0. 环境
租用了1台GPU服务器,系统 ubuntu20,GeForce RTX 3090 24G。过程略。本人测试了ai-galaxy的,今天发现网友也有推荐autodl的。
(GPU服务器已经关闭,因此这些信息已经失效)
SSH地址:*
端口:16116
SSH账户:root
密码:*
内网: 3389 , 外网:16114
VNC地址: *
端口:16115
VNC用户名:root
密码:*
硬件需求,这是ChatGLM-6B的,应该和ChatGLM2-6B相当。
量化等级 最低 GPU 显存
FP16(无量化) 13 GB
INT8 10 GB
INT4 6 GB
1. 测试gpu
nvidia-smi
(base) root@ubuntuserver:~# nvidia-smi
Fri Sep 8 09:58:25 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.54 Driver Version: 510.54 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:00:07.0 Off | N/A |
| 38% 42C P0 62W / 250W | 0MiB / 11264MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
(base) root@ubuntuserver:~#
2. 下载仓库
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B服务器也无法下载,需要浏览器download as zip 通过winscp拷贝上去
3. 升级cuda
查看显卡驱动版本要求:
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
发现cuda 11.8需要 >=450.80.02。已经满足。
执行指令更新cuda
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sh cuda_11.8.0_520.61.05_linux.run
-> 输入 accept
-> 取消勾选 Driver
-> 点击 install
export PATH=$PATH:/usr/local/cuda-11.8/bin
nvcc --version4. 源码编译方式升级python3
4.1 openssl(Python3.10 requires a OpenSSL 1.1.1 or newer)
wget https://www.openssl.org/source/openssl-1.1.1s.tar.gz
tar -zxf openssl-1.1.1s.tar.gz && \
cd openssl-1.1.1s/ && \
./config -fPIC --prefix=/usr/include/openssl enable-shared && \
make -j8
make install4.2 获取源码
wget https://www.python.org/ftp/python/3.10.10/Python-3.10.10.tgz
or
wget https://registry.npmmirror.com/-/binary/python/3.10.10/Python-3.10.10.tgz4.3 安装编译python的依赖
apt update && \
apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev libsqlite3-dev wget libbz2-dev4.4 解压并配置
tar -xf Python-3.10.10.tgz && \
cd Python-3.10.10 && \
