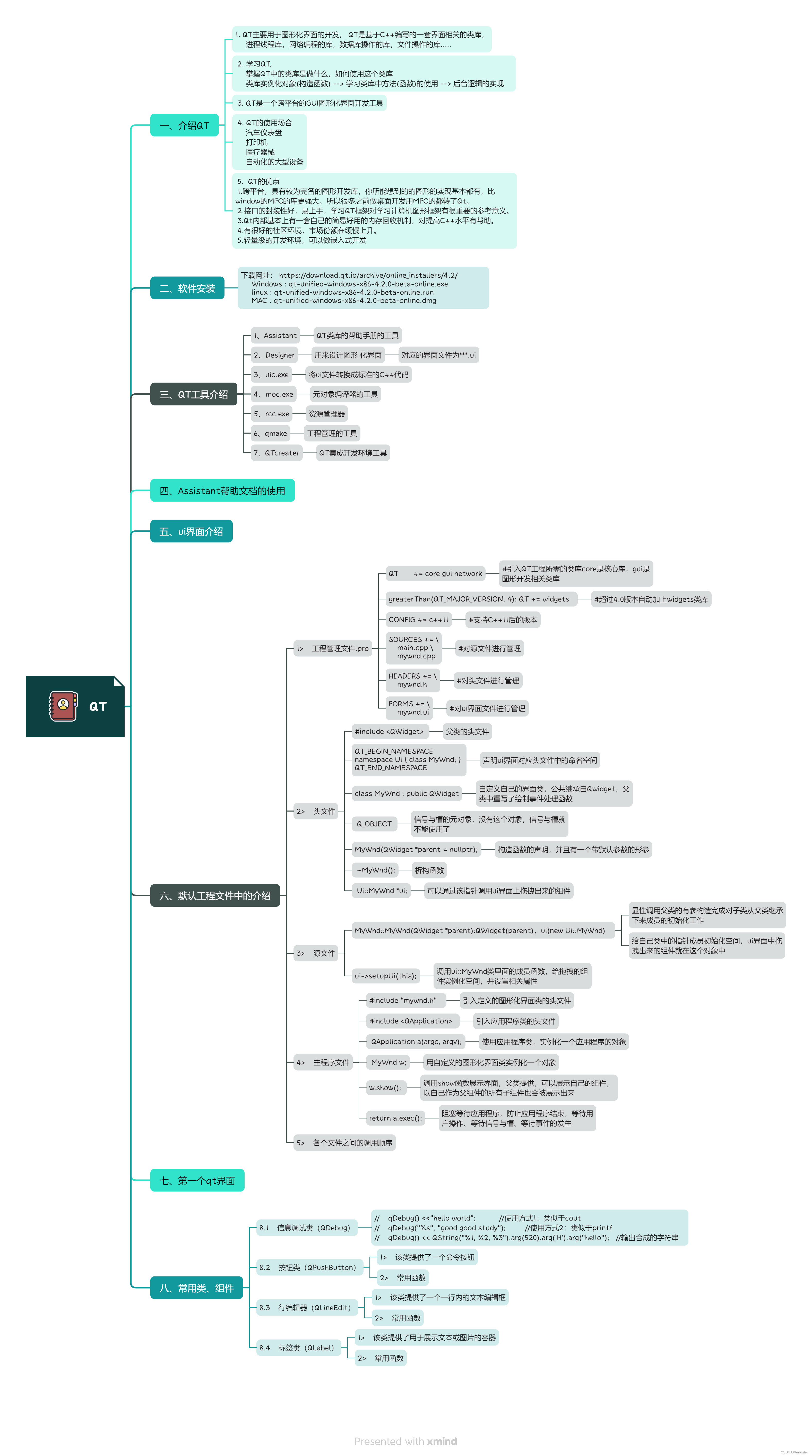
满足标准:并发大于等于100 ,平均响应时间小于等于3秒
项目在压测过程中并发数只有50,在并发数100的情况下有很多请求链接是失败的
我们该如何入手去处理这些问题并提高并发数呢?
1、首先从压测结果入手,对不满足标准的链接url进行单独压测,并在100并发数的条件下,查看聚合报告显示的当前压测链接的平均响应时间和错误率,并将结果输出本地中以查看有多少链接出现错误,出现的错误是什么,比如:403、401或500 等。
2、拿出日志,并根据具体报错信息,优化你的代码。
基本上到这一步,所有的问题一般都能解决了。
在本次压测中,大部分失败的请求都是500错误,同时错误主要集中在微服务之间的调用逻辑上,还有一部分是代码响应超时上。在并发量较高的情况下,就会出现处理失败的请求。
本次压测出现问题的原因
1、并发较高的情况下,使用shiro获取上下文中的用户信息时有时为空,这时就会导致错误链接,后台会报空指针异常
原因分析:在访问接口时,需要做登录认证,认证时,需要将用户信息存至上下文,存上下文时会负载均衡调用远程feign接口,导致调用失败,熔断。
这种情况目前处理方案
代码中做非空校验,让其返回200。并不能在压测链接中添加响应断言条件。这种是治标不治本,归其原因还是shiro的上下文信息无法处理高并发请求导致获取不到用户信息,导致压测时错误率升高。
2、并发较高的情况下,openfeign产生了服务降级
准确的说是 openfeign整和了ribbon 和hixtry 而 openfeign启用了hixtry后 并添加了fallback 注解,从而出现在服务端超时或报错的情况下出现了服务降级的情况。
深入剖析一下 openfeign中的服务降级和hixtry中的服务降级 有什么区别与联系?
