文章目录
- datetime
- base64
- hashlib
- hmac
- urllib
- XML
- HTMLParser
- random
- 小结
datetime
datetime是Python处理日期和时间的标准库。
获取当前日期时间
from datetime import datetime
now = datetime.now() # 获取当前datetime
print(now) #2023-09-13 10:28:48.621343
print(type(now))#<class 'datetime.datetime'>
- 注意到
datetime是模块,通过from datetime import datetime导入的才是datetime这个类。- 如果仅导入import datetime,则必须引用
全名datetime.datetime
- 如果仅导入import datetime,则必须引用
获取指定日期和时间
dt = datetime(2023, 9, 13, 12, 20) # 用指定日期时间创建datetime
print(dt)
datetime转换为timestamp
- 在计算机中,时间实际上是用
数字表示的。我们把1970年1月1日 00:00:00 UTC+00:00时区的时刻称为epoch time,记为0(1970年以前的时间timestamp为负数),当前时间就是相对于epoch time的秒数,称为timestamp。
dt = datetime(2023, 9, 13, 12, 20) # 用指定日期时间创建datetime
print(dt.timestamp()) # 把datetime转换为timestamp
#1694578800.0
- 注意Python的timestamp是一个
浮点数,整数位表示秒。
timestamp也可以直接被转换到UTC标准时区的时间:
t = 1429417200.0
print(datetime.fromtimestamp(t)) # 本地时间
#2015-04-19 12:20:00
print(datetime.utcfromtimestamp(t)) # UTC时间
#2015-04-19 04:20:00
str转换为datetime
- 通过datetime.strptime()实现,需要一个日期和时间的格式化字符串:
cday = datetime.strptime('2015-6-1 18:19:59', '%Y-%m-%d %H:%M:%S')
print(cday)
#2015-06-01 18:19:59
datetime转换为str
now = datetime.now()
print(now.strftime('%a, %b %d %H:%M'))
#Mon, May 05 16:28
datetime加减
- 对日期和时间进行加减实际上就是把
datetime往后或往前计算,得到新的datetime。加减可以直接用+和-运算符,不过需要导入timedelta这个类:
from datetime import datetime, timedelta
now = datetime.now()
datetime(2023, 9, 13, 10, 30, 3, 540997)
print(now + timedelta(hours=10))#2023-09-13 20:38:44.709003
datetime(2023, 9, 13, 10, 30, 3, 540997)
print(now - timedelta(days=1))#2023-09-12 10:38:44.709003
datetime(2023, 9, 13, 10, 30, 3, 540997)
print(now + timedelta(days=2, hours=12))#2023-09-12 10:38:44.709003
本地时间转换为UTC时间
from datetime import datetime, timedelta, timezone
tz_utc_8 = timezone(timedelta(hours=8)) # 创建时区UTC+8:00
now = datetime.now()
print(now)
dt = now.replace(tzinfo=tz_utc_8) # 强制设置为UTC+8:00
print(dt)
dt = datetime(2015, 9, 13, 10, 40, 13, 610986, tzinfo=timezone(timedelta(0, 28800)))
print(dt)
时区转换
from datetime import datetime, timedelta, timezone
# 拿到UTC时间,并强制设置时区为UTC+0:00:
utc_dt = datetime.utcnow().replace(tzinfo=timezone.utc)
print(utc_dt)
# astimezone()将转换时区为北京时间:
bj_dt = utc_dt.astimezone(timezone(timedelta(hours=8)))
print(bj_dt)
# astimezone()将转换时区为东京时间:
tokyo_dt = utc_dt.astimezone(timezone(timedelta(hours=9)))
print(tokyo_dt)
# astimezone()将bj_dt转换时区为东京时间:
tokyo_dt2 = bj_dt.astimezone(timezone(timedelta(hours=9)))
print(tokyo_dt2)
小结
-
datetime表示的时间需要时区信息才能确定一个特定的时间,否则只能视为本地时间。
-
如果要存储datetime,最佳方法是将其
转换为timestamp再存储,因为timestamp的值与时区完全无关。
base64
Base64是一种任意二进制转换文本字符串的编码方法,常用于在URL、Cookie、网页中传输少量二进制数据。
-
Base64的原理很简单,首先,准备一个包含64个字符的数组:
['A', 'B', 'C', ... 'a', 'b', 'c', ... '0', '1', ... '+', '/'] -
然后,对二进制数据进行处理,
每3个字节一组,一共是3x8=24bit,划为4组,每组正好6个bit: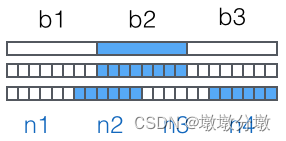
-
这样我们得到4个数字作为索引,然后
查表,获得相应的4个字符,就是编码后的字符串。-
所以,Base64编码
会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。 -
如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?
