1.gc算法有哪些
引用计数(循环引用)和可达性分析找到无用的对象
标记-清除:简单,内存碎片,大对象找不到空间
标记-复制:分成两半,清理一半,没有碎片,如果存活多效率低(适合新生代)
标记-整理:将存活对象向一端移动,清除边界外(适合老年代)
分代收集:老年代回收少,新生代回收多;对新生代使用复制算法,一个较大的eden和两个较小的survivor,提高空间利用的效率
2.反射的核心类是啥
反射是一种在程序运行时可以动态访问,修改某个类中任意属性和方法的机制(包括private)
功能包括:
1.判断对象所属的类
2.构造一个类的对象
3.判断类具有的变量和方法
4.调用任意一个对象方法
核心类包括四个:
1.java.lang.Class.java:类对象
2.java.lang.reflect.Constructor.java:类的构造器对象
3.java.lang.reflect.Method.java:类的方法对象
4.java.lang.reflect.Field.java:类的属性对象
工作原理:
java变成.class后有类的所有信息,父类接口构造函数方法属性;在运行时会被classLoader加载到虚拟机。类被加载后,jvm自动产生一个class对象,new就是通过这些class对象创建。
3.nio和io多路复用原理
用户进程想执行io,需要发起系统调用访问内核空间,包括:
1.内核等待io准备好数据
2.内核将数据从内核空间拷贝到用户空间
NIO(Non-blocking io)是只同步非阻塞io,使用轮询
1.如果kernel没有数据,调用失败,不需要等待
2.如果kernel有数据,阻塞,复制完成后才返回成功
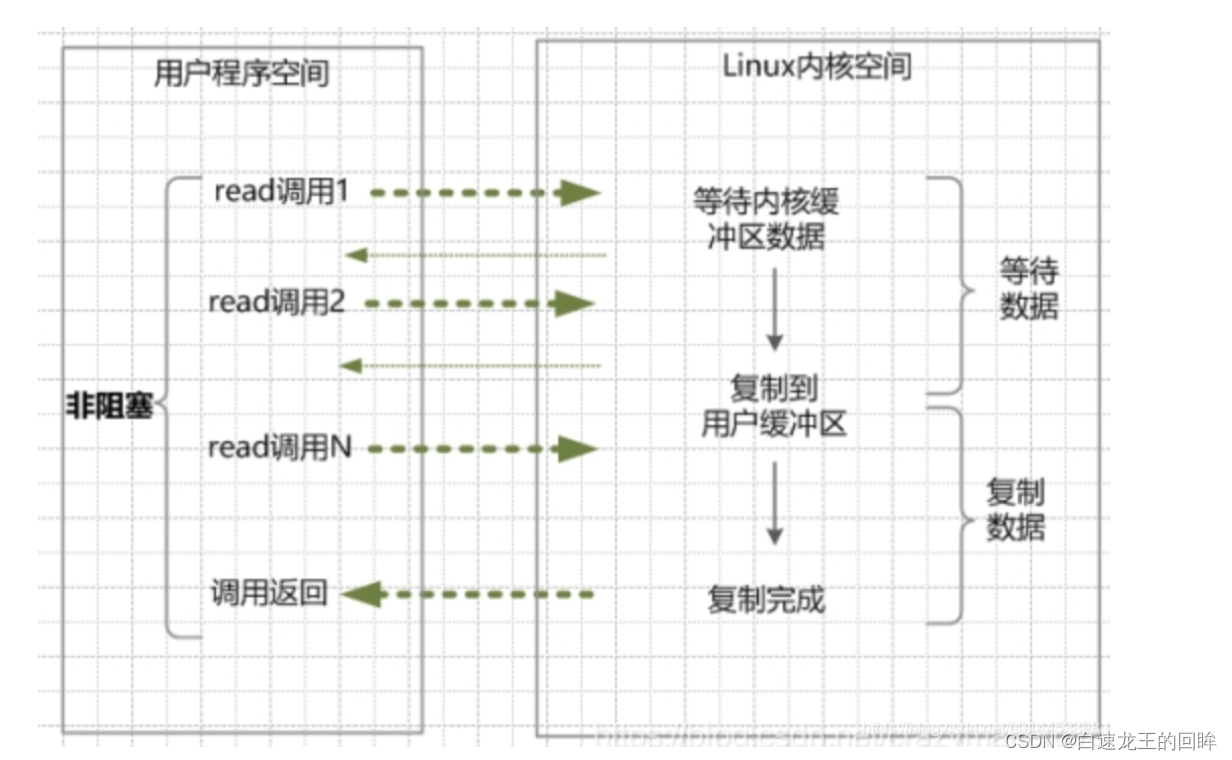
NIO优点:无序等待无数据
NIO缺点:轮询占用cpu;定时轮训不及时;read导致用户态内核态频繁转换
IO多路复用(也就是java中的NIO, newIO)
1.一个线程监视多个描述符socket,一旦某个描述符就绪(kernel可读可写),可以通知程序进行io,系统调用包括select,poll, epoll
2.select会阻塞到socket有数据就绪,再调用read
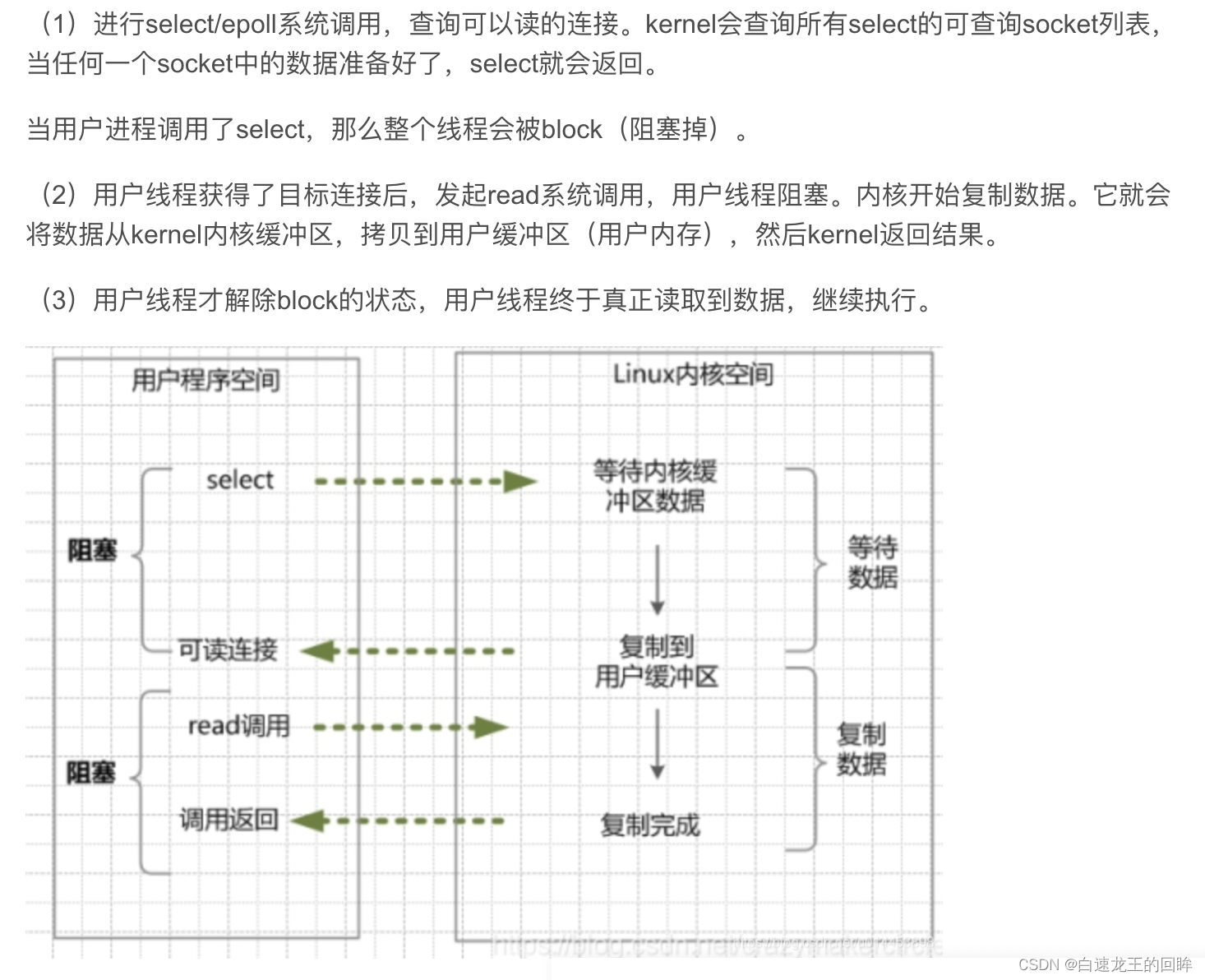
io多路复用优点:改为select轮询,查找可io的操作;可同时管理多条连接
io多路缺点:select也属于同步阻塞io
select和poll:线性结构存储socket集合,需要遍历文件描述符集合找到可用socket
