Prometheus最受诟病的一点就是单机存储不好扩展。
Prometheus存储容量估算
根据老师的经验,每秒接收 80 万个数据点,算是一个比较健康的上限,因而一开始也无需用一台配置特别高的机器,随着数据量的增长,以后再升级硬件的配置。
每秒接收 80 万个数据点是个什么概念呢?每台机器每个周期大概采集 200 个系统级指标,比如 CPU、内存、磁盘等相关的指标。假设采集频率是 10 秒,平均每秒上报 20 个数据点,可以支持同时监控的机器量是 4 万台。800000÷20=40000。可以看出,每秒接收 80 万数据点,其实是一个很大的容量了。当然,如果使用 node-exporter,指标数量要多于 200,基本800 左右,那也能支持 1 万台机器的监控。
不过刚刚我们只计算了机器监控数据,如果还要用这个 Prometheus 监控各类中间件,那就得再做预估计算了。有些中间件会吐出比较多的指标,有些指标其实用处不大,可以丢掉(drop)。
Prometheus联邦机制
联邦机制可以理解为是 Prometheus 内置支持的一种集群方式,核心就是 Prometheus 数据的级联抓取。
联邦机制就是把不同的 Prometheus 数据聚拢到一个中心的 Prometheus 中,可以结合着这个架构图来理解一下老师说的这种方法。
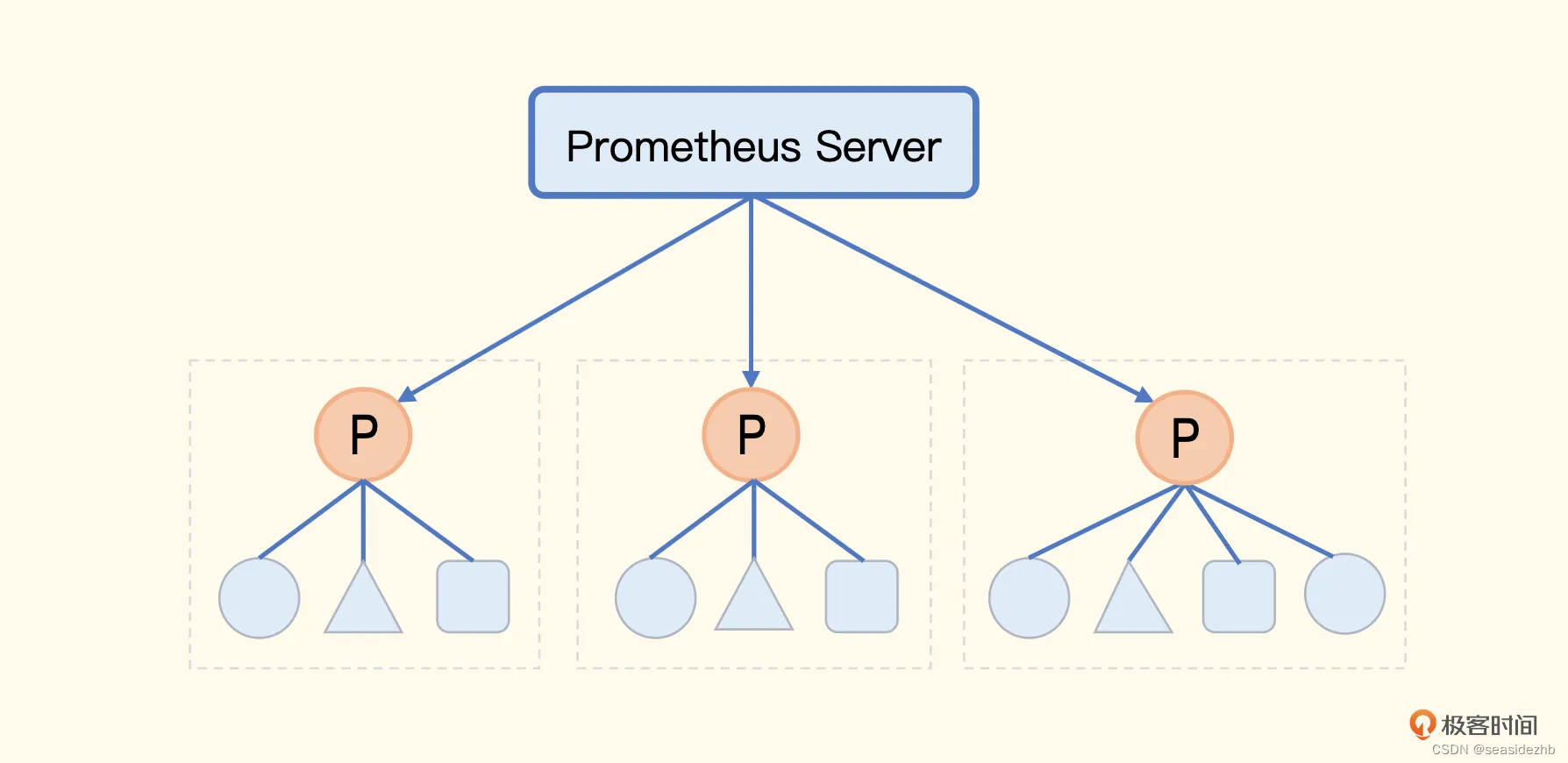
原本一个 Prometheus 解决不了的问题,拆成了多个Prometheus,之后又把多个 Prometheus 的数据聚拢到中心的 Prometheus中。但是,中心的 Prometheus 仍然是个瓶颈。所以在联邦机制中,中心端的 Prometheus 去抓取边缘 Prometheus 数据时,不应该把所有数据都抓取到中心,而是应该只抓取那些需要做聚合计算或其他团队也关注的指标,大部分数据还是应该下沉在各个边缘 Prometheus 内部消化掉。
联邦这种机制,可以落地的核心要求是,边缘 Prometheus 基本消化了绝大部分指标数据,比如告警、看图等,都在边缘的 Prometheus 上搞定了。只有少量数据,比如需要做聚合计算或其他团队也关注的指标,被拉到中心,这样就不会触达中心端 Prometheus 的容量上限。这就要求公司在使用 Prometheus 之前先做好规划,建立规范。
此文章为9月Day 14学习笔记,内容来源于极客时间《运维监控系统实战笔记》。