一、
MQ
介绍
1
、什么是
MQ
?为什么要用
MQ
?
ChatGPT
中对于消息队列的介绍是这样的:

MQ
:
MessageQueue
,消息队列。这东西分两个部分来理解:队列,是一种
FIFO
先进先出的数据结构。
消息:在不同应用程序之间传递的数据。
将消息以队列的形式存储起来,并且在不同的应用程序之间进行传
递,这就成了
MessageQueue
。而
MQ
的作用,从刚才
ChatGPT
的介绍中就能够抽象出三个关键字:异步、解耦、削峰。但是这什么意思呢?跟开发有什么关系?我们从一个简单的SpringBoot
应用开始说起。
首先搭建一个普通的
Maven
项目,在
pom.xml
中引入
SpringBoot
的依赖:


然后,添加一个监听器类

接下来,添加一个
SpringBoot
启动类。在启动类中加入自己的这个监听器。

好了。不用添加配置文件,直接启动就行。 然后可以看到这样的结果:

从这个例子中可以看到,在
run
方法中,我们使用
applicationContext
发布了一个
myEvent
事件,然后通过自定义的监听器MyApplicationListener
,就监听了到这个
myEvent
事件。这个过程中,
applicationContext担任了发布消息的功能,称为消息生产者Producer
,而
MyApplicationListener
担任了消费处理这个消息的功能,称为消息消费者Consumer
。
Producer
和
Consumer
他们的运行状况互不干涉,没有
Consumer
,Producer一样正常运行,反过来也一样。也就是说,推送
Producer
和
Consumer
正常工作的,只有发布的这些事件。这种方式就称为事件驱动。
从这个简单的例子中你可以看到,
SpringBoot
内部就是集成了事件驱动机制的。
SpringBoot
会将自己应用过程中发生的每一个重要的运行步骤都通过事件发送出来。你会发现这些事件对于监控一个SpringBoot
应用挺有用的。如果我想要另外搭建一个监控系统,也像MyApplicationListener
一样监听
SpringBoot
的这些事件,应该要怎么做呢?
直接监听肯定是不行的,因为
SpringBoot
中的这些事件只在应用内部有效。因此,需要独立出一个中间服务,这样才可以去统一接收SpringBoot
应用的这些事件。

这时这个神秘的中间服务要保证这些系统可以正常工作,应该要有哪些特性呢?
1
、
SpringBoot
应用和监控服务应该是
解耦
的。不管有没有监控服务,
SpringBoot
应用都要是可以正常运行
的。同时,不管监控服务是用什么语言开发的,同样不应该影响
SpringBoot
应用的正常运行。更进一步,不管监控服务要部署多少个,同样也不应该影响SpringBoot
应用的正常运行。反过来,从监控服务看SpringBoot应用也应该是一样的。这就需要这个中间服务可以提供不同语言的客户端,通过不同客户端让消息生产者和消息消费者之间彻底解耦。
2
、
SpringBoot
应用和监控服务之间处理消息应该是
异步
的。基于解耦的关系,
SpringBoot
应用并不需要知道监控服务有没有运行。所以他并不需要将消息直接发送到监控服务,也不需要保证消息一定会被监控服务处理。他只要将消息发到中间服务就可以了。而监控服务可以在SpringBoot
应用发布了时间之后,随时去接收处理这些消息。
3
、这个中间服务需要可以协调双方的事件处理速度,产生
削峰填谷
的效果。监控服务一般都是希望每五分钟接收到SpringBoot
发布过来的消息,然后进行一次统计,但是
SpringBoot
应用发布的事件频率却是不确定的。如果SpringBoot
应用在五分钟内产生了海量的消息,就有可能让监控服务内存撑爆,处理不过来。而监控服务如果加大内存,SpringBoot
应用又有可能在五分钟内根本没有消息,监控服务的内存就白加了。监控服务的内存配大配小都不合适。这时候,就需要这个中间服务能够这些消息暂存起来,让监控服务可以按照自己的能力慢慢处理问题。这就是中间服务的削峰填谷的作用。
而MQ
也就是为了这样的场景创建的中间服务。
MQ
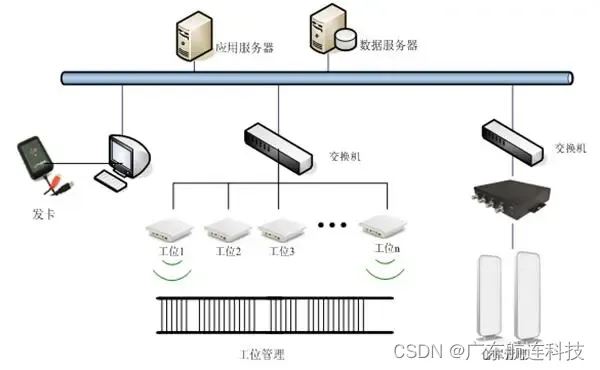
中间件在很多业务场景中都扮演着很重要的角色。例如下图是一个典型的秒杀场景业务图:

在后面的实战项目中,会带大家从头到尾搭建一个这样的秒杀系统。在这其中,对于后端最重要的优化就是使用MQ
。在典型的秒杀场景,瞬间产生的大量下单请求很容易让后端的下单服务崩溃。这时,就可以让下单系统将订单消息发送到MQ
中间暂存起来,而后端的额下单服务就可以从
MQ
中获取数据,按照自己的处理能力,慢慢进行下单。另外,下单是一个比较复杂的业务,需要通知支付系统、库存系统、物流系统、营销系统等大量的下游系统。下单系统光一个个通知这些系统,就会需要很长时间。这时,就可以将下单完成的消息发送到MQ
,然后下游的各种系统可以从
MQ
中获取下单完成的消息,进行异步处理。这样也能极大提高下单系统的性能。
2
、
MQ
的优缺点
这时候你可能在想,
SpringBoot
已经提供了本地的事件驱动支持。 那么我是不是给
SpringBoot
应用加上一些web
接口,基于这些
web
接口不就可以将本地的这些系统事件以及自己产生的这些事件往外部应用推送,那这不就成了一个MQ
服务了吗?单其实上面列出了
MQ
的的很多优点。 但是在具体使用
MQ
时,也会带来很多的缺点:
·系统可用性降低
系统引入的外部依赖增多,系统的稳定性就会变差。一旦
MQ
宕机,对业务会产生影响。这就需要考虑如何保证MQ
的高可用。
·系统复杂度提高
引入
MQ
后系统的复杂度会大大提高。以前服务之间可以进行同步的服务调用,引入
MQ
后,会变为异步调用,数据的链路就会变得更复杂。并且还会带来其他一些问题。比如:消息如何高效存储、如何定期维护、如何监控、如何溯源等等。如何保证消费不会丢失?不会被重复调用?怎么保证消息的顺序性等问题。
·消息安全性问题
引入
MQ
后,消息需要在
MQ
中存储起来。这时就会带来很多网络造成的数据安全问题。比如如何快速保存海量消息?如何保证消息不丢失?不被重复处理?怎么保证消息的顺序性?如何保证消息事务完整等问题。
所以
MQ
的应用场景虽然比较简单,但是随着深度分析业务场景,也会随之产生非常多的问题。甚至为此指定的业务标准都出现过好几套,比如JMX
,
AMQP
等。因此,这才需要构建出
RabbitMQ
等这些中间件,来完整的处理MQ
遇到的这些问题。
3
、几大主流
MQ
产品特点比较
所以
MQ
通常用起来比较简单,但是实现上是非常复杂的。基本上
MQ
代表了业界高可用、高并发、高可扩展三高架构的所有设计精髓。在MQ
长期发展过程中,诞生了很多
MQ
产品,但是有很多
MQ
产品都已经逐渐被淘汰了。比如早期的ZeroMQ,ActiveMQ
等。目前最常用的
MQ
产品包括
Kafka
、
RabbitMQ
和
RocketMQ
。我们对这三个产品做下简单的比较,重点需要理解他们的适用场景。

4
、关于
RabbitMQ
RabbitMQ
的历史可以追溯到
2006
年,是一个非常老牌的
MQ
产品,使用非常广泛。同时期的很多
MQ
产品都已经逐渐被业界淘汰了,比如2003
年诞生的
ActiveMQ
,
2012
年诞生的
ZeroMQ
,但是
RabbitMQ
却依然稳稳占据一席之地,足可见他的经典。官网地址
https://www.rabbitmq.com/
。

RabbitMQ
虽然是开源的,但是是基于
erlang
语言开发的。这个语言比较小众,用得不是很多。因此很少研究源码。
RabbitMQ
的应用相当广泛,拥有很多非常强大的特性:

二、
Rabbitmq
快速上手
1
、版本选择
RabbitMQ
版本,通常与他的大的功能是有关系的。
3.8.x
版本主要是围绕
Quorum Queue
功能,而
3.9.x
版本主要是围绕Streams
功能。后面的
3.10.x
版本和
3.11.x
版本,没有太多新功能,主要是对
Quorum Queue和Stream
功能做一些修复以及增强,另外,开始增加了一些功能插件,比如
OAuth2
,
MQTT
。我们这次就选择目前最新的3.11.10
版本。
RabbitMQ
是基于
Erlang
语言开发,所以安装前需要安装
Erlang
语言环境。需要注意下的是
RabbitMQ
与ErLang是有版本对应关系的。
3.11.10
版本的
RabbitMQ
只支持
25.0
以上到
25.2
版本的
Erlang
。这里要注意一下,如果使用CentOS
搭建
RabbitMQ
服务,
Erlang25.0~25.2
这几个版本建议的
CentOS
版本要升级到CentOS8或者
CentOS9
。
2
、安装
RabbitMQ
服务
接下来准备一台
CentOS9
服务器,快速搭建一个
RabbitMQ
服务。
RabbitMQ
服务安装的方式很多,现在企业级服务多偏向于使用
Docker
安装。
Duchub
上已经上传了当前版本的RabbitMQ
镜像。用以下
docker
指令可以安装。

但是这种方式相当于是官方将一个已经搭建好的环境给你用。这样不便于了解
RabbitMQ
的一些细节。因此我们这里会采用服务器直接安装的方式。
安装
RabbitMQ
之前需要先安装
Erlang
语言包
Linux
上的安装
Erlang
稍微有点复杂,需要有非常多的依赖包。简单起见,可以下载
rabbitmq
提供的
zero dependency版本。 下载地址
https://github.com/rabbitmq/erlang-rpm/releases
下载完成后,可以尝试使用下面的指令安装

这样
Erlang
语言包就安装完成了。 安装完后可以使用
erl -version
指令检测下
erlang
是否安装成功。

安装
RabbitMQ
RabbitMQ
的安装方式有很多,我们采用
RPM
安装包的方式。安装包可以到
github
仓库中下载发布包。下载地址:
https://github.com/rabbitmq/rabbitmq-server/releases
。 这里我们下载无依赖版本:rabbitmq-server-3.11.10-1.el8.noarch.rpm

安装完成后,可以使用常见的指令维护
RabbitMQ
的服务。

3
、启用
RabbitMQ
管理插件
RabbitMQ
提供了管理插件,可以快速使用
RabbitMQ
。在使用之前,需要先打开他的
Web
管理插件。


插件激活后,就可以访问
RabbitMQ
的
Web
控制台了。访问端口
15672
。
RabbitMQ
提供的默认用户是guest,密码
guest
。
但是注意下,默认情况下,只允许在
localhost
本地登录,远程访问是无法登录的。

这时,通常都会创建一个管理员账号单独对
RabbitMQ
进行管理。

这样就可以用
admin/admin
用户登录
Web
控制台了。
登录控制台后上方就能看到
RabbitMQ
的主要功能。其中
Overview
是概述,主要展示
RabbitMQ
服务的一些整体运行情况。后面Conections
、
Channels
、
Exchanges
和
Queues
就是
RabbitMQ
的核心功能。最后的Admin则是一些管理功能。

接下来可以尝试创建一个
Veirtual Hosts
虚拟机。

这里就创建了一个名为
/mirror
的虚拟机,并配置了
admin
用户拥有访问的权限。在
RabbitMQ
中,不同虚拟机之间的资源是完全隔离的。不考虑资源分配的情况下,每个虚拟机就可以当成一个独立的RabbitMQ
服务来使用。
管理页面的其他功能就不详细介绍了,后续随着深入使用再详细介绍
4
、理解
Exchange
和
Queue
Exchange
和
Queue
是
RabbitMQ
中用来传递消息的核心组件。我们可以简单体验一下。
1
、在
Queues
菜单,创建一个经典队列

创建完成后,选择这个
test1
队列,就可以在页面上直接发送消息以及消费消息了。

从这里可以看到,
RabbitMQ
中的消息都是通过
Queue
队列传递的,这个
Queue
其实就是一个典型的
FIFO的队列数据结构。而Exchange
交换机则是用来辅助进行消息分发的。
Exchange
与
Queue
之间会建立一种绑定关系,通过绑定关系,Exchange
交换机里发送的消息就可以分发到不同的
Queue
上。

队列
Queue
即可以发消息,也可以收消息,那旁边的
Exchange
交换机是干什么的呢?其实他也是用来辅助发送消息的。
进入
Exchanges
菜单,可以看到针对每个虚拟机,
RabbitMQ
都预先创建了多个
Exchange
交换机。