- Base64用
\x00字节在末尾补足后,再在编码的末尾上1个或2个=号,表示补了多少字节,解码的时候,会自动去掉。
- Base64用
-
Python内置的base64可以直接进行base64的编解码:
import base64
#`b'str'`可以表示字节,
a = base64.b64encode(b'binary\x00string')
print(a)
b = base64.b64decode(b'YmluYXJ5AHN0cmluZw==')
print(b)
#b'YmluYXJ5AHN0cmluZw=='
#b'binary\x00string'
b'str'可以表示字节,
由于标准Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种"url safe"的base64编码,其实就是把字符+和/分别变成-和_ :
#`b'str'`可以表示字节,
c= base64.b64encode(b'i\xb7\x1d\xfb\xef\xff')
print(c)#b'abcd++//'
d = base64.urlsafe_b64encode(b'i\xb7\x1d\xfb\xef\xff')
print(d)#b'abcd++//'
e = base64.urlsafe_b64decode('abcd--__')
print(e)#b'abcd++//'
hashlib
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
**什么是摘要算法呢?
-
**摘要算法又称
哈希算法、散列算法。摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。(通常用16进制的字符串表示)。 -
摘要算法之所以能指出数据是否被篡改过
- 因为摘要函数是一个
单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
- 因为摘要函数是一个
应用场景
- 写了一篇文章,内容是一个字符串’how to use python hashlib - by Michael’,并附上这篇文章的摘要是’
2d73d4f15c0db7f5ecb321b6a65e5d6d’。如果有人篡改了你的文章,并发表为’how to use python hashlib - by Bob’,你可以一下子指出Bob篡改了你的文章,因为根据’how to use python hashlib - by Bob’计算出的摘要不同于原始文章的摘要。
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit/16字节,通常用一个32位的16进制字符串表示。如下所示
import hashlib
md5 = hashlib.md5()
md5.update('how to use md5 in python hashlib?'.encode('utf-8'))
print(md5.hexdigest())
#d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
import hashlib
md5 = hashlib.md5()
md5.update('how to use md5 in '.encode('utf-8'))
md5.update('python hashlib?'.encode('utf-8'))
print(md5.hexdigest())
#d26a53750bc40b38b65a520292f69306
另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:SHA1的结果是160 bit/20字节,通常用一个40位的16进制字符串表示。
import hashlib
sha1 = hashlib.sha1()
sha1.update('how to use sha1 in '.encode('utf-8'))
sha1.update('python hashlib?'.encode('utf-8'))
print(sha1.hexdigest())
#2c76b57293ce30acef38d98f6046927161b46a44
比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法不仅越慢,而且摘要长度更长。
hmac
通过哈希算法,我们可以验证一段数据是否有效,方法就是对比该数据的哈希值,例如,判断用户口令是否正确,我们用保存在数据库中的password_md5对比计算md5(password)的结果,如果一致,用户输入的口令就是正确的。
为了防止黑客通过彩虹表根据哈希值反推原始口令,在计算哈希的时候,不能仅针对原始输入计算,需要增加一个salt来使得相同的输入也能得到不同的哈希,这样,大大增加了黑客破解的难度。
-
如果salt是我们自己随机生成的,通常我们计算MD5时采用
md5(message + salt)。但实际上,把salt看做一个“口令”,加salt的哈希就是:计算一段message的哈希时,根据不同口令计算出不同的哈希。要验证哈希值,必须同时提供正确的口令。-
这实际上就是
Hmac算法:Keyed-Hashing for Message Authentication。它通过一个标准算法,在计算哈希的过程中,把key混入计算过程中。 -
和我们自定义的加salt算法不同,
Hmac算法针对所有哈希算法都通用,无论是MD5还是SHA-1。采用Hmac替代我们自己的salt算法,可以使程序算法更标准化,也更安全。
-
Python自带的hmac模块实现了标准的Hmac算法。我们来看看如何使用hmac实现带key的哈希。
import hmac
#原始数据
message = b'Hello, world!'