- openfeign是一个声明式的服务调用客户端,它可以通过注解的方式来调用其他微服务的接口.hixtry是一个用于实现熔断器模式的库,它可以在服务出现故障时,提供一个备用的响应,从而避免级联失败.
- openfeign和hixtry可以结合使用,实现服务调用的容错和熔断。openfeign可以通过配置feign.hystrix.enabled=true来启用hixtry的支持然后可以在FeignClient注解中指定fallback或fallbackFactory属性,来定义当远程调用失败或超时时,应该使用哪个类来处理请求的回退逻辑。
- openfeign中的服务降级和hixtry中的服务降级的区别在于,openfeign中的服务降级是针对客户端的,即当客户端调用服务端失败或超时时,客户端会执行fallback类中的方法来返回一个默认的结果。而hixtry中的服务降级是针对服务端的,即当服务端出现异常或错误时,服务端会执行@HystrixCommand注解中指定的fallbackMethod来返回一个默认的结果。
- openfeign中的服务降级和hixtry中的服务降级的联系在于,它们都是基于hixtry的熔断机制来实现的,即当某个服务在一定时间内达到一定次数的失败率时,会触发熔断器打开,从而拒绝请求,并执行回退逻辑。它们都可以通过配置文件或注解来设置熔断器的相关参数,如超时时间、错误阈值、恢复时间等。
查看日志报错:
2023-09-05 18:36:07.219 [http-nio-0.0.0.0-8982-exec-34] ERROR c.e.p.cloud.base.exception.GlobalExceptionHandler - could not acquire a semaphore for execution com.netflix.hystrix.exception.HystrixRuntimeException: BaseUserRemote#updateSysUser(SysUser) could not acquire a semaphore for execution and no fallback available.
2023-09-05 18:36:07.219 [http-nio-0.0.0.0-8982-exec-34] 错误 c.e.p.cloud.base.exception.GlobalExceptionHandler - 无法获取用于执行的信号量 com.netflix.hystrix.exception.HystrixRuntimeException:BaseUserRemote#updateSysUser(SysUser) 无法获取用于执行的信号量,并且没有可用的后备。
来分析一下错误的原因:
这个异常信息表示您的程序在调用 BaseUserRemote#updateSysUser(SysUser) 方法时无法获取一个信号量(semaphore)。信号量是一种计数器,用来控制同时访问某个特定资源的操作数量。 如果信号量的值为 0,那么没有许可可用,请求获取信号量的线程会被阻塞,直到有其他线程释放信号量。
出现这个异常的可能原因有以下几种:
- 您的程序设置了信号量的初始值过小,导致可用的许可不足以满足并发请求的需求。 这种情况下,您可以检查您的程序中创建信号量的代码,看是否有相关的设置,并根据实际需求进行调整。
- 您的程序在获取信号量后没有正确地释放信号量,导致信号量被占用,无法被其他线程获取。 这种情况下,您可以检查您的程序中使用信号量的代码,看是否有正确地调用 release() 方法,并使用 try-finally 语句来保证释放操作的执行。
- 您的程序在获取信号量时没有设置超时时间,导致线程一直等待信号量,无法继续执行。 这种情况下,您可以检查您的程序中使用信号量的代码,看是否有正确地调用 tryAcquire() 方法,并设置合理的超时时间和时间单位。
hystrix为每个依赖提供一个小的线程池(或信号量),如果线程池已满调用将被立即拒绝,加速失败判定时间。hystrix还提供了两种隔离策略,分别是THREAD和SEMAPHORE。THREAD模式下,每个请求在单独的线程上执行,并受到线程池大小的限制;SEMAPHORE模式下,每个请求在调用线程上执行,并受到信号量计数的限制。隔离策略可以通过execution.isolation.strategy参数来设置,默认值是THREAD。
hixtry和ribbon的超时时间设置对压测时总是熔断有什么影响,主要取决于以下几个因素:
- 压测的流量和响应时间,如果压测的流量过大或者响应时间过长,可能导致请求堆积或者超时,触发熔断器的阈值,从而拒绝后续的请求
- hixtry和ribbon的隔离策略,hixtry有两种隔离策略,分别是THREAD和SEMAPHORE。THREAD模式下,每个请求在单独的线程上执行,并受到线程池大小的限制;SEMAPHORE模式下,每个请求在调用线程上执行,并受到信号量计数的限制。不同的隔离策略对压测的性能和稳定性有不同的影响。
- hixtry和ribbon的超时时间设置,hixtry和ribbon都有自己的超时时间设置,分别控制执行命令、执行fallback、建立连接、读取数据等方面的超时时间。不同的超时时间设置对压测的成功率和失败率有不同的影响。
- hixtry和ribbon的重试机制,hixtry和ribbon都有自己的重试机制,分别控制是否对所有操作都重试、对同一个服务器或者下一个服务器的最大重试次数等方面的重试策略。不同的重试机制对压测的效率和效果有不同的影响
一般来说,要避免压测时总是熔断,需要根据实际情况合理地设置hixtry和ribbon的超时时间,保证在压测流量范围内,请求能够及时得到响应或者降级处理,不会因为等待过久或者失败过多而触发熔断器打开
# 设置实例HystrixCommandKey的此属性值,使用信号量策略
hystrix.command.HystrixCommandKey.execution.isolation.strategy=SEMAPHORE
# 设置 Hystrix 信号量隔离策略的最大并发请求数
hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests=100
# 设置 Hystrix 信号量隔离策略的最大并发回退请求数
hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests=50
# 设置 Hystrix 熔断器开关,true 表示开启熔断器
hystrix.command.default.circuitBreaker.enabled=true
# 设置 Hystrix 熔断器的请求阈值,即在一个统计窗口内最少请求数
hystrix.command.default.circuitBreaker.requestVolumeThreshold=20
# 设置 Hystrix 熔断器的错误率阈值,即触发熔断的错误百分比
hystrix.command.default.circuitBreaker.errorThresholdPercentage=50
# 设置 Hystrix 熔断器的休眠时间窗,即熔断后多久尝试恢复,默认为 5 秒
hystrix.command.default.circuitBreaker.sleepWindowInMilliseconds=5000
高并发一下如何设置 hixtry 和 ribbon的超时时间?
