目录
1 Pandas 可视化功能
2 Pandas绘图实例
2.1 绘制线图
2.2 绘制柱状图
2.3 绘制随机散点图
2.4 绘制饼图
2.5 绘制箱线图A
2.6 绘制箱线图B
2.7 绘制散点图矩阵
2.8 绘制面积图
2.9 绘制热力图
2.10 绘制核密度估计图
1 Pandas 可视化功能
pandas是一个强大的数据分析库,提供了一些可视化工具来帮助用户更好地理解和展示数据。以下是pandas可视化工具的一些常见功能:
1. 折线图:通过plot()函数可以绘制折线图,展示数据随时间或其他变量的变化趋势。
2. 散点图:使用scatter()函数可以绘制散点图,在二维平面上展示两个变量之间的关系。
3. 条形图:使用bar()函数可以绘制条形图,用于比较不同类别或组的数值大小。
4. 直方图:使用hist()函数可以绘制直方图,用于展示数值型数据的分布情况。
5. 饼图:使用pie()函数可以绘制饼图,展示不同类别的占比情况。
6. 箱线图:使用boxplot()函数可以绘制箱线图,展示数值型数据的分布特征、离群值等。
Pandas 是一个用于数据处理和分析的流行库,它提供了一些内置的可视化功能,通常基于 Matplotlib 这个底层库。
-
绘制线图:
df['column_name'].plot(kind='line')
绘制柱状图:
df['column_name'].plot(kind='bar')
绘制散点图:
df.plot(x='x_column', y='y_column', kind='scatter')
hist()函数:hist()函数用于绘制直方图,以显示数据的分布和频率。
df['column_name'].hist(bins=10)
boxplot()函数:boxplot()函数用于绘制箱线图,显示数据的分位数和离群值。
df.boxplot(column='column_name')
scatter_matrix()函数:scatter_matrix()函数用于绘制多个变量之间的散点图矩阵,有助于了解变量之间的关系。
from pandas.plotting import scatter_matrix
scatter_matrix(df, alpha=0.5, figsize=(8, 8), diagonal='hist')
plotting.scatter_matrix()函数:这是一个更高级的散点图矩阵绘制函数,可以自定义每个子图的属性。
from pandas.plotting import scatter_matrix
scatter_matrix(df, alpha=0.5, figsize=(8, 8), diagonal='kde', color='red')
plot.barh()函数:plot.barh()函数用于绘制水平柱状图。
df['column_name'].plot(kind='barh')
plot.pie()函数:plot.pie()函数用于绘制饼图,用于显示数据的占比。
df['column_name'].plot(kind='pie', autopct='%1.1f%%')
plot.area()函数:plot.area()函数用于绘制堆叠面积图,显示数据的累积变化趋势。
df.plot.area()
plot.kde()函数:plot.kde()函数用于绘制核密度估计图,显示数据的概率密度分布。
2 Pandas绘图实例
2.1 绘制线图
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
# 创建数据
data = {'年份': [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017],
'销售额': [100, 150, 120, 180, 200, 250, 300, 280]}
