组,是用于快速查找某一个元素是否存在,况且还可以节省空间;
import java.util.Arrays; public class MyBitSet { public byte[] array; //每一个字节的比特位数都是从左到右边依次递增的 public int usedSize;//记录在当前这个位图中存放了多少有效的数据 public MyBitSet(){ this.usedSize=0; this.array=new byte[1]; } //这里面的n表示需要多少个比特位,有可能会多给1个字节,但是也是无所谓的 public MyBitSet(int n){ this.array=new byte[n/8+1];//假设n=12,此时实际上计算是1个字节,其实现在给2个字节也是可以的 this.usedSize=0; } //设置某一位是1 public void set(int val){ if(val<0) throw new ArrayIndexOutOfBoundsException(); int arrayIndex=val/8;//先找到这个数要放到第几个字节 if(arrayIndex>array.length-1){ //等于的时候刚刚好 this.array= Arrays.copyOf(array,arrayIndex+1); //数组如果越界,那么直接进行扩容,假设存放130,那么计算的下标是16,那么扩容到17个个字节即可 } int bitIndex=val%8;//再找到要修改这个字节的第几位 //也就是说我们要把array[arrayIndex]的第bitIndex位设置成1 this.array[arrayIndex]|=(1<<bitIndex); usedSize++; } //判断当前位是不是1 public boolean get(int val){//判断当前val存储的这一位是1还是0 if(val<0) throw new ArrayIndexOutOfBoundsException(); int arrayIndex=val/8; if(arrayIndex>array.length-1) return false; int bitIndex=val%8; if(((array[arrayIndex]>>bitIndex)&1)==1) return true;//if((array[array[index]&(1<<bitIndex))!=0) return false; } //将val对应字节的存储对应位置置为0,就是相当于是在位图中删除这个值 public void reset(int val){ if(val<0) throw new ArrayIndexOutOfBoundsException(); int arrayIndex=val/8; int bitIndex=val%8; usedSize--; array[arrayIndex]= (byte) ((~(1<<bitIndex))&array[arrayIndex]); } public int getUsedSize(){ return usedSize;//返回当前位图中所存储的元素个数 } //根据位图来进行排序 public static void main(String[] args) { int[] nums={1,9,8,78,100,20,45,16}; MyBitSet set=new MyBitSet(20); //1.现将所有的数字存放到位图里面 for(int i=0;i<nums.length;i++){ set.set(nums[i]); System.out.println(set.get(nums[i])); } System.out.println(set.getUsedSize()); //2.从小到大遍历所有的字节,遍历到其中一个字节之后在进行按照下标从小到大遍历每一个字节里面的比特位 for(int i=0;i<set.array.length;i++){ for(int j=0;j<8;j++){ if(((set.array[i])&(1<<j))!=0){ System.out.println(i*8+j); } } } } }
二)布隆过滤器:
是哈希和位图的一个整合,布隆过滤器是判断某样东西一定不存在或者是可能存在,本质上没有存储当前的数据
布隆过滤器的提出:日常生活中在我们进行设计计算机软件的时候,通常要进行判断某一个元素是否在集合中,最直接的方法就是将所有的元素存储到一个哈希表中,当遇到一个新元素的时候,要进行判断当前这个元素是否出现在集合中

1)在布隆过滤器中最终并没有我所需要进行判断的值
2)布隆过滤器是一种比较巧妙的,紧凑型的概率性数据结构,特点是高效的插入和查询,可以用来告诉你某一样东西一定不存在或者是可能存在,它的原理是使用多个哈希函数,将一个数据映射到位图结构中,此种方式不仅仅可以提升查询效率,也是可以进行节省大量的内存空间,下面是类似与布隆过滤器的插入
1)假设我们要向布隆过滤器存入有关于百度的信息,现在我们使用三个不同的哈希函数,把这个字符串哈希到了三个不同的位置,并将这三个位置的比特位设置成1,接下来又使用这三个不同的哈希函数,将这个字符串又哈希到了三个不同的位置,并且将这三个位置设置成1
2)既然是哈希,就可能会发生碰撞,如果哈希函数越多,此时发生冲突的概率就越小
3)下面比如说出现了这种情况,之前先向这个哈希表中存放了百度相应的信息,通过三个哈希函数得到字符串的下标分别是0 4 6,现在来查询hello这个字符串是否出现在布隆过滤器中,结果经过相同的哈希函数映射到了和百度相同的下标,程序会判断这三个字符串下标的二进制位,此时发现她们三个的二进制位都是1,由此程序判断hello这个字符串在布隆过滤器中,但是如果hello经过三个哈希函数计算出来的下标有一个位置的比特位是0,那么就可以判断这个字符串一定不在布隆过滤器中;
1)布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1,所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中
2)布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判,比如在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的



