有时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,请认准
https://blog.zysicyj.top
首发博客地址
系列文章地址
需求描述
现在假设有这样一个需求,我们要开发一个图像存储系统。要求如下:
-
该系统能快速记录图片的ID和图片保存在系统中的ID -
能根据图片ID快速查找到图片存储对象ID
这里我们用10位来存储图片ID和对象ID,比如下面这种:
photo_id: 1101000051
photo_obj_id: 3301000051
这里我们能分析出两个点:
-
图片ID和图片对象ID是一一对应的,是典型的“键-单值”模式 -
String可以保存二进制字节流,只需要将流转成数组即可
方案一:使用String存储
这个方案是首先想到的,毕竟这个场景是非常契合String的。我们把图片ID和图片存储对象ID分别作为键值对的key和value来存储,其中,图片存储对象ID用String类型。
这里一亿张图片的数据量大概用了6.4G的内存。随着图片的增多,Redis使用的内存也在不断增加,这列就会遇到「大内存Redis因为生成RDB而响应变慢」的问题。
为什么会变慢?
当Redis生成RDB文件时,会将内存中的数据写入到磁盘上,以便在Redis重启时可以从RDB文件中恢复数据。生成RDB文件的过程可能会导致Redis的响应变慢,特别是在处理大内存的情况下。
造成大内存Redis生成RDB而响应变慢的原因主要有以下几点:
-
「内存写入磁盘的速度限制」:磁盘的写入速度相对较慢,尤其是对于大内存的Redis来说,需要写入的数据量较大,可能会导致写入磁盘的速度无法满足Redis的写入速度,从而导致响应变慢。
-
「RDB生成过程的阻塞」:在生成RDB文件的过程中,Redis会阻塞其他操作,以确保生成的RDB文件是一致的。这意味着在生成RDB文件期间,Redis无法处理其他的读写请求,从而导致响应变慢。
所以这时候String 类型并不是一种好的选择,我们还需要进一步寻找能节省内存开销的数据类型方案。
为什么String内存开销大?
先说结论:「String 类型并不是适用于所有场合的,它有一个明显的短板,就是它保存数据时所消耗的内存空间较多。」
我们回看一下,前面说过,1亿张图片信息,用了约6.4G内存。那么一张图片平均就是64字节,这里面包含了一个图片ID和一个图片对象ID。
实际上一张图片对应ID和对象ID只需要16字节就可以了,为什么却要64字节呢?