./configure --prefix=/usr/local/python310 --with-openssl-rpath=auto --with-openssl=/usr/include/openssl OPENSSL_LDFLAGS=-L/usr/include/openssl OPENSSL_LIBS=-l/usr/include/openssl/ssl OPENSSL_INCLUDES=-I/usr/include/openssl4.5 编译与安装
make -j8
make install4.6 建立软链接
ln -s /usr/local/python310/bin/python3.10 /usr/bin/python3.105. 再次操作ChatGLM2-6B
5.1 使用 pip 安装依赖
# 首先单独安装cuda版本的torch
python3.10 -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 再安装仓库依赖
python3.10 -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
python3.10 -m pip install -r requirements.txt
问题:网速慢,加上国内软件源
python3.10 -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
问题:ERROR: Could not find a version that satisfies the requirement streamlit>=1.24.0
ubuntu20内的python3.9太旧了,不兼容。
验证torch是否带有cuda
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)5.2 准备模型
# 这里将下载的模型文件放到了本地的 chatglm-6b 目录下
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git clone https://huggingface.co/THUDM/chatglm2-6b $PWD/chatglm2-6b还是网速太慢
另外一种办法:
mkdir -p THUDM/ && cd THUDM/
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b
下载ChatGLM2作者上传到清华网盘的模型文件
https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2Fchatglm2-6b&mode=list
并覆盖到THUDM/chatglm2-6b
先前以为用wget可以下载,结果下来的文件是一样大的,造成推理失败。
win10 逐一校验文件SHA256,需要和https://huggingface.co/THUDM/chatglm2-6b中Git LFS Details的匹配。
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00001-of-00007.bin SHA256
SHA256 的 pytorch_model-00001-of-00007.bin 哈希:
cdf1bf57d519abe11043e9121314e76bc0934993e649a9e438a4b0894f4e6ee8
CertUtil: -hashfile 命令成功完成。
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00002-of-00007.bin SHA256
SHA256 的 pytorch_model-00002-of-00007.bin 哈希:
1cd596bd15905248b20b755daf12a02a8fa963da09b59da7fdc896e17bfa518c
CertUtil: -hashfile 命令成功完成。
