ConcurrentHashMap
- 一. Hashtable
- 二. ConcurrentHashMap
- 三. 相关面试题
HashMap 本身不是线程安全的.
在多线程环境下使用哈希表可以使用:
- Hashtable
- ConcurrentHashMap
一. Hashtable
在关键方法加上了 synchronized 关键字.

- 这相当于直接针对 Hashtable 对象本身加锁.
- 如果多线程访问同一个 Hashtable 就会直接造成锁冲突.
- size 属性也是通过 synchronized 来控制同步, 也是比较慢的.
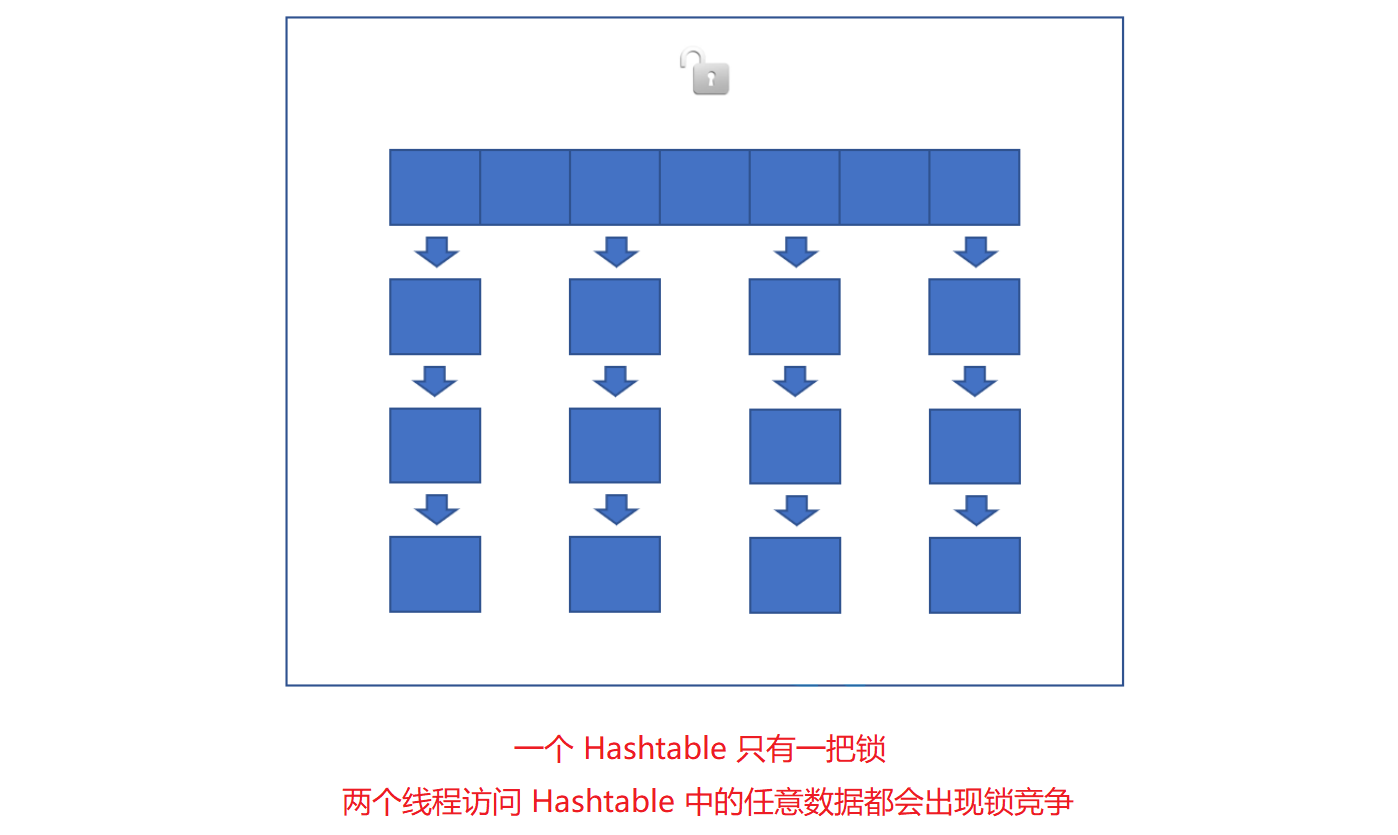
并且如果触发扩容, 就由该线程完成整个扩容过程. 这个过程会涉及到大量的元素拷贝, 效率会非常低,会导致这次 put 操作特别卡顿.
所以说多线程情况下不推荐使用 Hashtable, 而推荐使用 ConcurrentHashMap.
二. ConcurrentHashMap
相比于 Hashtable 做出了一系列的改进和优化.
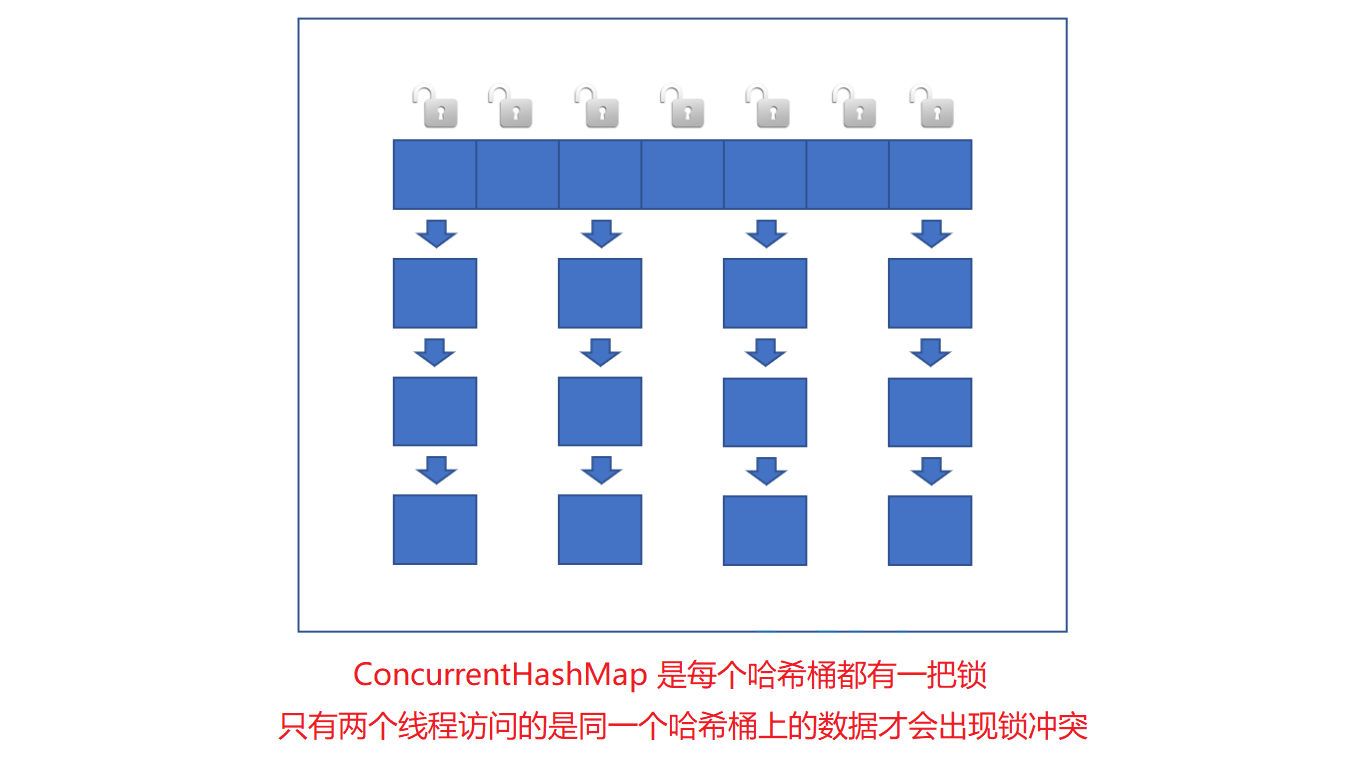
- 读操作没有加锁(但是使用了 volatile 保证从内存读取结果), 只对写操作加锁.
- 锁桶
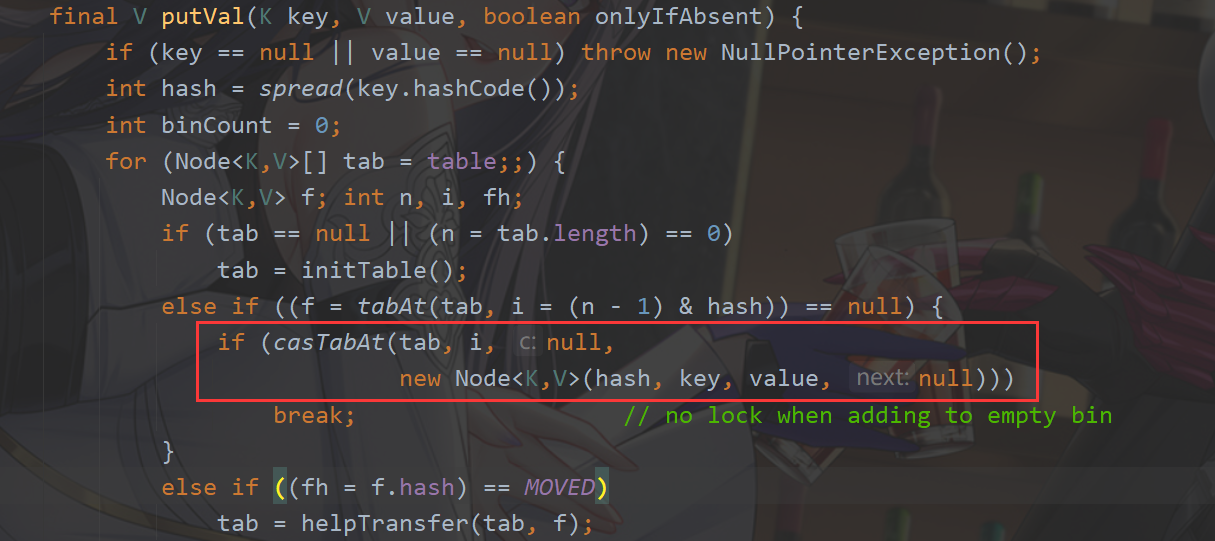
加锁的方式仍然是是用 synchronized, 但是不是锁整个对象, 而是 “锁桶” (用每个链表的头结点作为锁对象), 由于哈希表中的链表数目很多, 每个链表的长度相对较短, 所以能大大降低锁冲突的概率. - 充分利用 CAS 特性.
比如 putVal() 方法,使用 CAS 来确保在并发情况下正确设置节点的链表或红黑树. - 优化了扩容方式: 化整为零
发现需要扩容的线程, 只需要创建一个新的数组, 同时只搬几个元素过去.
扩容期间, 新老数组同时存在. 插入只往新数组加. 查找需要同时查新数组和老数组.
后续每个来操作 ConcurrentHashMap 的线程, 都会参与搬家的过程. 每个操作负责搬运一小部分元素. 搬完最后一个元素再把老数组删掉.
三. 相关面试题
-
ConcurrentHashMap 的读是否要加锁,为什么?
读操作没有加锁. 目的是为了进一步降低锁冲突的概率. 为了保证读到刚修改的数据, 搭配了 volatile 关键字. -
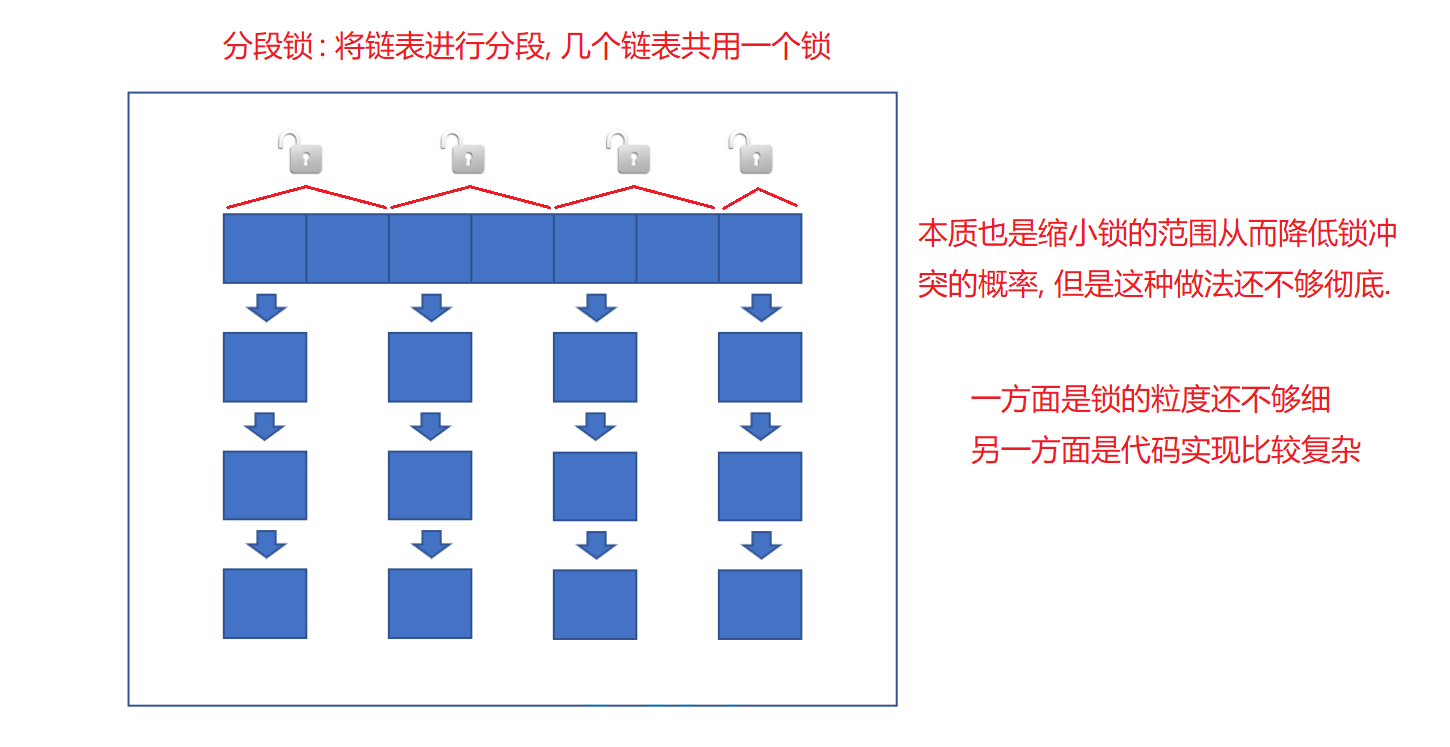
介绍下 ConcurrentHashMap的锁分段技术?
这个是 Java1.7 中采取的技术. Java1.8 中已经不再使用了.
- 简单的说就是把若干个哈希桶分成一个"段" (Segment), 针对每个段分别加锁.
- 目的也是为了降低锁竞争的概率. 当两个线程访问的数据恰好在同一个段上的时候, 才触发锁竞争.
- ConcurrentHashMap 在 jdk1.8 做了哪些优化?
- 取消了分段锁, 直接给每个哈希桶 (每个链表) 分配了一个锁 (就是以每个链表的头结点对象作为锁对象).
- 将原来 数组 + 链表 的实现方式改进成 数组 + 链表 / 红黑树 的方式. 当链表元素个数 >= 8 && 数组长度 >= 64 就转换成红黑树.
- Hashtable 和 HashMap、ConcurrentHashMap 之间的区别?
-
HashMap: 线程不安全. key 允许为 null, 对于 key 为 null, hash 值处理为 0.

-
Hashtable: 线程安全. 使用 synchronized 锁 Hashtable 对象, 效率较低. key 不允许为 null.

如果 key 为空, 调用 hashCode 时会抛异常 -
ConcurrentHashMap: 线程安全. 使用 synchronized 锁每个链表头结点, 锁冲突概率低, 充分利用 CAS 机制. 优化了扩容方式. key 不允许为 null

- ConcurrentHashMap 的优点:
- 减少了锁冲突,把锁加到每个链表的头节点上 (锁桶).
- 只针对写操作加锁, 读操作只是使用 volatile 关键字保证内存可见性.
- 更广泛使用 CAS,比如使用 CAS 来确保在并发情况下正确设置节点的链表或红黑树, 进一步提高效率.
- 扩容时使用巧妙的化整为零:
对于 Hashtable 扩容时创建更大的数组,把之前旧元素全搬过去,非常耗时,会使这次 put 非常卡顿.
对于 ConcurrentHashMap,每次操作只搬运一点点,通过多次操作完成整个搬运过程,同时维护一个新的 数组和一个旧的数组,查找时两个都查,插入时只插入新的,直到搬运完毕再销毁旧的.
好啦! 以上就是对 ConcurrentHashMap 的讲解,希望能帮到你 !
评论区欢迎指正 !









![[移动通讯]【Carrier Aggregation-4】【LTE-4】](https://img-blog.csdnimg.cn/bfd45e55e3a24bf3a3d524c3def0cd3b.png)