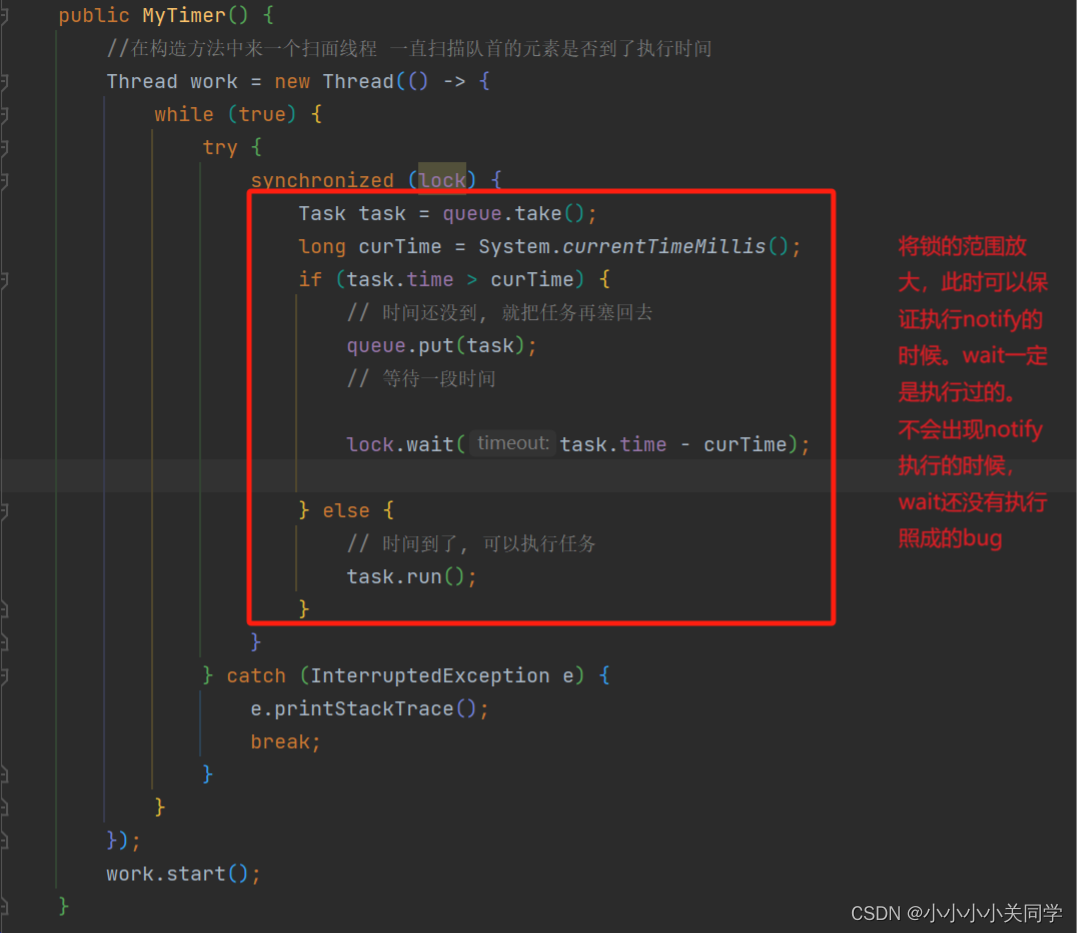
记录一些踩坑的地方,以及理顺一些思路。
通过管理系统页面,完成商品属性分组和商品属性(基本属性)关联维护
属性表 与 属性组表 的功能完善:显示属性组与属性表的一对多关系
前端
1. 引入组件,是否显示使用v-if,但是还要注意引入的组件本身,是否自己也有 :visible.sync="visible"这样的属性。只有当两层是否显示的变量都为true的时候,才会显示。
2. 使用子组件的方法,使用ref
3. 需要在执行完毕后,才立即执行的情况,使用this.$nextTick(()->{ lambda表达式的方法体 })
移除中间表,即连接属性表与属性组表的AttrAttrgroupRelation表
后端
需求说明:
批量删除关联表内容。
我的方案问题及解决方案:
1.我写了(@RequestBody Map params) 来获取参数,结果参数都拿不到,直接报错。
前端传递的问题。使用postman可以正常传输。
这个方案不好:①获取参数麻烦;②传递数组也不方便
2.还有底层不知道给两个基本参数,还是给一个对象,比较好?