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00003-of-00007.bin SHA256
812edc55c969d2ef82dcda8c275e379ef689761b13860da8ea7c1f3a475975c8
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00004-of-00007.bin SHA256
555c17fac2d80e38ba332546dc759b6b7e07aee21e5d0d7826375b998e5aada3
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00005-of-00007.bin SHA256
cb85560ccfa77a9e4dd67a838c8d1eeb0071427fd8708e18be9c77224969ef48
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00006-of-00007.bin SHA256
09ebd811227d992350b92b2c3491f677ae1f3c586b38abe95784fd2f7d23d5f2
C:\Users\qjfen\Downloads\chatglm2-6b>certutil -hashfile pytorch_model-00007-of-00007.bin SHA256
316e007bc727f3cbba432d29e1d3e35ac8ef8eb52df4db9f0609d091a43c69cb这里需要推到服务器中。并在ubuntu下用sha256sum <filename> 校验下文件。
注意如果模型是坏的,会出现第一次推理要大概10分钟、而且提示idn越界什么的错误。
5.3 运行测试
切换回主目录
python3.10
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("chatglm2-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("chatglm2-6b", trust_remote_code=True, device='cuda')
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
5.4 gpu占用
(base) root@ubuntuserver:~/work/ChatGLM2-6B/chatglm2-6b# nvidia-smi
Mon Sep 11 07:12:21 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.54 Driver Version: 510.54 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:00:07.0 Off | N/A |
| 30% 41C P2 159W / 350W | 13151MiB / 24576MiB | 38% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 55025 C python3.10 13149MiB |
+-----------------------------------------------------------------------------+
(base) root@ubuntuserver:~/work/ChatGLM2-6B/chatglm2-6b#6. 测试官方提供的demo
6.1 cli demo
vim cli_demo.py
修改下模型路径为chatglm2-6b即可运行测试
用户:hello
ChatGLM:Hello! How can I assist you today?
用户:你好
ChatGLM:你好! How can I assist you today?
用户:请问怎么应对嵌入式工程师的中年危机
