目录
判断题💖
1-1 希尔排序是稳定的算法。F
1-2 在散列表中,所谓同义词就是具有相同散列地址的两个元素。 T
1-3 对AVL树中的任一结点,其左、右子树的高度一定是一样的。 F
1-4 任何最小堆中从根结点到任一叶结点路径上的所有结点是有序的(从小到大)。 T
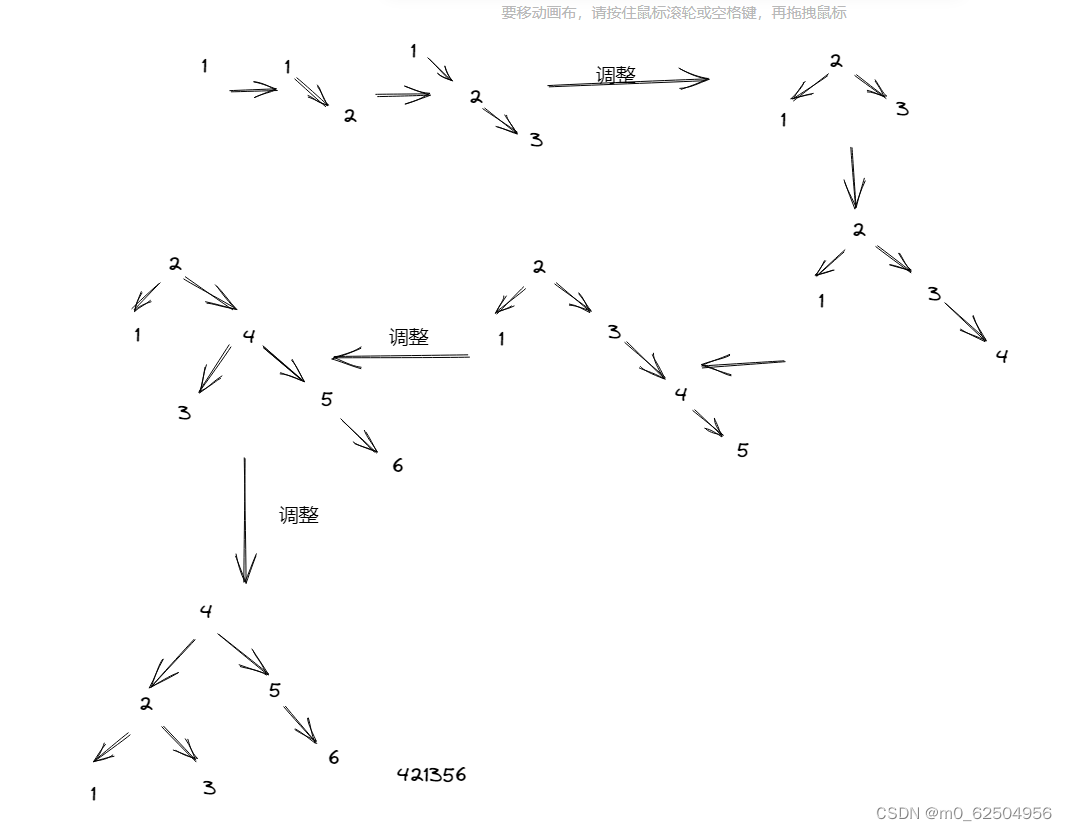
1-5 将1、2、3、4、5、6顺序插入初始为空的AVL树中,当完成这6个元素的插入后,该AVL树的先序遍历结果是:4、2、1、3、5、6。 T
1-6 将N个数据按照从小到大顺序组织存放在一个单向链表中。如果采用二分查找,那么查找的平均时间复杂度是O(logN)。 F
1-7 任何二叉搜索树中同一层的结点从左到右是有序的(从小到大)。 T
1-8 在一棵二叉搜索树上查找63,序列39、101、25、80、70、59、63是一种可能的查找时的结点值比较序列。
1-9 对N个不同的数据采用冒泡排序进行从大到小的排序,当元素基本有序时交换元素次数肯定最多。 F
1-10 要从50个键值中找出最大的3个值,选择排序比堆排序快。 T
选择题💝
分享🥰:
每一个优秀的人背后都有一段沉默的时光,那是付出很多努力却不一定有结果的日子,我们把它叫做扎根。🌟
判断题💖
1-1 希尔排序是稳定的算法。F
在排序过程中是根据步长将原始数据进行分组,这样就可能会导致相同的元素分到不同组,在最终排序时就不能保证原来两个相同元素的顺序啦,所以希尔排序是不稳定的。
1-2 在散列表中,所谓同义词就是具有相同散列地址的两个元素。 T
同义词为映射到同一散列地址的关键字。
1-3 对AVL树中的任一结点,其左、右子树的高度一定是一样的。 F
不一定是一样的,左右子树高度差小于等于1,也就是为0和1时就满足AVL树的性质
1-4 任何最小堆中从根结点到任一叶结点路径上的所有结点是有序的(从小到大)。 T
最小堆堆顶最小,从堆顶向下走呈递增顺序,即从小到大
1-5 将1、2、3、4、5、6顺序插入初始为空的AVL树中,当完成这6个元素的插入后,该AVL树的先序遍历结果是:4、2、1、3、5、6。 T
1-6 将N个数据按照从小到大顺序组织存放在一个单向链表中。如果采用二分查找,那么查找的平均时间复杂度是O(logN)。 F
二分查找的平均复杂度是O(logN),用在数组上。而链表是不能用二分查找的,链表只能顺序访问,顺序查找
1-7 任何二叉搜索树中同一层的结点从左到右是有序的(从小到大)。 T
二叉搜索树又称二叉排序树,具有左子树上的结点都小于根节点,右子树上的点都大于根节点,从左到右即从小到大
1-8 在一棵二叉搜索树上查找63,序列39、101、25、80、70、59、63是一种可能的查找时的结点值比较序列。
假设按照先序遍历,39为根节点,剩下的为左右子树,但101比39大,所以这棵树没有左子树,剩下的均在右子树,比39大,但是又存在25比39小,所以矛盾
1-9 对N个不同的数据采用冒泡排序进行从大到小的排序,当元素基本有序时交换元素次数肯定最多。 F
每进行一趟冒泡排序,最值都在后面位置依此排列,当元素基本有序时,交换次数会少
1-10 要从50个键值中找出最大的3个值,选择排序比堆排序快。 T
选择排序每次都会找出剩余序列的最值,所以选择排序之后进行三次
选择排序的时间复杂度为 O(n^2),空间复杂度为 O(1) 堆排序的时间复杂度为 O(n log n),空间复杂度为 O(1) 如果你只需要从 50 个键值中找出最大的 3 个值,使用选择排序可能会更快,因为它的时间复杂度比堆排序要低。但是,如果你需要对整个数组进行排序,使用堆排序可能会更快,因为它的时间复杂度比选择排序要低。
选择题💝