这里我们分析一下。图片 ID 和图片存储对象 ID 都是 10 位数,我们可以用两个 8 字节的 Long 类型表示这两个 ID。因为 8 字节的 Long 类型最大可以表示 2 的 64 次方的数值,所以肯定可以表示 10 位数。但是,为什么 String 类型却用了 64 字节呢?
在Redis中,String类型是一种二进制安全的数据结构,可以存储任意类型的数据,包括字符串、整数、浮点数等。Redis中的String类型并不是固定长度的,它的长度是根据存储的实际数据来动态调整的。
对于存储图片ID和图片存储对象ID这样的10位数,使用8字节的Long类型是足够的,因为Long类型可以表示的范围远远超过10位数。但是在Redis中,String类型的底层实现并不是简单地存储数据本身,而是包含了一些额外的信息。
在Redis中,每个String类型的值都包含一个头部(header)和一个数据体(body)。头部包含了一些元数据信息,如数据类型、长度等。而数据体则存储了实际的数据内容。
对于String类型的值,Redis为了能够高效地进行内存管理和数据操作,会在头部中存储一些额外的信息。这些额外的信息包括了数据的长度、引用计数、过期时间等。这些信息的存储需要一定的空间,因此会导致String类型的值占用的空间比实际数据的长度要大。
具体来说,Redis中的String类型的头部占用了39字节的空间,而数据体则占用了实际数据的长度。所以,对于一个10位数的数据,使用String类型存储时,实际占用的空间是39字节加上数据长度的总和。
需要注意的是,「Redis的String类型的头部大小是固定的,不会随着数据的大小而变化」。因此,「对于较小的数据,头部占用的空间相对较大」,而对于较大的数据,头部占用的空间相对较小。
总结起来,虽然String类型的值在Redis中占用的空间比实际数据的长度要大,但这是为了支持Redis的高效内存管理和数据操作而设计的。对于较小的数据,这种额外的空间开销可能会比较大,但对于较大的数据,这种开销相对较小。
具体String是如何保存数据的呢
Redis String是一种简单的键值对数据结构,它的值可以是字符串、整数或浮点数。在Redis中,String类型的数据是以字节数组的形式进行存储的。
具体来说,当我们向Redis中存储一个String类型的值时,Redis会将这个值以二进制的形式进行存储。Redis使用了一种称为简单动态字符串(Simple Dynamic String,SDS)的数据结构来表示String类型的值。SDS是Redis自己实现的一种字符串表示方式,它比C语言中的字符串更加灵活和高效。
SDS的结构如下:
struct sdshdr {
int len; // 字符串的长度 占 4 个字节,表示 buf 的已用长度。
