01 预训练语言模型 VS 预训练对话模型
1. 大规模语言模型
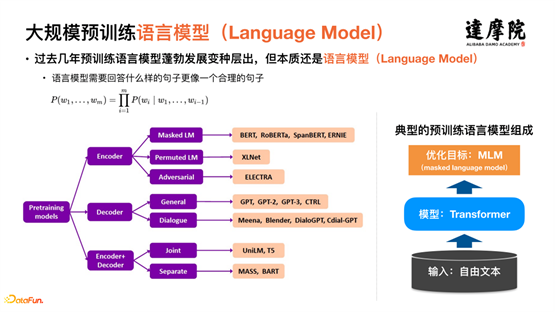
过去几年 NLP 领域的重大进展,主要是大型预训练模型出现与大规模使用。预训练语言模型有了很大的发展,出现了很多变种。但是,本质上都还是语言模型,如上图右边的流程图所示,输入基本上为网络上的自由文本,模型基本上都是 Transformer 结构,优化的目标基本上都是 MLM(掩码语言模型)。

预训练语言模型对整个 NLP 领域带来巨大进步,到了对话领域之后,可以进一步地提取对话领域更为独特的特征。如上图所示,左侧的网络上的自由文本为大规模预训练模型所需要的语料,右侧的表示对话的语料,直观上看,已经有很大的不同。

对话是对语言的高级应用,主要有以下几个特点:
①口语化,表述随意,不一定符合语法、句子不完整、噪音较多、有很多 ASR 错误。
②分角色多轮次,至少两个参与主体,轮次间存在省略、指代、状态继承、状态遗忘等。
③垂直知识约束,每个对话任务有自己的知识约束,模型需要针对性地利用起来。
④深层语义理解,需要深入理解语言,Intent-Slots/ 逻辑推理等等。
⑤讲究对话策略,为完成特定任务目标,需要知道应该怎么说。
2. 预训练语言模型 VS 预训练对话模型
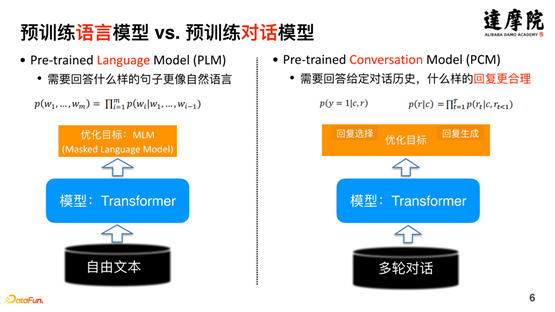
基于对话数据独有的特点,在预训练模型的基础上,发展出独特的预训练对话模型。如上图左侧表示的预训练语言模型,其优化的目标是回答什么样的句子更像自然语言;而上图右侧表示的是预训练对话模型,从端到端的角度看,其优化的目标是需要回答给定对话历史,什么样的回复更合理。这就是预训练语言模型与预训练对话模型的一个很大的不同点。
3. 预训练对话模型进展
对话主要分三块:对话理解、对话策略、对话生成。2021 年初,预训练对话模型已经有了较多发展。如下图所示,对话理解领域,2019 年 PolyAI 提出了 ConveRT 模型、2020 年 Salesforce 提出了 TOD-BERT 模型、2021 年 JingDong 提出了 DialogBERT 模型。


面向理解的预训练对话模型的出现,对于对话理解方面,相对于预训练语言模型,带来了巨大的提升,如上图所示,EMNLP2020 上的一篇文章(Probing Task-Oriented Dialogue Representation from Language Models)的实验结果,表明预训练对话模型和预训练语言模型相比,在对话理解任务上,可以提升 10% 以上的效果;在表征学习上,也能学到更好的表示,有更好的聚类效果。这一点可以通俗地理解,因为当前的预训练模型(包含语言与对话模型)本质上是数据驱动出来的,那么,对话数据训练的预训练模型,自然比从自由文本上训练出来的模型在对话领域更具表现力。