这里我们选择
amq.direct
交换机,进入交换机详情页,选择
Binding
,并将
test1
队列绑定到这个交换机上。

绑定完成后,可以在
Exchange
详情页以及
Queue
详情页都看到绑定的结果。

Exchange
交换机既然可以绑定一个队列,当然也可以绑定更多的队列。而
Exchange
的作用,就是将发送到Exchange
的消息转发到绑定的队列上。在具体使用时,通常只有消息生产者需要与
Exchange
打交道。而消费者,则并不需要与Exchange
打交道,只要从
Queue
中消费消息就可以了。
另外,
Exchange
并不只是简单的将消息全部转发给
Queue
,在实际使用中,
Exchange
与
Queue
之间可以建立不同类型的绑定关系,然后通过一些不同的策略,选择将消息转发到哪些Queue
上。这时候,Messaage上几个没有用上的参数,像
Routing Key ,Headers
,
Properties
这些参数就能派上用场了。
在这个过程中,我们都是通过页面操作完成的消息发送与接收。在实际应用时,其实就是通过
RabbitMQ提供的客户端API
来完成这些功能。但是整个执行的过程,其实跟页面操作是相同的。
渔与鱼
:
1
、页面上的这些操作,建议你一定要自己动手,到处尝试尝试。不要觉得能收发消息了,对RabbitMQ就掌握得差不多了。并且,多带上脑子来体验,收集你在使用当中的困惑,这样在后续学习过程中你会更有目标。比如Stream
类型的队列为什么不能在页面上获取消息?记住这个问题,后续在我给你分享队列类型时,你才有兴趣听得进去。
2
、之前说过
RabbitMQ
的这些操作几乎都有后台命令行工具与之相匹配。而后台的很多命令行也提供了丰富的帮助文档。借助页面控制台了解后台命令行的操作,也是一个不错的方式。比如我们之前使用rabbitmqctl adduser指令添加了
admin
用户。那添加虚拟机、添加队列、添加交换机这些也可以类似去了解。你只需要使用rabbitmqctl -help
就能看到大量的帮助文档。
5
、理解
Connection
和
Channel
这两个概念实际上是跟客户端应用的对应关系。一个
Connection
可以理解为一个客户端应用。而一个应用可以创建多个Channel
,用来与
RabbitMQ
进行交互。
我们可以来搭建一个客户端应用了解一下。
1
、创建一个
Maven
项目,在
pom.xml
中引入
RabbitMQ
客户端的依赖:

2
、然后就可以创建一个消费者实例,尝试从
RabbitMQ
上的
test1
这个队列上拉取消息。


执行这个应用程序后,就会在
RabbitMQ
上新创建一个
test2
的队列
(
如果你之前没有创建过的话
)
,并且启动一个消费者,处理test2
队列上的消息。这时,我们可以从管理平台页面上往
test2
队列发送一条消息,这个消费者程序就会及时消费消息。

然后在管理平台的
Connections
和
Channels
里就能看到这个消费者程序与
RabbitMQ
建立的一个
Connection
连接与一个
Channel
通道。

这里可以看到
Connection
就是与客户端的一个连接。只要连接还通着,他的状态就是
running
。而
Channel
是
RabbitMQ
与客户端进行数据交互的一个通道,没有数据交互时,状态就是
idle
闲置。有数据交互时,就会变成running
。在他们后面,都会展示出数据交互的状态。
另外,从这个简单示例中可以看到,
Channel
是从
Connection
中创建出来的,这也意味着,一个
Connection
中可以创建出多个
Channel
。从这些
Connection
和
Channel
中可以很方面的了解到
RabbitMQ
当前的服务运行状态。
6
、
RabbitMQ
中的核心概念总结
通过这些操作,我们就可以了解到
RabbitMQ
的消息流转模型。

