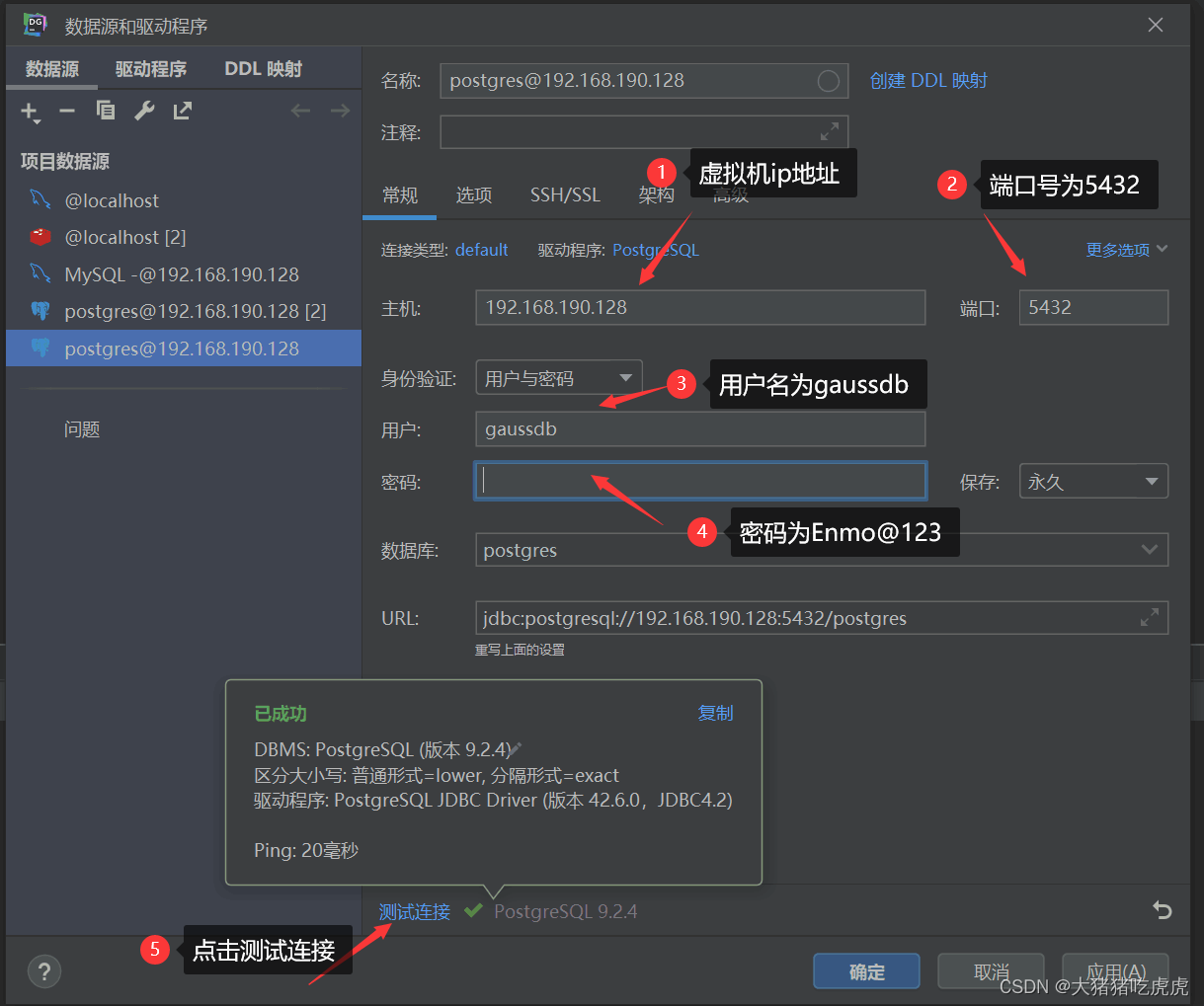
全文链接:http://tecdat.cn/?p=27384
在本文中,数据包含有关葡萄牙“Vinho Verde”葡萄酒的信息(点击文末“阅读原文”获取完整代码数据)。
介绍
该数据集(查看文末了解数据获取方式)有1599个观测值和12个变量,分别是固定酸度、挥发性酸度、柠檬酸、残糖、氯化物、游离二氧化硫、总二氧化硫、密度、pH值、硫酸盐、酒精和质量。固定酸度、挥发性酸度、柠檬酸、残糖、氯化物、游离二氧化硫、总二氧化硫、密度、pH、硫酸盐和酒精是自变量并且是连续的。质量是因变量,根据 0 到 10 的分数来衡量。
相关视频
探索性分析
总共有 855 款葡萄酒被归类为“好”品质,744 款葡萄酒被归类为“差”品质。固定酸度、挥发性酸度、柠檬酸、氯化物、游离二氧化硫、总二氧化硫、密度、硫酸盐和酒精度与葡萄酒质量显着相关( t 检验的 P 值 < 0.05),这表明了重要的预测因子。我们还构建了密度图来探索 11 个连续变量在“差”和“好”葡萄酒质量上的分布。从图中可以看出,品质优良的葡萄酒在PH方面没有差异,而不同类型的葡萄酒在其他变量上存在差异,这与t检验结果一致。
na.oit() %>
muate(qal= ase_hen(ality>5 ~good", quaity <=5 ~ "poor")) %>%
muate(qua= s.fatrqual)) %>%
dpeme1 <- rsparentTme(trans = .4)
plot = "density", pch = "|",
auto.key = list(columns = 2))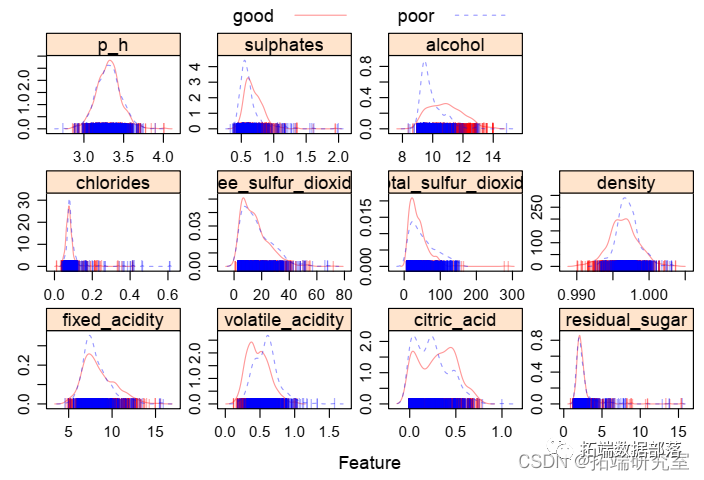
图 1. 葡萄酒品质和预测特征之间的描述图。
表 1. 优质和劣质葡萄酒的基本特征。
# 在表1中创建一个我们想要的变量b1 <- CeatTableOe(vars litars, straa = ’qual’ da winetab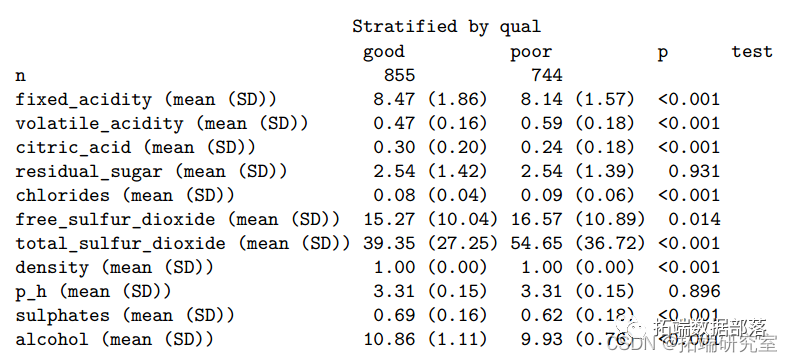
点击标题查阅往期内容

R语言主成分分析(PCA)葡萄酒可视化:主成分得分散点图和载荷图

左右滑动查看更多
01
02
03
04
模型