除了对话理解以外,还有一块是对话生成领域。
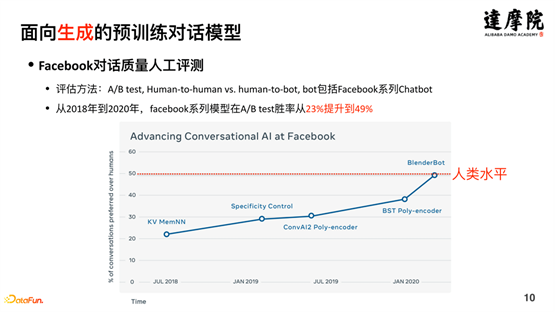
2019 年 Microsoft 提出了 DialoGPT、2020 年 Google 提出的 Meena、2020 年 Facebook 提出的 Blender、2021 年 Baidu 提出的 PLATO-2 等,这些模型的出现的话,对对话生成方面的质量也带来了很大的提升。如下图所示,Facebook的Blender模型,从 2018 年到 2020 年,在 A/B Test 胜率从 23% 提升到了 49%。
以上是对整个预训练对话模型的简单介绍,对理解本文提出的模型有很大的帮助。总体上,预训练语言模型的出现,大幅度提升了 NLP 所有任务的效果,而基于预训练语言模型的预训练对话模型,进一步提升了对话领域的 NLP 任务的效果。所以,基于预训练对话模型的智能对话已经成为一个基座模型。
--
02 “无知识不对话”:知识是对话的基础
对话还有一个非常大的特点,就是强依赖于知识。换而言之,知识是对话的基础。
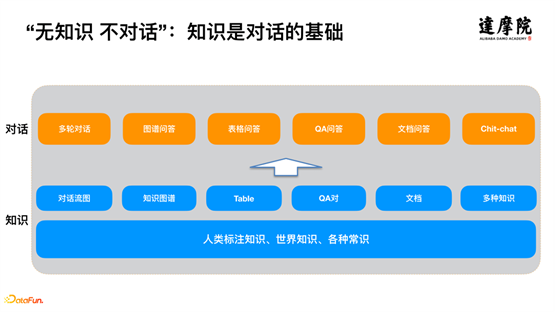
由上图的对话体系架构可以看出,上层的主流对话引擎,比如多轮对话、图谱问答、表格问答、QA问答、文档问答、闲聊(Chit-chat)等,其划分的依据就是底层知识的不同。举例而言,多轮对话引擎,主要是基于对话流程图;图谱问答,依赖于知识图谱的知识等。除了这些显著的知识,想要做好智能对话,还需要一些其他的知识,比如人类标注知识、世界知识、各种常识等。
这里以一个办理汽车保险的任务为参考案例。这个任务是一个流程类的任务,即办理一个保险是有步骤,有流程的。首先,校验个人和证件信息,包括身份证、驾驶证、行驶证等;然后开始验车,生成验车结果:如果验车结果不通过,则告知验车不合格原因,流程结束,结果为不能办理汽车保险;如果验车结果通过,则进行后续步骤,填写保单,包括车险险种、被保险人信息等,然后交保险费,并获得保险存根。
这是一个典型的流程类任务,需要通过任务型对话进行处理。流程类知识的一个显著特点,大多是情况下,任务的顺序是不可变的。比如,不能先做第三步,再做第一步,这样整个流程是不对的,执行不下去的。流程类知识的第二个特点就是,流程类知识打开每一步看的话,又包含了很多其他的知识。比如第一步,要校验个人和证件信息,比如姓名,对于中国人,基本上都是汉字,而且字数都在 2-10 个字以内,这些属于世界知识或基本常识,以及身份证号,大陆身份证都是 18 位的等,都是世界知识里面的范畴。而且,为了训练出一个可用的任务型对话,需要一定量的标注数据,而这些标注的数据,蕴含了人类的知识。比如意图、类别,以及情感等的标注,都是将人类的知识,显式的写在了数据上,从而形成新的知识。综上所述,整个对话都是围绕知识展开的,无知识,不对话。
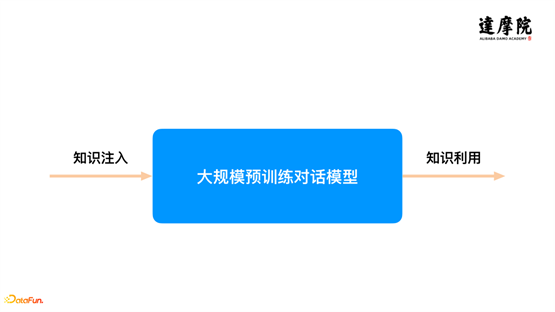
前面做了基本的引入和介绍,一方面,针对智能对话,预训练对话模型已经成为基础模型;另一方面,对于整个对话系统来讲,都是围绕着知识展开的。所以,我们(达摩院 Conversational AI 团队)过去一段时间的研究和探索,都是围绕着这两点展开。主要的思路是将知识和预训练对话模型结合起来。具体来看,如上图所示,将任务拆成两个子任务:一个子任务是我们如何把知识注入到预训练对话模型,让模型有更好的知识容量;另一个子任务,在应用方面,将在预训练对话模型中学到的大量的知识,显式地抽取出来,和下游任务更好的结合和使用。围绕这两个方面,本文将重点分享一些探索性的工作。
--
03 半监督预训练:一种新的知识注入方式
1. 标注知识