epoll:用红黑树跟踪文件描述符(logn),事件驱动维护链表记录就绪事件
4.MYSQL索引列建议
适合:
1.唯一性限制
2.频繁where,order by和group by
3.多表join的连接字段创建索引,类型必须一致(否则隐式转换导致索引失效)
4.字符串前缀创建索引,使用最频繁放联合索引左侧
5.多个字段维护索引,联合索引更优
不合适:
1.数据量小没有效果
2.大量重复数据高于10%例如性别
3.经常更新的表索引影响效率
4.无序的值不要做索引
5.每张表索引不超过6个
5.MYSQL事务特性
MySQL 事务具有四个特性:原子性、一致性、隔离性、持久性,这四个特性简称 ACID 特性
一、原子性(Atomicity ):一个事务是一个不可再分割的整体,要么全部成功,要么全部失败
事务在数据库中就是一个基本的工作单位,事务中包含的逻辑操作(SQL 语句),只有两种情况:成功和失败。事务的原子性其实指的就是这个逻辑操作过程具有原子性,不会出现有的逻辑操作成功,有的逻辑操作失败这种情况
二、一致性(Consistency ):一个事务可以让数据从一种一致状态切换到另一种一致性状态
举例说明:张三给李四转账 100 元,那么张三的余额应减少 100 元,李四的余额应增加 100 元,张三的余额减少和李四的余额增加这是两个逻辑操作具有一致性