传给一个关联表的entity对象。可以使用@RequestBody来直接封装到该自定义的entity里面。
而且参数使用数组的形式,前端使用Json,只有数组,没有集合格式
再在后端转为集合,因为dao层foreach遍历,传参用的是集合。这样便可以实现批量删除
3.我的想法,要先去mysql查到要删除的数据,然后再去mysql删除,多了一个查询的步骤。
4.想返回受影响的行数。
测试发现,在dao层返回类型设为Integer,是可以直接返回受影响行数的,不用额外写代码。
细节踩坑:
1、在dao层的接口方法,依然要使用注解@Param 传参!
通过删除该注解发现,参数会值为空,且不能正确运行。
2、测试数据的类型要求数组,所以格式要求“ [ ] ”这样来表示数组!
通过在postman,哪怕是单一entity,没有使用[ ],也发生了错误。
3、Mapper语句中,字段名(来自于mysql) = 值(来自于java的Entity)。
没有写错,再次提醒而已。
4、找了2个小时的bug。在service层调用dao层的方法时,使用了this.方法,结果调的是service层自己,就变成了无限嵌套,导致出错。根本原因还是对这儿的this理解不够。
错误原因:
① 错误写法形成的原因。之前的代码,因为有“工具类”(可能形容不准确)的存在,所以能使用this.方法,使得能通过this.方法,在service层调用dao层的对应方法。
② 出错的原因。因为当前方法是我在dao层自定义的,service没有进行实现,需要我自己调用dao层来实现,结果我写个this.方法,成了自己调用自己当前方法,就形成了没有返回的嵌套。
最好的解决办法,不要使用this,代码规范有要求
查询某个商品属性分组可以关联的商品属性(基本属性),支持分页和条件检索
@RequestBody和@RequestParam区别全面详细
还是对this的理解不够深刻。为什么:
为什么在AttrServiceImpl.java就可以
IPage<AttrEntity> page = this.page(
new Query<AttrEntity>().getPage(params),
//终于看懂这个wrapper了,它是个变量,放在这儿作参数用的。
wrapper
);在AttrgroupServiceImpl.java,就不可以
IPage<AttrEntity> page = new AttrServiceImpl().page(
new Query<AttrEntity>().getPage(params),
wrapper
);显示可建立关联的基本属性
涉及多表联查,使用AB两表查询得到限制条件,通过限制条件,在C表直接分页查询完成。
新建属性组与基础属性的关联
调用service提供的接口,即可完成。
因为支持批量增加,所以参数是List类型的,使用@RequestBody进行传递
商品发布
SPU和SKU介绍
1、SPU的概述
1)SPU(Standard Product Unit):标准化产品单元
2)用简单的话来说就是一类商品,比如手机里的一种牌子,如小米,苹果,都是一类。然后加入具体的类型,如小米10、苹果X。那么它就是一个spu
2、sku的概述
1)SKU(Stock keeping Unit):库存保有单位
2)sku简单来说就是在spu原有的基础上加入具体的类型,如小米10,银色,8+128g。组合起来就是一个完整地sku。所以sku就是一类商品的各种样式的组合。