在最坏情况下,二分查找需要比较 log2(n) 次,其中 n 是数组的大小。因此,在从 100 个有序整数中查找某数的情况下,二分查找最坏情况下需要比较 log2(100) = 7 次。

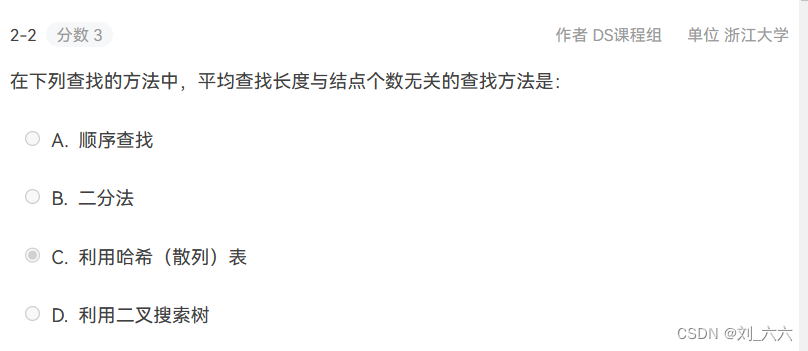
哈希表查找的时间复杂度为 O(1),空间复杂度为 O(n),其中 n 是表中的结点个数。
哈希表查找的平均查找长度与结点个数无关,这是因为哈希表查找的时间复杂度是常数级别的,与结点个数无关。
其他查找方法的平均查找长度与结点个数有关,例如:
- 顺序查找的平均查找长度为 (n+1)/2,其中 n 是结点个数。
- 二分查找的平均查找长度为 log2(n),其中 n 是结点个数。
- 折半查找的平均查找长度为 log2(n),其中 n 是结点个数。
- 分块查找的平均查找长度为 sqrt(n),其中 n 是结点个数。
- 二叉排序树查找的平均查找长度为 log2(n),其中 n 是结点个数。