三、隔离性(Isolution ):一个事务不受其他事务的影响,并且多个事务彼此隔离
一个事务内部的操作及使用的数据,对并发的其他事务是隔离的,并发执行的各个事务之间不会互相干扰
四、持久性(Durability ):一个事务一旦被提交,在数据库中的改变就是永久的,提交后就不能再回滚
一个事务被提交后,在数据库中的改变就是永久的,即使系统崩溃重新启动数据库数据也不会发生改变
6.分布式id实现方案
唯一标识

雪花算法:

号段模式:也是基于数据库,但分段,每次可以获得多个id,性能提升
7.RPC原理
remote procedure call,远程过程调用,使得分布式应用更容易
rpc一般都有长链接,都有注册中心,协议效率更高
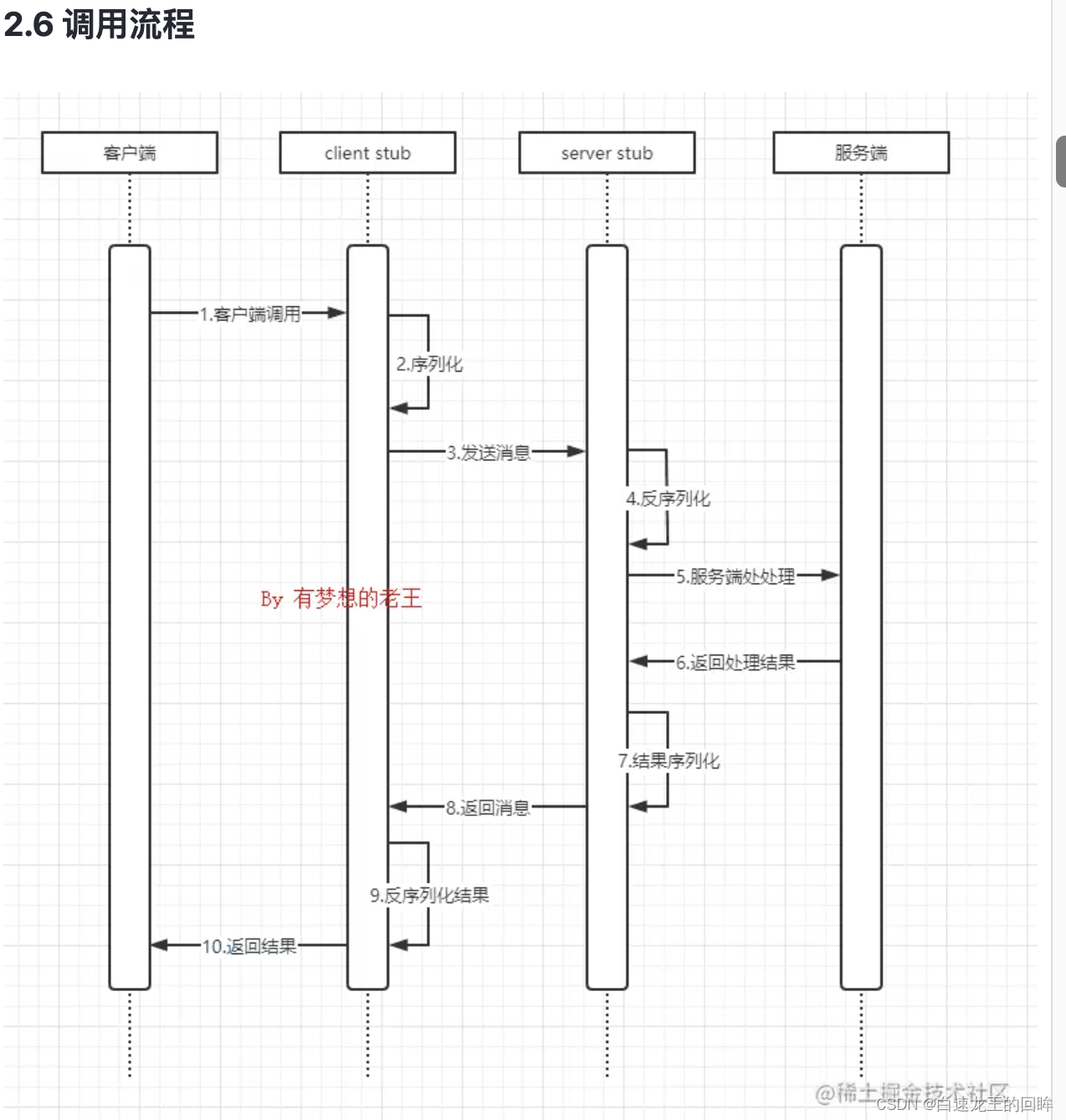
1.client发起调用给client stub
2.client stub序列化后找到地址发给server stub
3.server stub解码后调用本地服务处理
4.得到返回结果后发给stub序列哈再发给client stub
5.client stub解码后发给client得到结果
涉及到的技术:
1.动态代理,stub的生成需要java动态代理
