一、什么是kafka?
是分布式(项目部署于多个服务器)的基于发布/订阅模式的消息队列,主要用于处理活跃的数据,如:登录、浏览、点击、分享等用户行为产生的数据,说白了就是一个消息系统(消息队列)。
进一步理解:
1.消息队列
消息(Message):网络中的两台计算机或者两个通讯设备之间传递的数据,如:文本、音频等。
队列(Queue):直接把它想象成羽毛球筒,羽毛球先进先出,是一种特殊的线性表,特殊之处在于,只能在头部删除元素,在尾部添加元素。
消息队列(MQ):保存消息的队列,相当于消息传输过程中的一个容器,主要有两个作用,一个是给外部提供存入消息的接口,另一个是提供取出消息的接口。
保存消息的队列,是消息在传输过程中的容器。主要提供生产和消费接口供外部调用,进行数据的存储和获取。
二、MQ的分类
1.主要有两大类:点对点(Peer-to-Peer)、发布/订阅(Publish/Subsribe)。
2.共同点:生产消息发送到队列中,消费者从队列中读取并消费消息。
3.不同点:
(1)点对点
组成:消息队列、发送者(Sender)、接受者(Receiver)。
注:一个生产者生产的消息只能有一个消费者消费,一旦被消费了,消息就不会存在于消息队列中。
(2)发布/订阅
组成:消息队列、发布者(Publisher)、订阅者(Subscriber)、主题(Topic)
注:每个消息可以有多个消费者,彼此互不影响,如:我在微信公共号发了一篇文章,关注我的人都能看到,即消息被多个人接受到(订阅者)。
三、常见的消息系统
ActiveMQ:实现了JMS(Java Message Service)规范,支持性较好,性能相对不高。
RabbitMQ:可靠性高、安全。
Kafka:分布式、高性能、跨语言。
RockeMQ:阿里开源的消息中间件,纯Java实现。
四、kafka特性
1.高吞吐量、低延迟:每秒可以处理几十万条消息,其延迟只有几毫秒,每个主题可以分多个分区,消费组对其分区进行消费。
2.可扩展:集群支持热扩展。
3.持久性、可靠性:可以持久化到本地磁盘,支持数据备份防止数据丢失。
4.容错性:允许节点中节点失败。
5.高并发:支持数千个客户端同时读写。
五、kafka的组成
1.Broder:kafka集群中包含多个kafka服务节点,每个kafka服务节点就是一个broker。
2.Topic:主题(相当于消息的类型),用来存储不同类别的消息(kafka消息数据村存放于硬盘)。
3.Partition:分区,每个Topic可以包含一个或多个分区,分区的数据量是在创建主题时决定的,
目的在于进行分布式存储。
4.Replication:副本,每个分区可以有多个副本,分布在不同的Broker上,会选出一个副本呢作为Leader,所有请求都会通过Leader完成,Follower只负责备份数据。
5.Message:消息,是通信的基本单位,每个消息都存于Partition。
6.Producer:消息的生产者,向topic发布消息。
7.Consumer:消息的消费之,订阅topic并读取其发布消息。
8.Consumer Group:每个Consumer属于一个特定的Consumer Group,多个Consumer可以属于同一个Consumer Group中。
9.Zookeeper:协调kafka正常运行,同时存储kafka元数据信息如,topic的数量等。注:发送给Topic本身的数据不是存在Zookeeper中,而是存在于磁盘文件中。

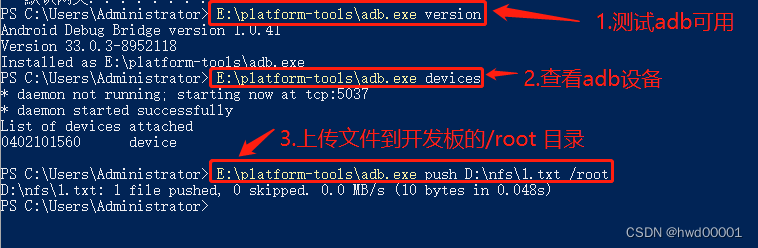
六、kafka的安装和配置
1.安装
1.解压kafka_2.12-2.3.0.tgz
cd ~/software tar -zxf kafka_2.12-2.3.0.tgz
2.配置
# 创建存放数据的文件夹 cd kafka_2.12-2.3.0 mkdir data # 修改kafka配置文件 cd config vi server.properties #listeners=PLAINTEXT://:9092 # kafka默认监听的端口号为9092 log.dirs=../data # 指定数据的存放目录 zookeeper.connect=localhost:2181 # zookeeper的连接信息
3.启动zookeeper
使用kafka内置zookeeper
cd ~/software/kafka_2.12-2.3.0/bin/ ./zookeeper-server-start.sh ../config/zookeeper.properties
4.使用外部zk(推荐)
cd ~/software/zookeeper-3.4.13/bin/ ./zkServer.sh start
5.启动kafka
./kafka-server-start.sh ../config/server.properties & # &表示后台运行,也可使用-daemon选项 jps # 查看进程,jps是jdk提供的用来查看所有java进程的命令
6.创建Topic(主题)
./kafka-topics.sh \ --create \ --zookeeper localhost:2181 \ --replication-factor 1 \ --partitions 3 \ --topic hello
# 查看Topic列表 ./kafka-topics.sh --list --zookeeper localhost:2181 # __consumer_offsets是kafka的内部Topic # 查看某一个具体的Topic ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic hello # 修改Topic:只能增加partition个数,不能减少,且不能修改replication-factor ./kafka-topics.sh --alter --zookeeper localhost:2181 --topic hello --partitions 5 # 删除Topic (需要启用topic删除功能) ./kafka-topics.sh --delete --zookeeper localhost:2181 --topic hello
7.启动kafka的Producer(生产者 )
./kafka-console-producer.sh --broker-list localhost:9092 --topic hello
8.启动kafka的Consumer(消费者)
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic hello --from-beginning
9.验证
查看data数据存放目录:Topic的每个Partition对应一个目录,数据存储在目录下的00000000000000000000.log文件中
查看zookeeper中的内容:get /brokers/topics/hello/partitions/0/state2.配置
############################# Server Basics #############################
# broker的id,值为整数,且必须唯一,在一个集群中不能重复
broker.id=0
############################# Socket Server Settings #############################
# kafka默认监听的端口为9092
#listeners=PLAINTEXT://:9092
# 处理网络请求的线程数量,默认为3个
num.network.threads=3
# 执行磁盘IO操作的线程数量,默认为8个
num.io.threads=8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes=102400