int alloc; // 分配的内存空间大小 也占个 4 字节,表示 buf 的实际分配长度,一般大于 len。
char buf[]; // 字符串的实际内容 字节数组,保存实际数据。为了表示字节数组的结束,Redis 会自动在数组最后加一个“\0”,这就会额外占用 1 个字节的开销。
};
其中,len表示字符串的长度,alloc表示分配的内存空间大小,buf是一个柔性数组,用来存储字符串的实际内容。
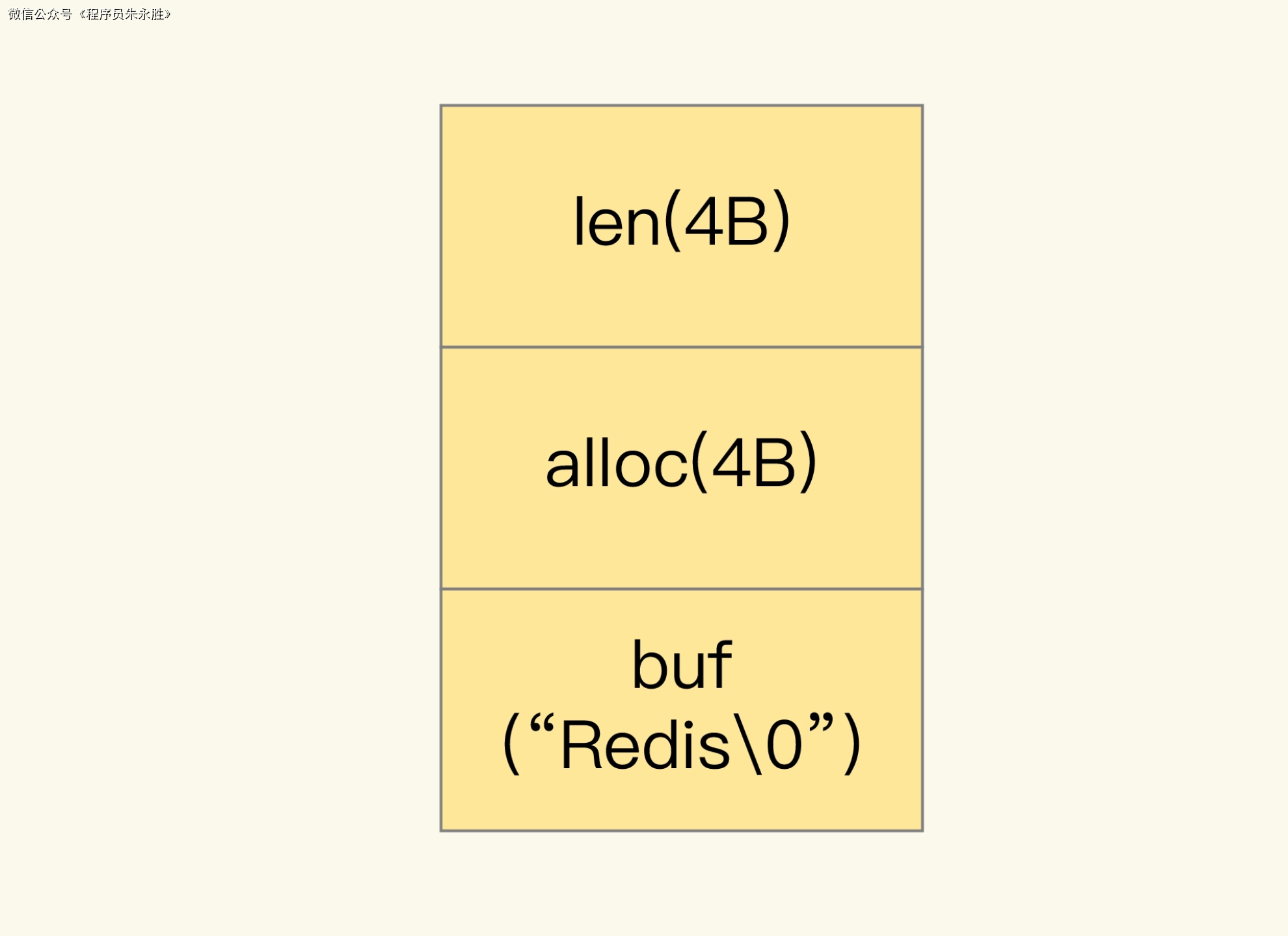
当我们向Redis中存储一个String类型的值时,Redis会根据值的长度来分配一块合适大小的内存空间,并将值的内容复制到这块内存中。Redis会根据值的长度来设置len字段的值,并根据分配的内存空间大小来设置alloc字段的值。
当我们对SDS进行修改时,如果新的字符串长度小于等于alloc字段的值,那么可以直接在SDS中修改原有的字符串内容,而无需重新分配内存。只有当新的字符串长度大于alloc字段的值时,才需要重新分配内存。
当需要重新分配内存时,Redis会根据新字符串的长度计算出需要分配的内存大小,并将新字符串的内容复制到新分配的内存中。然后,Redis会更新SDS的len字段为新字符串的长度,更新alloc字段为新分配的内存大小。
需要注意的是,**SDS结构中的alloc字段表示的是分配的内存空间大小,而不是已使用的字节长度。这样设计的目的是为了提高字符串的修改效率,避免频繁的内存分配和释放操作 **。
在Redis中,String类型的值是以字节数组的形式进行存储的,所以「它可以存储任意类型的数据」 。当我们需要读取String类型的值时,Redis会将存储的字节数组转换为对应的数据类型,并返回给我们。
需要注意的是,「Redis的String类型是二进制安全的」 ,也就是说它可以存储任意二进制数据,而不仅仅是文本字符串。这使得Redis的String类型非常灵活,可以用于存储各种类型的数据,例如序列化的对象、图片、音频等。
总结起来,Redis String类型的数据是以字节数组的形式进行存储的,使用了简单动态字符串(SDS)来表示。它可以存储任意类型的数据,并且支持高效的读写操作。
对于 String 类型来说,除了 SDS 的额外开销,还有一个来自于 RedisObject 结构体的开销。
因为 Redis 的数据类型有很多,而且,不同数据类型都有些相同的元数据要记录(比如最后一次访问的时间、被引用的次数等),所以,Redis 会用一个 RedisObject 结构体来统一记录这些元数据,同时指向实际数据。