3、spu和sku的关系
1)spu和sku就是上下级关系,没有spu就没有sku。因为假如没有这一类商品,就没法谈这件商品具体的颜色尺寸
2)如下图:假如没有选择任何类型那么他就是一个单独的spu,但是当它选择了具体的颜色,版本,购买方式等等,那么他就是一个sku
完成商品发布页面

1.完成选择商品分类时,联动获取该分类下的品牌
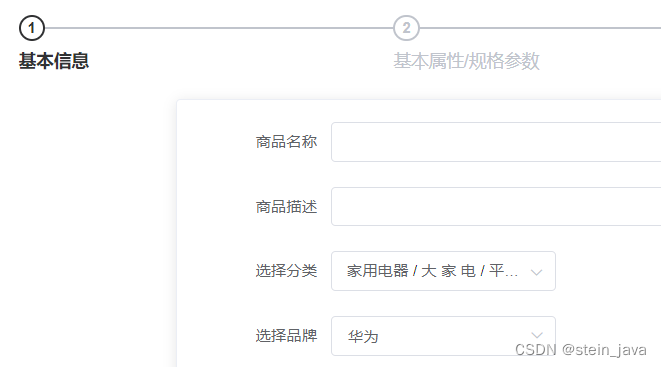
指定商品分类后,自动显示可以选择的品牌列表
实现:
利用categoryId查询关联表,得到brandId,使用它查询brand表的行,并返回
注意:
1.当输入的categoryId没有时,会报异常
2.当输入的categoryId在关联表,找不到对应的brandId时,也会报错
因为这时的mysql的语句里面in()后面的内容为空,所以报异常
解决办法是,直接使用stream流进行处理,处理完的BrandEntity进行返回,这样允许返回为[]。
2.完成获取某个分类的关联的所有属性分组和这些属性分组关联的基本属性,并显示供发布选择
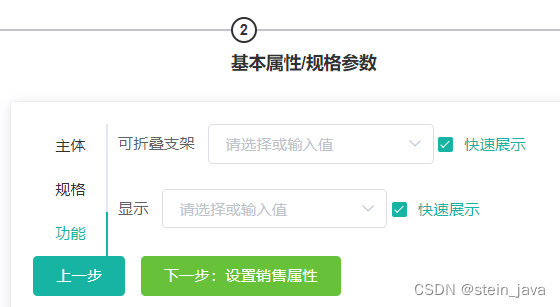
1. 当目前的实体类/对象,格式不能满足需求时,可以使用VO(View Object)视图对象
2. VO可以根据需求组合己有的实体类字段,或者增加,或者删除一些字段
难点:
1.多表查询。使用流式计算,提高效率。
2.使用BeanUtils.copyProperties(数据源,目的数据)将数据封装到VO里面。以前在JavaWeb的时候用过。
debug:
1.前后端的debug都没有反馈:居然是因为@PathVariable("catalogId") 括号里面的单词拼错了!
2.后端测试正确,前端不显示结果。原因是前端遍历子属性的名称,和后端不一致,导致无法遍历。将后端名称改为和前端一致,便解决了。
3.完成获取某个分类的销售属性,并显示供发布选择
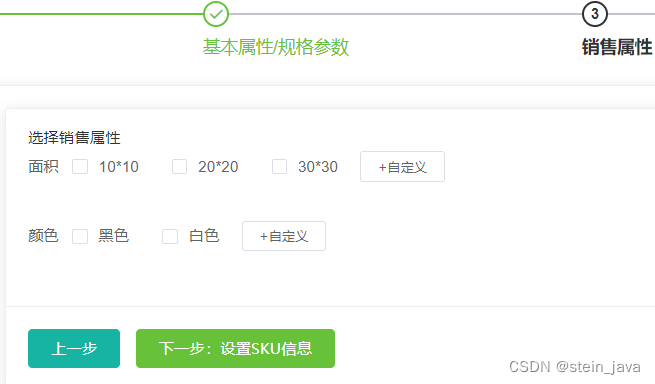
debug:
1.因为不带查询条件,所以代码要判断查询条件是否为空,否则mysql会导致异常。
2.查询条件的字段,需要与mysql保持一致,否则也会引起异常。
3.检查前端的分隔符,split(",")里面的符号,和后端是否保持一致,同时注意中英文。
4.完成根据前面填写的多个销售属性,构建成商品SKU信息(也就是各种组合关系)

由前端页面完成
5.完成保存商品信息功能
需要设计VO类:
1、通过前端获得提交的json格式的数据,在JSON在线解析及格式化验证 - JSON.cn里面选择,“json生成java实体”
2、根据业务要求,修改生成类的类型,以及必要的增删
功能1-保存spu基本信息
创建数据库,使用renren-fast生成crud代码
复制/剪切到后端程序中
报错:
java: 找不到符号
符号: 类 SpuInfoEntity
位置: 程序包 com.stein.steinliving.commodity.entity
解决办法:
1.Maven 刷新(Reload All Maven Project)
2.菜单栏:build->Build Module "xxxxxx”
上两步依然没有解决,实际解决:
Maven,lifecircle-> clean。重新运行module即可。。
bug:
前端点击继续添加,如果不重新手动选择categoryId和品牌brand,那么前端显示有数据,后端得不到,数据库内会显示为null。
功能2-保存spu图片描述url
开始认为是一对多,使用一个id+多行decript保存;结果是用“,”逗号分割,保存在一行里面。
所以当初设计的时候,mysql对应的字段属性是LONGTEXT。
功能3-保存spu图片集信息
功能4-保存spu的基本属性/规格参数
功能5-保存sku的基本信息
注意字段的命名:
因为mysql不区分大小写,所以将java属性的spuId,写作spu_id。不按照这个格式进行对应,可能会出错。
功能6-保存sku的图片信息
完善上传功能:
在前端的src/components/upload/multiUpload.vue文件下
<el-upload> 中的action进行设置,改为自己的oss地址,比如
action="http://xxxxxx.oss-cn-beijing.aliyuncs.com"
功能7-保存sku的销售属性
spu管理页面
添加订阅发布功能
因为要使用到订阅发布功能,所以我们需要做如下操作:
1.使用npm添加依赖:npm install --save pubsub-js
(失败的话使用此命令:cnpm install --save pubsub-js)
2.修改:在src下的views/main.js,增加语句
import cloneDeep from 'lodash/cloneDeep'
import PubSub from 'pubsub-js'
3.挂载全局下面添加:
Vue.prototype.PubSub = PubSub // 组件发布订阅消息
完善分页检索功能
其中的模糊检索:
wrapper.and(w->{
w.eq("id",key).or().like("spu_name",key);
});完善“上架”和“下架”
1.先编写dao层。
可以使用快捷键alt+enter,找mybatis的选项,自动填充@注解
继续使用快捷键,找mybatis的选项,自动完善要实现的result部分
void productUpOrDown(@Param("spuId") Long spuId,
@Param("statusCode") Integer statusCode);实现语句:
先在mysql里面测试语句是否正确,再写到实现语句
2.完善service层
3.controller层进行接口调用。
sku管理页面
同上
1.引入新页面打不开,可以重启下前端。
2.查看前端检索条件,注意看条件的名称:
key: this.dataForm.key, catalogId: this.dataForm.catalogId, brandId: this.dataForm.brandId, min: this.dataForm.price.min, max: this.dataForm.price.max
然后判断出封装在哪个变量:this.dataForm,然后输出查看:
console.log("检索条件=>",this.dataForm)
3.检索条件。价格区间:
这儿给max加了一条不为“0”的限制条件。
因为前端默认min、max=0。不利于初始化显示。
//这儿的min和max是在price的子属性上,也是这么取吗?
// 是的。因为封装的时候是遍历price的属性再进行封装的。
//这儿是比较的数字,还是使用String接收吗? 是的
//如何比较的大小? ge(GreatEqual),le(LittleEqual)
String min = (String)params.get("min");
if(StringUtils.isNotBlank(min)){
wrapper.ge("price",min);
}
String max = (String)params.get("max");
if(StringUtils.isNotBlank(max) && !"0".equals(max)){
wrapper.le("price",max);
}搭建客户端显示的首页面
Thymeleaf的导入/引入
1.将资源包中的resources文件解压,放到后端项目的中的resources中。
2.maven中引入thymeleaf。在pom.xml中添加,不设置版本号,由版本仲裁控制
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>3.application.properties设置关闭缓存,便于随时刷新变化。
spring.thymeleaf.cache=false
4.添加前端web控制层。
@Controller
public class IndexController {
//响应用户请求首页面
@GetMapping(value={"/","/index.html"})
private String indexPage(){
// 默认找到就是"classpath\templates"+"index"+".html"
return "index";
}
}5.index.html文件引入命名空间。否则后期使用th标签时,无法识别。
文件路径:src/main/resources/templates/index.html
<html lang="en"xmlns th="http://www.thymeleaf.org">
首页显示1级目录
首页显示2、3级目录
1.创建2-3级VO类的数据结构
2.实现VO类数据的封装
2.1逻辑删除
通过查询发现,返回的数据不会有逻辑删除的内容。回忆之前逻辑删除的实现方法:
mybatis-plus:
mapper-locations: classpath:/mapper/**/*.xml
global-config:
db-config:
id-type: auto #配置主键自增
logic-delete-value: 0 # 逻辑已删除值(默认为 1, 提示:调整成我们自己的)
logic-not-delete-value: 1 # 逻辑未删除值(默认为 0 提示:调整成我们自己的)2.1.2 属性添加响应的注解
2.2 categoryService层编写方法
2.2.1 可以编写一个测试类,随时查看返回值是否正确
@Controller
public class Test {
@Resource
private CategoryService categoryService;
@RequestMapping("/t1")
@ResponseBody //返回Json格式的数据。使用了便没有报错
public Map<String, List<CategoryLevel2OV>> test(){
Map<String, List<CategoryLevel2OV>> categoryLevelJson
= categoryService.getCategoryLevelJson();
return categoryLevelJson;
}
}2.2.2代码实现
@Override
public Map<String, List<CategoryLevel2OV>> getCategoryLevelJson() {
List<CategoryEntity> categoryList = this.baseMapper.selectList(null);
//System.out.println(categoryList.toString());
// 1级->2级->3级 再组装
//获取1级分类
List<CategoryEntity> level1 = getCategoryByParentId(categoryList, 0l);
//通过流,遍历1级分类,并把数据进行封装,并从List转换为前端需要的Map
Map<String,List<CategoryLevel2OV>> categoryMap = level1.stream().collect(Collectors.toMap(k -> {
return k.getId().toString();
}, v -> {
//第二级的封装
//先获取2级分类
List<CategoryEntity> level2
= getCategoryByParentId(categoryList, v.getId());
List<CategoryLevel2OV> level2OV = level2.stream().map(l2 -> {
CategoryLevel2OV categoryLevel2 = new CategoryLevel2OV();
categoryLevel2.setCatalog1Id(v.getParentId().toString());
categoryLevel2.setId(v.getId().toString());
categoryLevel2.setName(v.getName());
//第三级的封装
List<CategoryEntity> level3 = getCategoryByParentId(categoryList, l2.getId());
List<CategoryLevel2OV.Catalog3List> level3VO = level3.stream().map(l3 -> {
CategoryLevel2OV.Catalog3List level3Entity = new CategoryLevel2OV.Catalog3List();
level3Entity.setId(l3.getId().toString());
level3Entity.setName(l3.getName());
level3Entity.setParentCId(l3.getParentId().toString());
return level3Entity;
}).collect(Collectors.toList());
categoryLevel2.setCatalog3List(level3VO);
return categoryLevel2;
}).collect(Collectors.toList());
return level2OV;
}));
return categoryMap;