# 转换为DataFrame格式
df = pd.DataFrame(data)
# 绘制折线图
plt.plot(df['年份'], df['销售额'], marker='o')
# 设置x轴和y轴标签、标题
plt.xlabel('年份')
plt.ylabel('销售额')
plt.title('销售额变化趋势')
# 添加图例
plt.legend(['销售额'])
# 显示图形
plt.show()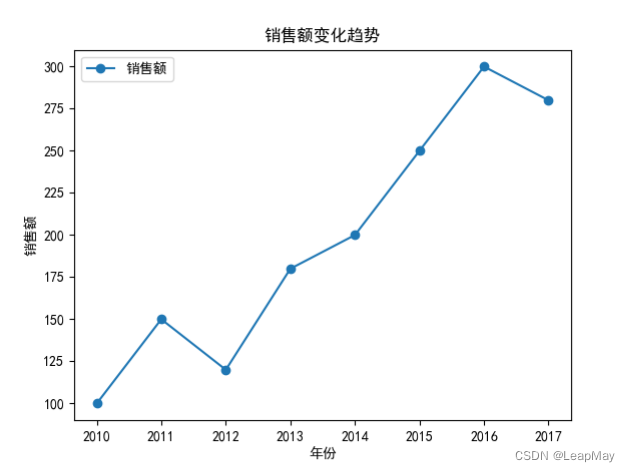
当使用Pandas绘制柱状图、散点图和饼图时,您可以使用plot()函数的不同kind参数来指定要绘制的图表类型。
2.2 绘制柱状图
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 替换为您系统中支持的字体
# 创建一个示例DataFrame
data = {'Category': ['A', 'B', 'C', 'D'],
'Values': [10, 15, 7, 12]}
df = pd.DataFrame(data)
# 绘制柱状图
df.plot(x='Category', y='Values', kind='bar', title='柱状图')
plt.xlabel('类别')
plt.ylabel('数值')
plt.show()
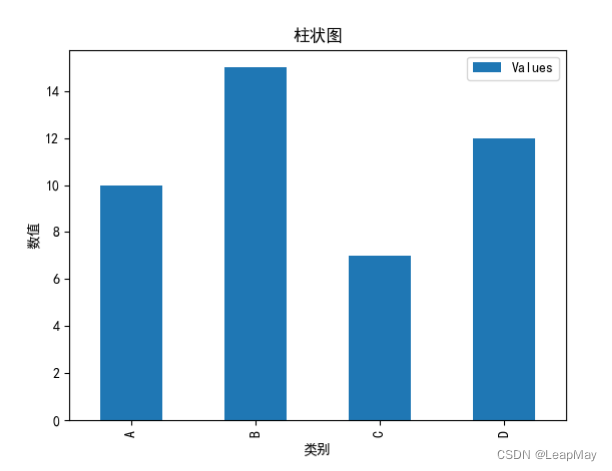
2.3 绘制随机散点图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 替换为您系统中支持的字体
# 生成随机数据
np.random.seed(0) # 设置随机种子以确保可重复性
num_points = 100
x = np.random.rand(num_points) # 随机生成x坐标
y = np.random.rand(num_points) # 随机生成y坐标
colors = np.random.rand(num_points) # 随机生成颜色值
# 创建DataFrame
data = {'X': x, 'Y': y, 'Color': colors}
df = pd.DataFrame(data)
# 绘制散点图
plt.figure(figsize=(8, 6)) # 设置图形大小
plt.scatter(x='X', y='Y', c='Color', data=df, cmap='viridis', alpha=0.7)
plt.xlabel('X轴')
plt.ylabel('Y轴')
plt.title('随机散点图')
plt.colorbar(label='颜色')
plt.show()
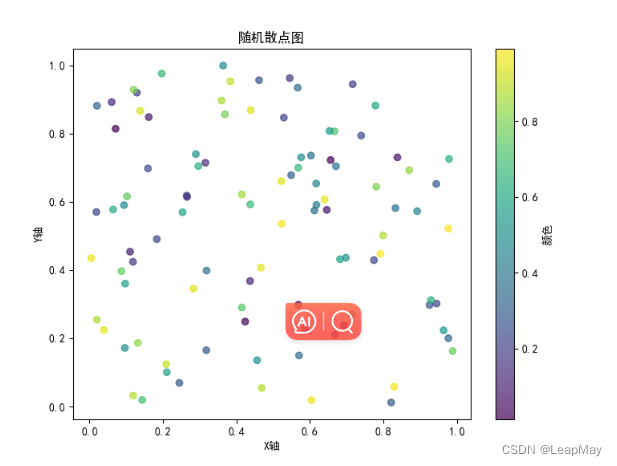
上述示例中,我们首先使用NumPy生成了一些随机的x和y坐标数据,以及随机的颜色值。然后,我们将这些数据放入一个Pandas DataFrame 中,并使用Matplotlib绘制了散点图。颜色使用了色彩映射(cmap),并添加了颜色条(colorbar)以显示颜色映射的对应关系。
2.4 绘制饼图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 替换为您系统中支持的字体
# 创建一个示例DataFrame,包含不同类别的值
data = {'Category': ['A', 'B', 'C', 'D'],
'Values': [10, 15, 7, 12]}
df = pd.DataFrame(data)
# 指定用于饼图的数值列和标签列
values = df['Values']
labels = df['Category']