RedisObject是Redis中通用的对象结构,用于表示不同类型的数据。对于String类型的数据,RedisObject结构体中包含了一个指向SDS结构体的指针,以及其他一些用于管理对象的字段,比如引用计数等。
具体的RedisObject结构如下:
typedef struct redisObject {
unsigned type:4; // 对象类型
unsigned encoding:4; // 对象编码方式
unsigned lru:LRU_BITS; // LRU时间戳
int refcount; // 引用计数
void *ptr; // 指向实际数据的指针
} robj;
在Redis中,每个String类型的值都会被封装成一个RedisObject对象。这个对象中的ptr 字段指向实际的SDS结构体,而不是直接存储字符串的内容。这样设计的目的是为了支持不同编码方式的字符串,比如int、float等。
RedisObject结构体中的其他字段,比如type、encoding、lru和refcount等,用于管理对象的类型、编码方式、LRU时间戳和引用计数等信息。
因此,对于String类型的数据,在Redis中除了SDS结构本身的开销外,还需要考虑RedisObject结构体的开销。
一个 RedisObject 包含了 8 字节的元数据和一个 8 字节指针,这个指针再进一步指向具体数据类型的实际数据所在,例如指向 String 类型的 SDS 结构所在的内存地址,可以看一下下面的示意图。关于 RedisObject 的具体结构细节,我会在后面的课程中详细介绍,现在你只要了解它的基本结构和元数据开销就行了。
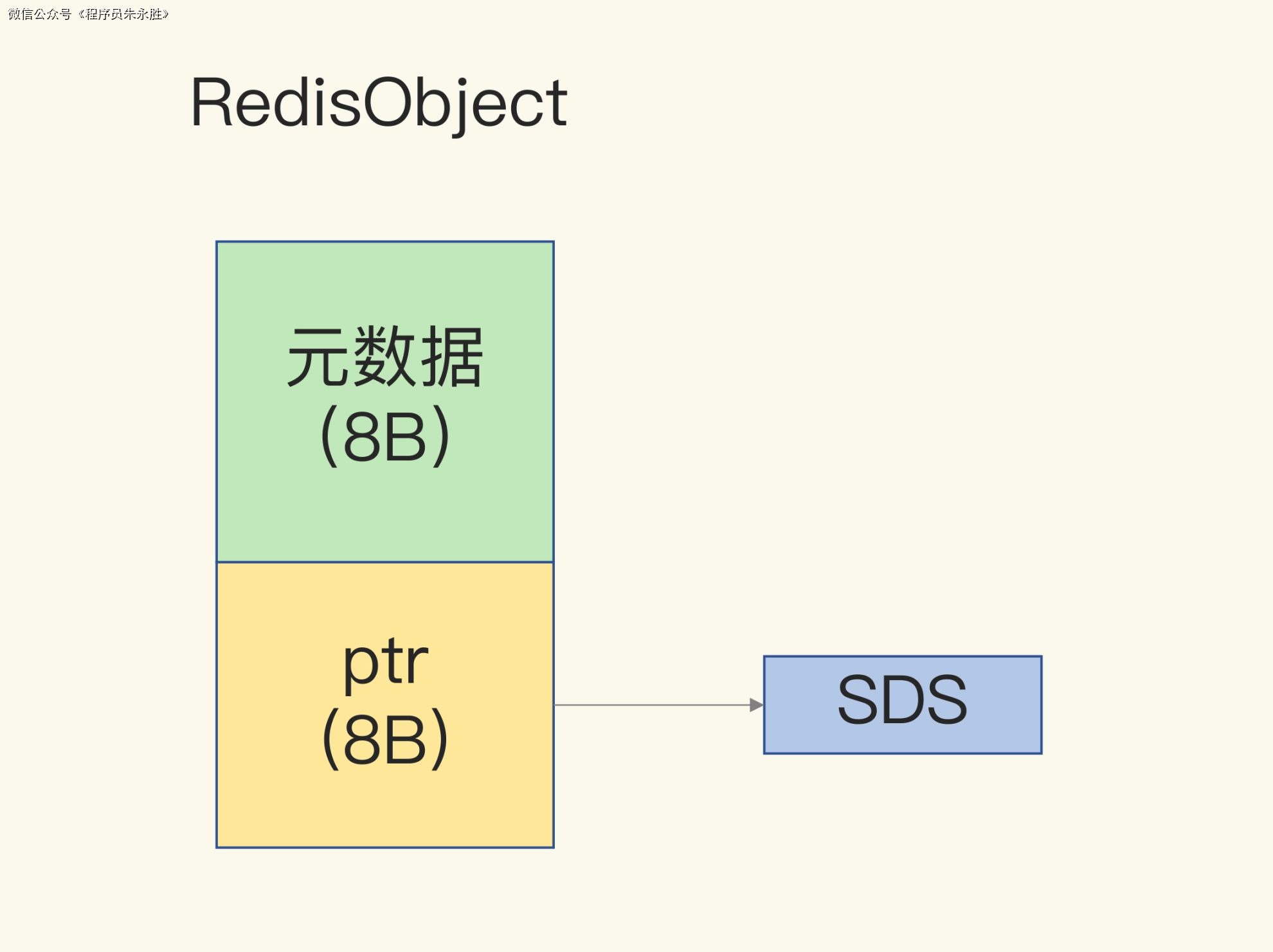
Redis为了节省内存空间,在处理Long类型整数和SDS(Simple Dynamic String)时进行了专门的设计。
对于Long类型整数,RedisObject中的指针直接赋值为整数数据,而不需要额外的指针指向整数。这样可以节省指针的空间开销。
对于字符串数据,当字符串的长度小于等于44字节时,RedisObject中的元数据、指针和SDS是一块连续的内存区域。这种布局方式被称为embstr编码方式。这样可以避免内存碎片,提高内存利用率。
然而,当字符串的长度大于44字节时,SDS的数据量就开始变多了。为了避免内存浪费,Redis不再将SDS和RedisObject布局在一起,而是给SDS分配独立的空间,并使用指针指向SDS结构。这种布局方式被称为raw编码模式。