布隆过滤器删除元素:
布隆过滤器不能直接支持元素的删除操作,因为在进行删除一个元素的时候,可能会影响到其他元素的查找,比如说要删除上面的Tencent,如果将该元素对应的三个二进制比特位设置成0,那么可能会baidu元素也被删除了,因为两个元素在多个哈希函数计算出来的比特位上刚好有重叠,那么一种支持删除的方法就是给布隆过滤器的每一个比特位上面扩展一个小的计数器,插入元素的时候给k个计数器的(k个哈希函数计算出来的哈希地址+1),当进行删除元素的时候,给k个计数器减1,同过多占用几倍存储空间的代价来增加删除操作
1)无法真正的判断元素是否真正地存在于布隆过滤器中,因为这样做会有误判
2)存在计数环绕
布隆过滤器的应用场景:
布隆过滤器的优点:
1)增加或者是查询元素的时间复杂度是O(K),这里面的K是哈希函数的个数,一般比较小,与数据量的大小没有关系
2)哈希函数之间通常没有关系,方便于硬件来进行计算,极大的减少空间
3)布隆过滤器一般来说不需要存储元素本身,在那些具有保密严格要求的场合有很大优势
package Demo; import java.util.BitSet; public class MyBloomFilter { //使用位图 public BitSet bitSet; public static int DEFAULT=1<<20; //记录存放了多少元素个数 public int usedSize; public static final int[] seeds={5,7,11,17,23}; public MySimpleHash[] simpleHashes; public MyBloomFilter(){ bitSet=new BitSet(DEFAULT); simpleHashes=new MySimpleHash[seeds.length]; for(int i=0;i<seeds.length;i++){ simpleHashes[i]=new MySimpleHash(DEFAULT,seeds[i]); } } //添加元素到布隆过滤器中 public void add(String val){ //让若干个哈希函数分别来进行处理当前的数据,把他们都存储在为图档中即可 for(MySimpleHash hash:simpleHashes){ int index=hash.hash(val); //把他们全部存储在哈希中 bitSet.set(index); } usedSize++; } //是否包含val,这里会存在一定的误判的 public boolean contains(String val){ for(MySimpleHash hash:simpleHashes){ int index=hash.hash(val); //进行查找index位置是否存在值,val也是通过这几个哈希函数来进行判断相应的位置,只要有一个位置位0那么一定不存在 boolean flag= bitSet.get(index); if(flag==false) return false; } return true; } public static void main(String[] args) { MyBloomFilter filter=new MyBloomFilter(); filter.add("hello"); filter.add("hello2");//在布隆过滤器里面只是存放了一个状态,真实的数据是没有存放在布隆过滤器里面的 filter.add("bit"); System.out.println(filter.contains("hello3")); } }package Demo; public class MySimpleHash { public int count;//当前容量 public int seed; public MySimpleHash(int count,int seed){ this.count=count; this.seed=seed; } //根据seed不同创建不同的哈希函数 final int hash(String key){ int h;//(n-1)&hash直接计算下标 return key==null?0:(seed*(count-1))&(h=key.hashCode())^(h>>>16);//根据字符串得到一个哈希值 //在这里面必须要乘以seed,因为如果不乘以seed的话,相同的字符串就通过相同的哈希函数被映射到了相同位置 } }使用布隆过滤器:
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>30.1-jre</version> </dependency>public class HelloWorld { //第一个参数代表要想布隆过滤器中存放多少数据,第二个参数代表的是误判率 private static BloomFilter<Integer> bloomFilter=BloomFilter.create(Funnels.integerFunnel(),100000,0.01); public static void main(String[] args) { //1.插入数据 for(int i=0;i<100000;i++){ bloomFilter.put(i); } //2.使用count变量来记录最终误判了多少个 int count=0; for(int i=100000;i<200000;i++){ if(bloomFilter.mightContain(i)){ count++; System.out.println(i+"被误判"); } } System.out.println("一共误判了"+count+"个"); } }总结:
1)位图适合于整数,大量数据,查找去重排序,但是如果不是整数,就需要使用布隆过滤器
2)布隆过滤器适合于一些非整数的,本质上是用哈希+位图来进行结合做的,查找的时间复杂度和哈希函数的个数有关系,但是布隆过滤器本质上是不会存储任何有关于数据的信息的

三)海量数据问题:
1)首先内存中是不可能放大下100G的数据的,现在给定一个100G大小的log file,log中存放着IP地址,请你设计一个算法计算出找到次数最多的IP地址?还有和上个题相同,如何找到TOPK的IP?