我们随机选择 70% 的观测值作为训练数据,其余的作为测试数据。所有 11 个预测变量都被纳入分析。我们使用线性方法、非线性方法、树方法和支持向量机来预测葡萄酒质量的分类。对于线性方法,我们训练(惩罚)逻辑回归模型和线性判别分析(LDA)。逻辑回归的假设包括相互独立的观察结果以及自变量和对数几率的线性关系。LDA 和 QDA 假设具有正态分布的特征,即预测变量对于“好”和“差”的葡萄酒质量都是正态分布的。对于非线性模型,我们进行了广义加性模型(GAM)、多元自适应回归样条(MARS)、KNN模型和二次判别分析(QDA)。对于树模型,我们进行了分类树和随机森林模型。还执行了具有线性和径向内核的 SVM。我们计算了模型选择的 ROC 和准确度,并调查了变量的重要性。10 折交叉验证 (CV) 用于所有模型。
inTrai <- cateatPariti(y winequal, p = 0.7, lit =FASE)traiData <- wine\[inexTr, teDt <wi\[-idxTrain,\]线性模型 多元逻辑回归显示,在 11 个预测因子中,挥发性酸度、柠檬酸、游离二氧化硫、总二氧化硫、硫酸盐和酒精与葡萄酒质量显着相关(P 值 < 0.05),解释了总方差的 25.1%。酒质。将该模型应用于测试数据时,准确度为 0.75(95%CI:0.71-0.79),ROC 为 0.818,表明数据拟合较好。在进行惩罚性逻辑回归时,我们发现最大化ROC时,最佳调优参数为alpha=1和lambda=0.00086,准确度为0.75(95%CI:0.71-0.79),ROC也为0.818。由于 lambda 接近于零且 ROC 与逻辑回归模型相同,因此惩罚相对较小,
但是,由于逻辑回归要求自变量之间存在很少或没有多重共线性,因此模型可能会受到 11 个预测变量之间的共线性(如果有的话)的干扰。至于LDA,将模型应用于测试数据时,ROC为0.819,准确率为0.762(95%CI:0.72-0.80)。预测葡萄酒品质的最重要变量是酒精度、挥发性酸度和硫酸盐。与逻辑回归模型相比,LDA 在满足正常假设的情况下,在样本量较小或类别分离良好的情况下更有帮助。
### 逻辑回归cl - tranControlmehod =cv" number 10,
summayFunio = TRUE)
set.seed(1)
moel.gl<- train(x = tainDaa %>% dpyr::selct(-ual),
y = trainDaa$qualmetod "glm",
metic = OC",