总结一下,Redis为了节省内存空间,对Long类型整数和SDS进行了特殊的内存布局设计。对于Long类型整数,直接将指针赋值为整数数据,避免了额外的指针开销。对于小于等于44字节的字符串,将元数据、指针和SDS布局在一起,避免了内存碎片。而对于大于44字节的字符串,将SDS分配独立的空间,并使用指针指向SDS结构,避免了内存浪费。
这种内存布局设计可以有效地节省内存空间,提高Redis的性能和效率。但需要注意的是,这种设计是基于对数据类型和数据长度的特定假设,如果数据类型或 「数据长度超出了设计的范围,可能会导致内存浪费或性能下降」。
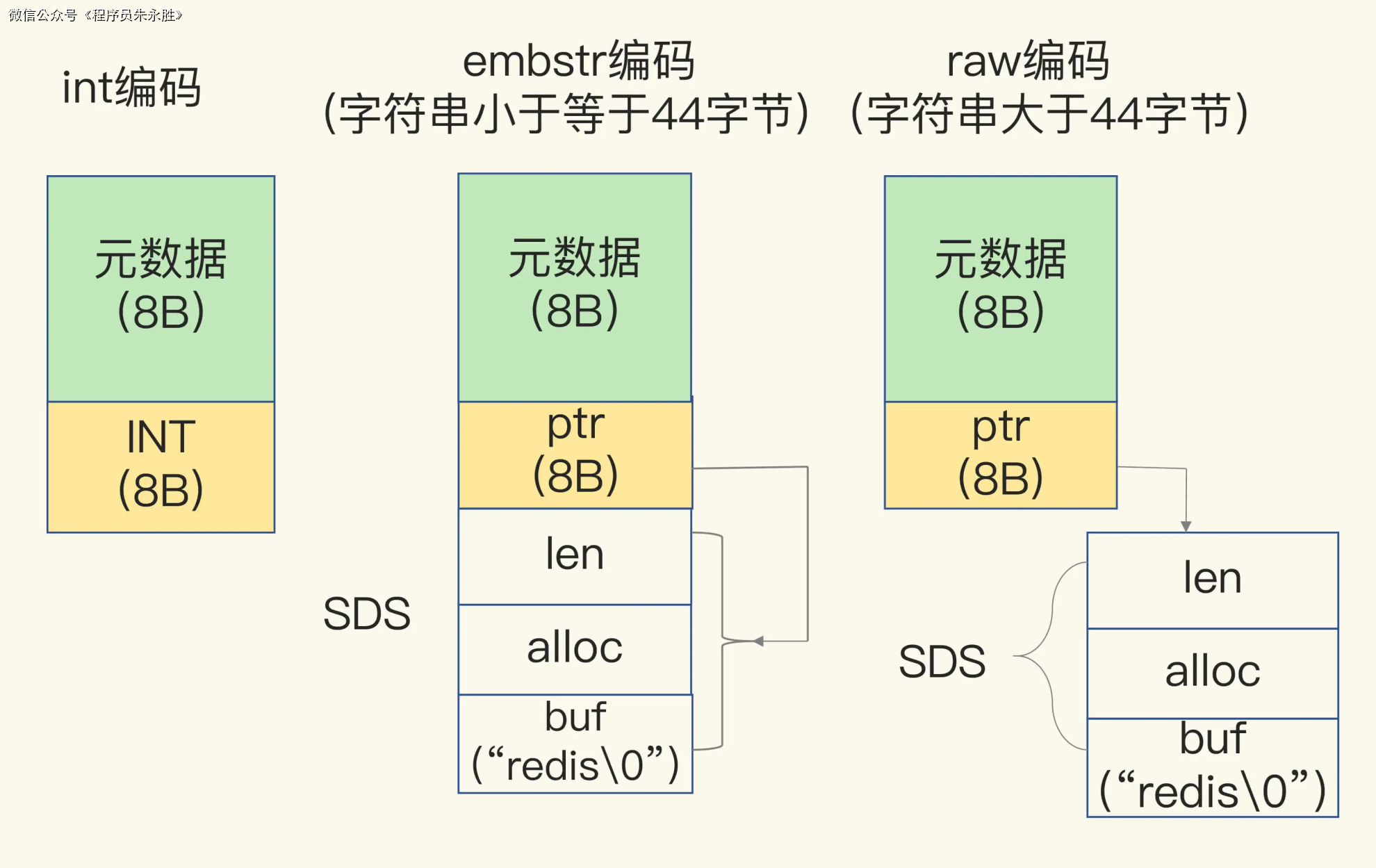
计算String类型内存消耗
每个图片 ID 和图片存储对象 ID 都是 Long 类型整数,可以直接用 int 编码的 RedisObject 保存。每个 int 编码的 RedisObject 元数据部分占 8 字节,指针部分被直接赋值为 8 字节的整数。因此,每个 ID 使用了 16 字节。
然而,你提到还有另外的 32 字节,这些字节是用来保存 Redis 的全局哈希表中的键值对的。Redis 使用一个全局哈希表来保存所有的键值对,每个键值对由一个 dictEntry 结构体表示。dictEntry 结构体包含三个 8 字节的指针,分别指向 key、value 和下一个 dictEntry,共占用 24 字节。
这意味着,每个键值对在全局哈希表中占用了 24 字节的空间。因此,对于每个 ID,除了使用的 16 字节外,还需要额外的 24 字节来保存键值对的指针。
综上所述,每个 ID 使用了 16 字节来保存自身的值,另外还需要额外的 24 字节来保存键值对的指针,总共占用了 40 字节的空间。
这三个指针只有 24 字节,为什么会占用了 32 字节呢?这就要提到 Redis 使用的内存分配库 jemalloc 了。
jemalloc是一种内存分配器,它会对申请的内存进行对齐,以提高内存的使用效率。
当申请的空间大小不是 8 字节的倍数时,jemalloc 会将申请的空间大小向上对齐到 8 字节的倍数。这是为了提高内存的读写效率,因为现代计算机的内存读写操作通常是以 8 字节为单位的。
在这个场景中,dictEntry 结构占用了 24 字节的空间,不是 32 字节。这是因为 jemalloc 对申请的内存进行了对齐,使得 dictEntry 结构的起始地址对齐到 8 字节的边界。
因此,当使用 String 类型保存图片 ID 和图片存储对象 ID 时,需要使用 40 个字节。这是因为图片 ID 和图片存储对象 ID 的总长度为 16 字节,而 jemalloc 会按照对齐的原则,将内存地址对齐到 8 字节的边界。