2.序列化,例如fastjson,数据都转化为字节
3.nio通信,例如dubbo
4.服务注册中心,client连接server发布的服务,dubbo用zookeeper
5.负载均衡多节点集群
6.探活:client心跳和server主动探测
8.redis除了缓存还能做什么
队列:list,例如将爬虫失败的存到redis队列,再启动一个线程自旋的方式阻塞式取出
签到:bitmap,二进制数组,setbit, bitcount获取结果
原子扣减库存:lua脚本保证原子性
分布式锁:setnx + 过期事件用lua保证原子性;锁有心跳检测,防止未解锁,锁失效问题;线程自旋获取锁;redisson框架
延迟队列,排行榜:zset,用score作为延迟的时间点,顺序获得端口的值,如果时间戳大于等于score可以取出
分布式id递增等等
9.redis数据结构底层
string:sds,获取长度o1,不会溢出,二进制安全
列表:双端链表
字典:类似hashmap
跳表:查询插入删除logn,zset
压缩列表:一块连续的内存空间,没有空隙(当lsit数据较少时,多了就linkedlist)
快速列表:由于每个节点都有prev和next指针,内存单独分配,使用quicklist代替。它是ziplist和linkedlist的混合,将linkedlist切分,每一段数据使用ziplist紧凑存储,多个ziplist之间用指针串联
10.springboot的自动装配原理
自动装配:通过注解或者一些简单的配置就可以在springboot的帮助下实现某块功能
@springbootapplicaiton = @configuration + @enableautoConfiguration + @ComponentScan
@EnableAutoConfiguration:实现自动装配的核心注解,importSelector获取所有符合条件的类的全限定类名,这些类需要被加载到ioc容器中
@configuration:允许在上下文注册额外的bean或导入其他配置类
@componentScan:扫描被@Component注解的bean,启动类所在包下的所有类,可以通过filter排除不扫描的包
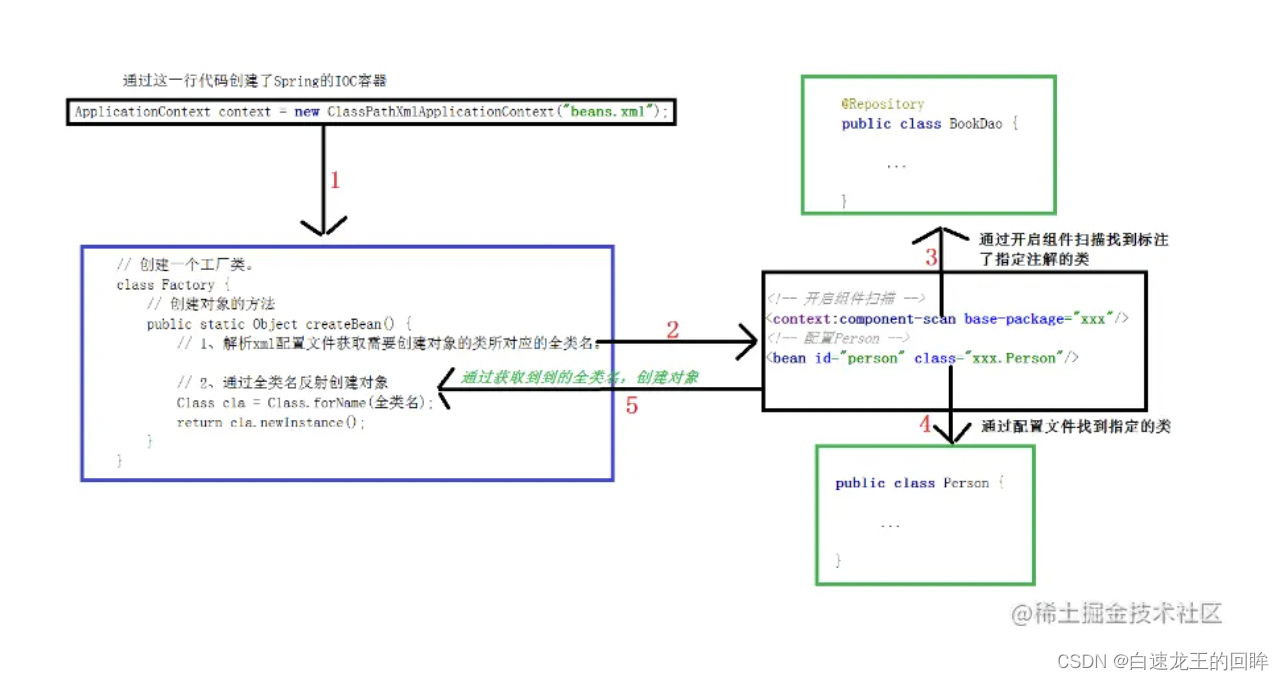
11.spring的ioc原理
ioc=控制反转,把创建对象的控制交给spring进行管理,原来自己要new现在直接从spring获取
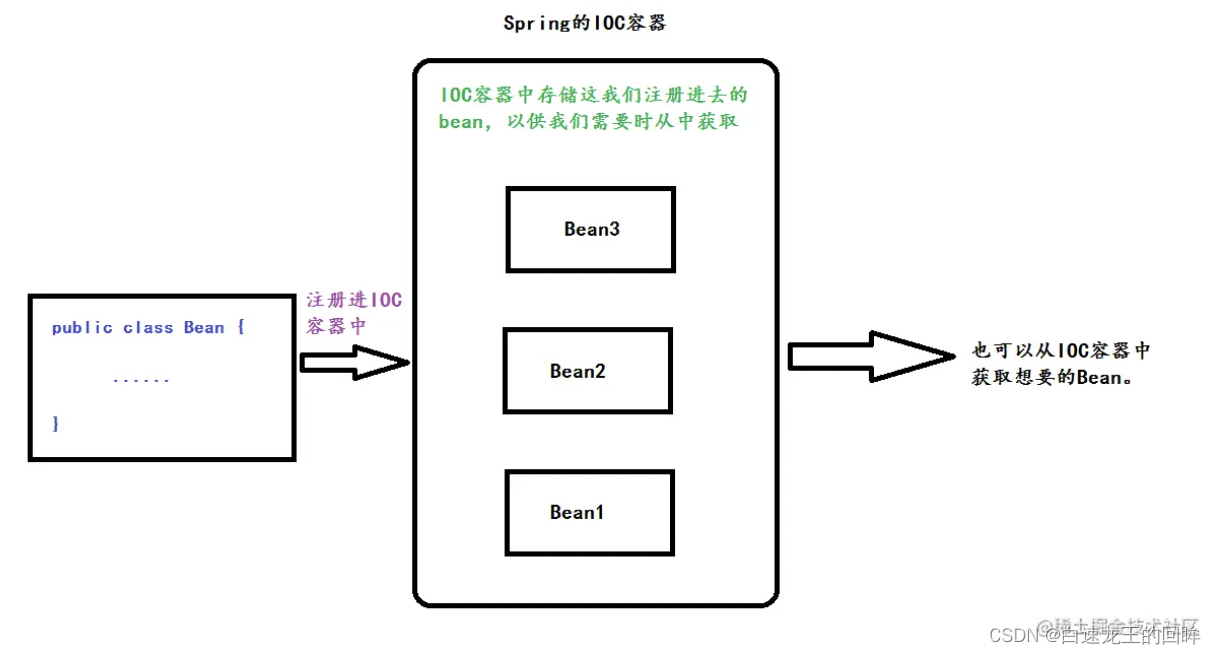