第一部分主要关于知识注入。如何将知识注入到模型中,本文提出一种新的方式,半监督预训练方式。

首先回顾一下知识。知识中有一种非常重要——标注知识。离开标注知识,很难将 NLP 任务做好。在人工标注的知识中,包含大量任务相关的知识。示意图分类、意图匹配、实体识别、对话策略、情感等,这些标签数据,都是将人类的知识,显式地表现在数据上。人工标注的知识有如下特点:
第一,对提升具体任务效果至关重要,虽然现在 Few-Shot 等小数据量标注很热门,但是,这种不需要标注数据或者少量标注数据的模型,尚未满足业务上线的要求,所以,标注数据对于提升任务作用非常大;
第二, 任务相关,数据分散。即在A任务上标注的数据,在 B 任务上并不能使用,需要重新标注;
第三,总量较小。相对于无监督数据往往几千万,几亿条,有标注的数据,可能只有几百条、几千条等。
如何将这些分散的标注数据,汇总到一块,将其中蕴含的知识,注入到预训练对话模型,提高模型的能力?本文即针对这个问题进行了研究和探索。如果可以实现这样的操作,即可实现知识迁移,将在A任务标注的数据的知识,用到B任务上,从而提升B任务的效果。好处如下:第一,解决冷启动问题;第二,在达到相同准确率的情况下,需要的标注数据更少。
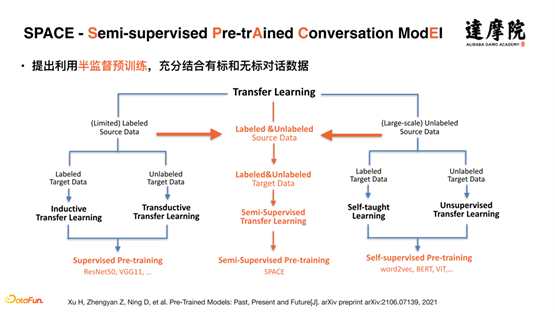
首先,回顾一下预训练模型的发展。预训练模型在图像领域首先使用,而且是基于有监督的数据。而当 Bert 等预训练模型提出后,开始从大量的无监督数据中进行预训练,即通过自监督学习。预训练模型以前有两种手段:一个是对有监督数据进行监督学习;另一个是对无监督数据进行自监督学习。今天面对的任务是大量的无监督数据和小量的有监督数据,我们提出了半监督学习,通过半监督的方式,将有监督数据和无监督数据结合起来,如上图所示,我们提出了一个 SPACE(Semi-supervised Pre-trAined Conversation ModEl)模型。
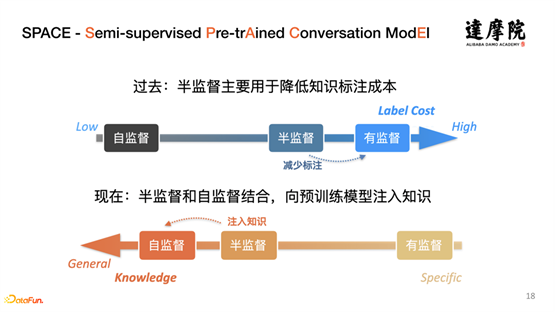
半监督的概念已将发展很多年了,这里提出的半监督方式和以前的半监督方式是有所不同的,主要区别在于:过去,半监督将半监督和有监督结合一起,用于降低知识标注成本;现在,我们主要是半监督和自监督结合,向预训练模型注入知识。
2. 预训练对话模型发展