-
一般来说,hixtry的超时时间包括以下几个方面:
- execution.isolation.thread.timeoutInMilliseconds:执行命令的超时时间,单位为毫秒,默认为1000
- execution.timeout.enabled:是否启用执行超时,默认为true
- fallback.isolation.thread.timeoutInMilliseconds:执行fallback的超时时间,单位为毫秒,默认为1000
- fallback.enabled:是否启用fallback,默认为true
-
一般来说,ribbon的超时时间包括以下几个方面:
- ribbon.ConnectTimeout:建立连接的超时时间,单位为毫秒,默认为1000
- ribbon.ReadTimeout:读取数据的超时时间,单位为毫秒,默认为5000
- ribbon.OkToRetryOnAllOperations:是否对所有操作都重试,默认为false
- ribbon.MaxAutoRetries:对同一个服务器的最大重试次数,默认为0
- ribbon.MaxAutoRetriesNextServer:切换到下一个服务器的最大重试次数,默认为1
-
hixtry还有一个fallback机制,当请求失败或者被拒绝时,可以执行一个备选方案,返回一个默认值或者友好提示。fallback也需要一定的资源来执行,所以hixtry也对fallback的并发请求数做了限制
-
hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests是一个配置参数,它表示每个命令允许的最大并发请求数。如果超过这个数目,请求将被拒绝,并触发降级逻辑
-
当你使用100并发进行压测时,可能有以下几种情况:
- 如果你使用的是THREAD模式,并且线程池大小小于100,那么一部分请求会被线程池拒绝,并触发fallback。如果fallback的并发请求数超过了hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests的值(默认为10),那么一部分fallback也会被信号量拒绝,并报信号量阻塞的错误
- 如果你使用的是SEMAPHORE模式,并且hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests的值小于100(默认为10),那么一部分请求会被信号量拒绝,并触发fallback。如果fallback的并发请求数也超过了hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests的值(默认为10),那么一部分fallback也会被信号量拒绝,并报信号量阻塞的错误
- 如果你使用的是任何一种模式,并且请求的失败率超过了hystrix.command.default.circuitBreaker.errorThresholdPercentage的值(默认为50%),那么熔断器会打开,后续的请求都会直接被拒绝,并触发fallback。如果fallback的并发请求数超过了hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests的值(默认为10),那么一部分fallback也会被信号量拒绝,并报信号量阻塞的错误
-
当你设置了hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests=100时,就相当于把fallback的并发请求数限制放宽了,让所有的fallback都能执行成功,不会报信号量阻塞的错误](about:blank#)12。但这并不意味着你解决了压测中出现的问题,只是把错误从信号量阻塞转移到了其他地方(如线程池拒绝、熔断器打开等)](about:blank#)12。
根据上述分析,我们解决此问题 从两点出发:1、设置hixtry 的超时时间 2、设置ribbon的超时时间 3、设置fallback的数量
实际场景分析:
当在进行压测时,发生了60个请求连接失败并触发了服务降级,这可能是由于服务端在高并发情况下无法处理这些请求而导致的。服务降级是为了保护服务端的稳定运行而进行的一种策略,当服务端无法及时响应请求或出现错误时,Hystrix会触发服务降级来保护服务端资源不过载。这样会导致某些请求被降级,返回默认响应。
要解决这种情况,首先需要确认为什么这60个请求触发了服务降级,而其他请求并没有报错或被降级。可能的原因包括:
-
服务端资源限制:服务端可能存在资源限制,如线程池容量不足、内存限制或者数据库连接池不够。你可以检查服务端的资源配置,并根据实际情况进行调整和优化。
-
请求过于频繁:这60个请求可能在短时间内同时发起,导致高并发情况下服务端无法处理这些请求。你可以考虑限制或调整客户端请求的频率,以免过多的请求同时到达服务端。
在OpenFeign和Hystrix的配置方面,你可以采取一些措施来改善这个问题:
-
调整线程池配置:在Hystrix的配置中,你可以增加线程池的核心线程数、最大线程数等参数来提高服务端的并发处理能力。
-
调整Hystrix的超时时间:可根据实际情况适当调整Hystrix的超时时间,避免过长的等待时间导致服务降级。
-
优化服务端性能:通过代码优化、缓存技术等方式提高服务端的性能和并发处理能力,以应对高并发请求。
-
使用负载均衡:使用负载均衡器对请求进行分流,将请求均匀分配到多个服务实例上,分散负载压力。