1.1)通常来说如果忽略大小,那么我们可以统计处每一个IP出现的次数,可以使用hash<Key,Vlaue>结构来解决这个问题,但是问题是当前的100G的数据实在是太大了,肯定是无法一次性全部加载到内存中的
1.2)100G太大了,肯定要把文件变小,这也就意味着文件的个数要成倍增加,思路就是尝试把这一个文件拆分成若干个小文件,问题是如何进行拆分,可能说均分,100G,每一个文件大概存放个200M,512M,一个一个小文件去读取,但是这样不可以,因为均分会出现一个情况,一个文件当中最多的IP地址不一定就是整体上最多的IP地址,假设www.baidu.com出现的次数是最多的,但是因为文件均分,假设分成了200个文件每一个文件都分了一点www.baidu.com,整体上来看www.baidu.com,但是每一个文件中www.baidu.com却不是最多的;所以不可以将文件均分,均分的是数量,不是根据IP地址的内容均分的;
1.3)我们进行分割的目的就是如果所有的www.baidu.com可以分到一个文件中,也就是所有相同的IP地址被分到一个文件中,这样有可能是分割好的,是否可以将相同的IP地址存储到同一个文件中?如果可以做到就可以解决这个问题;
1)IP本身就是一个字符串而已,先把IP地址变成一个整数int data=hash(IP)
2)要把这个IP地址放到的文件的下标就是index=hash(IP)%总共分成的文件的个数,这样做的好处就是把相同的IP地址字符串映射到同一个文件中
3)我们创建一个200个文件,每一个文件存放500M的数据,每一个文件存放的内容都是根据1 2步来进行划分的
4)读取每一个文件出现的内容,最后统计每一个文件当中IP出现的次数,就可以使用HashMap来进行记录,HashMap<IP地址字符串,每一个IP地址出现的次数>,这种思想就是哈希切割
2)给定100亿个整数,设计算法找到只出现一次的整数?
10亿个字节占1G,10亿个整数占4G,那么100亿个整数占40G内存,100G文件肯定在磁盘上,在大文件里面,int整数无符号也就只有40个亿,有某一个数字可能出现的次数是1次,两次,三次都有可能
解法1:哈希切割
可以创建若干个不同的小文件,每一个小文件的内存不要太大,可以把每一个数字哈希到对应的小文件中,这个时候相同的数字一定都被分到了一个小文件里面,此时我们需要遍历每一个小文件,可以把这一个小文件读到内存里面,然后在内存中统计每一个数字出现的次数,此时在内存中就知道了哪一个数字只是出现了一次,最后将只出现一次的数字保存下来
解法2:位图
42亿个整数,大约是512M个比特位
42亿/8/1024/1024=512M的字节
创建两个位图:
一个位图存放着对应某一个数字出现的底位
另一个位图表示对应着某一个数字出现的高位
没有出现过0 0
出现过1次:0 1
出现过2次: 1 0
出现过三次以上: 1 1
最后需要定义一个下标i和下标j同时遍历这个位图,i和j其实都是指向的是同一个位置,如果发现bitSet1(i)==0&&bitSet(j)==1,那么就代表着这个数字出现了1次
解法3:使用一个位图来解决这个问题: