基础学习
- 数据类型转换
- 运算符
- 字符串
- 方法传递参数: 值传递
- 构造器
- String
- new关键字创建的对象则按对象方式去处理
- 静态代码块和实例代码块
- 静态代码块:
- 实例代码块:
- 多态
- 匿名内部类
- 格式:
- StringJoiner (JDK1.8)
- 小数计算BigDecimal
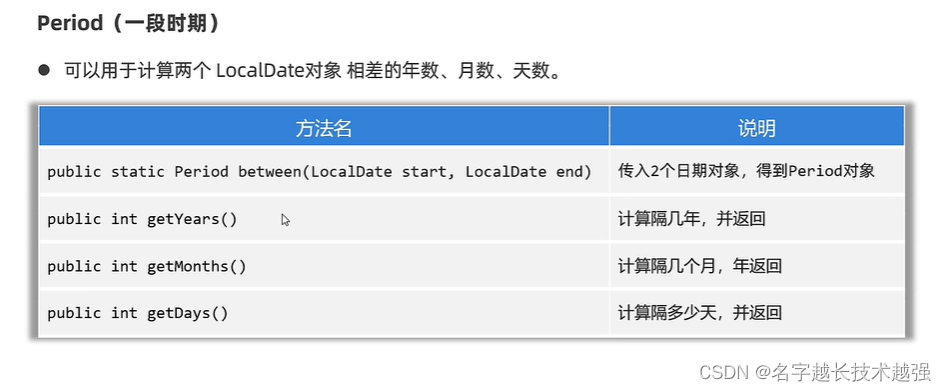
- 时间
- 时间
- 集合
- List 有序 有索引 重复
- ArrayList 低层(数组)
- LinkList 低层(双向链表)
- 双链表
- Set
- HashSet 无序 不重复 无索引
- 低层 哈希表(JDK1.8前:数组+链表 ;1.8后数组+链表+红黑树)
- LinkedHashSet 有序(双链表的机制) 不重复 无索引
- TreeSet 排序 不重复 无索引
- 排序:
- 可变参数
- 双列集合
- Map(key-value)
- HashMap 无序 不重复 无索引
- LinkedHashMap 有序 不重复 无索引
- TreeMap 排序 不重复 无索引
- Stream (JDK1.8上线)
- 如何获取集合和数组的流
- 中间操作
- 终结方法(不在返回新流)
- File
- 字符集(1bit=8位)
- 字符的编码和解码
- 编码
- 解码
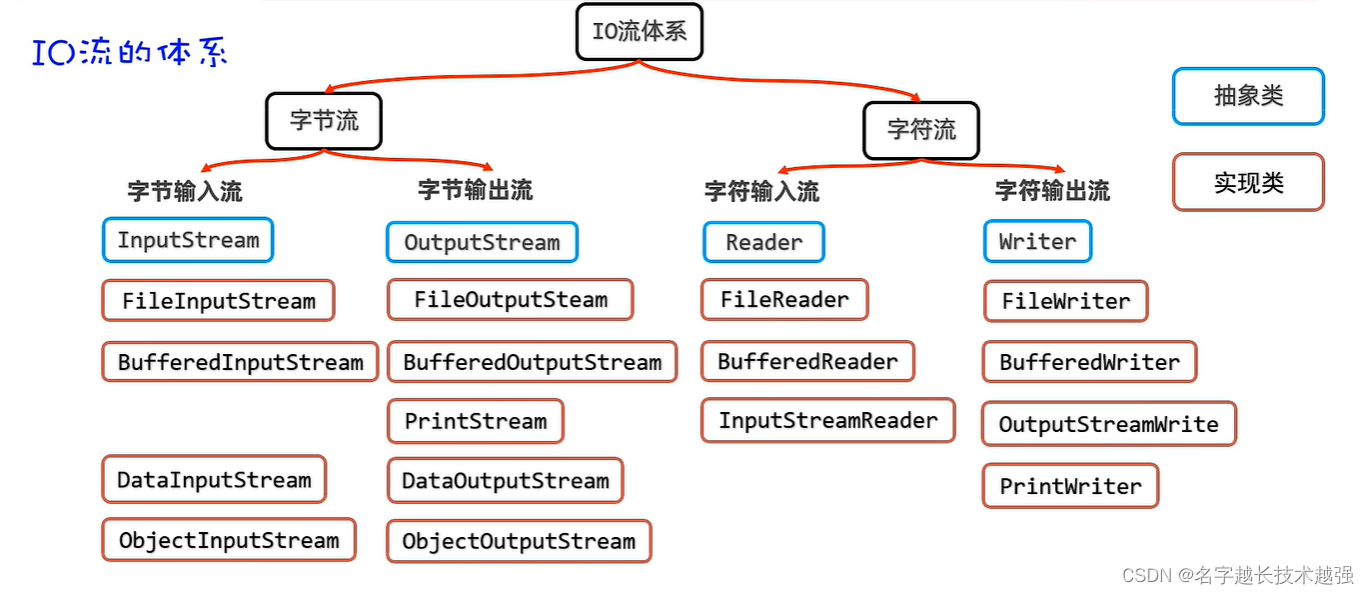
- io流
- 字节流、字符流 (解决文件读写)
- 字节流
- 字符流
- 字符流数据刷新
- 关闭流
- 缓冲流(解决读写性能)
- 字节缓冲流
- 字符缓冲流
- 读写推荐使用:缓冲流+数组(数组扩大到一个阀值,其效率不会在继续显著提高)
- 转换流(解决不同编码读取时的乱码)
- 打印流
- PrintStream 字节
- PrintWriter 字符
- 数据流
- DataOutputStream 输出
- DataInputStream 输入
- 序列化流
- 特殊文件
- Properties(属性集合key=value)
- 读取
- 写入
- XML 扩展标记语言
- 读取
- 方法
数据类型转换
byte short char :这三种类型相互运算是以int为结果类型
原因:以为他们之 间相互运算可能存在超过其原数据类型的存储空间
运算符
/:两个整数做运算其结果一定是整数,因为最高类型为整数
解决:通常可给其中一个整数*1.0来转换类型
int a=5;
int b=a/2 // 2
字符串
能算则算,不能算就在一起吧
int a=10;
char c='a';
System.out.println(a+5); // 15
System.out.println(a+c+"test"); // 107test
System.out.println("test"+a+111); // test10111
方法传递参数: 值传递
- 基本类型方法参数中传递时:为其数值的传递,结果,原数据无变化
- 应用类型方法参数中传递时: 内存地址的传递,结果,堆中发生了变化
构造器
- 如果类不写构造器,类编译时会自动生成一个无参构造器;
- 如果类定义类有参构造器,则类不会在自动生成无参构造器,所以要手写补充无参构造器;
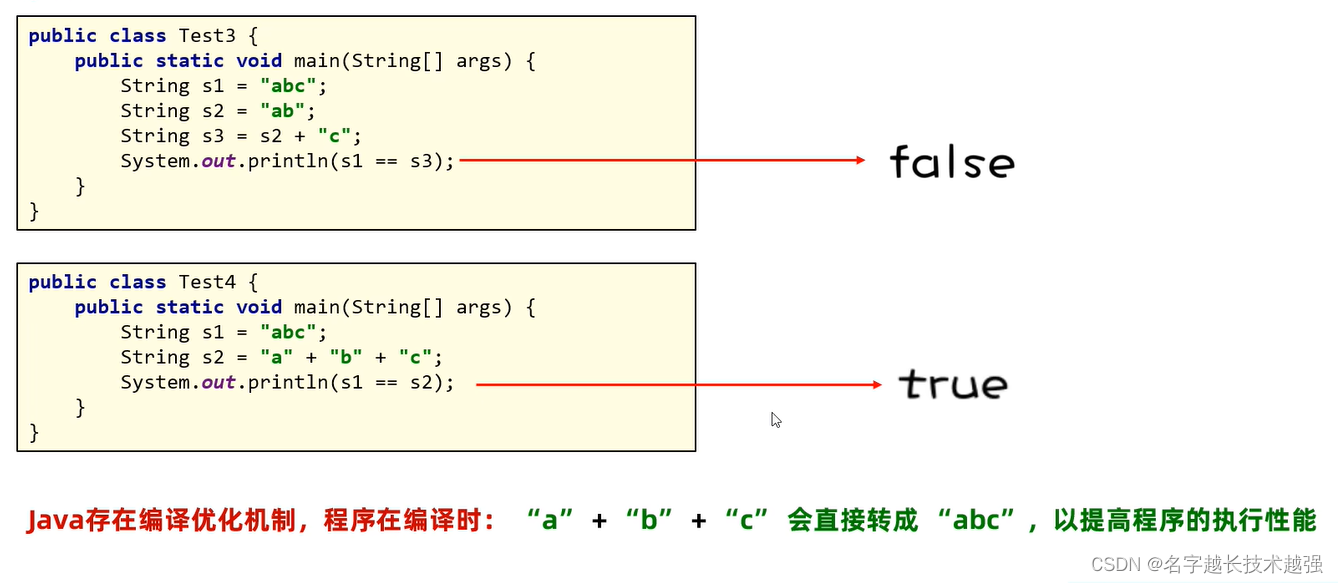
String
String是不可变的字符串
只要是以“xxx”方式创建的字符串,都会存储在堆内存的字符串常量池中,相同内存只会存储一份(节约内存)
new关键字创建的对象则按对象方式去处理
String name1="name";
String name2="name";
System.out.println(name1==name2); // true
String name11=new String("nema");
String name22=new String("nema");
System.out.println(name11==name22); // false
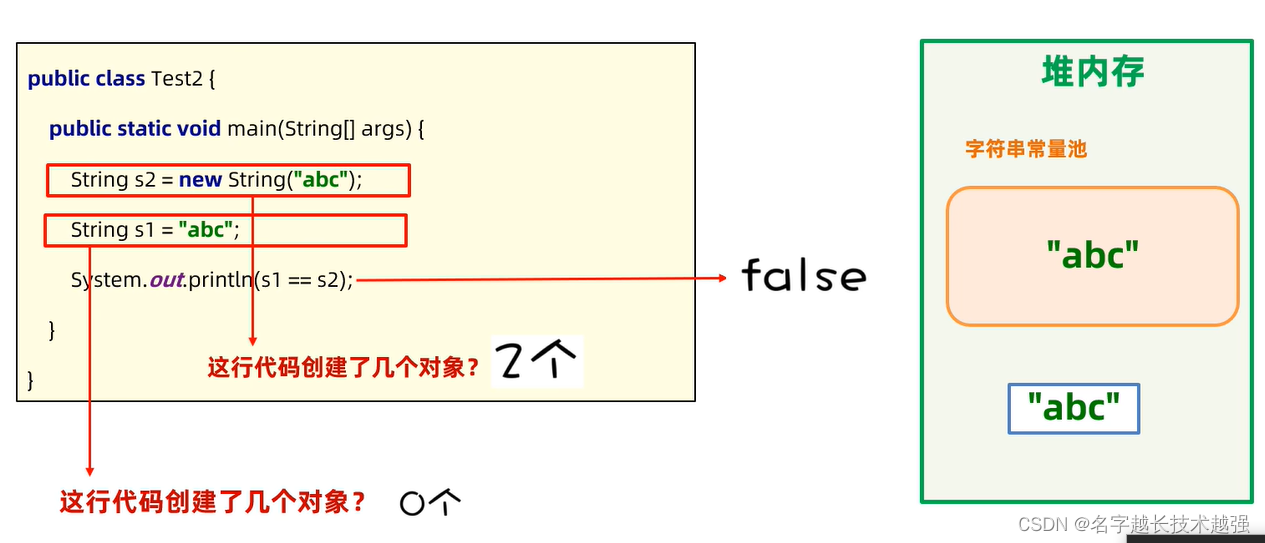
s2+“c”:去运算后生成堆内存对象
静态代码块和实例代码块
静态代码块:
- 格式:static{}
- 特点:类加载时自动执行,只会执行一次
静态代码块只执行一次
实例代码块:
- 格式: {}
- 特点:实例代码块会每次在创建对象时,在构造方法前执行
多态
编译看左边 运行看右边
匿名内部类
就是一种特殊的局部内部类;所谓匿名,是值不需要为此类指定名字
实质:匿名内部类编译成一个子类,子类会立马创建一个对象出来
格式:
new 类或者接口(参数){
类体(一般是方法重写)
}
StringJoiner (JDK1.8)
解决:字符串拼接时候需要前缀、后缀、分隔符
StringJoiner stringJoiner=new StringJoiner(",","[","]");
stringJoiner.add("a");
stringJoiner.add("b");
stringJoiner.add("c");
System.out.println(stringJoiner); // [a,b,c]
小数计算BigDecimal
BigDecimal bigDecimal =new BigDecimal (double) 此种方式也存在精度丢失。可以下来解决
- BigDecimal bigDecimal =new BigDecimal (String );
- BigDecimal bigDecimal = BigDecimal.valueOf(String);
时间

时间



集合
单列集合
List 有序 有索引 重复
ArrayList 低层(数组)
- 初始化创建一个长度为0的数组
- 添加第一个元素时,会创建个长度为10的数组
- 存满时,会自动扩容1.5倍
- 如果一次性添加多个元素,1.5倍不够用,则创建一个实际长度的数组
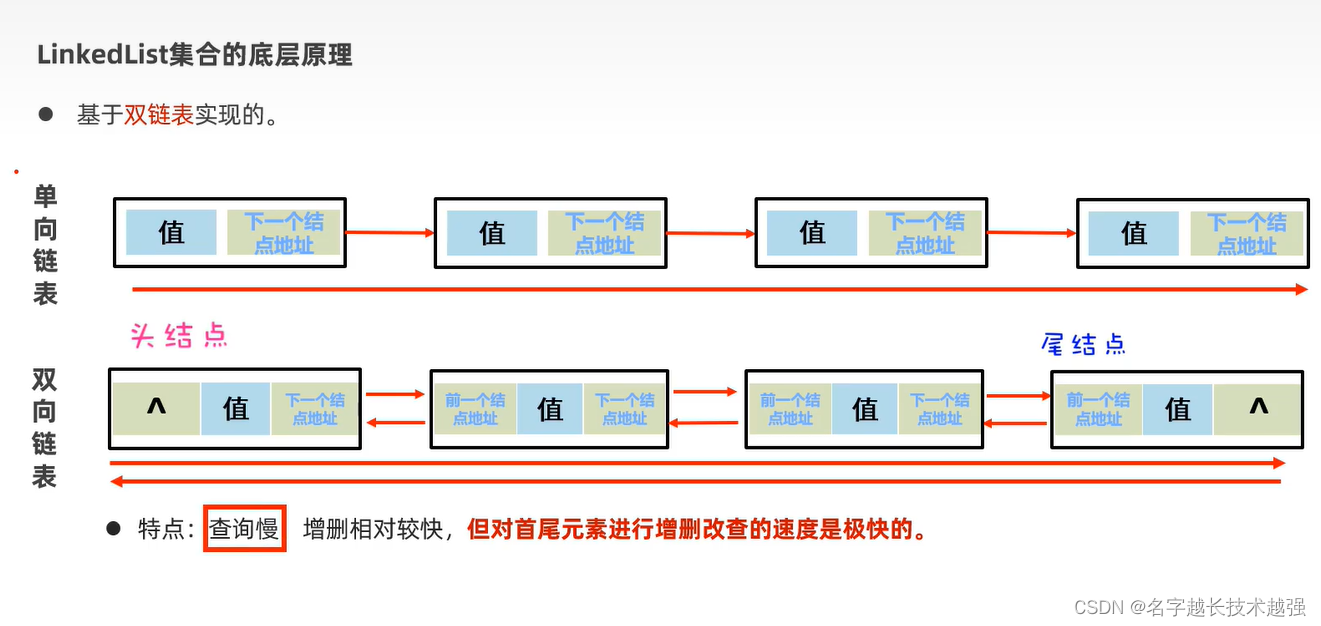
特点:查询快,增删慢
LinkList 低层(双向链表)
双链表
Set
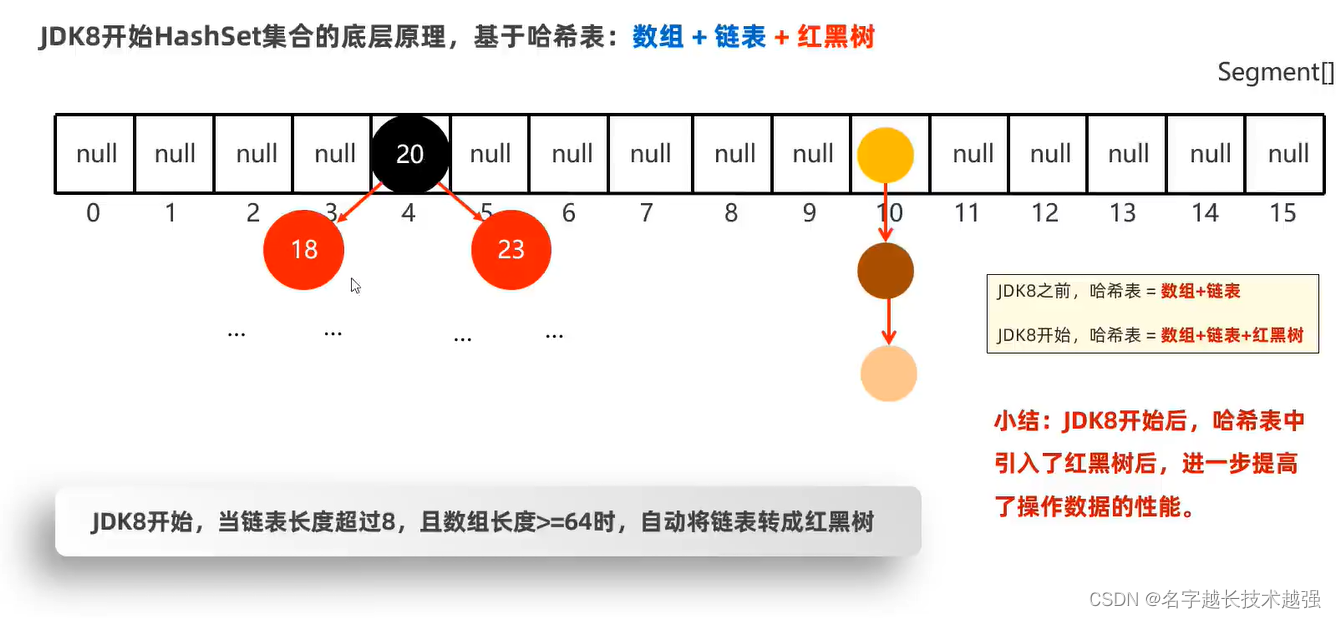
HashSet 无序 不重复 无索引
特点:增删改查性能就较好
低层 哈希表(JDK1.8前:数组+链表 ;1.8后数组+链表+红黑树)
哈希值:就是一个int的数值,每一个java对象都有,Object类的方法 hashCode返回其自己的哈希值
,不同对象的哈希值不同,但也可能存在相同(int -21亿,21亿,如果对象唱过21亿则会出现:哈希碰撞)
无序:使用元素的哈希值和数组的长度求余计算出存入的位置

扩容:
- 数组 16*0.75=12,当数组元素超过12中翻倍扩
- 链表:JKD8后长度超过8 生成红黑树
根据对象内容去重
正常情况下,每一个对象hashCode不同,根据其数据存储算法,则为非重复数据。当其hashCode相同时进一步比较equals是否相同;去重则为让其hashCode、equals都相同;对象重写其hashCode、equals让其算法相同即可
hashCode 和 equals:
LinkedHashSet 有序(双链表的机制) 不重复 无索引
低层: 哈希表 ,但是它的每一个元素都多了一个双链表的机制记录前后的元素的位置
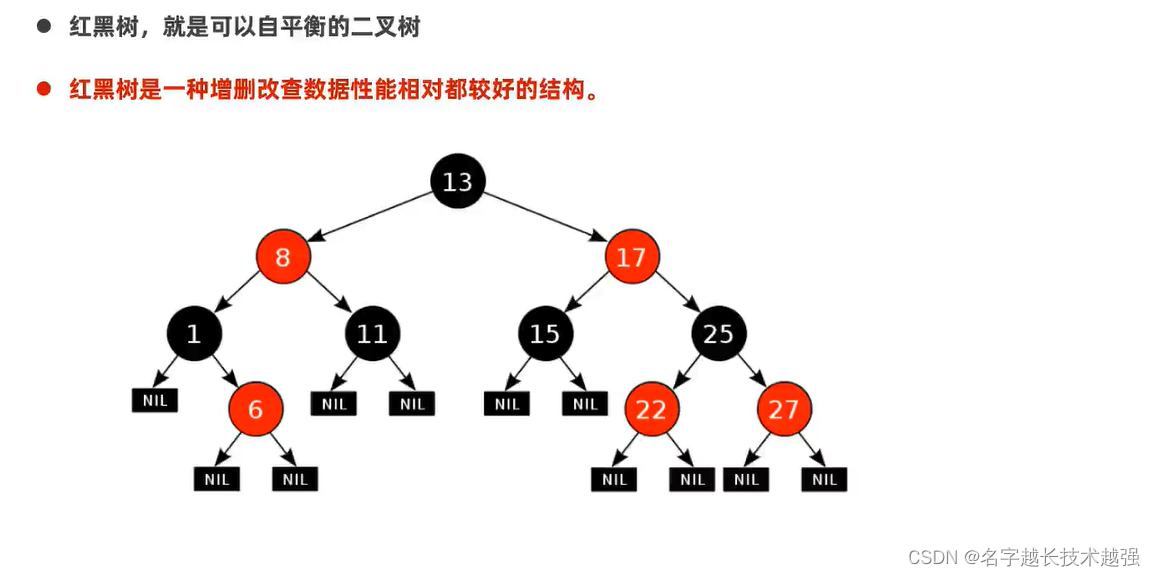
TreeSet 排序 不重复 无索引
低层:红黑树
排序:
- 默认自带比较器
- 让自定义类实现comparable 接口
- TreeSet 有参构造器设置比较器(comparator)
可变参数
格式:数据类型…参数名称
特点:可不传数据、可传一个、可传多个、可传数组
注意:形参中只能有一个可变参数,只可以放在最后
public static void main(String[] args) {
testParam();
testParam(1);
testParam(2,3);
testParam(new int[]{1,2,3,4,5});
}
public static void testParam(int...param){
System.out.println("----------:"+param.length);
}
双列集合
Map(key-value)
HashMap 无序 不重复 无索引
LinkedHashMap 有序 不重复 无索引
TreeMap 排序 不重复 无索引
Stream (JDK1.8上线)
用于操作集合和数组的数据
特点:Stream流大量的集合了Lambda编程分格,更加强大和简洁的操作集合和数组
如何获取集合和数组的流
- List ,Set直接使用Collection集合接口提供的stream()
- Map map,ketSet 然后获取strean()
- 数组 Arrays.stream(object[]) 或者 Stream.of(T…t)
中间操作
filter:过滤
sorted:排序
limit:限制数量
skip:跳过
distinct:去重
concat:多流合并为新流
map:映射
List<String> list=new ArrayList();
list.add("公司是");
list.add("公司啊");
list.add("阿萨德");
list.add("规范的");
list.add("轨道射灯");
list.stream().filter(s -> s.startsWith("公司") && s.length() == 3).sorted().forEach(s -> System.out.println(s));
终结方法(不在返回新流)
- foreach
- count
- max
- min
返回对象
- List 、Set ----->Collectors.toList()
- Array------>toArray()
List<String> newList = list.stream().filter(s -> s.startsWith("公司") && s.length() == 3).sorted().collect(Collectors.toList());
File
构造方法形参:文件路径
注: File.separator 根据系统获取分隔符-----兼容
- 绝对路径:绝对地址查找
- 相对路径:当前项目下查找
字符集(1bit=8位)
- ASCIl 汉字占1字节
- GBK 汉字占2字节 以1开头 如:1XXXXXXX 1XXXXXXX
- UTF-8 汉字占3字节 以110 10 10开头 如:110xxxxx 10xxxxxx 10xxxxxx
编码和解码其字符集必须一致(汉字在不同字符集所占字节不同),否则乱码
字符的编码和解码
编码
- byte[] getBytes() :默认字符集
- byte[] getBytes(String charsetName):指定字符集
解码
- new String(byte[]) :默认字符集
- new String(byte[],String charsetName):指定字符集
io流
字节流、字符流 (解决文件读写)
字节流
- InputStream
- FileInputStreat
- OutputStream
- FileOutPutStream
try( InputStream inputStream =new FileInputStream("F:"+File.separator+"a.txt");
OutputStream outputStream=new FileOutputStream("F:"+File.separator+"c.txt")) {
byte[] bytes=new byte[1024];
int len=0;
while ((len=inputStream.read(bytes))!=-1){
outputStream.write(bytes,0,len);
}
}catch (Exception e){
}
字符流
- Reader
- FileReader
- Writer
- FileWriter
try( Reader reader=new FileReader("F:"+File.separator+"a.txt");
Writer writer= new FileWriter("F:"+File.separator+"b.txt")) {
char[] chars=new char[6];
int len=0;
while ((len=reader.read(chars))!=-1){
writer.write(chars,0,len);
}
writer.flush();
}catch (Exception e){
}
字符流数据刷新
本质: 频繁向磁盘写文件浪费性能。 则输出的数据写入内存,当刷新或关闭,则从内存写入到磁盘文件。当写入内存的数量达到一定的程度也会写入,
字符流输出数据后,要刷新或者关闭(关闭会自动刷新)字符流,写出去的数据才会生效。
关闭流
- try-catch-finally
finally: 先判断流对象是否为空(因为可能在创建流对象前就已经出异常) - try-with-resource(对 try-catch-finally的优化)
格式:try(定义资源1,定义资源2,…){
可能出现的异常代码
}catch(exception e){
}
注: try(只可放置资源对象,何为资源对象,是指对象实现了AutoCloseable接口,资源使用完毕后,会自动调用其close接口,完成释放)
try ( InputStream fileInputStream = new FileInputStream("f:" + File.separator + "a.txt");
FileOutputStream fileOutputStream=new FileOutputStream(new File("f:" + File.separator + "b.txt"));){
int available = fileInputStream.available(); // 数据量过大不可
byte[] buff=new byte[available];
int len=0;
while ((len=fileInputStream.read(buff))!=-1){
fileOutputStream.write(buff,0 ,len);
}
}catch (Exception e){
e.printStackTrace();
}
缓冲流(解决读写性能)
字节缓冲流
包装原始数据,提升读写性能: 自带8KB的缓冲池,构造参数可自定义修改大小
本质:从磁盘那一次性读取缓冲区大小的数据到内存,从内存一次性读取缓冲区大的数据到磁盘
- BufferedInputStream
- BufferedOutputStream
字符缓冲流
包装原始数据,提升读写性能: 自带8KB的缓冲池,构造参数可自定义修改大小
本质:从磁盘那一次性读取缓冲区大小的数据到内存,从内存一次性读取缓冲区大的数据到磁盘
- BufferedReader
- readLine() :读取一行字符
String line="";
while ((line=bufferedReader.readLine())!=null){
bufferedWriter.write(line);
}
- BufferedWriter
- newLine() : 写入一个行分隔符。
读写推荐使用:缓冲流+数组(数组扩大到一个阀值,其效率不会在继续显著提高)
转换流(解决不同编码读取时的乱码)
本质:获取原始字节流,按照指定字符集编码转为输入或输出流。
- InputStreamReader (字符输入转换流:按照指定字符集编码解析输入)
- 构造函数:InputStreamReader(InputStream in, CharsetDecoder dec)
- CharsetDecoder: 原始数据的字符集编码格式;字符编码格式不同其所占字节不同,根据指定编码解析为原始字节流。
- OutputStreamWriter(字符输出转换流:按照指定字符集编码解析输出)
打印流
直接输出什么就直接打印什么(高性能)
System.out.println() :就是打印流
PrintStream 字节
PrintStream printStream=new PrintStream("f:"+ File.separator+"aa.txt");
printStream.println(97);
printStream.println(‘a’);
printStream.println("阿萨");
PrintWriter 字符
数据流
将数据和其数据类型一起输入输出
DataOutputStream 输出
try( DataOutputStream dataOutputStream=new DataOutputStream(new FileOutputStream("f:"+ File.separator+"date.txt"))) {
dataOutputStream.writeInt(1);
dataOutputStream.writeDouble(2.2);
dataOutputStream.writeUTF("测试");
}catch (Exception e){
}
DataInputStream 输入
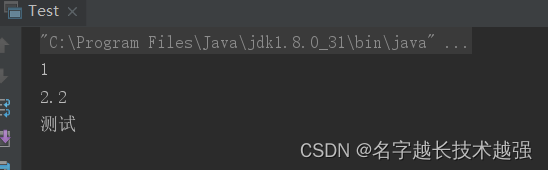
try( DataInputStream dataInputStream=new DataInputStream(new FileInputStream("f:"+ File.separator+"date.txt"))) {
int i = dataInputStream.readInt();
System.out.println(i);
double v = dataInputStream.readDouble();
System.out.println(v);
String s = dataInputStream.readUTF();
System.out.println(s);
}catch (Exception e){
序列化流
序列化:把java对象导入到文件中去
反序列化:将文件中的java对象读出来
- ObjectOutputStream:序列化的类必须实现Serializable(会标记此类特殊处理)
try( ObjectOutputStream objectOutputStream=new ObjectOutputStream(new FileOutputStream("f:"+File.separator+"object.txt"))) {
Emp emp=new Emp();
emp.setEmpno(111);
emp.setEname("xusx");
emp.setJob("coder");
objectOutputStream.writeObject(emp);
}catch (Exception e){
}
transient :标识此成员变量不参与序列化
private transient String ename;
- ObjectInputStream
try(ObjectInputStream objectInputStream=new ObjectInputStream(new FileInputStream("f:"+File.separator+"object.txt"))) {
Emp emp = (Emp) objectInputStream.readObject();
System.out.println(emp);
}catch (Exception e){
}
多个对象如何序列化
是用ArryList集合中放入对象,ArryList已实现Serializable
特殊文件
Properties(属性集合key=value)
读取
Properties properties=new Properties();
properties.load(new FileReader("a.properties"));
String name = properties.getProperty("name");
写入
将整个Properties 中key-value 全部重新写入文件
Properties properties=new Properties();
properties.setProperty("name","xusx");
properties.store(new FileWriter("a.properties"),null);
XML 扩展标记语言
一种数据格式来存储复杂的数据格式和数据关系
jar:dom4j解析xml
读取
SAXReader saxReader=new SAXReader();
Document document = saxReader.read("users.xml");
Element rootElement = document.getRootElement();
List<Element> elements = rootElement.elements();
for (Element element:elements){
Element name = element.element("name");
System.out.println(name.getText());
Attribute id = element.attribute("id");
String value = id.getValue();
System.out.println(value);
System.out.println(element.getName());
}
方法
- public String getName()
- public List elements()
- public List elements(String name)
- public Element element(String name)
- public String attributterValue(String name)
- public String elementText(子元素名)
- public String getText()