# 绘制饼图
plt.figure(figsize=(6, 6)) # 设置图形大小
df.plot(y='Values', kind='pie', labels=df['Category'], autopct='%1.1f%%', title='饼图') # 绘制饼图
plt.title('饼图') # 设置图表标题
# 显示图表
plt.axis('equal') # 使饼图保持圆形
plt.show()

在上述示例中,首先创建了一个包含类别和对应数值的DataFrame。然后,使用
plt.pie()函数来绘制饼图,其中values包含数值数据,labels包含饼图的标签。autopct参数用于显示百分比标签,startangle参数用于指定饼图的起始角度。最后,使用plt.axis('equal')确保饼图保持圆形。
2.5 绘制箱线图A
import pandas as pd
import matplotlib.pyplot as plt
import random
plt.rcParams['font.sans-serif'] = ['SimHei']
# 创建示例数据集
data = {
'Product_A': [random.randint(50, 100) for _ in range(50)],
'Product_B': [random.randint(40, 90) for _ in range(50)],
'Product_C': [random.randint(60, 110) for _ in range(50)],
'Product_D': [random.randint(30, 70) for _ in range(50)],
'Product_E': [random.randint(20, 80) for _ in range(50)],
'Product_F': [random.randint(70, 120) for _ in range(50)]
}
df = pd.DataFrame(data)
# 使用boxplot()函数绘制箱线图
df.boxplot(column=['Product_A', 'Product_B', 'Product_C', 'Product_D', 'Product_E', 'Product_F'])
# 添加标题和标签
plt.title('不同产品销售数据箱线图')
plt.ylabel('销售数量')
# 显示图形
plt.show()
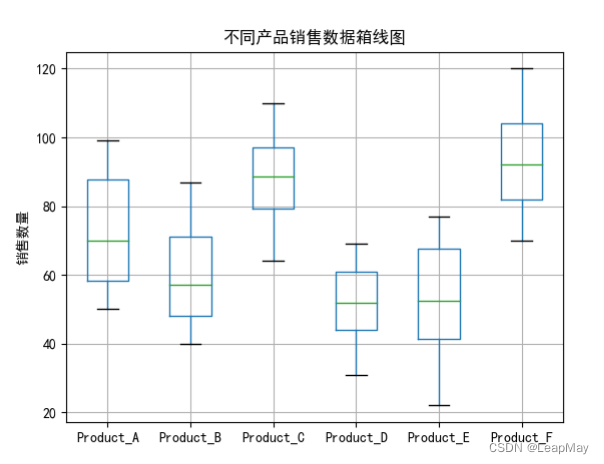
在这个示例中,我们创建了一个包含6种产品的示例DataFrame
df,每种产品有50个销售数据点。然后,我们使用boxplot()函数绘制了这6种产品的箱线图。箱线图将展示每种产品的销售数量分布情况,包括中位数、四分位数、离群值等信息。通过比较不同产品的箱线图,您可以更好地了解它们的销售数据分布,以便进行进一步的分析和决策。这种可视化方法可以帮助您分析潜在的销售趋势和异常情况。
2.6 绘制箱线图B
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #替换为系统中支持的字体
# 创建一个示例数据集,包括三个组的数据
data = pd.DataFrame({
'Group1': np.random.normal(0, 1, 100),
'Group2': np.random.normal(2, 1, 100),
'Group3': np.random.normal(1, 1, 100),
'Group4': np.random.normal(3, 1, 100)
})
# 使用boxplot()函数绘制箱线图,指定显示的列和参数
data.boxplot(column=['Group1', 'Group2', 'Group3', 'Group4'],
