JPA框架
文章目录
- JPA框架
- 认识SpringData JPA
- 使用JPA快速上手
- 方法名称拼接自定义SQL
- 关联查询
- JPQL自定义SQL语句

在我们之前编写的项目中,我们不难发现,实际上大部分的数据库交互操作,到最后都只会做一个事情,那就是把数据库中的数据映射为Java中的对象。比如我们要通过用户名去查找对应的用户,或是通过ID查找对应的学生信息,在使用Mybatis时,我们只需要编写正确的SQL语句就可以直接将获取的数据映射为对应的Java对象,通过调用Mapper中的方法就能直接获得实体类,这样就方便我们在Java中数据库表中的相关信息了。
但是以上这些操作都有一个共性,那就是它们都是通过某种条件去进行查询,而最后的查询结果,都是一个实体类,所以你会发现你写的很多SQL语句都是一个套路select * from xxx where xxx=xxx,实际上对于这种简单SQL语句,我们完全可以弄成一个模版来使用,那么能否有一种框架,帮我们把这些相同的套路给封装起来,直接把这类相似的SQL语句给屏蔽掉,不再由我们编写,而是让框架自己去组合拼接。
认识SpringData JPA
首先我们来看一个国外的统计:

在国外JPA几乎占据了主导地位,而Mybatis并不像国内那样受待见,所以你会发现,JPA都有SpringBoot的官方直接提供的starter,而Mybatis没有,直到SpringBoot 3才开始加入到官方模版中。
那么,什么是JPA:
JPA(Java Persistence API)和JDBC类似,也是官方定义的一组接口,但是它相比传统的JDBC,它是为了实现ORM而生的,即Object-Relationl Mapping,它的作用是在关系型数据库和对象之间形成一个映射,这样,我们在具体的操作数据库的时候,就不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作它就可以了。
其中比较常见的JPA实现有:
- Hibernate:Hibernate是JPA规范的一个具体实现,也是目前使用最广泛的JPA实现框架之一。它提供了强大的对象关系映射功能,可以将Java对象映射到数据库表中,并提供了丰富的查询语言和缓存机制。
- EclipseLink:EclipseLink是另一个流行的JPA实现框架,由Eclipse基金会开发和维护。它提供了丰富的特性,如对象关系映射、缓存、查询语言和连接池管理等,并具有较高的性能和可扩展性。
- OpenJPA:OpenJPA是Apache基金会的一个开源项目,也是JPA规范的一个实现。它提供了高性能的JPA实现和丰富的特性,如延迟加载、缓存和分布式事务等。
- TopLink:TopLink是Oracle公司开发的一个对象关系映射框架,也是JPA规范的一个实现。虽然EclipseLink已经取代了TopLink成为Oracle推荐的JPA实现,但TopLink仍然得到广泛使用。
JPA:具体的实现交给框架,我们只需要一一对应自己设置的实体类就行,方便很多
而实现JPA规范的框架一般最常用的就是Hibernate,它是一个重量级框架,学习难度相比Mybatis也更高一些,而SpringDataJPA也是采用Hibernate框架作为底层实现,并对其加以封装。
官网:https://spring.io/projects/spring-data-jpa
使用JPA快速上手
同样的,我们只需要导入stater依赖即可:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
接着我们可以直接创建一个类,比如用户类,只需要把一个账号对应的属性全部定义好即可:
@Data
public class Account {
int id;
String username;
String password;
}
通过注解形式在属性上添加数据库映射关系,这样就能够让JPA知道我们的实体类对应的数据库表长啥样,这里用到了很多注解:
@Data
@Entity //表示这个类是一个实体类
@Table(name = "account") //对应的数据库中表名称
public class Account {
@GeneratedValue(strategy = GenerationType.IDENTITY) //生成策略,这里配置为自增
@Column(name = "id") //对应表中id这一列
@Id //此属性为主键
int id;
@Column(name = "username") //对应表中username这一列
String username;
@Column(name = "password") //对应表中password这一列
String password;
}
接着修改配置文件,把日志打印给打开:
spring:
jpa:
#开启SQL语句执行日志信息
show-sql: true
hibernate:
#配置为检查数据库表结构,没有时会自动创建
ddl-auto: update
ddl-auto属性用于设置自动表定义,可以实现自动在数据库中为我们创建一个表,表的结构会根据我们定义的实体类决定,它有以下几种:
none: 不执行任何操作,数据库表结构需要手动创建。create: 框架在每次运行时都会删除所有表,并重新创建。create-drop: 框架在每次运行时都会删除所有表,然后再创建,但在程序结束时会再次删除所有表。update: 框架会检查数据库表结构,如果与实体类定义不匹配,则会做相应的修改,以保持它们的一致性。validate: 框架会检查数据库表结构与实体类定义是否匹配,如果不匹配,则会抛出异常。
这个配置项的作用是为了避免手动管理数据库表结构,使开发者可以更方便地进行开发和测试,但在生产环境中,更推荐使用数据库迁移工具来管理表结构的变更。
我们可以在日志中发现,在启动时执行了如下SQL语句:

我们的数据库中对应的表已经自动创建好了
接着来看如何访问表,需要创建一个Repository实现类:
@Repository
public interface AccountRepository extends JpaRepository<Account, Integer> {
}
注意JpaRepository有两个泛型,前者是具体操作的对象实体,也就是对应的表,后者是ID的类型,接口中已经定义了比较常用的数据库操作。编写接口继承即可,可以直接注入此接口获得实现类:
@Resource
AccountRepository repository;
@Test
void contextLoads() {
Account account = new Account();
account.setUsername("小红");
account.setPassword("1234567");
System.out.println(repository.save(account).getId()); //使用save来快速插入数据,并且会返回插入的对象,如果存在自增ID,对象的自增id属性会自动被赋值,这就很方便了
}
执行结果如下:

同时,查询操作也很方便:
@Test
void contextLoads() {
//默认通过通过ID查找的方法,并且返回的结果是Optional包装的对象,非常人性化
repository.findById(1).ifPresent(System.out::println);
}
得到结果为:

包括常见的一些计数、删除操作等都包含在里面,仅仅配置应该接口就能完美实现增删改查:
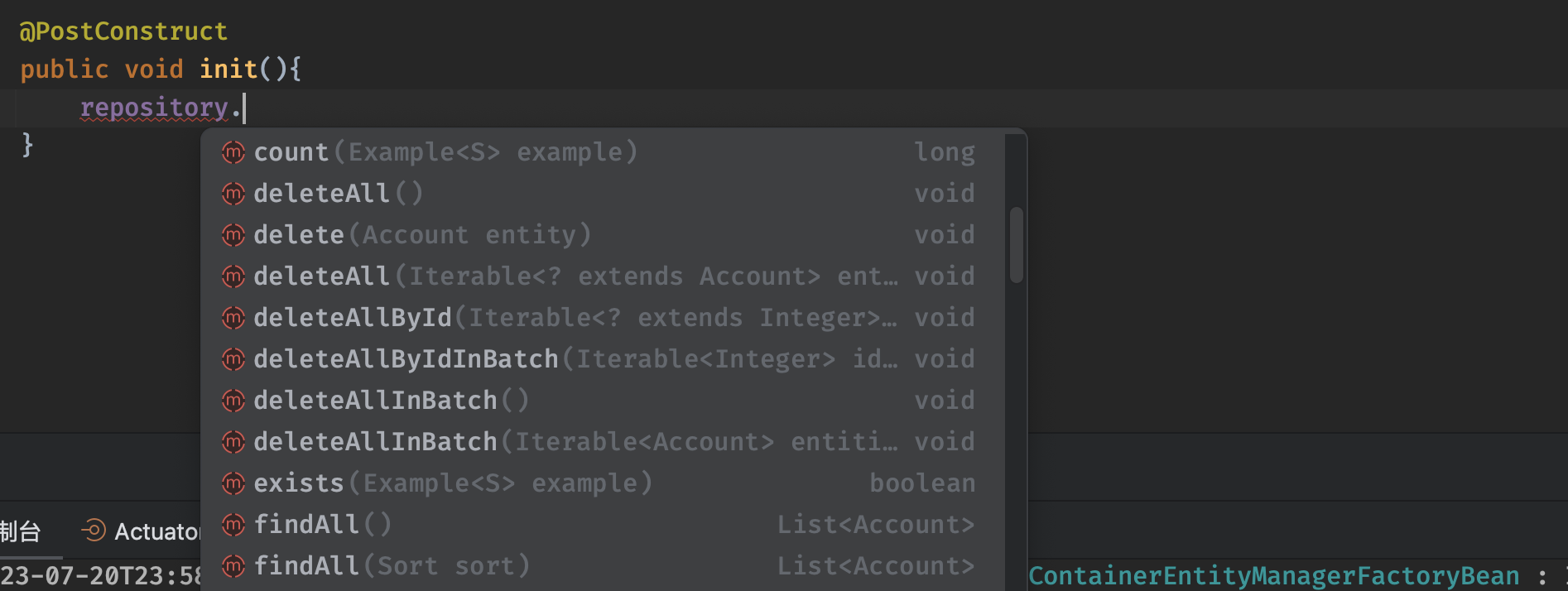
我们发现,使用了JPA之后,整个项目的代码中没有出现任何的SQL语句,可以说是非常方便了,JPA依靠我们提供的注解信息自动完成了所有信息的映射和关联。
相比Mybatis,JPA几乎就是一个全自动的ORM框架,而Mybatis则顶多算是半自动ORM框架。
方法名称拼接自定义SQL
虽然接口预置的方法使用起来非常方便,但是如果我们需要进行条件查询等操作或是一些判断,就需要自定义一些方法来实现,同样的,我们不需要编写SQL语句,而是通过方法名称的拼接来实现条件判断,这里列出了所有支持的条件判断名称:
| 属性 | 拼接方法名称示例 | 执行的语句 |
|---|---|---|
| Distinct | findDistinctByLastnameAndFirstname | select distinct … where x.lastname = ?1 and x.firstname = ?2 |
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstname,findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull,Null | findByAge(Is)Null | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1(参数与附加%绑定) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1(参数与前缀%绑定) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1(参数绑定以%包装) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection ages) | … where x.age not in ?1 |
| True | findByActiveTrue | … where x.active = true |
| False | findByActiveFalse | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstname) = UPPER(?1) |
比如我们想要实现根据用户名模糊匹配查找用户:
@Repository
public interface AccountRepository extends JpaRepository<Account, Integer> {
//按照表中的规则进行名称拼接,不用刻意去记,IDEA会有提示
List<Account> findAllByUsernameLike(String str);
}
测试一下:
@Test
void contextLoads() {
repository.findAllByUsernameLike("%明%").forEach(System.out::println);
}

同时根据用户名和ID一起查询:
@Repository
public interface AccountRepository extends JpaRepository<Account, Integer> {
List<Account> findAllByUsernameLike(String str);
Account findByIdAndUsername(int id, String username);
//也可以使用Optional类进行包装,Optional<Account> findByIdAndUsername(int id, String username);
}
@Test
void contextLoads() {
System.out.println(repository.findByIdAndUsername(1, "小明"));
}
想判断数据库中是否存在某个ID的用户:
@Repository
public interface AccountRepository extends JpaRepository<Account, Integer> {
List<Account> findAllByUsernameLike(String str);
Account findByIdAndUsername(int id, String username);
//使用exists判断是否存在
boolean existsAccountById(int id);
}
注意自定义条件操作的方法名称一定要遵循规则,不然会出现异常:
Caused by: org.springframework.data.repository.query.QueryCreationException: Could not create query for public abstract ...
有了这些操作,我们在编写一些简单SQL的时候就很方便了,用久了甚至直接忘记SQL怎么写。
关联查询
在实际开发中,比较常见的场景还有关联查询,也就是我们会在表中添加一个外键字段,而此外键字段又指向了另一个表中的数据,当我们查询数据时,可能会需要将关联数据也一并获取,比如我们想要查询某个用户的详细信息,一般用户简略信息会单独存放一个表,而用户详细信息会单独存放在另一个表中。当然,除了用户详细信息之外,可能在某些电商平台还会有用户的购买记录、用户的购物车,交流社区中的用户帖子、用户评论等,这些都是需要根据用户信息进行关联查询的内容。
在JPA中,每张表实际上就是一个实体类的映射,而表之间的关联关系,也可以看作对象之间的依赖关系,比如用户表中包含了用户详细信息的ID字段作为外键,那么实际上就是用户表实体中包括了用户详细信息实体对象:
@Data
@Entity
@Table(name = "users_detail")
public class AccountDetail {
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Id
int id;
@Column(name = "address")
String address;
@Column(name = "email")
String email;
@Column(name = "phone")
String phone;
@Column(name = "real_name")
String realName;
}
而用户信息和用户详细信息之间形成了一对一的关系,那么这时直接在类中指定这种关系:
@Data
@Entity
@Table(name = "users")
public class Account {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
@Id
int id;
@Column(name = "username")
String username;
@Column(name = "password")
String password;
@JoinColumn(name = "detail_id") //指定存储外键的字段名称
@OneToOne //声明为一对一关系
AccountDetail detail;
}
在修改实体类信息后,我们发现在启动时也进行了更新,日志如下:

接着往用户详细信息中添加一些数据,一会可以直接进行查询:
@Test
void pageAccount() {
repository.findById(1).ifPresent(System.out::println);
}
查询后,可以发现,得到如下结果:

也就是,在建立关系之后,我们查询Account对象时,会自动将关联数据的结果也一并进行查询。
那要是我们只想要Account的数据,不想要用户详细信息数据怎么办呢?我希望在我要用的时候再获取详细信息,这样可以节省一些网络开销,我们可以设置懒加载,这样只有在需要时才会向数据库获取:
@JoinColumn(name = "detail_id")
@OneToOne(fetch = FetchType.LAZY) //将获取类型改为LAZY
AccountDetail detail;
接着测试一下:
@Transactional //懒加载属性需要在事务环境下获取,因为repository方法调用完后Session会立即关闭
@Test
void pageAccount() {
repository.findById(1).ifPresent(account -> {
System.out.println(account.getUsername()); //获取用户名
System.out.println(account.getDetail()); //获取详细信息(懒加载)
});
}
接着来看看控制台输出了什么:
Hibernate: select account0_.id as id1_0_0_, account0_.detail_id as detail_i4_0_0_, account0_.password as password2_0_0_, account0_.username as username3_0_0_ from users account0_ where account0_.id=?
Test
Hibernate: select accountdet0_.id as id1_1_0_, accountdet0_.address as address2_1_0_, accountdet0_.email as email3_1_0_, accountdet0_.phone as phone4_1_0_, accountdet0_.real_name as real_nam5_1_0_ from users_detail accountdet0_ where accountdet0_.id=?
AccountDetail(id=1, address=四川省成都市青羊区, email=8371289@qq.com, phone=1234567890, realName=卢本)
可以看到,获取用户名之前,并没有去查询用户的详细信息,而是当我们获取详细信息时才进行查询并返回AccountDetail对象。
也可以在添加数据时,利用实体类之间的关联信息,一次性添加两张表的数据:需要稍微修改一下级联关联操作设定:
@JoinColumn(name = "detail_id")
@OneToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL) //设置关联操作为ALL
AccountDetail detail;
- ALL:所有操作都进行关联操作
- PERSIST:插入操作时才进行关联操作
- REMOVE:删除操作时才进行关联操作
- MERGE:修改操作时才进行关联操作
可以多个并存,接着进行一下测试:
@Test
void addAccount(){
Account account = new Account();
account.setUsername("Nike");
account.setPassword("123456");
AccountDetail detail = new AccountDetail();
detail.setAddress("重庆市渝中区解放碑");
detail.setPhone("1234567890");
detail.setEmail("73281937@qq.com");
detail.setRealName("张三");
account.setDetail(detail);
account = repository.save(account);
System.out.println("插入时,自动生成的主键ID为:"+account.getId()+",外键ID为:"+account.getDetail().getId());
}
可以看到日志结果:
Hibernate: insert into users_detail (address, email, phone, real_name) values (?, ?, ?, ?)
Hibernate: insert into users (detail_id, password, username) values (?, ?, ?)
插入时,自动生成的主键ID为:6,外键ID为:3
结束后会发现数据库中两张表都同时存在数据。
接着我们来看一对多关联,比如每个用户的成绩信息:
@JoinColumn(name = "uid") //注意这里的name指的是Score表中的uid字段对应的就是当前的主键,会将uid外键设置为当前的主键
@OneToMany(fetch = FetchType.LAZY, cascade = CascadeType.REMOVE) //在移除Account时,一并移除所有的成绩信息,依然使用懒加载
List<Score> scoreList;
@Data
@Entity
@Table(name = "users_score") //成绩表,注意只存成绩,不存学科信息,学科信息id做外键
public class Score {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
@Id
int id;
@OneToOne //一对一对应到学科上
@JoinColumn(name = "cid")
Subject subject;
@Column(name = "socre")
double score;
@Column(name = "uid")
int uid;
}
@Data
@Entity
@Table(name = "subjects") //学科信息表
public class Subject {
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "cid")
@Id
int cid;
@Column(name = "name")
String name;
@Column(name = "teacher")
String teacher;
@Column(name = "time")
int time;
}
在数据库中填写相应数据,接着我们就可以查询用户的成绩信息了:
@Transactional
@Test
void test() {
repository.findById(1).ifPresent(account -> {
account.getScoreList().forEach(System.out::println);
});
}
成功得到用户所有的成绩信息,包括得分和学科信息。
同样的,我们还可以将对应成绩中的教师信息单独分出一张表存储,并建立多对一的关系,因为多门课程可能由同一个老师教授(千万别搞晕了,一定要理清楚关联关系,同时也是考验你的基础扎不扎实):
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "tid") //存储教师ID的字段,和一对一是一样的,也会当前表中创个外键
Teacher teacher;
接着就是教师实体类了:
@Data
@Entity
@Table(name = "teachers")
public class Teacher {
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Id
int id;
@Column(name = "name")
String name;
@Column(name = "sex")
String sex;
}
最后我们再进行一下测试:
@Transactional
@Test
void test() {
repository.findById(3).ifPresent(account -> {
account.getScoreList().forEach(score -> {
System.out.println("课程名称:"+score.getSubject().getName());
System.out.println("得分:"+score.getScore());
System.out.println("任课教师:"+score.getSubject().getTeacher().getName());
});
});
}
成功得到多对一的教师信息。
最后我们再来看最复杂的情况,现在我们一门课程可以由多个老师教授,而一个老师也可以教授多个课程,那么这种情况就是很明显的多对多场景,现在又该如何定义呢?我们可以像之前一样,插入一张中间表表示教授关系,这个表中专门存储哪个老师教哪个科目:
@ManyToMany(fetch = FetchType.LAZY) //多对多场景
@JoinTable(name = "teach_relation", //多对多中间关联表
joinColumns = @JoinColumn(name = "cid"), //当前实体主键在关联表中的字段名称
inverseJoinColumns = @JoinColumn(name = "tid") //教师实体主键在关联表中的字段名称
)
List<Teacher> teacher;
接着,JPA会自动创建一张中间表,并自动设置外键,我们就可以将多对多关联信息编写在其中了。
JPQL自定义SQL语句
虽然SpringDataJPA能够简化大部分数据获取场景,但是难免会有一些特殊的场景,需要使用复杂查询才能够去完成,这时你又会发现,如果要实现,只能用回Mybatis了,因为我们需要自己手动编写SQL语句,过度依赖SpringDataJPA会使得SQL语句不可控。
使用JPA,我们也可以像Mybatis那样,直接编写SQL语句,不过它是JPQL语言,与原生SQL语句很类似,但是它是面向对象的,当然我们也可以编写原生SQL语句。
比如我们要更新用户表中指定ID用户的密码:
@Repository
public interface AccountRepository extends JpaRepository<Account, Integer> {
@Transactional //DML操作需要事务环境,可以不在这里声明,但是调用时一定要处于事务环境下
@Modifying //表示这是一个DML操作
@Query("update Account set password = ?2 where id = ?1") //这里操作的是一个实体类对应的表,参数使用?代表,后面接第n个参数
int updatePasswordById(int id, String newPassword);
}
@Test
void updateAccount(){
repository.updatePasswordById(1, "654321");
}
现在我想使用原生SQL来实现根据用户名称修改密码:
@Transactional
@Modifying
@Query(value = "update users set password = :pwd where username = :name", nativeQuery = true) //使用原生SQL,和Mybatis一样,这里使用 :名称 表示参数,当然也可以继续用上面那种方式。
int updatePasswordByUsername(@Param("name") String username, //我们可以使用@Param指定名称
@Param("pwd") String newPassword);
@Test
void updateAccount(){
repository.updatePasswordByUsername("Admin", "654321");
}
通过编写原生SQL,在一定程度上弥补了SQL不可控的问题。
虽然JPA能够为我们带来非常便捷的开发体验,但是正是因为太便捷了,尤其是一些国内用到复杂查询业务的项目,可能开发到后期特别庞大时,就只能从底层SQL语句开始进行优化,而由于JPA尽可能地在屏蔽我们对SQL语句的编写,所以后期优化是个大问题,并且Hibernate相对于Mybatis来说,更加重量级。不过,在微服务的时代,单体项目一般不会太大,JPA的劣势并没有太明显地体现出来。