需要注意的是,在进行配置调整之前,一定要通过监控和分析来了解系统的瓶颈和性能状况,并找到具体的问题所在。同时,也可以适用开源性能测试工具,如JMeter、Gatling等进行压力测试,用于定位问题和验证配置的效果。
综上所述,通过优化服务端资源和配置OpenFeign和Hystrix的相关参数,可以增加系统的并发处理能力,减少触发服务降级的情况。但并发测试需要综合考虑系统的硬件资源和业务逻辑,建议结合具体场景来进行调整和优化。
在高并发情况下,Hystrix发生服务降级的条件包括:
- 请求超时:配置的超时时间内未收到响应。
- 请求阈值和错误比例:请求的数量超过阈值,并且错误的比例超过配置的阈值。
- 熔断器打开状态:当熔断器处于打开状态时,所有请求都将被熔断。
这些条件可以通过配置Hystrix的参数来控制。使用OpenFeign集成Hystrix时,可以通过在Feign客户端接口的方法上添加@HystrixCommand注解来设置相关参数。
为了满足100个并发数并避免服务降级的情况,你可以根据以下几个方面进行配置:
-
超时时间:适当增加超时时间,确保服务端有足够的时间进行处理,并保证请求在指定超时时间内得到响应。可以在@HystrixCommand注解的commandProperties属性中设置
execution.isolation.thread.timeoutInMilliseconds参数。 -
请求阈值和错误比例:根据实际情况,调整请求阈值和错误比例的参数,使得请求超过阈值和错误比例的发生概率较低。可以在@HystrixCommand注解的commandProperties属性中设置
circuitBreaker.requestVolumeThreshold和circuitBreaker.errorThresholdPercentage参数。 -
熔断时间:调整熔断器的关闭时间,确保熔断器在一段时间后能够逐渐关闭,允许部分请求通过。可以在@HystrixCommand注解的commandProperties属性中设置
circuitBreaker.sleepWindowInMilliseconds参数。
需要注意的是,并发数受到多个因素的影响,包括服务端的资源和处理能力、网络传输速度等。当高并发情况下,确保系统的可用性和性能需要综合考虑各个环节的优化。除了Hystrix的参数配置,还可以采取负载均衡、集群部署、合理设计数据库访问、缓存策略等措施来提升系统的并发处理能力。
最重要的是根据具体的业务场景进行测试和调优,逐步优化系统的性能和可用性,以满足高并发场景下的需求。
熔断策略的本质
-
熔断并不是服务报错,而是一种主动的保护机制,用于避免服务因为故障或者延迟而造成的雪崩效应]。雪崩效应是指当一个服务不可用或者响应缓慢时,会导致调用方的资源耗尽,从而影响其他服务的正常运行,最终导致整个系统崩溃。
-
熔断的原理是通过监控服务的调用情况,当发现服务出现异常或者超时的比例或次数达到一定的阈值时,就会触发熔断器打开,切断对该服务的调用,并返回一个默认的结果或者提示信息 。这样可以保证调用方不会因为等待故障服务而浪费资源,也可以减轻故障服务的压力,让其有机会恢复正常 。
-
熔断的优势是可以提高系统的可用性和稳定性,因为它可以防止故障服务影响整个系统的运行,也可以让故障服务快速恢复 。熔断并不会影响高并发的需求,反而可以让系统在高并发下更加健壮和鲁棒 。
-
服务降级是指当服务不可用或者响应缓慢时,为了保证系统的可用性和稳定性,采取一些措施来减少服务的质量或者功能,从而避免系统崩溃或者雪崩效应。
-
熔断的目的是为了保护系统在高并发下不至于崩溃,而不是为了满足所有用户的数据需求。当系统的处理能力达到极限时,必须采取一些措施来减少负载,否则会导致系统无法正常运行,甚至崩溃 。
-
熔断的策略是根据服务的重要性和可用性来制定的,一般来说,对于核心业务和关键服务,不会轻易触发熔断,而对于非核心业务和次要服务,可以适当降低服务质量,或者提供一些默认的结果或提示信息 。
-
熔断的效果是让系统在高并发下更加稳定和可靠,因为它可以防止故障服务影响其他正常服务,并且可以让故障服务快速恢复。虽然熔断会让部分用户无法获取到他们想要的数据,但这是一种权衡和妥协的结果,相比于让整个系统崩溃,熔断是一种更好的选择 。
-
对于那些降级的服务,会给用户返回一些默认的结果或者提示信息,以便让用户知道服务目前的状态,不再继续等待或者重试.具体的返回内容取决于服务的类型和业务场景,一般有以下几种方式:
- 返回空值或者null,表示服务没有返回任何数据。
- 返回缓存数据或者静态数据,表示服务返回了一些过期或者固定的数据。
- 返回友好的错误提示或者异常信息,表示服务出现了故障或者异常。
- 返回降级页面或者功能,表示服务只提供了部分或者简化的页面或功能。
-
举例说明:
- 如果一个电商网站的商品详情页出现了延迟或者故障,可以给用户返回一个空白页或者一个提示“商品信息暂时无法显示,请稍后再试”的页面。
- 如果一个新闻网站的最新新闻列表出现了延迟或者故障,可以给用户返回一些缓存的新闻列表或者一些静态的新闻列表
- 如果一个社交网站的用户评论功能出现了延迟或者故障,可以给用户返回一个错误提示或者一个异常信息,比如“评论失败,请重试”或者“评论功能暂时不可用,请稍后再试”
- 如果一个视频网站的高清视频播放功能出现了延迟或者故障,可以给用户返回一个降级的视频播放功能,比如只提供标清视频播放。
如何解决
综上分析,
1、高并发情况下出现了服务降级无非就是 服务器压力过大,或者超过了熔断的阈值导致了降级。如果服务端还能承受那就调整熔断的阈值。
2、如果不能承受就修改在降级后响应给用户数据,来保证高并发。
在使用jmeter进行压测时,错误的请求链接是如何产生的,比如100个请求同时进来,为啥会有链接成功,也有部分链接报错,这是什么原理呢?实际上并发小的情况下 代码并不会报错,这是为什么
在使用 JMeter 进行压测时,错误的请求链接是由于多种原因导致的,比如网络延迟、服务器负载、请求参数、代码逻辑等。当有 100 个请求同时进来时,可能会有以下几种情况发生:
- 部分请求成功,部分请求失败。这可能是因为服务器的处理能力不足以应对高并发的压力,导致部分请求超时或被拒绝。或者是因为请求参数不合法或不一致,导致部分请求无法正常处理。或者是因为代码逻辑存在缺陷或异常,导致部分请求出现错误。
- 所有请求都失败。这可能是因为网络连接断开或不稳定,导致所有请求无法到达服务器。或者是因为服务器崩溃或宕机,导致所有请求无法得到响应。或者是因为请求参数或代码逻辑存在严重的问题,导致所有请求都无法正常处理。
- 所有请求都成功。这可能是因为网络连接良好,服务器性能强大,请求参数合法,代码逻辑正确,导致所有请求都能够正常处理。
实际上,并发小的情况下,代码并不会报错,这可能是因为以下几个原因:
- 并发小的情况下,服务器的压力较小,可以及时响应每个请求,不会出现超时或拒绝的情况。
- 并发小的情况下,请求参数较少或较简单,可以满足代码逻辑的要求,不会出现非法或异常的情况。
- 并发小的情况下,代码逻辑较少或较简单,可以正确地处理每个请求,不会出现缺陷或错误的情况。
如果请求参数一致,为什么还要错误的链接
压测时请求的参数都是一致的,为什么还会出现部分请求成功,部分请求失败的情况,这可能是因为以下几个原因:
- 请求的参数虽然一致,但是请求的时间不一致。不同的请求可能会在不同的时间点发送,而服务器的状态和负载可能会随着时间而变化。例如,如果服务器在某个时间点出现了高峰或异常,那么在这个时间点发送的请求就有可能失败,而在其他时间点发送的请求就有可能成功。
- 请求的参数虽然一致,但是请求的环境不一致。不同的请求可能会经过不同的网络路径或设备,而网络和设备的状况可能会影响请求的结果。例如,如果网络出现了延迟或丢包,那么部分请求就有可能超时或丢失,而其他请求就有可能正常到达服务器。
- 请求的参数虽然一致,但是请求的处理不一致。不同的请求可能会被分配到不同的服务器或线程来处理,而服务器或线程的性能和资源可能会影响请求的结果。例如,如果某个服务器或线程出现了负载过高或内存不足,那么由它处理的请求就有可能失败,而由其他服务器或线程处理的请求就有可能成功。
压测过程中,如果并发高的情况下,有的请求报500错误,有的请求是成功的。如果并发小的情况下 所有的请求都是成功的,这说明了什么?既然有请求成功,为什么还会报500错误呢?500错误是代码错误啊,既然是请求成功的为啥还会报代码错误呢?
压测过程中,如果并发高的情况下,有的请求报 500 错误,有的请求是成功的。如果并发小的情况下 所有的请求都是成功的,这说明了以下几点:
- 服务器的处理能力有限,不能同时满足高并发的压力,导致部分请求失败。
- 代码逻辑存在缺陷或异常,不能正确地处理高并发的情况,导致部分请求出错。
- 网络或设备存在问题,不能稳定地传输高并发的数据,导致部分请求丢失或超时。
既然有请求成功,为什么还会报 500 错误呢?500 错误是服务器内部错误,表示服务器在处理请求时出现了意料之外的情况,无法完成请求。这可能是由于以下几种原因:
- 服务器资源不足,如 CPU、内存、磁盘等,导致服务器无法正常运行或响应请求。
- 服务器配置不当,如线程数、连接数、超时时间等,导致服务器无法处理高并发的请求。
- 代码逻辑错误,如空指针、数组越界、类型转换等,导致服务器抛出异常或崩溃。
- 数据库操作错误,如 SQL 语句、事务处理、连接池等,导致服务器无法访问或操作数据库。
既然是请求成功的为什么还会报代码错误呢?这可能是由于以下几种原因:
- 请求成功的只是指请求能够到达服务器,并不一定表示请求能够得到正确的响应。服务器在处理请求时可能会遇到代码错误,导致返回 500 错误。
- 请求成功的只是指请求能够得到响应,并不一定表示响应能够满足预期。服务器在返回响应时可能会遇到代码错误,导致返回错误的数据或格式。
- 请求成功的只是指部分请求能够正常处理,并不一定表示所有请求都能够正常处理。服务器在处理高并发的请求时可能会遇到代码错误,导致部分请求失败。
如何使用jmeter进行压测
压测完整步骤
对app服务端压测分为两个步骤:
1、使用fildder工具进行抓包
2、根据抓取的信息在jmeter上创建测试计划,并填写抓取信息。(这里可通过fildder 导出jmx脚本供jmeter使用)
Fiddler是一款可以抓取HTTP/HTTPS/FTP请求的工具,它可以通过代理的方式拦截和修改网络流量,从而获取app应用的请求链接和请求头等信息。要使用Fiddler抓取app应用的请求,您需要做以下几个步骤:
- 在电脑上安装Fiddler,并设置为允许远程连接和解密HTTPS请求。
- 在手机上设置网络代理为电脑的IP地址和Fiddler的端口号(默认为8888)。
- 在手机上安装Fiddler的根证书,并设置为信任。(如果是http协议此步骤可省略)
- 在手机上打开app应用,进行操作,然后在电脑上的Fiddler中查看抓取到的请求和响应。
具体的操作方法和截图,您可以参考以下链接:
- 十六、Fiddler抓包工具详细教程 — 抓取移动端App请求
- Fiddler如何对手机抓包?
- 全网最详细,Fiddler抓包实战 - 手机APP端https请求(超详细)
JMeter是一款可以进行性能测试和压力测试的工具,它可以根据Fiddler抓取到的请求信息来模拟用户并发访问app应用。要使用JMeter进行压测,您需要做以下几个步骤:
- 在电脑上安装JMeter,并启动JMeter GUI。
- 在JMeter中创建一个测试计划,并添加线程组、HTTP请求、断言、监听器等元件。
- 在HTTP请求中填写Fiddler抓取到的请求链接、请求方法、请求参数、请求头等信息。
- 在线程组中设置线程数、循环次数、启动时间等参数。
- 在监听器中选择要查看的结果报告或图表。
- 点击运行按钮,开始压测,并观察结果。
如果您要抓取的协议是HTTP协议,那么Fiddler的操作方法和上述操作基本一致,只是不需要安装和信任Fiddler的根证书,也不需要设置解密HTTPS请求。您只需要在手机上设置网络代理为电脑的IP地址和Fiddler的端口号(默认为8888),然后在手机上打开app应用,进行操作,就可以在电脑上的Fiddler中查看抓取到的HTTP请求和响应。
JMeter的操作方法也和我之前回答的基本一致,只是不需要在HTTP请求中填写SSL管理器或Keystore配置元件。您只需要在HTTP请求中填写Fiddler抓取到的请求链接、请求方法、请求参数、请求头等信息,然后在线程组中设置线程数、循环次数、启动时间等参数,就可以开始压测。
如果您想要简便的操作方式,您可以尝试使用Fiddler的导出功能,将抓取到的请求导出为JMeter脚本文件(.jmx格式),然后在JMeter中直接打开该文件,就可以看到已经配置好的测试计划。
jmeter中结构树
测试计划-》线程组-》控制器-》Http Request-》(请求头、提取器、响应断言)

jmeter中,常用的监听器
View Result Tree ( 结果查看树)、Aggregate Report(聚合报告)、Asserssion Result(断言结果)
聚合报告中各个参数
聚合报告是一种常用的性能测试结果分析工具,它可以显示每个请求的统计信息,如响应时间、吞吐量、错误率等。
聚合报告的各个参数的含义如下:
- Label:请求的名称,就是脚本中Sampler的名称。
- Samples:总共发给服务器的请求数量,如果模拟10个用户,每个用户迭代10次,那么总的请求数为:10*10 =100次。
- Average:默认情况下是单个Request的平均响应时间,当使用了Transaction Controller(事务控制器)时,也可以用Transaction的时间,来显示平均响应时间,单位是毫秒。
- Median:中位数,50%用户的响应时间小于该值,注意它与Average平均响应时间的区别。
- 90% Line:90%用户的响应时间小于该值,表示有90%的请求耗时都在这个时间之内。
- 95% Line:95%用户的响应时间小于该值,表示有95%的请求耗时都在这个时间之内。
- 99% Line:99%用户的响应时间小于该值,表示有99%的请求耗时都在这个时间之内。
- Min:最小的响应时间。
- Max:最大的响应时间。
- Error%:错误率=错误请求的数量/请求的总数。
- Throughput:默认情况下表示每秒完成的请求数(Request per Second)。
- Received KB/sec:每秒从服务器端接收到的数据量。
- Sent KB/sec:每秒发送到服务器端的数据量。
结果树报告

spring boot默认参数配置
这是因为在springboot项目中,内置的tomcat服务器就已经设置了并发的参数。主要有四个参数比较重要,如下是默认配置
server.tomcat.accept-count=100 # 设置请求队列的最大长度 server.tomcat.max-connections=10000 # 设置最大连接数 server.tomcat.max-threads=200 # 设置最大工作线程数 server.tomcat.min-spare-threads=10 # 设置最小空闲线程数
这四个参数是指 Spring Boot 内置 tomcat 的配置参数,分别是:
- server.tomcat.accept-count:设置请求队列的最大长度,即当所有可用线程都被占用时,可以放入队列中等待的请求的个数。
- server.tomcat.max-connections:设置最大连接数,即 tomcat 可以同时处理的最大请求数。
- server.tomcat.max-threads:设置最大工作线程数,即 tomcat 可以同时运行的最大线程数。
- server.tomcat.min-spare-threads:设置最小空闲线程数,即 tomcat 在运行时保持的最小空闲线程数。
这四个参数的含义可以用一个生活中的案例来类比,例如:
假设有一个快餐店,它有一个柜台和一个厨房。柜台负责接收顾客的订单,厨房负责制作食物。我们可以把这个快餐店看作是一个 tomcat 服务器,把顾客看作是请求,把柜台和厨房看作是线程。
那么,这四个参数就相当于:
- server.tomcat.accept-count:柜台后面有一个等候区,可以容纳一定数量的顾客排队等待。当柜台和厨房都忙不过来时,新来的顾客就会进入等候区。如果等候区也满了,那么新来的顾客就会被拒绝服务。这个等候区的容量就相当于请求队列的最大长度。
- server.tomcat.max-connections:快餐店有一个门槛,限制了同时进入店内的顾客数量。当店内已经达到门槛限制时,新来的顾客就不能进入店内,只能在门外等待。这个门槛限制就相当于最大连接数。
- server.tomcat.max-threads:快餐店有一定数量的员工,包括柜台和厨房的工作人员。每个员工可以同时为一个顾客提供服务,例如接单或制作食物。当所有员工都在忙时,新来的顾客就要等待空闲的员工。这个员工数量就相当于最大工作线程数。
- server.tomcat.min-spare-threads:快餐店为了保证服务质量和效率,会保持一定数量的空闲员工,以应对突发的高峰期或异常情况。这些空闲员工可以随时接手新来的顾客或替换出现问题的员工。这个空闲员工数量就相当于最小空闲线程数。
在使用过程中,如何配置这四个参数取决于您的应用程序的性能需求和实际情况。一般来说,您可以参考以下的原则:
- server.tomcat.accept-count:建议设置为一个较大的值,以免在高并发情况下拒绝过多的请求。但是也不能设置过大,以免造成内存溢出或响应延迟。