#密钥
key = b'secret'
h = hmac.new(key, message, digestmod='MD5')
# 如果消息很长,可以多次调用h.update(msg)
print(h.hexdigest())
#'fa4ee7d173f2d97ee79022d1a7355bcf'
- 需要注意传入的key和message都是
bytes类型,str类型需要首先编码为bytes。
urllib
详见【Python】从入门到上头—网络请求模块urlib和reuests的应用场景(12)
XML
操作XML有两种方法:DOM和SAX。
-
DOM会把整个XML读入内存,解析为树,因此占用
内存大,解析慢,优点是可以任意遍历树的节点。 -
SAX是
流模式,边读边解析,占用内存小,解析快,缺点是我们需要自己处理事件。 -
正常情况下,优先考虑SAX,因为DOM实在太占内存。
在Python中使用SAX解析XML非常简洁,通常我们关心的事件是start_element,end_element和char_data,准备好这3个函数,然后就可以解析xml了。
如: 当SAX解析器读到一个节点时:
<a href="/">python</a>
会产生3个事件:
-
start_element事件,在读取
<a href="/">时; -
char_data事件,在读取
python时; -
end_element事件,在读取
</a>时。from xml.parsers.expat import ParserCreate class DefaultSaxHandler(object): def start_element(self, name, attrs): print('sax:start_element: %s, attrs: %s' % (name, str(attrs))) def end_element(self, name): print('sax:end_element: %s' % name) def char_data(self, text): print('sax:char_data: %s' % text) xml = r'''<?xml version="1.0"?> <ol> <li><a href="/python">Python</a></li> <li><a href="/ruby">Ruby</a></li> </ol> ''' handler = DefaultSaxHandler() parser = ParserCreate() #start_element事件 parser.StartElementHandler = handler.start_element #end_element事件 parser.EndElementHandler = handler.end_element #char_data事件 parser.CharacterDataHandler = handler.char_data #解析 parser.Parse(xml)执行结果
sax:start_element: ol, attrs: {} sax:char_data: sax:char_data: sax:start_element: li, attrs: {} sax:start_element: a, attrs: {'href': '/python'} sax:char_data: Python sax:end_element: a sax:end_element: li sax:char_data: sax:char_data: sax:start_element: li, attrs: {} sax:start_element: a, attrs: {'href': '/ruby'} sax:char_data: Ruby sax:end_element: a sax:end_element: li sax:char_data: sax:end_element: ol- 需要注意的是:读取一大段字符串时,
CharacterDataHandler可能被多次调用,所以需要自己保存起来,在EndElementHandler里面再合并。
- 需要注意的是:读取一大段字符串时,
除了解析XML外,如何生成XML呢?
-
99%的情况下需要生成的XML结构都是非常简单的,因此,
最简单也是最有效的生成XML的方法是拼接字符串:L = [] L.append(r'<?xml version="1.0"?>') L.append(r'<root>') L.append(encode('some & data')) L.append(r'</root>') return ''.join(L)
HTMLParser
如果我们要编写一个搜索引擎,第一步是用爬虫把目标网站的页面抓下来,第二步就是解析该HTML页面,看看里面的内容到底是新闻、图片还是视频。
- 假设第一步已经完成了,第二步应该如何解析HTML呢?