基于我们提出的半监督模型的理念和框架,再来看一下预训练对话模型的进展。如何将半监督的思想融入到预训练对话模型,在一个具体的业务场景进行实验和落地。由上图可以知道,围绕着对话理解和对话生成,有很多机构做了很多的模型,但是对于对话策略做的非常少,基本上没有相关研究。但是,对话策略非常的关键和重要。

那么,什么是对话策略?在对话理解和对话生成之间,存在着对话策略。对话策略就是根据对话理解的结果,以及结合历史的状态,来决定如何回复下一句话。
举例而言,两个人 A 和 B,在对话过程中,A 不断地说,B 可以一直回复,嗯,好的,对对。这就是一种对话策略,B的策略表示我在听,我听懂了。还有一种策略,B 在听的过程中,有部分听不懂,需要反问其中某个点等;以及对于 A 说的某些地方有些疑问,进行澄清等,也是一种策略。所以,对话策略是保证一段对话可以顺利进行很关键的一步。
学术界对对话策略的定义是 DA(Dialog act),由上图所示,在不同时间,DA 的定义与名称不尽相同,整个对话策略虽然发展了很多年,但是存在复杂和不一致等缺点。导致今天应用起来比较麻烦。
3. 准备工作
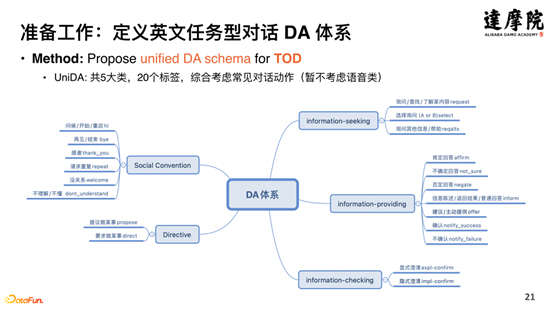
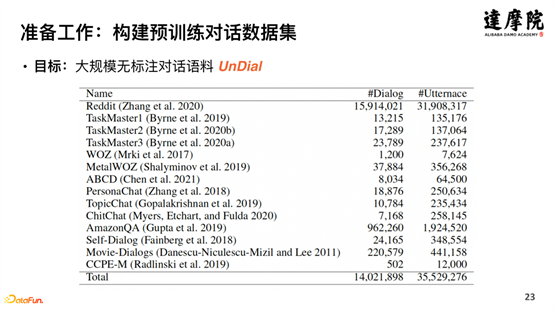
将对话策略作为知识注入到预训练对话模型,需要在数据和知识层面做一些准备工作。如上图所示,将英文开源数据集进行综合,形成英文任务型对话 DA 体系——UniDA,共 5 大类,20 个标签,100 万份有标注的数据,3500 万的无标注数据,如下图所示:

整理好以上知识之后,如何定义预训练的任务?如上图所示,选用的是显式建模对话策略,即给定对话历史,预测下一轮系统端的 DA,即做成分类任务,预测下一轮的 DA 标签。
4. 半监督方案设计