}
//私有方法:起到一个筛选作用。在数据列表中,筛出符合条件的的categoryEntities。
private List<CategoryEntity> getCategoryByParentId(List<CategoryEntity> selectList, Long parentId) {
List<CategoryEntity> categoryEntities = selectList.stream().filter(item -> {
return item.getParentId().equals(parentId);
}).collect(Collectors.toList());
return categoryEntities;
}因为它是一个映射,所以返回类型是
3.连接前端
3.1找到前端发送Ajax请求的位置:
src\main\resources\static\index\js\catalogLoader.js,该js文件就是向服务器发出ajax请求,返回第2级和第3级json数据,然后由前端人员完成显示【我们直接使用即可】
由这句$.getJSON("index/catalog.json", function (data)可以看出访问路径为:"index/catalog.json",由此设置后端访问接口
3.2完善前端属性,便于数据显示
完善属性,便可在首页正常显示。
<a href="#" class="header_main_left_a" th:attr="ctg-data=${category.id}">
但是在控制台的data不能正常显示,显示一些类似当前行高的数字,随鼠标滑轮变化。看不懂。。
0
secend.js:3 0.9090908765792847
secend.js:3 6.363636016845703
secend.js:3 19.09090805053711
secend.js:3 40.909088134765625
secend.js:3 70.90908813476562
secend.js:3 108.18181610107422
secend.js:3 148.1818084716797
secend.js:3 185.4545440673828
secend.js:3 215.4545440673828
secend.js:3 235.4545440673828
secend.js:3 244.5454559326172
secend.js:3 246.36363220214844
secend.js:3 245.4545440673828
secend.js:3 240.90908813476562
secend.js:3 234.5454559326172
secend.js:3 224.5454559326172
secend.js:3 209.09091186523438完善搜素首页
1.创建OV类
注意Thymeleaf是通过对象传输的,而不是Json
2.实现搜索功能-Service层
3.实现数据的二次封装。添加Model参数,用于传输属性。-Controller层
4.前端调用封装到Model里面的数据。
添加Thymeleaf的命名空间
找到显示的list.html文件,通过搜索显示的实例里面的价格,找到对应的属性,进行关联。
完善分页导航栏
完善搜索框搜索
只搜索状态为上架的商品
1.添加搜索spuInfo表的dao层,完成搜索,获得上架spuIds
2.把原来的搜索添加spuId这个搜索条件,限定搜索范围在spuIds上架状态
注意:
要判断spuIds.size>0,如果真,则执行限定in();
如果假,便直接返回。为了统一返回内容为SearchResult,便开始重构
重构搜索功能
//返回购买用户检索的结果PageUtils->SearchResult / Result
完善分页查询功能,用户点击某页超链接,显示对应页的数据
分析源代码,查看导航页的参数属性构成情况。
没有输入,便按照默认设置的参数执行。

添加前端导航条,分页代码
//分页请求
$(".page_a").click(function () {
var pn = $(this).attr("pn");
var href = location.href;
if (href.indexOf("page") != -1) {
//替换, 这里的"page" 是因为我们后台分页插件是按照 page 这个参数来当做当前页
//的参数
//所以写成 page ,同学们应当根据你的后台是安装什么参数名来接收当前页进行相应改变
location.href = replaceParamVal(href, "page", pn);
} else {
//增加 pageNuw
if (href.indexOf("?") != -1) {
location.href = location.href + "&page=" + pn;
} else {
location.href = location.href + "?page=" + pn;
}
}
return false;
})在搜索框,保留检索关键字
原理:前端发送到 -> 后端,添加类字段,保存keyword,通过result回传 -> 前端,回显
1.前端原始代码,通过placeholder显示默认内容。此时内容固定显示
<input id="keyword_input" type="text" placeholder="家居~"/>2.后端封装返回数据的SearchResultOV.java类,添加keyword属性
3.业务代码,完善SkuInfoServiceImpl.java类中,keyword的内容封装
//添加搜索框回显内容 //三元操作符
searchResultOV.setKeyword(params.get("keyword")==null?"":params.get("keyword").toString());4.前端回显
<input id="keyword_input" th:value="${result.keyword}"
type="text" placeholder="家居~"/>通过value取出result.keyword进行回显。
加入Nginx-完成反向代理、负载均衡和动静分离
https://blog.csdn.net/weixin_49764008/article/details/132887378?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22132887378%22%2C%22source%22%3A%22weixin_49764008%22%7D
完成 Nginx的添加
![[字符串和内存函数]strcat和strncat的区别](https://img-blog.csdnimg.cn/7263fce341fa459da8970416e18e5dc4.png)