需要注意的是,这个例子中的对齐规则是 jemalloc 的默认行为,不同的内存分配器可能有不同的对齐规则。此外,对齐规则也可能受到编译器和操作系统的影响。因此,在实际开发中,需要根据具体的情况来确定内存对齐的需求。
明明有效信息只有 16 字节,使用 String 类型保存时,却需要 40 字节的内存空间,有 24 字节都没有用于保存实际的数据。我们来换算下,如果要保存的图片有 1 亿张,那么 1 亿条的图片 ID 记录就需要 1.6GB 内存空间,其中有 2.4GB 的内存空间都用来保存元数据了,额外的内存空间开销很大。那么,有没有更加节省内存的方法呢?
方案二:压缩列表
压缩列表(ziplist)是 Redis 中一种用于存储较小的列表和哈希表的数据结构。它是一种紧凑的、连续存储的数据结构,可以在内存中节省空间。
压缩列表是 Redis 中用于存储列表和哈希表等数据结构的一种紧凑存储结构。每个 entry 表示一个元素,可以是字符串、整数或者其他类型的数据。
-
prev_len:前一个 entry 的长度。它有两种取值情况:1 字节或 5 字节。如果前一个 entry 的长度小于 254 字节,则 prev_len 取值为 1 字节;否则,取值为 5 字节。这是为了节省存储空间,因为 1 字节的值能表示的数值范围是 0 到 255,而压缩列表中 zlend 的取值默认是 255,所以不能再用 255 表示长度大于 254 字节的情况。
-
len:当前 entry 的长度,占用 4 字节。它表示当前 entry 的实际长度,包括 encoding 和 content。
-
encoding:当前 entry 的编码方式,占用 1 字节。它表示当前 entry 存储的数据的类型和编码方式。不同的编码方式对应不同的数据类型,比如字符串、整数等。
-
content:当前 entry 的实际数据。它保存了当前 entry 存储的具体内容,根据 encoding 的不同,可以是字符串、整数等。
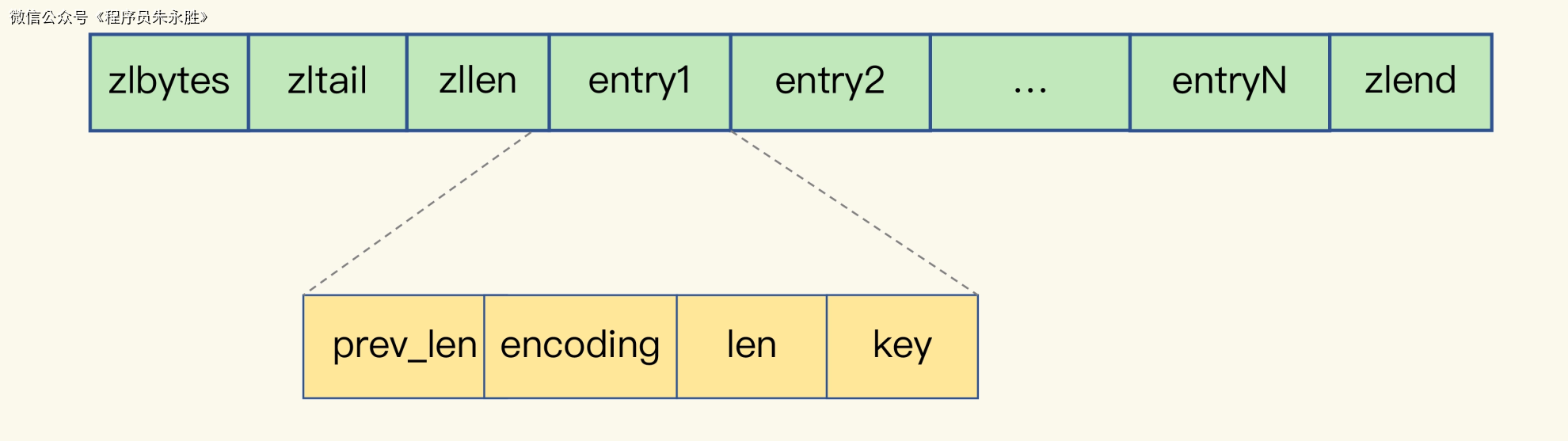
需要注意的是,这只是压缩列表中每个 entry 的结构,压缩列表本身还有其他的元数据信息,比如 zlbytes(压缩列表的总字节数)、zltail(尾部 entry 的偏移量)等。这些信息一起构成了完整的压缩列表数据结构。
压缩列表的节点是紧密排列的,「没有额外的指针和元数据」,这使得它在内存中占用的空间更小。同时,由于「节点是连续存储的」 ,可以通过偏移量来快速访问节点,而不需要像链表那样遍历整个数据结构。
压缩列表的构成可以根据存储的数据类型进行灵活调整。例如,如果列表中的所有元素都是整数,那么可以使用整数编码来存储数据,这样可以进一步减少存储空间。压缩列表还支持变长编码,可以根据数据的大小动态选择编码方式,以提高存储效率。