有了数据,有了知识,有了显式建模方式,就可以进行半监督的学习。如上图所示,半监督学习的方案主要由以上三种方式:判别式方法、生成式方法、对比学习方法等。
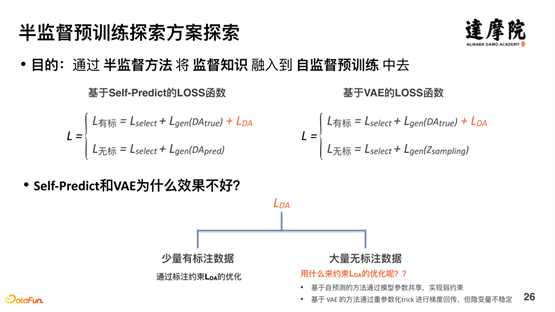
由于判别式方法和生成式方法比较常规,所以先对以上两种方法进行探索。结果表明以上两种方式做出来的效果并不好。如上图所示,针对判别式的方法,对有标数据,可以新加一个损失函数 LDA ,但是对于无标数据,无法添加损失函数。针对生成式的方法,也是同样的道理。即 Self-Predict 和 VAE 的方法,对于有标数据建模是不错的,但是对于无标数据的建模效果不好,因为基于⾃预测的⽅法通过模型参数共享,实现弱约束,基于 VAE 的⽅法通过重参数化 Trick 进⾏梯度回传,但隐变量不稳定。
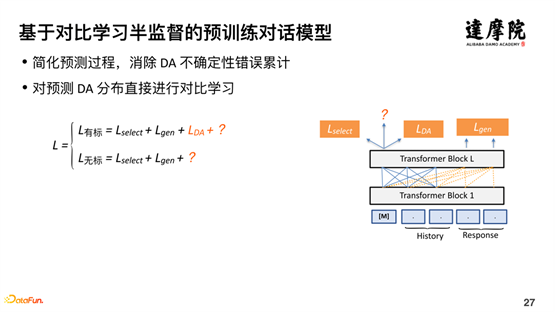
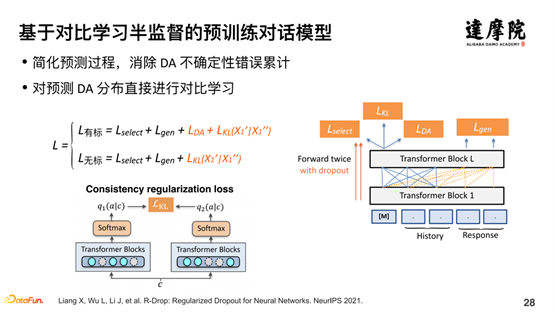
基于上述问题,我们希望通过对比学习,进行半监督学习的探索。针对有标数据可以轻松地加上 LDA 损失函数,而针对无标数据如何做,这里引入一致性损失函数。如上图,我们对同一个样本,过两遍图右边的模型结构,每一遍都有 Dropout 进行随机处理,所以,两次的样本编码不一致,但是,相差不会很远,距离应该很近。整体思想如下:
基于少量的有标数据和大量的无标数据,通过有标数据学习一个支持的概率分布,对于无标数据,进行两次学习,每次过模型都生成一个向量,这两次生成的向量的距离,应该是很近的。通过这种对比学习的半监督学习方式,很好地解决了半监督学习有标数据和无标数据结合的问题。
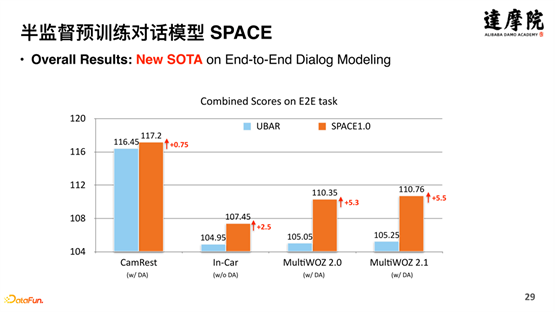
模型的效果非常好,在 MultiWOZ2.0 和 MultiWOZ2.1 实现了 5.3% 和 5.5% 的提升。以前的模型提升只能在 1% 或者 2% 的提升,而 SPACE 带来了 5% 以上的提升。