tContrl = crl# 检查预测因素的重要性summary(odel.m)
# 建立混淆矩阵
tetred.prb <- rdct(mod.gl, newdat = tstDat
tye = "robtest.ped <- rep("good", length(pred.prconfusionMatrix(data = as.factor(test.pred),
# 绘制测试ROC图oc.l <- roc(testa$al, es.pr.rob$god)
## 测试误差和训练误差er.st. <- mean(tett$qul!= tt.pred)tranped.obgl <-pric(moel.lmnewda= taiDaa,type = "robmoe.ln <-tai(xtraDa %>% dlyr:seec-qal),y = traDmethd = "met",tueGid = lGrid,mtc = "RO",trontrol ctl)plotodel.gl, xTras =uction() lg(x)
#选择最佳参数mol.mn$bestune
# 混淆矩阵tes.red2 <- rp"good" ngth(test.ed.prob2$good))
tst.red2\[tespre.prob2$good < 0.5\] <- "poor
conuionMatridata = as.fcto(test.prd2),
非线性模型 在 GAM 模型中,只有挥发性酸度的自由度等于 1,表明线性关联,而对所有其他 10 个变量应用平滑样条。
结果表明,酒精、柠檬酸、残糖、硫酸盐、固定酸度、挥发性酸度、氯化物和总二氧化硫是显着的预测因子(P值<0.05)。
总的来说,这些变量解释了葡萄酒质量总变化的 39.1%。使用测试数据的混淆矩阵显示,GAM 的准确度为 0.76(95%CI:0.72-0.80),ROC 为 0.829。
MARS 模型表明,在最大化 ROC 时,我们在 11 个预测变量中包含了 5 个项,其中 nprune 等于 5,度数为 2。这些预测变量和铰链函数总共解释了总方差的 32.2%。根据 MARS 输出,三个最重要的预测因子是总二氧化硫、酒精和硫酸盐。
将 MARS 模型应用于测试数据时,准确度为 0.75(95%CI:0.72,0.80),ROC 为 0.823。我们还执行了 KNN 模型进行分类。当 k 等于 22 时,ROC 最大化。KNNmodel 的准确度为 0.63(95%CI:0.59-0.68),ROC 为 0.672。