减低了代码的耦合度,降低程序的维护成本。
spring提供了一个beanFactory,他还有一个ApplicationContext,通过工厂+反射实现
12.autowired和resource区别,autowired希望byname咋办
都可以卸载字段or setter上
autowired只能byTpye注入,如果希望byName可以结合@Qualifier一起使用或者@Primary
resource默认通过ByName注入,spring会把@resource注解的name属性解析为bean的名字
13.一致性哈希了解吗
多副本负载均衡可以用加权轮询,但是对于数据分片分布式系统不适用
例如某个key只能在某些node上获取
如果使用hash(key) % n进行映射,当n变化时会迁移数据,成本高
用一致性哈希会有一个2**32-1的空间,将节点和data都映射到一个哈希环上
数据i存储节点就是hash顺时针找到的第一个节点
加入节点只影响相邻节点
但是,一致性哈希不保证分布均匀
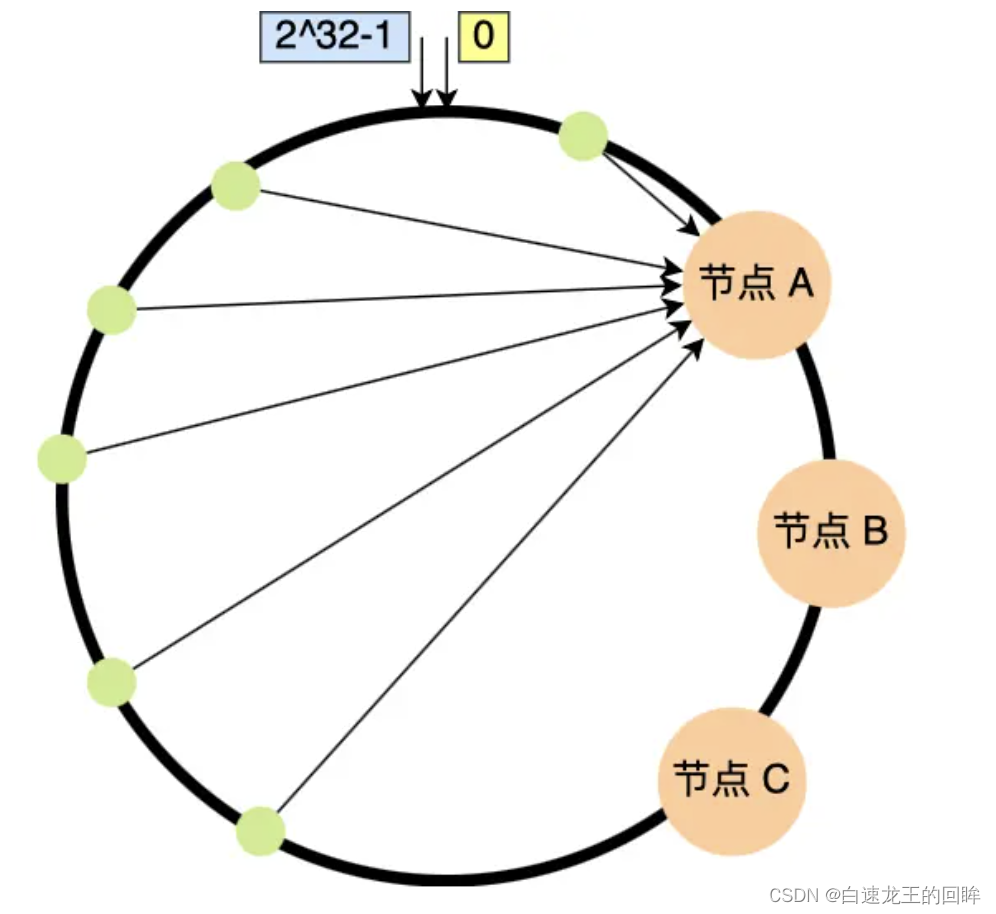
可能会导致数据的全体迁移
通过引入虚拟节点解决不均匀问题
原有节点多复制一些可以提高节点的均衡度,使得某个节点不会负载特别高