- server.tomcat.max-connections:建议设置为一个较大的值,以免在高并发情况下拒绝过多的请求。但是也不能设置过大,以免超过服务器或网络设备的承载能力。
- server.tomcat.max-threads:建议根据服务器的 CPU 核心数和应用程序的业务逻辑来设置一个合理的值。一般来说,可以设置为 CPU 核心数的 2 倍或 4 倍。如果设置过小,会导致线程不足,无法处理所有的请求。如果设置过大,会导致线程切换开销过大,影响性能。
- server.tomcat.min-spare-threads:建议设置为一个较小的值,以免浪费资源。但是也不能设置为 0,以免在高并发情况下无法及时响应请求。
机器的配置是影响这四个参数的重要因素,主要包括 CPU、内存、网络等方面。一般来说,机器的配置越高,就可以支持更高的并发数和更快的响应速度。但是,机器的配置并不是唯一的决定因素,还需要考虑应用程序的代码质量、业务逻辑、缓存策略、数据库优化等方面。
也就是说,当100个请求同时进来后,当前配置能处理的最大并发数 = max-threads + accept-count(队列数)
请求的超时时间是如何影响并发的呢?
如果在请求响应中超时,那么一般来说就会占用一定的资源,增加了服务器的负载,所以必要的请求超时时间的设置也是必不可少的。
链接服务器的超时时间是指客户端在发送请求后,等待服务器响应的最大时间。如果在这个时间内,客户端没有收到服务器的响应,那么客户端就会认为请求失败,抛出一个超时异常。
链接服务器的超时时间是如何影响并发的呢?一般来说,链接服务器的超时时间越短,就可以支持更高的并发数,但是也会增加请求失败的风险。链接服务器的超时时间越长,就可以降低请求失败的风险,但是也会占用更多的资源,限制并发数。
为什么会这样呢?我们可以用一个生活中的例子来类比,例如:
假设有一个银行,它有一个柜台和一个后台系统。柜台负责接收客户的业务请求,后台系统负责处理业务逻辑。我们可以把这个银行看作是一个客户端,把后台系统看作是一个服务器。
那么,链接服务器的超时时间就相当于柜台等待后台系统响应的最大时间。如果在这个时间内,柜台没有收到后台系统的响应,那么柜台就会认为业务失败,向客户道歉并结束服务。
如果链接服务器的超时时间设置得很短,比如 1 分钟,那么柜台就可以快速地处理每个客户的业务请求,不会占用太多的资源,可以支持更多的客户同时办理业务。但是,如果后台系统处理业务逻辑需要花费较长的时间,或者出现了网络延迟或故障等情况,那么柜台就有可能在 1 分钟内没有收到后台系统的响应,导致业务失败。
如果链接服务器的超时时间设置得很长,比如 10 分钟,那么柜台就可以降低业务失败的风险,即使后台系统处理业务逻辑需要花费较长的时间,或者出现了网络延迟或故障等情况,柜台也可以等待更久地收到后台系统的响应。但是,如果柜台处理每个客户的业务请求需要花费较长的时间,那么柜台就会占用更多的资源,无法支持更多的客户同时办理业务。
因此,在设置链接服务器的超时时间时,需要根据实际情况和需求来进行权衡和调整。一般来说,可以参考以下的原则:
- 链接服务器的超时时间应该设置为一个合理的值,既不能过短也不能过长。过短会导致请求失败率过高,影响用户体验和服务质量。过长会导致资源浪费和性能下降,影响并发能力和服务效率。
- 链接服务器的超时时间应该根据服务器的处理能力和网络状况来动态调整。如果服务器处理能力强大且网络状况良好,那么可以适当缩短超时时间。如果服务器处理能力不足或网络状况不稳定,那么可以适当延长超时时间。
- 链接服务器的超时时间应该根据请求类型和优先级来区分设置。如果请求类型比较简单或优先级比较高,那么可以设置较短的超时时间。如果请求类型比较复杂或优先级比较低,那么可以设置较长的超时时间。
在spring boot项目中,有很多可能的超时时间需要配置:
1、zuul网关
#默认1000
zuul.host.socket-timeout-millis=2000
#默认2000
zuul.host.connect-timeout-millis=4000
2、ribbon
ribbon:
OkToRetryOnAllOperations: false #对所有操作请求都进行重试,默认false
ReadTimeout: 5000 #负载均衡超时时间,默认值5000
ConnectTimeout: 3000 #ribbon请求连接的超时时间,默认值2000
MaxAutoRetries: 0 #对当前实例的重试次数,默认0
MaxAutoRetriesNextServer: 1 #对切换实例的重试次数,默认1
3、熔断器Hixtry
hystrix:
command:
default: #default全局有效,service id指定应用有效
execution:
timeout:
#如果enabled设置为false,则请求超时交给ribbon控制,为true,则超时作为熔断根据
enabled: true
isolation:
thread:
timeoutInMilliseconds: 1000 #断路器超时时间,默认1000ms
feign.hystrix.enabled: true
- 如果hystrix.command.default.execution.timeout.enabled为true,则会有两个执行方法超时的配置,一个就是ribbon的ReadTimeout,一个就是熔断器hystrix的timeoutInMilliseconds, 此时谁的值小谁生效
- 如果hystrix.command.default.execution.timeout.enabled为false,则熔断器不进行超时熔断,而是根据ribbon的ReadTimeout抛出的异常而熔断,也就是取决于ribbon
- ribbon的ConnectTimeout,配置的是请求服务的超时时间,除非服务找不到,或者网络原因,这个时间才会生效
- ribbon还有MaxAutoRetries是单个实例的重试次数,MaxAutoRetriesNextServer对切换实例的次数(是切换次数,不是重试次数), 如果ribbon的ReadTimeout超时,或者ConnectTimeout连接超时,会进行重试操作
- 由于ribbon的重试机制,通常熔断的超时时间需要配置的比ReadTimeout长,ReadTimeout比ConnectTimeout长,否则还未重试,就熔断了
- 为了确保重试机制的正常运作,理论上(以实际情况为准)建议hystrix的超时时间为:(1 + MaxAutoRetries)*(1+ MaxAutoRetriesNextServer) * ReadTimeout.