拆开细看,以 MultiWOZ2.0 为例,模型的提升主要体现在 Success 和 BLEU 等方面,因为对话策略对于 Success 对话完成率和 BLEU 对话回复生成至关重要,这说明通过半监督,模型很好地学会了这类知识。
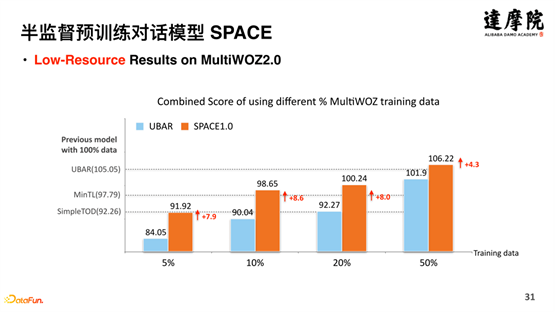
除了对全量数据的测试,也在少量数据进行了测试,如上图所示,分别在 5%、10%、20%、50% 等数据量上进行了对比实验,可以发现 SPACE 模型在不同数据量上也带来了显著的提升。
以上主要讲解我们提出的知识注入的方式,半监督训练 SPACE 模型,在预训练上面显著提高预训练模型的效果。
--
04 Proton:预训练模型中知识利用的探索
接下来,讲解预训练模型中的知识利用。因为预训练模型是经过海量的数据进行训练的,里面包含了海量的知识,如果可以将其中的知识进行利用,无疑会对 NLP 任务提供很大的帮助与提升。我们提出了一种方法——Probing tuning。
1. TableQA 任务

想要验证知识的作用,需要知识密集型的任务,如上图,TableQA 任务非常合适,TableQA 核心任务即是将文本语言转换成 SQL。
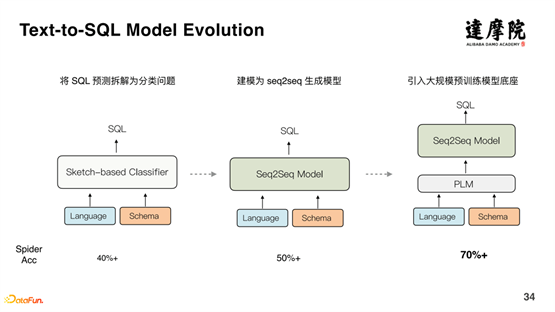
上图表示的是 Text-to-SQL 的发展历程。初始的时候,将 SQL 预测拆解为分类问题,准确率在 40% 左右;后来使用 Seq2Seq 生成模型,准确率提升到 50% 以上;进一步地,引入大规模预训练模型,准确率提升到 70% 以上。因此,可以看出,预训练对话模型,对整个对话系统的提升非常显著。但是仍然存在一定的问题。

以 Spider 数据集为例,在标记 Spider 数据集的同时,他们是看到数据集的,导致他们在编写数据集的时候,所用到的词汇,都是存在原文中的词汇。缺少同义变化和世界知识等。比如,在购买家居场景,有一种沙发的型号为L型,是一种官方术语,而对于用户,或者消费者而言,他们并不知道L型沙发是什么,他们只知道“贵妃椅”。而“贵妃椅”是L型沙发的俗称。因此,有人在 Spider 数据集上进行了同义词改造,构建了新的数据集Spider-Syn,则原来的模型在新的数据集上效果显著下降。
除了同义词问题外,上图右边提到的,“… in African countries that are republics?”即非洲共和制国家有哪些?Republics,这个单词是“共和制”的意思,而这个含义,模型无法从数据中学习到,需要世界知识。

