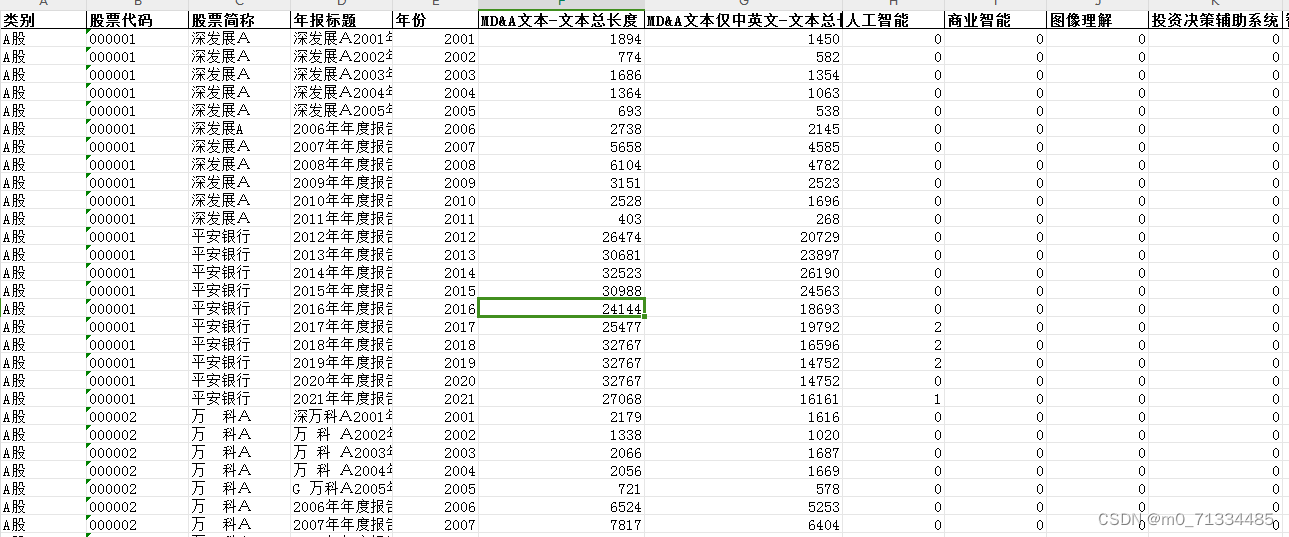
0、前言:
- 机器学习中的贝叶斯的理论基础是数学当中的贝叶斯公式。
- 这篇博客强调使用方法,至于理论未作深究。
- 机器学习中三种类型的贝叶斯公式:高斯分布(多分类)、多项式分布(文本分类)、伯努利分布(二分类任务)
- 贝叶斯算法优点:对小规模数据表现好,能处理多分类任务,常用于文本分类。缺点:只能用于分类问题。
1、高斯分布的贝叶斯算法:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
data,target = load_iris(return_X_y=True)
display(data.shape, target.shape)
data2 = data[:,2:].copy()
GS_nb = GaussianNB()
GS_nb.fit(data2,target)
X = np.linspace(data2[:,0].min(),data2[:,0].max(),1000)
Y = np.linspace(data2[:,1].min(),data2[:,1].max(),1000)
nx,ny = np.meshgrid(X,Y)
nx = nx.ravel()
ny = ny.ravel()
disdata = np.c_[nx,ny]
pd.DataFrame(disdata).head(3)
disdata_pred = GS_nb.predict(disdata)
plt.scatter(disdata[:,0],disdata[:,1],c=disdata_pred)
plt.scatter(data2[:,0],data2[:,1],c=target,cmap='rainbow')
plt.pcolormesh(X,Y,disdata_pred.reshape(1000,-1))
plt.scatter(data2[:,0],data2[:,1],c=target,cmap='rainbow')

- 在这个应用中,用多项式分布的贝叶斯分类效果没有高斯分布好,而伯努利分布的贝叶斯只能用于二分类任务。
2、三种贝叶斯算法的文本分类应用效果:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB,MultinomialNB,BernoulliNB
data = pd.read_table('./data2/SMSSpamCollection',header=None)
pd.DataFrame(data).head(2)
a_data = data[1].copy()
target = data[0].copy()
a_data.shape
from sklearn.feature_extraction.text import TfidfVectorizer
'''
1、TfidfVectorizer将文本数据转换为特征向量形式,每个词表示一个特征维度,每个维度的值是这个词在文本中的权重(出现的次数)
2、这个库是文本数据用于机器学习模型的关键步骤
3、导入后使用方法和机器学习算法非常类似,要先创建对象,然后fit()
'''
tf = TfidfVectorizer()
tf.fit(a_data)
X = tf.transform(a_data).toarray()
GS = GaussianNB()
GS.fit(X,target)
GS.score(X,target)
MT = MultinomialNB()
MT.fit(X,target)
MT.score(X,target)
BE = BernoulliNB()
BE.fit(X,target)
BE.score(X,target)
m = [
'hello, nice to meet you',
'Free lunch, please call 09999912313',
'Free lunch, please call 080900031 9am - 11pm as a $1000 or $5000 price'
]
m = tf.transform(m).toarray()
GS.predict(m)
MT.predict(m)
BE.predict(m)
- 总结:
1、在进行文本分类时调用贝叶斯算法的方式还是中规中矩,其中一个难点是读数据时要先知道数据的格式,然后才能通过pandas来读取
2、非常重要的一个工具就是sklearn库提供的分词工具from sklearn.feature_extraction.text import TfidfVectorizer,它可以把一个一维的文本数据(每个元素是一个句子文本的列表或者其他一维数据)通过fit方法将其特征词提取出来,进行分词,之后通过transform方法再次输入数据就可以把数据变成稀疏矩阵,然后再次通过toarray方法将数据变成真真的numpy二维数组。
3、从文本分类结果看,多项式分布更适合做文本分类,但是对于二分类文本分类任务伯努利效果更佳。