QDA模型显示ROC为0.784,准确率为0.71(95%CI:0.66-0.75)。预测葡萄酒质量的最重要变量是酒精、挥发性酸度和硫酸盐。59-0.68),ROC 为 0.672。QDA模型显示ROC为0.784,准确率为0.71(95%CI:0.66-0.75)。
预测葡萄酒质量的最重要变量是酒精、挥发性酸度和硫酸盐。59-0.68),ROC 为 0.672。QDA模型显示ROC为0.784,准确率为0.71(95%CI:0.66-0.75)。预测葡萄酒质量的最重要变量是酒精、挥发性酸度和硫酸盐。
GAM 和 MARS 的优点是这两个模型都是非参数模型,并且能够处理高度复杂的非线性关系。具体来说,MARS 模型可以在模型中包含潜在的交互作用。然而,由于模型的复杂性、耗时的计算和高度的过拟合倾向是这两种模型的局限性。对于 KNN 模型,当 k 很大时,预测可能不准确。
### GAMse.see(1)
md.gam<- ran(x =trainDta %%dplr::slect(-qal),y = traiat$ual,thod = "am",metri = "RO",trCotrol = ctrl)
moel.gm$finlMdel
summary(mel.gam)
# 建立混淆矩阵test.pr.pob3 - prdict(mod.ga nwdata =tstData,
tye = "prb")
testped3 - rep"good" legt(test.predpob3$goo))
testprd3\[test.predprob3good < 0.5\] <- "poo
referetv = "good")
model.mars$finalModel
vpmodl.rs$inlodel)
# 绘制测试ROC图
ocmas <- roctestataqua, tes.pred.rob4god)
## Stting level: conrol = god, case= poor
## Settig diectio: cntrols> caseplot(ro.mars legac.axes = TRE, prin.auc= RUE)
plot(soothroc.mars), co = 4, ad =TRUE)
errr.tria.mas <-man(tainat$qul ! trai.red.ars)### KNNGrid < epa.gri(k seq(from = 1, to = 40, by = 1))