需要注意的是,压缩列表适用于存储较小的列表和哈希表,当数据量较大时,性能可能会受到影响。在 Redis 中,当列表或哈希表的长度超过一定阈值时,会自动将压缩列表转换为普通的链表或哈希表,以提高性能。
压缩列表占用空间大小
我们以保存图片存储对象 ID 为例,来分析一下压缩列表是如何节省内存空间的。
每个 entry 保存一个图片存储对象 ID(8 字节),并且每个 entry 的 prev_len 只需要 1 个字节。这样一来,一个图片的存储对象 ID 所占用的内存大小是 14 字节(1+4+1+8=14),实际分配 16 字节。
这里的 1 个字节用于保存 prev_len,4 个字节用于保存 entry 的长度,1 个字节用于对齐,8 个字节用于保存图片存储对象 ID。
在计算内存大小时,需要考虑对齐的问题。对齐是为了提高内存访问的效率,因为现代计算机的内存访问通常是按照字节对齐的方式进行的。对齐的规则通常是按照数据类型的大小进行对齐,比如 1 字节对齐、2 字节对齐、4 字节对齐等。
每个 entry 的长度为 8 字节,所以按照 4 字节对齐的规则,需要补齐到 8 字节。因此,实际分配的内存大小为 16 字节。
总结下压缩列表
压缩列表是一种特殊的数据结构,它将多个元素紧密地存储在一起,以节省内存。在 Redis 中,压缩列表被用于存储较小的集合类型,例如 List、Hash 和 Sorted Set。
压缩列表中的每个元素都由一个或多个字节组成,其中包含元素的长度和实际的元素值。元素的长度可以是 1 字节、5 字节或 9 字节,具体取决于元素的长度。
使用压缩列表实现集合类型的好处是节省了每个元素的开销,因为它们共享同一个 dictEntry。在使用 String 类型时,每个键值对都需要一个 dictEntry,占用 32 字节的空间。但是,使用集合类型时,一个键只需要一个 dictEntry,而可以保存多个元素,这样就节省了内存。
然而,压缩列表也有一些限制和缺点:
-
压缩列表只适用于较小的集合类型,因为随着元素数量的增加,压缩列表的性能会下降。当集合类型的元素数量超过一定阈值时,Redis 会自动将其转换为更适合大型集合的数据结构。 -
压缩列表不支持快速的随机访问,因为要找到一个元素,需要遍历整个压缩列表。这对于需要频繁的随机访问的场景可能会影响性能。
Redis 使用压缩列表实现集合类型是为了节省内存空间,但在处理大型集合和需要快速随机访问的场景下可能会有性能问题。在实际使用中,需要根据具体的需求和数据规模来选择合适的数据结构。
如何用集合类型保存单值的键值对?