HTML本质上是XML的子集,但是HTML的语法没有XML那么严格,所以不能用标准的DOM或SAX来解析HTML。
Python提供了HTMLParser来非常方便地解析HTML,只需简单几行代码:
from html.parser import HTMLParser
from html.entities import name2codepoint
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print('<%s>' % tag)
def handle_endtag(self, tag):
print('</%s>' % tag)
def handle_startendtag(self, tag, attrs):
print('<%s/>' % tag)
def handle_data(self, data):
print(data)
def handle_comment(self, data):
print('<!--', data, '-->')
def handle_entityref(self, name):
print('&%s;' % name)
def handle_charref(self, name):
print('&#%s;' % name)
parser = MyHTMLParser()
parser.feed('''<html>
<head></head>
<body>
<!-- test html parser -->
<p>Some <a href=\"#\">html</a> HTML tutorial...<br>END</p>
</body></html>''')
-
feed()方法可以
多次调用,也就是不一定一次把整个HTML字符串都塞进去,可以一部分一部分塞进去。 -
特殊字符有两种,一种是英文表示的
,一种是数字表示的Ӓ,这两种字符都可以通过Parser解析出来。
random
Python random 模块主要用于生成随机数。实现了各种分布的伪随机数生成器。
常用方法
andom() 生成一个 [0.0, 1.0) 之间的随机小数
seed(seed) 初始化给定的随机数种子
randint(a, b) 生成一个 [a, b] 之间的随机整数
uniform(a, b) 生成一个 [a, b] 之间的随机小数
choice(seq) 从序列 seq 中随机选择一个元素
shuffle(seq) 将序列 seq 中元素随机排列, 返回打乱后的序列
random.random()
import random
print(random.random())
#0.4784904215869241
**random.seed(seed) **
-
初始化给定的随机数种子
-
计算机使用确定性的算法计算出一个随机数序列。计算机产生的随机数并不真正的随机,
但具有类似于随机数的统计特征,如均匀性、独立性等。 -
计算机根据
随机数种子产生随机数序列,如果随机数种子相同,每次产生的随机数序列是相同的;如果随机数种子不同,产生的随机数序列是不同的。random.seed(10) a = random.randint(0, 100) print(a) a = random.randint(0, 100) print(a) a = random.randint(0, 100) print(a) # 73 # 4 # 54 random.seed(10) a = random.randint(0, 100) print(a) a = random.randint(0, 100) print(a) a = random.randint(0, 100) print(a) # 73 # 4 # 54- 结果
第1个random.seed(10)设定种子为 10 产生第 1 个随机数 73 产生第 2 个随机数 4 产生第 3 个随机数 54 第2个random.seed(10)设定种子为 10 产生第 1 个随机数 73 产生第 2 个随机数 4 产生第 3 个随机数 54 可以看出,当种子相同时,产生的随机数序列是相同的
random.randint(a, b)
-
生成一个 [a, b] 之间的随机整数,示例如下:
a = random.randint(0, 2) print(a) a = random.randint(0, 2) print(a) a = random.randint(0, 2) print(a) # 1 # 2 # 0
random.uniform(a, b)
- 是生成一个 [a, b] 之间的随机小数
import random random.uniform(0, 2) #0.20000054219225438 random.uniform(0, 2) #1.4472780206791538 random.uniform(0, 2) #0.5927807855738692
random.choice(seq)
-
从序列 seq 中随机选择一个元素
import random seq = [1, 2, 3, 4] random.choice(seq) #3 random.choice(seq) #1
random.shuffle(seq)
-
将序列 seq 中元素随机排列, 返回打乱后的序列
import random seq = [1, 2, 3, 4] random.shuffle(seq) #[1, 3, 2, 4]
小结
- 利用HTMLParser,可以把网页中的
文本、图像等解析出来。