seted(1fknnrainqual ~.,
dta = trnData,
mthd ="knn"metrrid = kid)
ggplot(fitkn
# 建立混淆矩阵ts.re.po7 < prdi(ft.kn, ewdt = estDaatype = "prb"
### QDAseteed1)%>% pyr:c-ual),y= trataq
ethod "d"mric = "OC",tContol =ctl)# 建立混淆矩阵tet.pprob <-pedct(mol.da,nedaa = teDta,te = "pb")
testred6<- rep(o", leng(est.ped.pob6$goo))
树方法
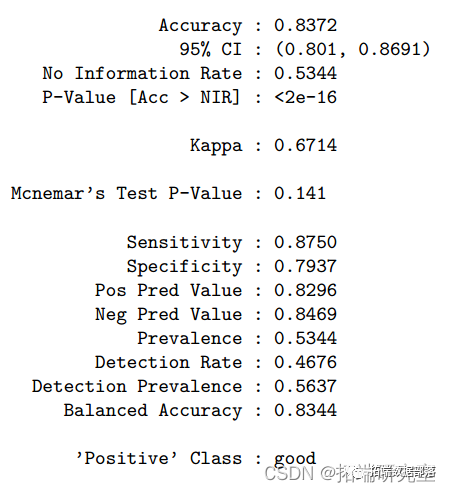
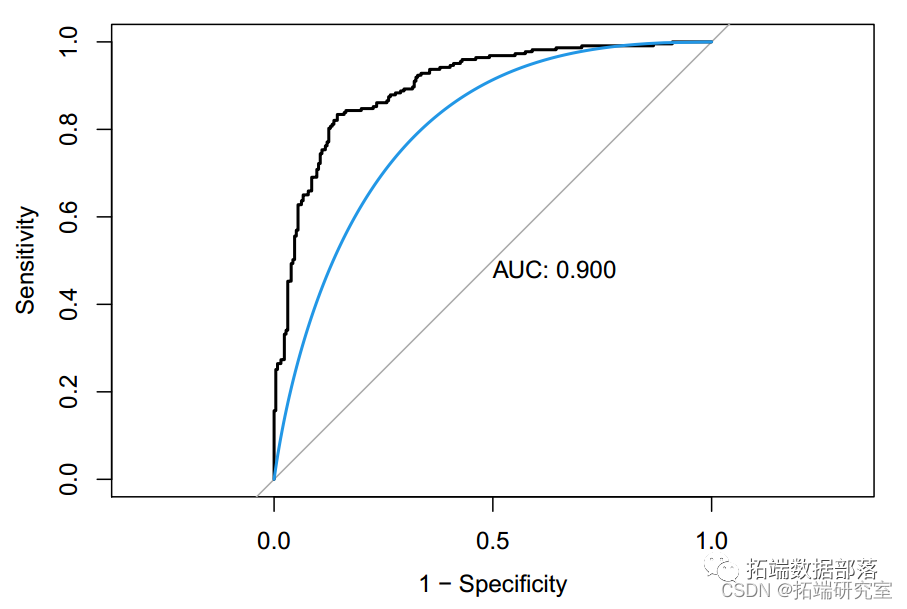
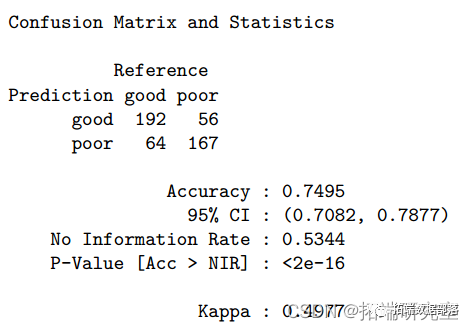
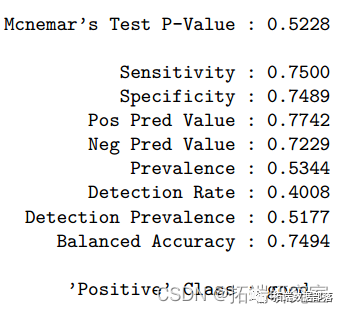
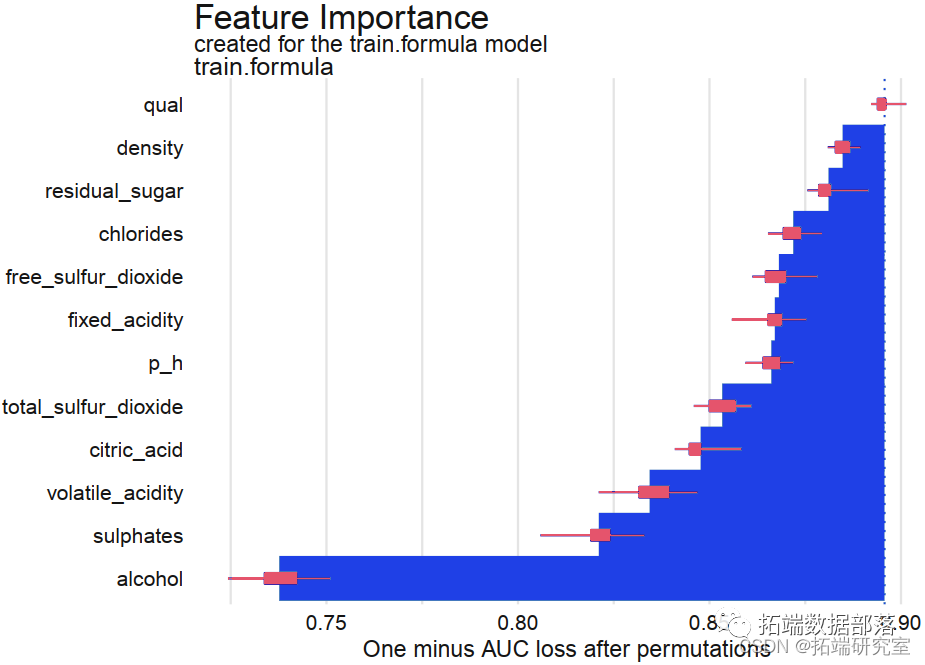
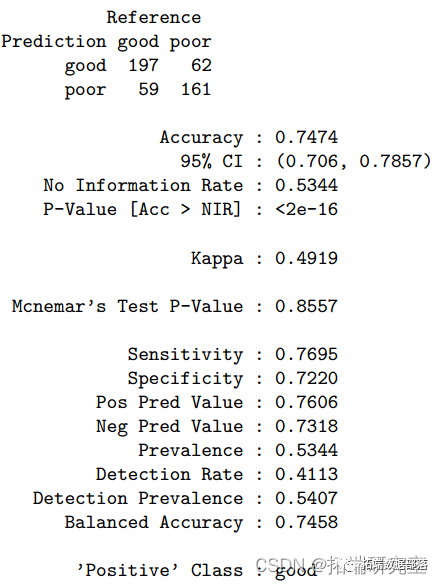
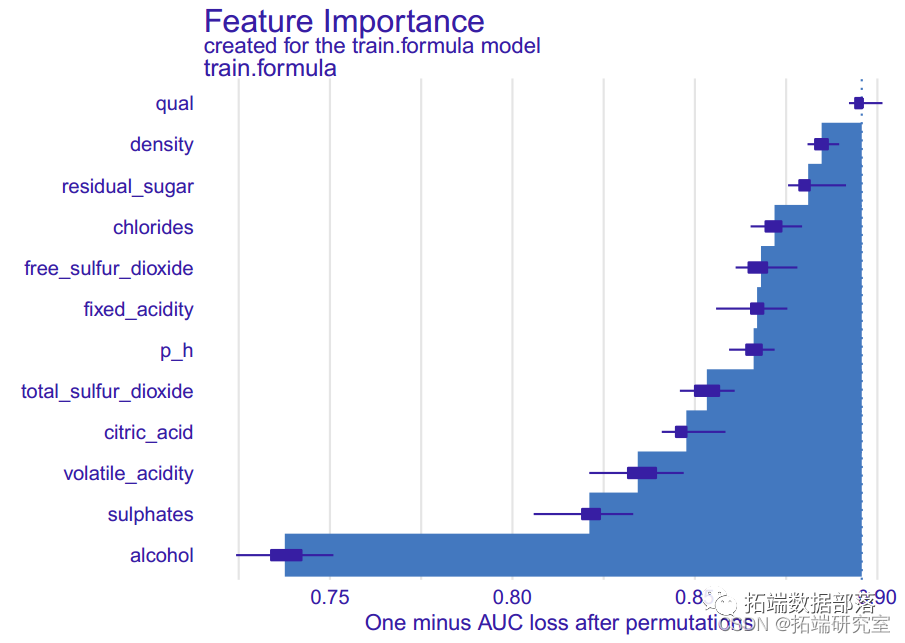
基于分类树,最大化AUC时最终的树大小为41。测试错误率为 0.24,ROC 为 0.809。此分类树的准确度为 0.76(95%CI:0.72-0.80)。我们还进行了随机森林方法来研究变量的重要性。因此,酒精是最重要的变量,其次是硫酸盐、挥发性酸度、总二氧化硫、密度、氯化物、固定酸度、柠檬酸、游离二氧化硫和残糖。pH 是最不重要的变量。对于随机森林模型,测试错误率为 0.163,准确率为 0.84(95%CI:0.80-0.87),ROC 为 0.900。树方法的一个潜在限制是它们对数据的变化很敏感,即数据的微小变化可能引起分类树的较大变化。
# 分类ctr <- tintol(meod ="cv", number = 10,smmryFuton= twoClassSma
et.se(1rart_grid = a.fra(cp = exp(eq(10,-, len =0)))clsste = traqua~., rainDta,metho ="rprt
tueGrid = patid,
trCtrl cr)
ggt(class.tee,highight =TRE)
## 计算测试误差rpartpred = icla.te edta =testata, ye = "aw)
te.ero.sree = mean(testa$a !=rartpre)
rprred_trin reic(ss.tre,newdta = raiata, tye "raw")
# 建立混淆矩阵
teste.pob8 <-rdic(cste, edata =tstData,pe = "po"
tet.pd8 - rpgod" legthtetred.rb8d))
# 绘制测试ROC图
ro.r <-oc(testaual, tstedrob$od)pot(rc.ctreegy.axes TU pit.a = TRE)plo(ooth(c.tre, col= 4, ad = TRE
# 随机森林和变量重要性
ctl <traontr(mthod= "cv, numbr = 10,clasPos = RUEoClssSummry)
rf.grid - xpa.gr(mt = 1:10,
spltrule "gini"min.nd.sie =seq(from = 1,to 12, by = 2))se.sed(1)
rf.fit <- inqual
mthd= "ranger",
meric = "ROC",
= ctrl
gglt(rf.it,hiliht TRE)
scle.ermutatin.iportace TRU)barplt(sort(rangr::imoranc(random

支持向量机
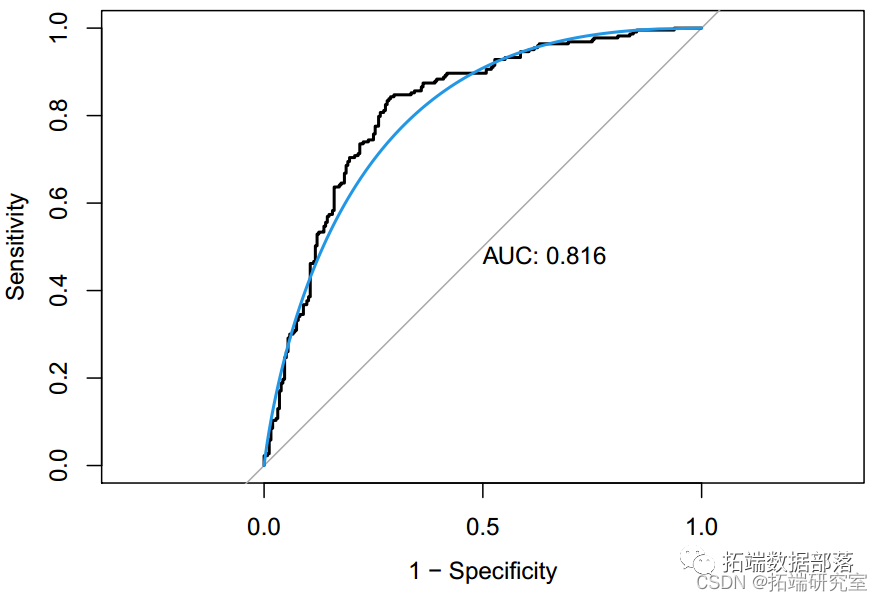
我们使用带有线性核的 SVM,并调整了成本函数。我们发现具有最大化 ROChad 成本的模型 = 0.59078。该模型的 ROC 为 0.816,准确度为 0.75(测试误差为 0.25)(95%CI:0.71-0.79)。质量预测最重要的变量是酒精;挥发性酸度和总二氧化硫也是比较重要的变量。如果真实边界是非线性的,则具有径向核的 SVM 性能更好。
st.seed(svl.fi <- tain(qual~ . ,data = trainDatamehod= "mLar2",tueGri = data.frae(cos = ep(seq(-25,ln = 0))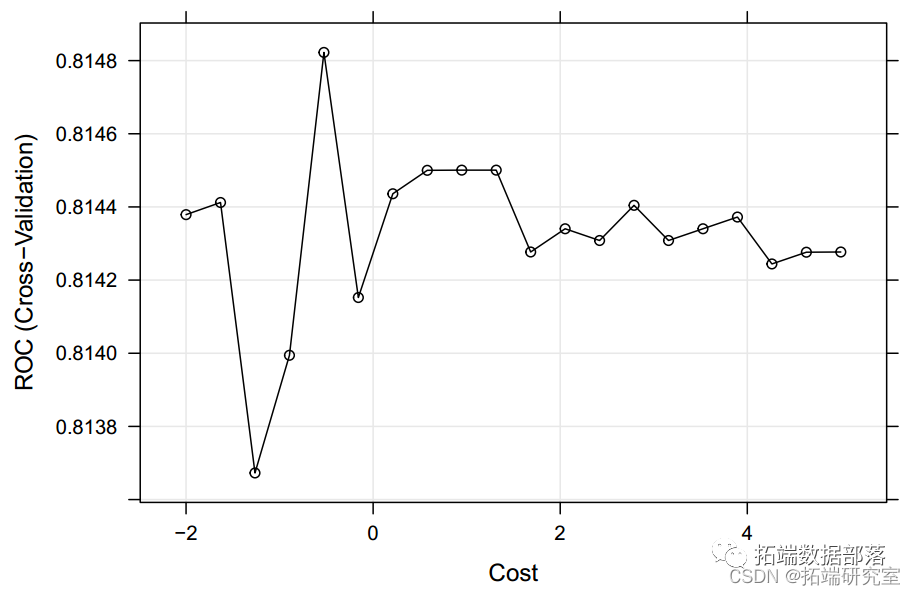