# socket服务接受数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes=102400
# socket服务所能接受的一个请求的最大大小,默认为100M
socket.request.max.bytes=104857600
############################# Log Basics #############################
# kafka存储消息数据的目录
log.dirs=../data
# 每个topic默认的partition数量
num.partitions=1
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir=1
############################# Log Flush Policy #############################
# 消息刷新到磁盘中的消息条数阈值
#log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours=168
# 日志保留大小,超出大小会自动删除,默认为1G
#log.retention.bytes=1073741824
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes=1073741824
# 每隔多长时间检测数据是否达到删除条件
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect=localhost:2181
# 连接zookeeper的超时时间
zookeeper.connection.timeout.ms=6000
# 是否可以删除topic,默认为false
delete.topic.enable=true
七、Kafka集群搭建
1.搭建Zookeeper集群
可以在不同的服务器上搭建kafka服务形成多个服务节点集群,
也可以在一台主机上启动多个zk服务,使用不同的端口就可以了。
拷贝多个zk目录
zookeeper1、zookeeper2、zookeeper3
分别配置每个zk
vi zookeeper1/conf/zoo.cfg
clientPort=2181
server.1=192.168.2.153:6661:7771
server.2=192.168.2.153:6662:7772
server.3=192.168.2.153:6663:7773
echo 1 > zookeeper1/data/myid
vi zookeeper2/conf/zoo.cfg
clientPort=2182
server.1=192.168.2.153:6661:7771
server.2=192.168.2.153:6662:7772
server.3=192.168.2.153:6663:7773
echo 2 > zookeeper2/data/myid
vi zookeeper3/conf/zoo.cfg
clientPort=2183
server.1=192.168.2.153:6661:7771
server.2=192.168.2.153:6662:7772
server.3=192.168.2.153:6663:7773
echo 3 > zookeeper3/data/myid
启动zk集群2.搭建Kafka集群
拷贝多个kafka目录
kafka1、kafka2、kafka3
分别配置每个kafka
vi kafka1/config/server.properties
broker.id=1
listeners=PLAINTEXT://192.168.2.153:9091
zookeeper.connect=192.168.2.153:2181,192.168.2.153:2182,192.168.2.153:2183
vi kafka2/config/server.properties
broker.id=2
listeners=PLAINTEXT://192.168.2.153:9092
zookeeper.connect=192.168.2.153:2181,192.168.2.153:2182,192.168.2.153:2183
vi kafka3/config/server.properties
broker.id=3
listeners=PLAINTEXT://192.168.2.153:9093
zookeeper.connect=192.168.2.153:2181,192.168.2.153:2182,192.168.2.153:2183
启动kafka集群
创建Topic
./kafka-topics.sh \
--create \
--zookeeper 192.168.7.40:2181,192.168.7.40:2182,192.168.7.40:2183 \
--replication-factor 3 \
--partitions 5 \
--topic aaa
生成数据/发布消息
./kafka-console-producer.sh --broker-list 192.168.7.40:9091,192.168.7.40:9092,192.168.7.40:9093 --topic aaa
消费数据/订阅消息
./kafka-console-consumer.sh --bootstrap-server 192.168.7.40:9091,192.168.7.40:9092,192.168.7.40:9093 --topic aaa --from-beginning
八、SpringBoot集成kafka
引入kafka的依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
配置kafka,编辑application.yml文件
spring:
kafka:
# kafka服务器地址(可以多个)
bootstrap-servers: 192.168.7.40:9091,192.168.7.40:9092,192.168.7.40:9093
producer:
# 每次批量发送消息的数量
batch-size: 65536
buffer-memory: 524288
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
# 指定一个默认的组名
group-id: test
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
创建生产者
@RestController
public class KafkaProducer {
@Autowired
private KafkaTemplate template;
/**
* 发送消息到Kafka
* @param topic 主题
* @param message 消息
*/
@RequestMapping("/sendMsg")
public String sendMsg(String topic, String message) {
template.send(topic, message);
return "success";
}
}
创建消费者
@Component
public class KafkaConsumer {
/**
* 订阅指定主题的消息
* @param record 消息记录
*/
@KafkaListener(topics = {"hello","world"})
public void listen(ConsumerRecord record) {
// System.out.println(record);
System.out.println(record.topic()+","+record.value());
}
}
测试
访问http://localhost:8080/sendMsg?topic=hello&message=aaaa
![[附源码]java毕业设计基于的网上饮品店](https://img-blog.csdnimg.cn/e7c7ce8ee13f40659b3c6e4640e9ca04.png)