一般情况下,预训练模型的使用方法有以上两种:Fine Tuning 和 Prompt Tuning。对于 Fine Tuning 而言,直接将预训练模型作为下游任务的表征,大多数任务都可以利用预训练模型的能力,但预训练模型和下游模型有很大的 GAP。简单而言,预训练模型的知识很多,而下游任务只能获取很小的一个出口进行输出,无法充分获取知识表达。对于 Prompt Tuning 模型,通过改变预测的方式来提升效果,最近在分类任务上崭露头角,尤其在小样本情况下。但是,如何用到更复杂的任务?比如 Parsin,效果却不太好。综上所述,通过训练出大型的预训练模型学到了的大量的知识,但是在下游任务上却无法进行很好的使用。
2. Probing Tuning 方法
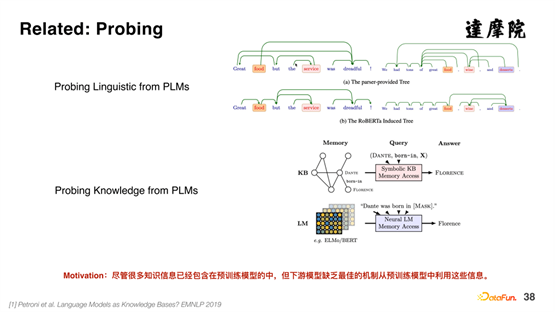
围绕大型预训练模型的知识使用,也有很多的研究,整体上被称为 Probing。Probing 可以从预训练模型中探索出句法结构、依存结构等,也可以从预训练模型中探索出三元组等知识。但是,如何将预训练模型中的知识,显式地表示出来,并结合下游任务,目前的相关工作相对比较少,我们就在这方面提出了一种新的 Finetune 方式——Probing Tuning 方法。
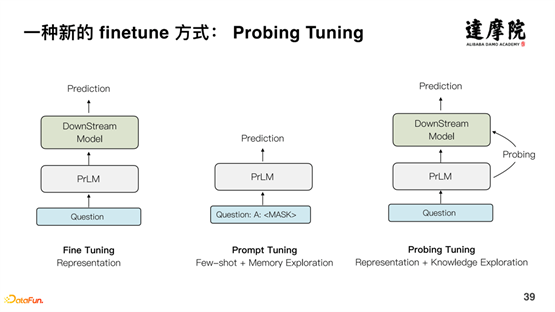
如上图所示,Prompt Tuning 方法是基于模板进行训练,本质上是通过记忆表达的方式加上少量的数据,对模型进行微调。而我们提出的 Probing Tuning 方式,原始的问题通过预训练模型得到稠密向量表达,并且,通过 Probing 的方式,获取知识的结构表达,输入到稠密向量表示中,对下游任务带来提升。
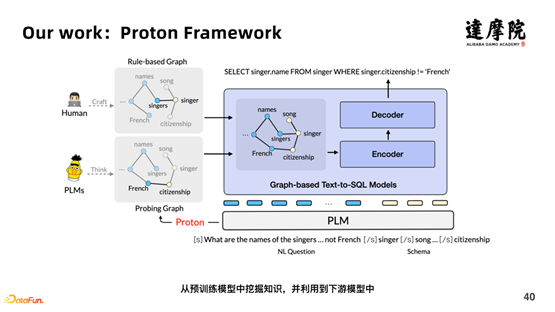
如上图所示,我们提出了一个框架——Proton Framework。首先,输入预训练模型的数据包含原始问题和表格对应的语句;另一方面,也包含了人类定义的规则的知识,不具有泛化性的知识;并且,通过 Proton 的方式,学习到知识的表达,并具有泛化性。

具体Probing的工作原理以上面的例子说明。
问句为:“Where is the youngest teacher from?,表格数据为“SELECT hometown FROM teacher ORDER BY age ASC LIMIT 1”。原句抽取出表格数据中的名词信息,“teacher,teacher.age, teacher.hometown”,组合成整体:“[CLS]Where is the youngest teacher from?[SEP] teacher,teacher.age,teacher.hometown”。然后进行随机 MASK 某个单词,比如“where”,然后计算该向量中“teacher.hometown”与原句向量的“teacher.hometown”距离,如果距离越远,这说明“where”和“teacher.hometown”越相似,即学到相关的知识。如上图的相关矩阵表示,“teacher.age”和“youngest”相关度有 0.83,非常的高,说明两者有非常强的相关性。然后就可以构建 Proton 中的图以及边的权重等。
以上即为 Probing 的整个过程,即将人工构建的知识和 Proton 学习到的知识,结合到预训练模型中,用以提高下游任务的效果。
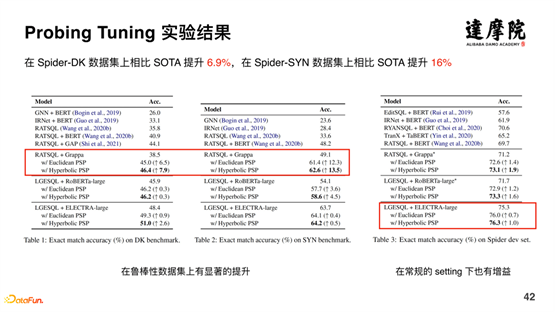
基于 Probing Tuning 的方法,在 Spider-DK 数据集上相比 SOTA 提升了 6.9%,在 Spider-SYN 数据集上相比 SOTA 提升 16%,效果提升非常明显。
总而言之,我们通过把预训练模型学到的知识,进行探测,并且以结构化的方式,显式的应用到下游模型中去,可以给具体的下游任务,带来显著的提升。
3. 后续工作展望

Probing 技术可以带着我们进行下一步探索,如何将预训练模型中的知识,显式地获取出来。在此领域,AlphaZero 做了相关探索,如上图左侧,左右两边分别表示人和模型自动学习出来的向量空间,模型学到了一些人类从未有的棋谱,说明模型可以学到人类并不知道的一些知识。
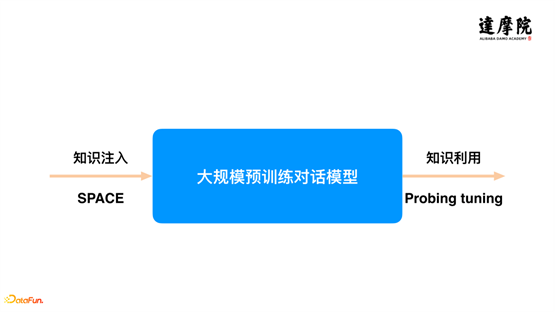
我们今天先讲了预训练对话模型对于整个对话系统的重要性;其次,是知识在对话系统中的重要性。基于以上两点,我们希望将知识和预训练对话模型结合一起,具体的分为两个工作:
第一,如何将知识注入到预训练对话模型,我们提出了一个半监督预训练的模型——SPACE。
第二,如何将预训练对话模型中的知识显式地提取和利用起来,我们提出了一个 Proton 的模型。
--
05
Q&A 环节
Q1:半监督预训练模型的监督任务,是否需要和下游任务保持一致?比如说预训练模型中的一些意图分类任务?
A1:现在所做的半监督预训练,还是面向与下游任务的预训练。即面向下游任务的半监督学习。当然,我们现在也在探索多任务的下游任务训练,探索多任务之间是否可以加强相关的任务效果。
Q2:Unified DA 是否考虑了无意义的语句等?
A2:是有的,在分类里面,是存在有不理解/不懂的语句在里面的。
Q3:Act 和 Intent 的区别是什么?
A3:Intent 是一个具象的事情,和一个具体任务相关的,比如说,你要办公积金,在这个场景,可以定义 5 个 Intent;在购买飞机票的场景,可以定义 10 个 Intent。这两个场景的 Intent 之间基本上没有关系。而 Act 是超越具体场景的,比如公积金和订机票场景,可以定义共同的 Act,比如显示澄清、隐式澄清等,都是和具体场景无关的。Act 和 Intent 都是对语义的表示,Intent 是具象层面的表示,Act 是抽象层面的表示。
Q4:数据集都是英文的,后续是否考虑中文的一些探索吗?
A4:我们团队是一个研究和业务共同并重的团队,我们的中文和英文是同步做的,今天主要分享的是英文的模型,而中文的模型我们这边是已经做好,并且在阿里云智能客服产品中全面落地应用,成为对话系统的基座,以意图分类为例,基于 SPACE 的训练样本数据标注量降低了 70% 左右。今天只是分享我们最早期和最经典的工作,后续会分享中文相关的工作。
Q5:SPACE 中,端到端的模型如何和 NLG 结合的?
A5:端到端模型分为三个部分:理解、策略和生成。对于生成任务,是基于理解和策略的概率分布,即前面的 Act 预测准的话,后续的生成任务也会更准。