## 带径向核的SVMsvmr.grid epand.gid(C = epseq(1,4,le=10)),
iga = expsq(8,len=10)))
svmr.it<- tan(qual ~ .,
da = taiDataRialSigma",
preProcess= c("cer" "scale"),
tunnrol = c)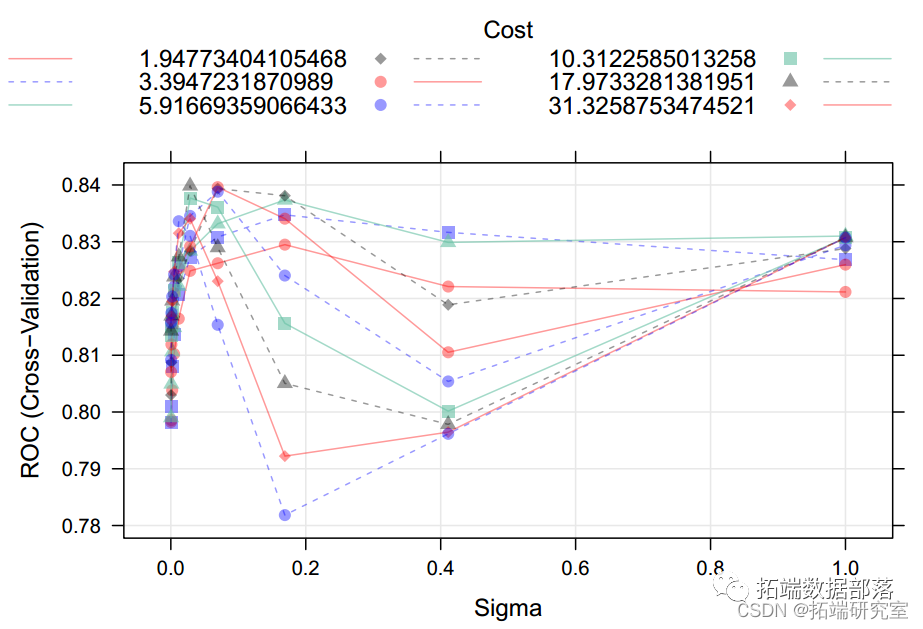
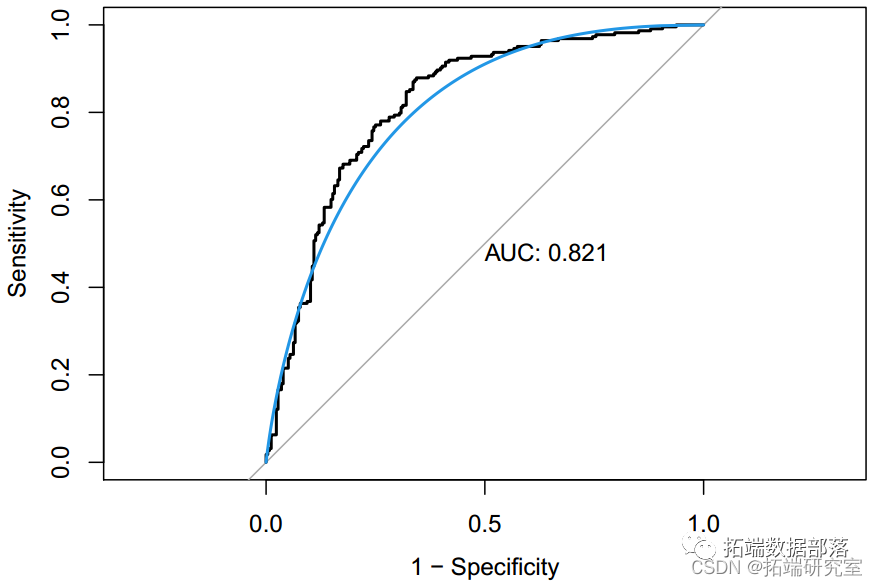
模型比较
模型建立后,我们根据所有模型的训练和测试性能进行模型比较。下表显示了所有模型的交叉验证分类错误率和 ROC。结果中,随机森林模型的 AUC 值最大,而 KNN 最小。因此,我们选择随机森林模型作为我们数据的最佳预测分类模型。基于随机森林模型,酒精、硫酸盐、挥发性酸度、总二氧化硫和密度是帮助我们预测葡萄酒质量分类的前 5 个重要预测因子。由于酒精、硫酸盐和挥发性酸度等因素可能决定葡萄酒的风味和口感,所以这样的发现符合我们的预期。在查看每个模型的总结时,我们意识到KNN模型的AUC值最低,测试分类错误率最大,为0.367。其他九个模型的 AUC 值接近,约为 82%。
rsam = rsmes(list(summary(resamp)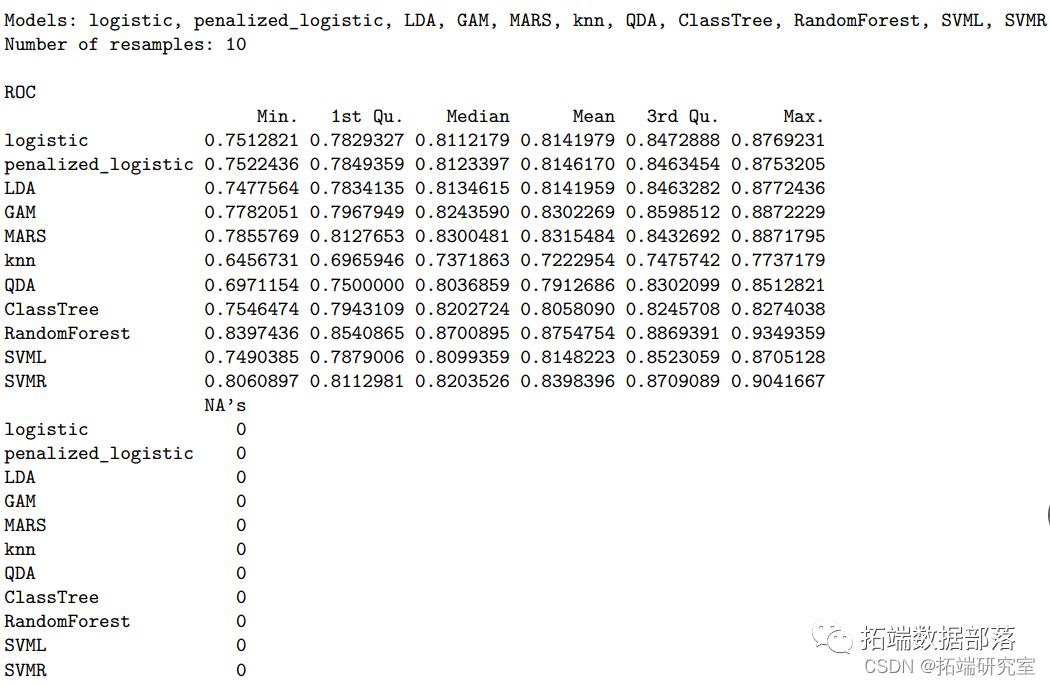
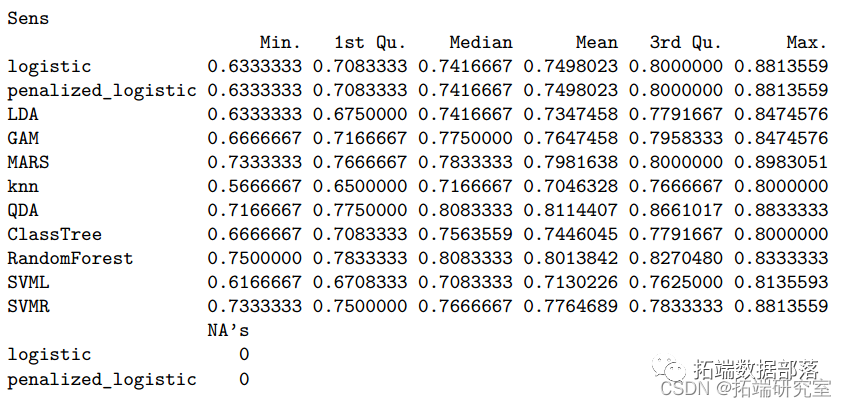
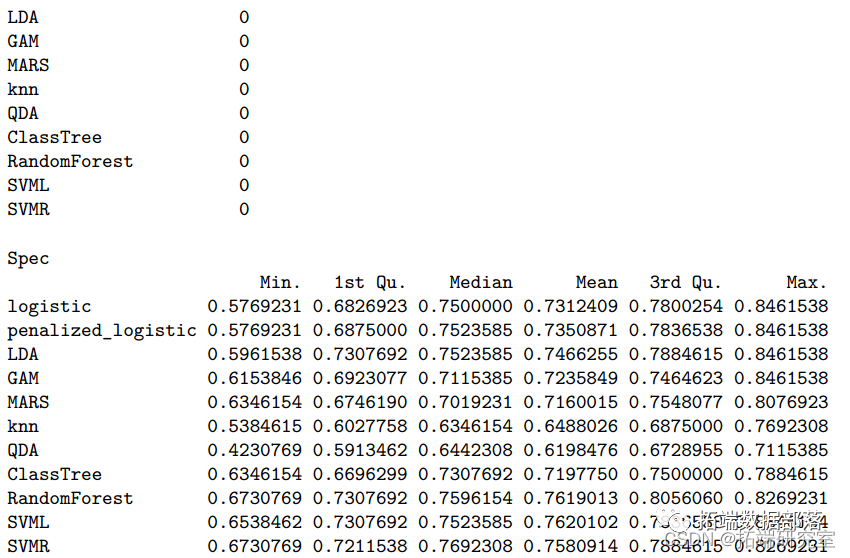
comrin = sumaryes)$satitics$ROr_quare smary(rsamp)saisis$sqrekntr::ableomris\[,1:6\])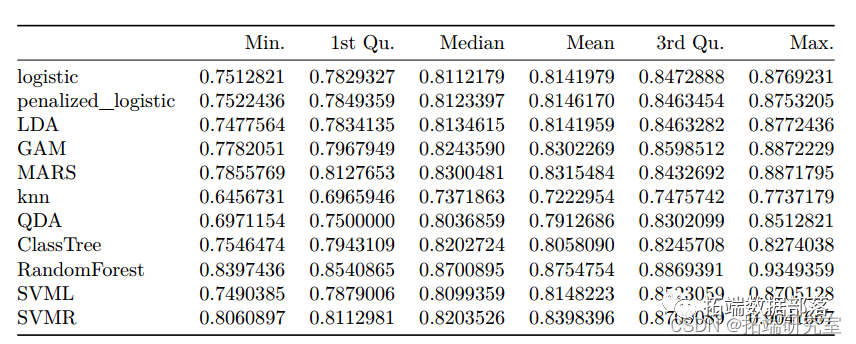
bpot(remp meic = "ROC")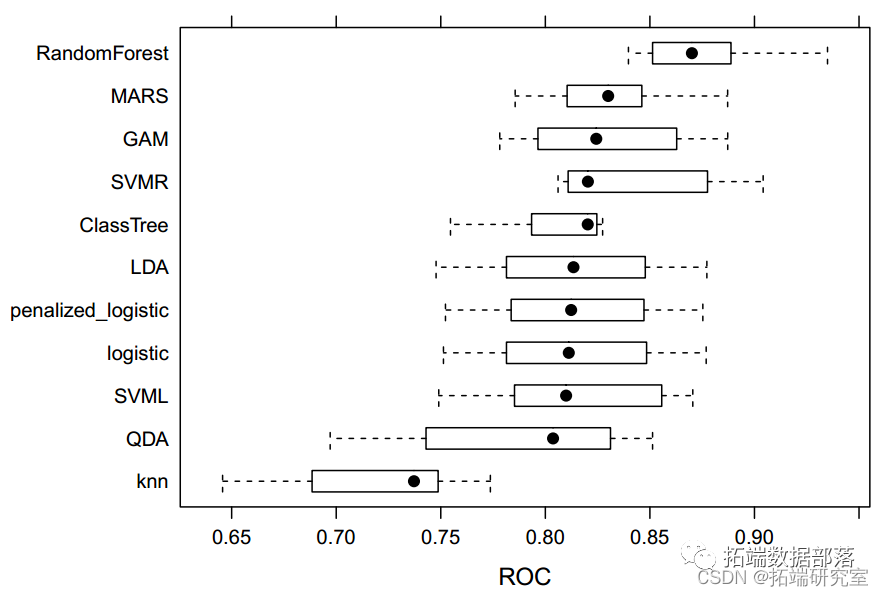
f<- datafram(dl\_Name, TainError,Test\_Eror, Tes_RC)
knir::abe(df)
结论