这里包含了很多
RabbitMQ
的重要概念:
1
、服务主机
Broker
一个搭建
RabbitMQ Server
的服务器称为
Broker
。这个并不是
RabbitMQ
特有的概念,但是却是几乎所有MQ产品通用的一个概念。未来如果需要搭建集群,就需要通过这些
Broker
来构建。
2
、虚拟主机
virtual host
RabbitMQ
出于服务器复用的想法,可以在一个
RabbitMQ
集群中划分出多个虚拟主机,每一个虚拟主机都有全套的基础服务组件,可以针对每个虚拟主机进行权限以及数据分配。不同虚拟主机之间是完全隔离的,如果不考虑资源分配的情况,一个虚拟主机就可以当成一个独立的RabbitMQ
服务使用。
2
、连接
Connection
客户端与
RabbitMQ
进行交互,首先就需要建立一个
TPC
连接,这个连接就是
Connection
。既然是通道,那就需要尽量注意在停止使用时要关闭,释放资源。
3
、信道
Channel
一旦客户端与
RabbitMQ
建立了连接,就会分配一个
AMQP
信道
Channel
。每个信道都会被分配一个唯一的ID
。也可以理解为是客户端与
RabbitMQ
实际进行数据交互的通道,我们后续的大多数的数据操作都是在信道 Channel
这个层面展开的。
RabbitMQ
为了减少性能开销,也会在一个
Connection
中建立多个
Channel
,这样便于客户端进行多线程连接,这些连接会复用同一个Connection
的
TCP
通道,所以在实际业务中,对于
Connection
和
Channel
的分配也需要根据实际情况进行考量。
4
、交换机
Exchange
这是
RabbitMQ
中进行数据路由的重要组件。消息发送到
RabbitMQ
中后,会首先进入一个交换机,然后由交换机负责将数据转发到不同的队列中。RabbitMQ
中有多种不同类型的交换机来支持不同的路由策略。从Web管理界面就能看到,在每个虚拟主机中,
RabbitMQ
都会默认创建几个不同类型的交换机来。

交换机多用来与生产者打交道。生产者发送的消息通过
Exchange
交换机分配到各个不同的
Queue
队列上,而对于消息消费者来说,通常只需要关注自己感兴趣的队列就可以了。
5
、队列
Queue
Queue
是实际保存数据的最小单位。
Queue
不需要
Exchange
也可以独立工作,只不过通常在业务场景中,会增加Exchange
实现更复杂的消息分配策略。
Queue
结构天生就具有
FIFO
的顺序,消息最终都会被分发到不同的Queue
当中,然后才被消费者进行消费处理。这也是最近
RabbitMQ
功能变动最大的地方。最为常用的是经典队列Classic
。
RabbitMQ 3.8.X
版本添加了
Quorum
队列,
3.9.X
又添加了
Stream
队列。从官网的封面就能看到,现在RabbitMQ
主推的是
Quorum
队列。
三、章节总结
这一章节最主要的,就是了解
RabbitMQ
的基础消息模型,这是
RabbitMQ
最重要最核心的部分。而后续就是针对这个大的模型,逐步深入,了解RabbitMQ
的更多功能细节。
如果你之前已经使用过
RabbitMQ
,那么前面的操作你都可以忘记,但是最后这个大模型,你一定要先构建起来,并且可以尝试根据你的经验,看看可以往这个模型中添加一些什么内容。例如消息如何传递、销毁。Exchange
与
Queue
之间如何进行消息路由等等。而如果你之前没有使用过
RabbitMQ
,那么前面的这些操作你最好自己动手都试试,并且在管理页面上到处多点点,多试试RabbitMQ
的功能。不要说课上只创建了一个Queue
,那你也就照着创建一个
Queue
就完了。以可视化的方式构建起最后的消息模型,保证对于这个模型当中的各个重要概念的理解是准确的。
在这个章节中,我们只演示了
Consumer
端的示例代码,并没有演示
Producer
端的示例代码。但是,如果你熟悉了整个消息模型,也可以猜想得到Producer
端的代码应该怎么写。无非也是这几个关键的步骤:
1
、创建
Connection
2
、创建
Channel
3
、声明
exchange(
如果需要的话
)
4
、声明
Queue
5
,发送消息,可以发到
Exchange
,也可以发到
Queue
。
例如一个简单的发送者如下:

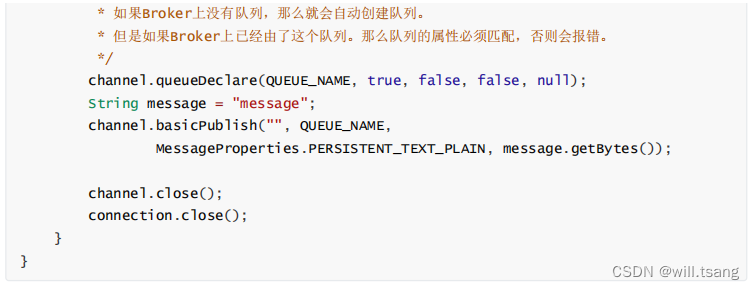
你看,整个流程跟消费者是不是差不多的?除了生产者发送完消息后需要主动关闭下连接,而消费者因为要持续消费消息所以不需要主动关闭连接,其他流程几乎完全一样的。