在保存单值的键值对时,可以采用基于 Hash 类型的二级编码方法。这里说的二级编码,就是把一个单值的数据拆分成两部分,前一部分作为 Hash 集合的 key,后一部分作为 Hash 集合的 value,这样一来,我们就可以把单值数据保存到 Hash 集合中了。
以图片 ID 1101000060 和图片存储对象 ID 3302000080 为例,我们可以把图片 ID 的前 7 位(1101000)作为 Hash 类型的键,把图片 ID 的最后 3 位(060)和图片存储对象 ID 分别作为 Hash 类型值中的 key 和 value。
按照这种设计方法,我在 Redis 中插入了一组图片 ID 及其存储对象 ID 的记录,并且用 info 命令查看了内存开销,我发现,增加一条记录后,内存占用只增加了 16 字节,如下所示:
127.0.0.1:6379> info memory
# Memory
used_memory:1039120
127.0.0.1:6379> hset 1101000 060 3302000080
(integer) 1
127.0.0.1:6379> info memory
# Memory
used_memory:1039136
在使用 String 类型时,每个记录需要消耗 64 字节,这种方式却只用了 16 字节,所使用的内存空间是原来的 1/4,满足了我们节省内存空间的需求。
之前我们介绍过,Redis Hash 类型的两种底层实现结构,分别是压缩列表和哈希表。
Hash 类型底层结构什么时候使用压缩列表,什么时候使用哈希表呢?
在 Redis 中,Hash 类型可以使用压缩列表(ziplist)或哈希表(hashtable)来保存数据。压缩列表是一种紧凑的数据结构,可以节省内存空间。但是,当 Hash 集合中的元素个数超过了 hash-max-ziplist-entries 的阈值,或者单个元素的大小超过了 hash-max-ziplist-value 的阈值时,Redis 会自动将 Hash 类型的实现结构从压缩列表转换为哈希表。
hash-max-ziplist-entries 表示压缩列表保存时 Hash 集合中的最大元素个数,而 hash-max-ziplist-value 表示压缩列表保存时 Hash 集合中单个元素的最大长度。一旦超过了这两个阈值,Redis 会将 Hash 类型转换为哈希表,以保证数据的完整性。
转换为哈希表后,Hash 类型将一直使用哈希表来保存数据,不会再转回压缩列表。相比压缩列表,哈希表在节省内存空间方面效率较低。
为了充分利用压缩列表的内存优势,我们通常需要控制 Hash 集合中保存的元素个数。在上述例子中,我们将图片 ID 的最后 3 位作为 Hash 集合的 key,以确保 Hash 集合的元素个数不超过 1000。同时,我们将 hash-max-ziplist-entries 设置为 1000,这样 Hash 集合就可以一直使用压缩列表来节省内存空间。
总结起来,通过合理设置 hash-max-ziplist-entries 和 hash-max-ziplist-value,我们可以在保证数据完整性的前提下,充分利用压缩列表的内存优势,从而提高 Redis 的性能和效率。
# 如果您喜欢我的内容,就点击关注吧
> 扫码长按关注交流群获取最新消息,免费的面试题手册即将在交流群内推出

> 公众号

> 个人微信

本文由 mdnice 多平台发布