模型构建过程表明,在训练数据集中,酒精、硫酸盐、挥发性酸度、总二氧化硫和密度是葡萄酒质量分类的前 5 个重要预测因子。我们选择了随机森林模型,因为它的 AUC 值最大,分类错误率最低。该模型在测试数据集中也表现良好。因此,这种随机森林模型是葡萄酒品质分类的有效方法。
数据获取
在下面公众号后台回复“葡萄酒数据”,可获取完整数据。

点击文末“阅读原文”
获取全文完整资料。
本文选自《R语言惩罚逻辑回归、线性判别分析LDA、广义加性模型GAM、多元自适应回归样条MARS、KNN、二次判别分析QDA、决策树、随机森林、支持向量机SVM分类优质劣质葡萄酒十折交叉验证和ROC可视化》。

本文中的葡萄酒数据分享到会员群,扫描下面二维码即可加群!


点击标题查阅往期内容
R语言贝叶斯广义线性混合(多层次/水平/嵌套)模型GLMM、逻辑回归分析教育留级影响因素数据
逻辑回归Logistic模型原理R语言分类预测冠心病风险实例
数据分享|用加性多元线性回归、随机森林、弹性网络模型预测鲍鱼年龄和可视化
R语言高维数据惩罚回归方法:主成分回归PCR、岭回归、lasso、弹性网络elastic net分析基因数据(含练习题)
Python中LARS和Lasso回归之最小角算法Lars分析波士顿住房数据实例
R语言Bootstrap的岭回归和自适应LASSO回归可视化
R语言Lasso回归模型变量选择和糖尿病发展预测模型
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
基于R语言实现LASSO回归分析
R语言用LASSO,adaptive LASSO预测通货膨胀时间序列
R语言自适应LASSO 多项式回归、二元逻辑回归和岭回归应用分析
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
Python中的Lasso回归之最小角算法LARS
r语言中对LASSO回归,Ridge岭回归和弹性网络Elastic Net模型实现
r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现
R语言实现LASSO回归——自己编写LASSO回归算法
R使用LASSO回归预测股票收益
python使用LASSO回归预测股票收益

![]()









![[maven] scopes 管理 profile 测试覆盖率](https://img-blog.csdnimg.cn/3379879de5154a1da1e6033ad9eb8f42.png)