6.2 web_demo
修改模型路径
vim web_demo.py
把
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
修改为
tokenizer = AutoTokenizer.from_pretrained("chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm2-6b", trust_remote_code=True).cuda()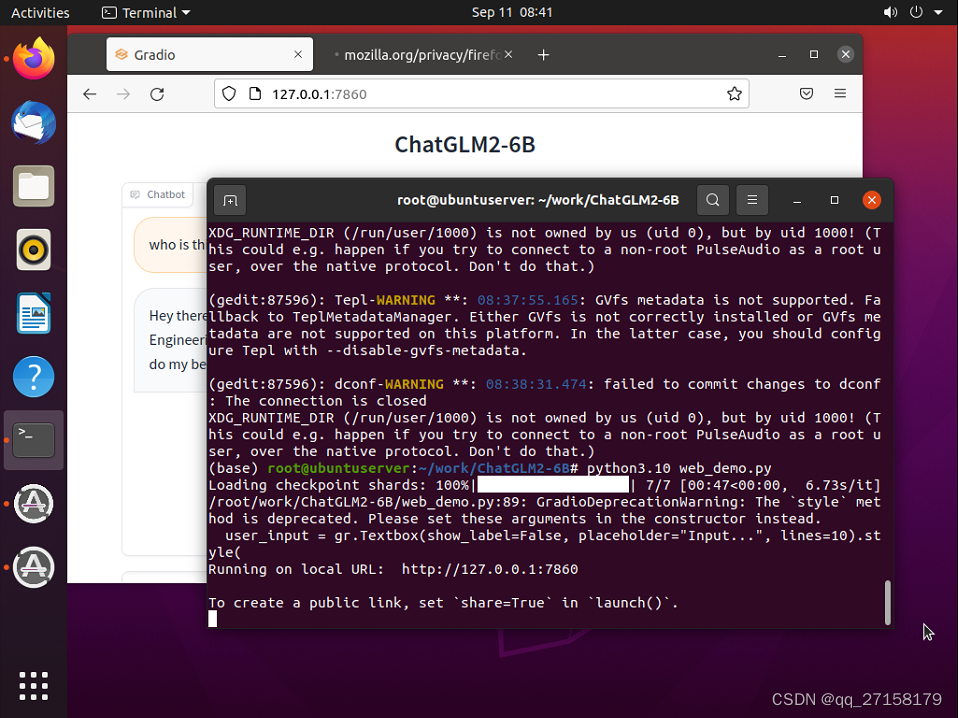

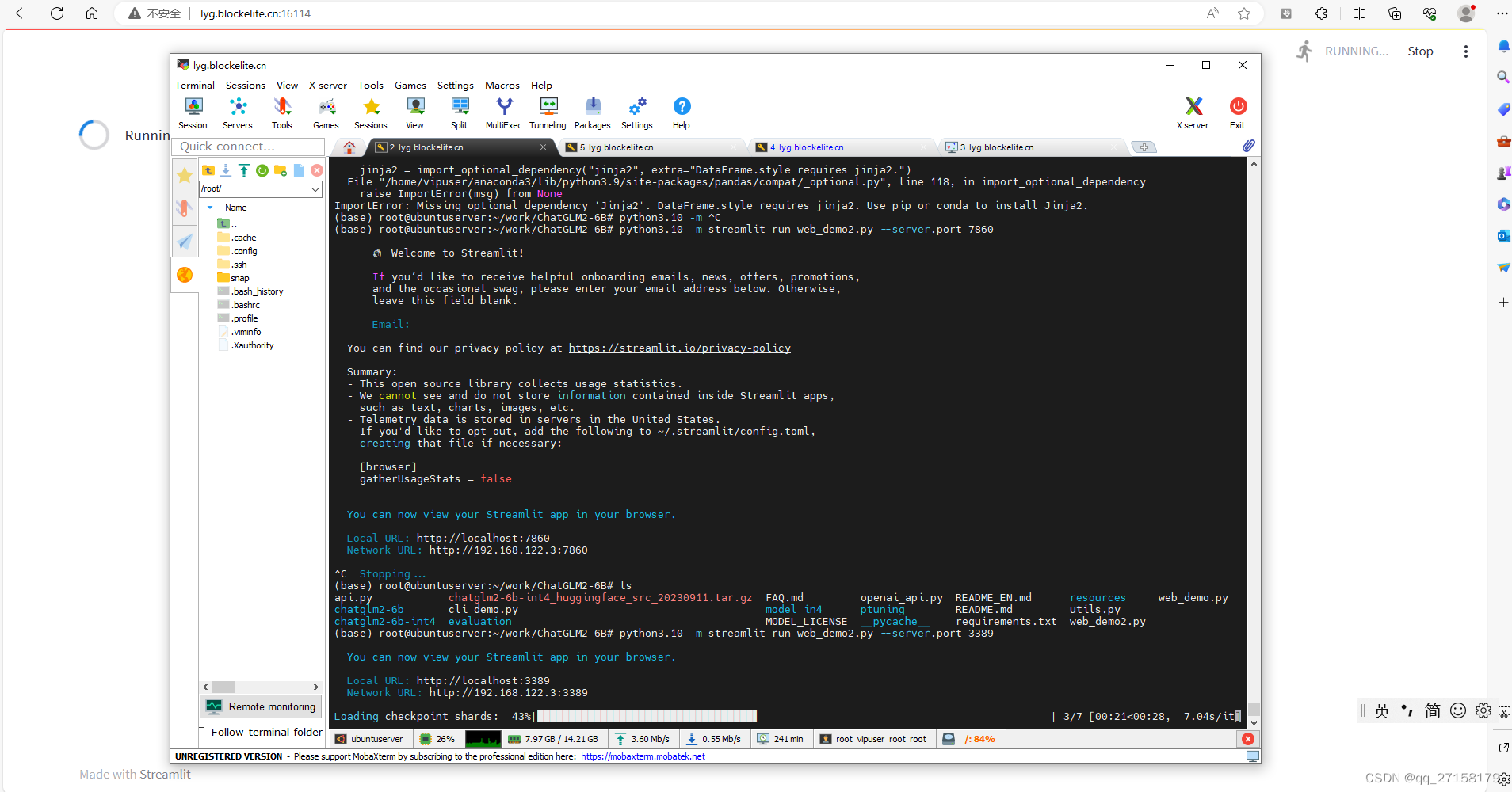
6.3 web_demo2
python3.10 -m pip install streamlit -i https://pypi.tuna.tsinghua.edu.cn/simple
python3.10 -m streamlit run web_demo2.py --server.port 3389
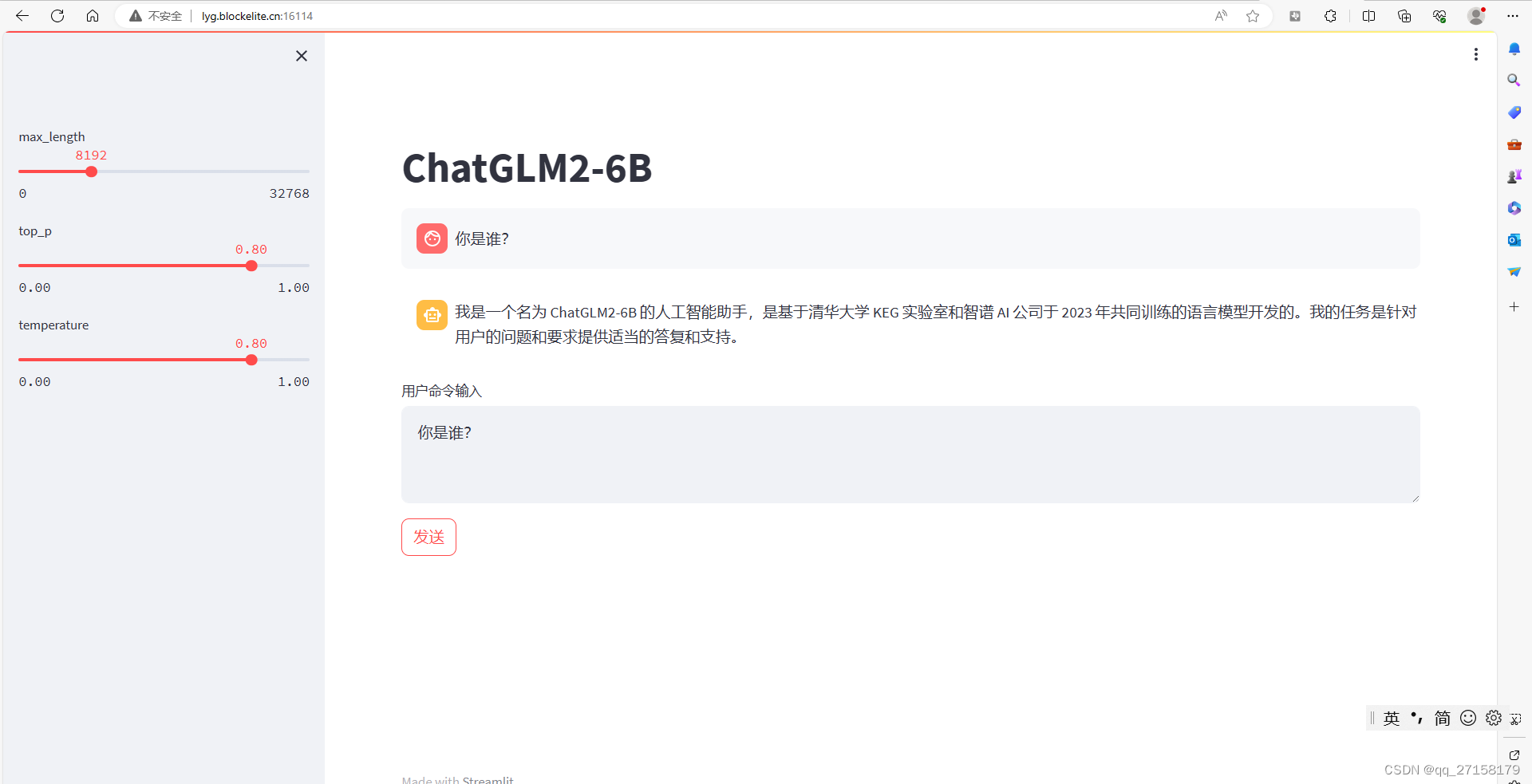
内网: 3389 , 外网:16114
本地浏览器打开:lyg.blockelite.cn:16114
6.4 api.py
把
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()
修改为
tokenizer = AutoTokenizer.from_pretrained("chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm2-6b", trust_remote_code=True).cuda()
另外,智星云服务器设置了端口映射,把port修改为3389,可以通过外网访问。
运行:
python3.10 api.py
客户端(智星云服务器):
curl -X POST "http://127.0.0.1:3389" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
客户端2(任意linux系统)
curl -X POST "http://lyg.blockelite.cn:16114" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
(base) root@ubuntuserver:~/work/ChatGLM2-6B# python3.10 api.py
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████| 7/7 [00:46<00:00, 6.60s/it]
INFO: Started server process [91663]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:3389 (Press CTRL+C to quit)
[2023-09-11 08:55:21] ", prompt:"你好", response:"'你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'"
INFO: 127.0.0.1:33514 - "POST / HTTP/1.1" 200 OK
[2023-09-11 08:55:34] ", prompt:"你好", response:"'你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。'"
INFO: 47.100.137.161:49200 - "POST / HTTP/1.1" 200 OK
^CINFO: Shutting down
INFO: Waiting for application shutdown.
INFO: Application shutdown complete.