notch=True, # 添加缺口以估计中位数的不确定性
sym='o', # 设置异常值标记为圆圈
vert=False, # 水平显示箱线图
patch_artist=True, # 填充箱体颜色
showmeans=True, # 显示均值点
meanline=True, # 显示均值线
widths=0.5 # 箱体宽度
)
# 添加标题和标签
plt.title('箱线图示例')
plt.xlabel('值')
plt.ylabel('分组')
# 显示图形
plt.show()
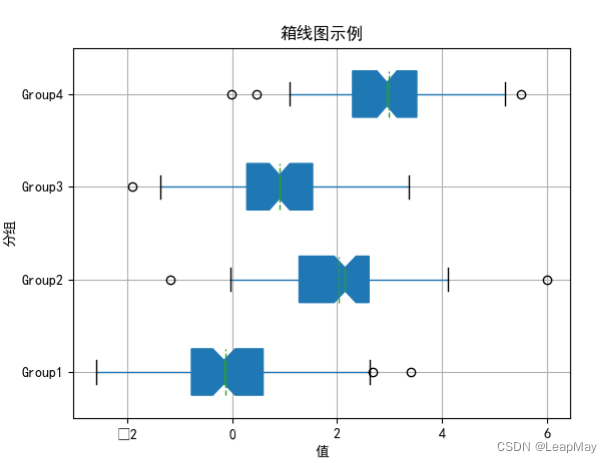
在这个示例中,我们创建了一个包含四个组的示例DataFrame
data,每个组有100个随机数。然后,我们使用boxplot()函数绘制箱线图,并自定义了多个参数:
notch=True:在箱体中添加缺口以估计中位数的不确定性。sym='o':将异常值标记为圆圈。vert=False:水平显示箱线图。patch_artist=True:填充箱体颜色。showmeans=True:显示均值点。meanline=True:显示均值线。widths=0.5:设置箱体宽度。其中每个箱体表示一个组的数据分布情况。箱线图还显示了中位数、均值点和异常值。这种可视化工具有助于比较多个组的数据分布,并检测异常值。
2.7 绘制散点图矩阵
pandas.plotting.scatter_matrix()函数用于绘制多个变量之间的散点图矩阵,帮助您了解各个变量之间的关系。这个函数可以自定义每个子图的属性,包括颜色、标记、直方图和核密度估计等。下面是一个详细的示例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pandas.plotting import scatter_matrix
plt.rcParams['font.sans-serif'] = ['SimHei']
# 创建一个包含多个变量的示例数据集
data = pd.DataFrame(np.random.randn(100, 4), columns=['A', 'B', 'C', 'D'])
# 使用scatter_matrix()函数绘制散点图矩阵
# 主要参数包括DataFrame对象,alpha(透明度),diagonal(对角线上的图表类型),color(颜色),marker(标记类型)等
scatter_matrix(data, alpha=0.8, figsize=(8, 8), diagonal='hist', color='blue', marker='o')
# 添加标题
plt.suptitle('散点图矩阵示例')
# 显示图形
plt.show()
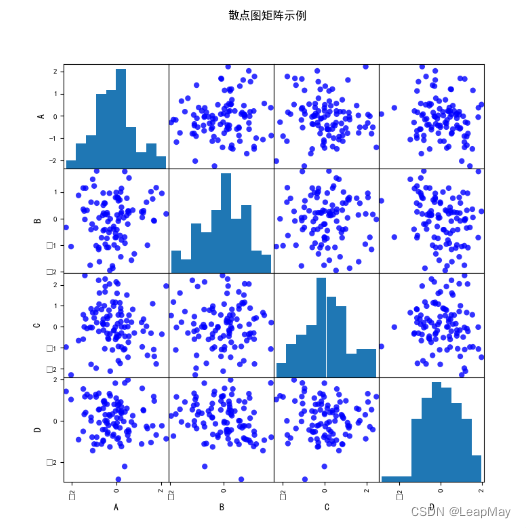
在这个示例中,我们首先创建了一个包含四个随机变量的示例DataFrame
data。然后,我们使用scatter_matrix()函数绘制散点图矩阵,指定了一些参数:
alpha参数设置透明度,这样可以看到重叠点。figsize参数设置图形的大小。diagonal参数设置对角线上的图表类型,这里使用直方图。color参数设置散点的颜色。marker参数设置散点的标记类型。最后,我们添加了标题并显示图形。
2.8 绘制面积图
面积图 (Area Plot)
面积图用于可视化时间序列或有序数据的变化趋势,通常用于显示数据的累积变化
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
# 创建示例数据集
data = {
'Year': [2000, 2001, 2002, 2003, 2004],