在将 10 个元素散列到 100000 个单元的哈希表中时,有可能不会产生冲突。这取决于哈希函数的质量以及散列表的大小。如果哈希函数质量较高,则可能会将 10 个元素散列到不同的单元中,不会产生冲突。如果哈希函数的质量较差,则可能会出现冲突,导致查找效率降低。因此,在使用哈希表时,需要选择一个质量较高的哈希函数。

在查找不成功的情况下,二分法至少需要比较 log2(10) = 3 次。二分查找,可以用二叉判定树,查找不成功的次数不超过判定树的深度,而树的深度为|_log2n_|+1

A.36比30大 但36后面的28比30小
B.48比38大,但48后面的28比38小
C.18比48小,18后面的均比48小;38比18大,38后面的比18大;28比38小,在38的左子树上找到28啦 binggo~ 符合
D.30比60小,30后面的均比60小;50比30大,50后面的均比30大;40比50小,40后面的均比50小;38比40小,38后面的比40小,36比38小,emmmm没啦 28没出现耶,木有找到

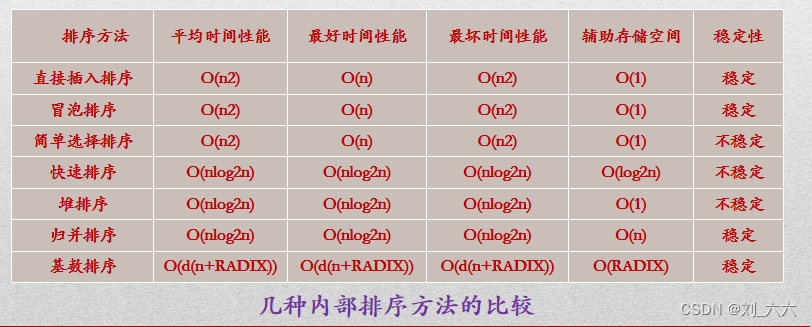
例如从小到大插入排序,最后一个插入的是最小的元素,此时最后一次前所有的数都不在正确的位置上。 其他几种排序每次循环都会确认至少一个元素的正确位置,所以不可能出现这种情况

题中所给的三趟排序过程中,每一趟排序是从前往后依次比较,使最大值“沉底”,符合冒泡排序的特点。
看第一趟可知仅有88被移到最后。
l 如果是希尔排序,则12,88,10应变为10,12,88。因此排除希尔排序。
l 如果是归并排序,则长度为2的子序列是有序的。因此可排除归并排序。
l 如果是基数排序,则16,5,10应变为10,5,16。因此排除基数排序。
提示:对于此类题,先看备选项的排序算法有什么特征,再看题目中的排序过程是否符合这一特征,从而得出答案。一般先从选项中的简单排序方法(插入排序、冒泡排序、选择排序)开始判断,若简单排序方法不符合,再判断排序方法(希尔排序、快速排序、堆排序、归并排序)。


1. 49 76 2. 38 13 3.65 27 4.97 50 49 13 27 50 76 38 65 97 ->B

分享🥰:
每一个优秀的人背后都有一段沉默的时光,那是付出很多努力却不一定有结果的日子,我们把它叫做扎根。🌟