INFO: Finished server process [91663]
(base) root@ubuntuserver:~/work/ChatGLM2-6B#7. 测试量化后的int4模型
7.1 准备模型以及配置文件
下载模型,这里有个秘诀,用浏览器点击 这个模型:models / chatglm2-6b-int4 / pytorch_model.bin
下载时候,可以复制路径,然后取消。到服务器中,wget https://cloud.tsinghua.edu.cn/seafhttp/files/7cf6ec60-15ea-4825-a242-1fe88af0f404/pytorch_model.bin
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b-int4下载ChatGLM2作者上传到清华网盘的模型文件
https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2Fchatglm2-6b-int4
并覆盖到chatglm2-6b-int4
tar -zcvf chatglm2-6b-int4_huggingface_src_20230911.tar.gz chatglm2-6b-int4 7.2 修改cli_demo.py
tokenizer = AutoTokenizer.from_pretrained("chatglm2-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm2-6b-int4", trust_remote_code=True).cuda()7.3 运行测试
python3.10 cli_demo.py
(base) root@ubuntuserver:~# nvidia-smi
Mon Sep 11 09:14:16 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.54 Driver Version: 510.54 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:00:07.0 Off | N/A |
| 30% 31C P8 25W / 350W | 5307MiB / 24576MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 98805 C python3.10 5305MiB |
+-----------------------------------------------------------------------------+
(base) root@ubuntuserver:~#8. 微调
这次微调,不能用python3.10了,脚本中是调用一些通过pip安装的软件如torchrun,用python3.10的pip安装的torch、streamlit未添加进系统运行环境,无法直接运行。
由于requirement.txt中的streamlit和python3.9有问题,因此注释掉streamlit即可。
8.1 安装依赖
pip install rouge_chinese nltk jieba datasets -i https://pypi.tuna.tsinghua.edu.cn/simple8.2 准备数据集
下载AdvertiseGen.tar.gz
https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
放到ptuning目录下
解压
tar -zvxf AdvertiseGen.tar.gz
8.3 训练
修改脚本中的模型路径:
把
--model_name_or_path THUDM/chatglm2-6b \
修改为
--model_name_or_path ../chatglm2-6b \
把
--max_steps 3000 \
改为
--max_steps 60 \
这样数分钟后即可完成训练。
把
--save_steps 1000 \
改为
--save_steps 60 \
训练:
bash train.sh微调时GPU利用情况:
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 109674 C ...user/anaconda3/bin/python 7631MiB |
+-----------------------------------------------------------------------------+
Mon Sep 11 09:48:55 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.54 Driver Version: 510.54 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:00:07.0 Off | N/A |
| 67% 60C P2 331W / 350W | 7633MiB / 24576MiB | 86% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 109674 C ...user/anaconda3/bin/python 7631MiB |
+-----------------------------------------------------------------------------+
8.4 训练完成
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 358.4221, 'train_samples_per_second': 2.678, 'train_steps_per_second': 0.167, 'train_loss': 4.090850830078125, 'epoch': 0.01}
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 60/60 [05:58<00:00, 5.97s/it]
***** train metrics *****
epoch = 0.01
train_loss = 4.0909
train_runtime = 0:05:58.42
train_samples = 114599
train_samples_per_second = 2.678
train_steps_per_second = 0.167
(base) root@ubuntuserver:~/work/ChatGLM2-6B/ptuning#查看模型文件:
这个多了个checkpoint-60文件夹,内面有模型文件
ChatGLM2-6B/ptuning/output/adgen-chatglm2-6b-pt-128-2e-2/checkpoint-60
8.5 推理
还是修改推理脚本中的模型位置
vim evaluate.sh
把
STEP=3000
修改为
STEP=60
把
--model_name_or_path THUDM/chatglm2-6b \
修改为
--model_name_or_path ../chatglm2-6b \
运行
bash evaluate.sh
修改web_demo.sh中的模型和checkpoint为
--model_name_or_path ../chatglm2-6b \
--ptuning_checkpoint output/adgen-chatglm2-6b-pt-128-2e-2/checkpoint-60 \
问题:解决ImportError: cannot import name ‘soft_unicode‘ from ‘markupsafe‘
python -m pip install markupsafe==2.0.1
参考
[1]https://github.com/THUDM/ChatGLM2-6B
[2]ChatGLM-6B (介绍以及本地部署),https://blog.csdn.net/qq128252/article/details/129625046
[3]ChatGLM2-6B|开源本地化语言模型,https://openai.wiki/chatglm2-6b.html
[3]免费部署一个开源大模型 MOSS,https://zhuanlan.zhihu.com/p/624490276
[4]LangChain + ChatGLM2-6B 搭建个人专属知识库,https://zhuanlan.zhihu.com/p/643531454
[5]https://pytorch.org/get-started/locally/