'Product_A': [100, 120, 140, 160, 180],
'Product_B': [80, 90, 110, 130, 150]
}
df = pd.DataFrame(data)
# 使用plot()函数创建面积图
plt.figure(figsize=(8, 6))
plt.stackplot(df['Year'], df['Product_A'], df['Product_B'], labels=['Product_A', 'Product_B'], alpha=0.7)
plt.xlabel('年份')
plt.ylabel('销售数量')
plt.title('面积图示例')
plt.legend(loc='upper left')
plt.show()
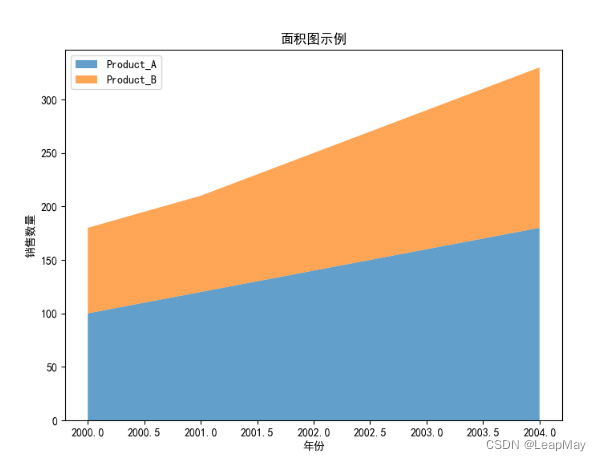
在上述示例中,我们首先创建了一个包含年份和两种产品销售数量的示例DataFrame。然后,使用
stackplot()函数创建面积图,alpha参数设置透明度,labels参数设置图例标签,legend()函数用于显示图例。
2.9 绘制热力图
热力图 (Heatmap)
热力图用于可视化矩阵数据中各个元素之间的关系,通常通过颜色来表示数值的大小。
要在Pandas中绘制热力图,通常需要使用辅助库,最常见的是Seaborn和Matplotlib。Seaborn提供了高级的热力图绘制函数,而Matplotlib用于显示图形。以下是如何在Pandas中使用Seaborn和Matplotlib绘制热力图的示例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei'] #替换为系统中支持的字体
# 创建示例数据集
data = np.random.rand(5, 5) # 5x5的随机矩阵
# 转换为DataFrame
df = pd.DataFrame(data, columns=['A', 'B', 'C', 'D', 'E'])
# 使用seaborn的heatmap()函数创建热力图
plt.figure(figsize=(8, 6))
sns.heatmap(df, annot=True, cmap='coolwarm', linewidths=.5)
plt.title('热力图示例')
plt.show()

在上述示例中,我们首先创建了一个随机矩阵,并将其转换为Pandas DataFrame。然后,使用Seaborn的
heatmap()函数来绘制热力图。参数annot=True用于在图表上显示数值标签,cmap用于设置颜色映射,linewidths用于设置单元格之间的间隔线宽度。
2.10 绘制核密度估计图
plot.kde()函数:plot.kde()函数用于绘制核密度估计图,显示数据的概率密度分布。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #替换为系统中支持的字体
# 创建示例数据集
data = {'Values': [10, 15, 13, 18, 25, 12, 22, 27, 16, 21]}
df = pd.DataFrame(data)
# 使用plot.kde()函数创建核密度估计图
df['Values'].plot.kde()
plt.xlabel('数值')
plt.ylabel('概率密度')
plt.title('核密度估计图示例')
plt.show()
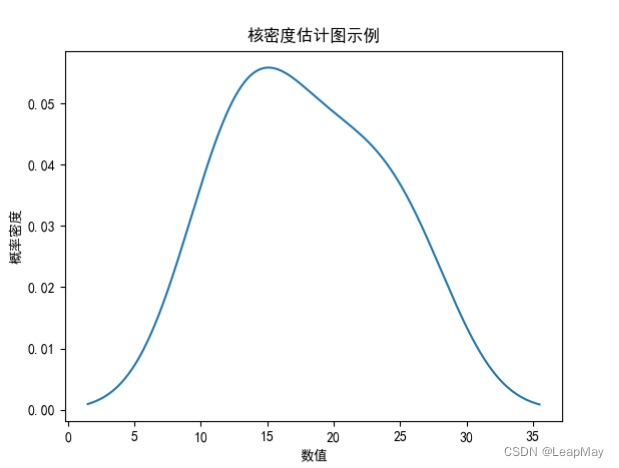
在这个示例中,我们首先创建了一个包含示例数据的DataFrame
df,然后使用plot.kde()函数绘制核密度估计图。这个图表显示了数据的概率密度分布,它是一个平滑的曲线,代表了数据在不同数值上的概率密度。