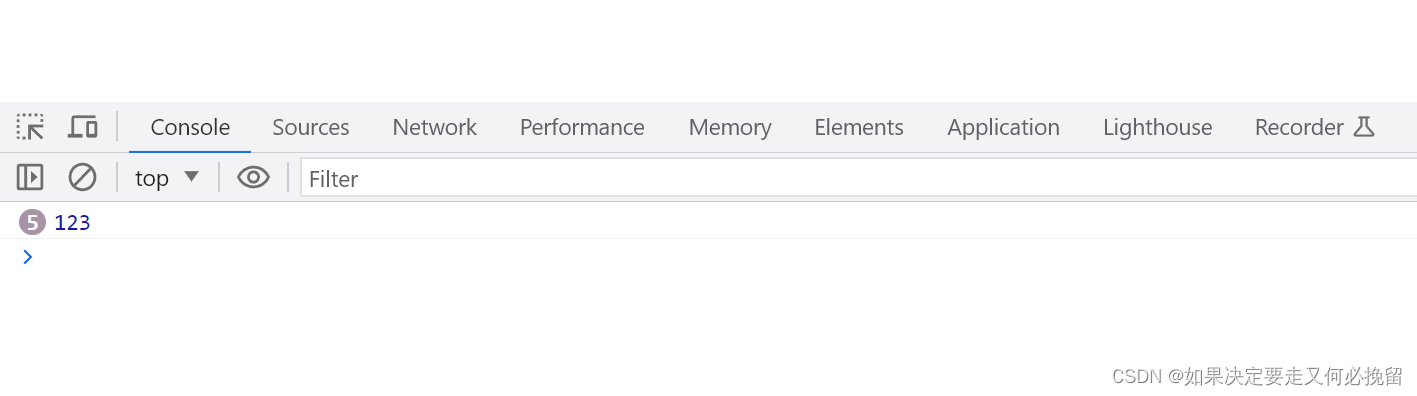
三字代码 http://www.6qt.net/

爬取城市、三字代码、所属国家、国家代码、四字代码、机场名称、英文名称、查询次数
import requests
url = 'http://www.6qt.net/'
r = requests.get(url)
r.encoding='gb2312'
print(r.text)
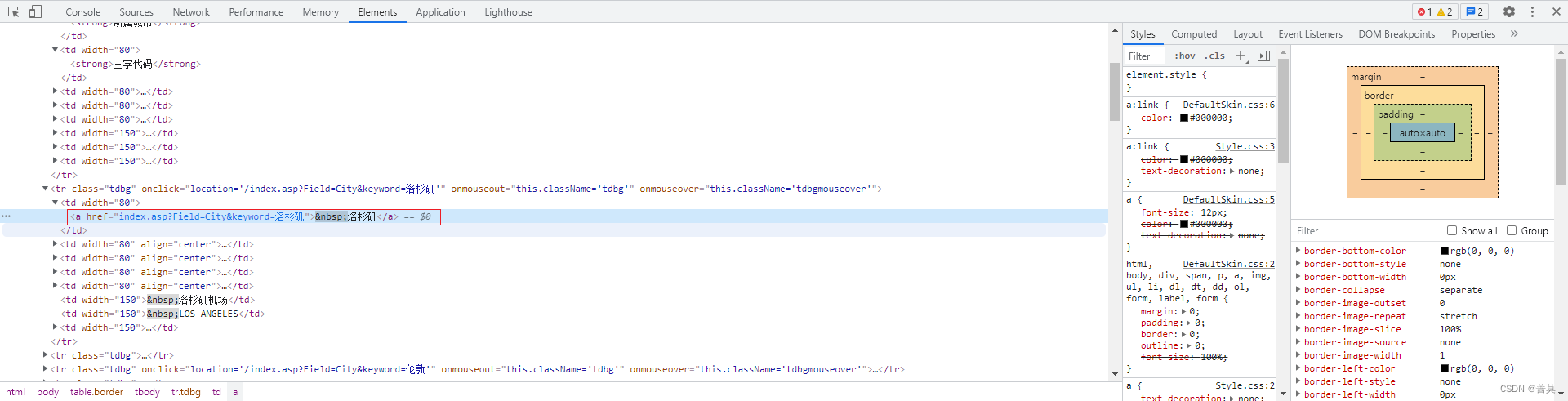
使用xpath解析,得到城市名
html.fromstring(html, base_url=None, parser=None, **kw)
Parse the html, returning a single element/document.解析html,返回单个元素/文档
import requests
from lxml import html
url = 'http://www.6qt.net/'
r = requests.get(url)
r.encoding='gb2312'
data_html = html.fromstring(r.text)
# 提取所有class属性为tdbg的tr元素
tr_html = data_html.xpath('//tr[@class="tdbg"]')# 得到Element对象列表# <Element tr at 0x20695cfdd18>
for tr in tr_html:
city_name = tr.xpath('td[1]/a/text()')
if city_name:
print(city_name[0])

完整代码
import requests
from lxml import html
url = 'http://www.6qt.net/'
r = requests.get(url)
r.encoding='gb2312'
data_html = html.fromstring(r.text)
tr_html = data_html.xpath('//tr[@class="tdbg"]')
for tr in tr_html:
data = {}
city_name = tr.xpath('td[1]/a/text()')
if city_name:
data['city_name'] = city_name[0].replace('\xa0','')
tcc = tr.xpath('td[2]/a/text()') # Three character code三字代码
if city_name:
data['tcc'] = tcc[0].replace('\xa0','')
country = tr.xpath('td[3]/a/u/text()')
if city_name:
data['country'] = country[0]
country_code = tr.xpath('td[4]/a/u/text()')
if city_name:
data['country_code'] = country_code[0]
fcc = tr.xpath('td[5]/a/u/text()')
if city_name:
if fcc: # 有的城市没有四字代码
data['fcc'] = fcc[0]
else:
data['fcc'] = '' # 没有四字代码用空字符串代替
airport_name = tr.xpath('td[6]/text()')
if city_name:
data['airport_name'] = airport_name[0].replace('\xa0','')
en_name = tr.xpath('td[7]/text()')
if city_name:
data['en_name'] = en_name[0].replace('\xa0','')
number = tr.xpath('td[8]/a/text()')
if city_name:
data['number'] = number[0]
if data:
print(data)

ASCII 字符集中的\xa0代表的是非打印字符"非断行空格",也称为"不间断空格",在网页中通常用于表示空格或保持文本的格式。在 HTML 中,它被称为“ ”实体。
可以使用lxml的tostring()函数将一个Element对象转换成可读的代码。例如:
from lxml import etree
# 创建一个HTML文档的根元素
root = etree.Element("html")
# 创建一个<head>标签并添加到根元素中
head = etree.SubElement(root, "head")
# 创建一个<title>标签并添加到<head>标签中
title = etree.SubElement(head, "title")
title.text = "Welcome to my website"
# 将根元素转换为可读的HTML代码并打印输出
html_code = etree.tostring(root, pretty_print=True, encoding='unicode')
print(html_code)
运行上述代码后,输出的结果为:
<html>
<head>
<title>Welcome to my website</title>
</head>
</html>