如下合适的配置:
ribbon:
OkToRetryOnAllOperations: false #对所有操作请求都进行重试,默认false
ReadTimeout: 10000 #负载均衡超时时间,默认值5000
ConnectTimeout: 2000 #ribbon请求连接的超时时间,默认值2000
MaxAutoRetries: 0 #对当前实例的重试次数,默认0
MaxAutoRetriesNextServer: 1 #切换实例的次数,默认1
hystrix:
command:
default: #default全局有效,service id指定应用有效
execution:
timeout:
enabled: true
isolation:
thread:
timeoutInMilliseconds: 20000 #断路器超时时间,默认1000ms
4、 配置Http会话超时
- 可以通过两种方式为Spring Boot应用程序配置HTTP会话超时。
application.properties中配置会话超时
最简单的方法是在你的application.properties中加入参数server.servlet.session.timeout。比如说
server.servlet.session.timeout=60s
还要注意的是,Tomcat不允许你将超时时间设置得少于60秒。
- 以程序方式配置会话超时
假设我们想让我们的HttpSession只持续两分钟。为了实现这一点,我们可以在我们的WebConfiguration类中添加一个EmbeddedServletContainerCustomizer Bean,内容如下。
@Configuration
public class WebConfiguration {
@Bean
public EmbeddedServletContainerCustomizer embeddedServletContainerCustomizer() {
return new EmbeddedServletContainerCustomizer() {
@Override
public void customize(ConfigurableEmbeddedServletContainer container) {
container.setSessionTimeout(2, TimeUnit.MINUTES);
}
};
}
使用Java 8和lambda表达式的捷径写法。
public EmbeddedServletContainerCustomizer embeddedServletContainerCustomizer() {
return (ConfigurableEmbeddedServletContainer container) -> {
container.setSessionTimeout(2, TimeUnit.MINUTES);
};
}
在应用程序启动期间,Spring Boot自动配置检测到EmbeddedServletContainerCustomizer,并调用customize(…)方法,传递对Servlet容器的引用。
5、配置接口访问超时
一、配置文件方式
在配置文件application.properties中加了spring.mvc.async.request-timeout=120000,意思是设置超时时间为120000ms即120s
spring.mvc.async.request-timeout=120000
二、配置Config配置类
还有一种就是在config配置类中加入:
public class WebMvcConfig extends WebMvcConfigurerAdapter {
@Override
public void configureAsyncSupport(final AsyncSupportConfigurer configurer) {
configurer.setDefaultTimeout(20000);
configurer.registerCallableInterceptors(timeoutInterceptor());
}
@Bean
public TimeoutCallableProcessingInterceptor timeoutInterceptor() {
return new TimeoutCallableProcessingInterceptor();
}
}
6、Nginx的设置
如果服务端使用到Nginx做了反向代理转发请求,就需要在Nginx的配置文件nginx.conf中设置超时时间,否则会返回“java.io.IOException: 你的主机中的软件中止了一个已建立的连接”这样的异常提示。
未设置时Nginx响应时间默认60秒,这里将http头部的keepalive_timeout 、client_header_timeout 、client_body_timeout 、send_timeout 、以及server代码块中的proxy_read_timeout 均配置为120秒。
http {
include mime.types;
default_type application/octet-stream;
client_max_body_size 100m;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 120; #连接超时时间,服务器将会在这个时间后关闭连接
send_timeout 120; #发送超时时间
client_header_timeout 120; #请求头的超时时间
client_body_timeout 120; #请求体的读超时时间
#gzip on;
#业务系统的配置
server {
listen 9092;
server_name localhost;
location / {
proxy_pass http://127.0.0.1:8811/mywebsev/;
proxy_read_timeout 120; # 等候后端服务器响应时间 秒
}
}
bytes_sent “KaTeX parse error: Expected 'EOF', got '#' at position 21: …referer" ' #̲ …http_user_agent” “$http_x_forwarded_for”';
```nginx
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 120; #连接超时时间,服务器将会在这个时间后关闭连接
send_timeout 120; #发送超时时间
client_header_timeout 120; #请求头的超时时间
client_body_timeout 120; #请求体的读超时时间
#gzip on;
#业务系统的配置
server {
listen 9092;
server_name localhost;
location / {
proxy_pass http://127.0.0.1:8811/mywebsev/;
proxy_read_timeout 120; # 等候后端服务器响应时间 秒
}
}