距离度量方法
- 一、欧式距离(Euclidean Distance)
- 二、余弦相似度(Cosine Similarity)
- 三、汉明距离(Hamming Distance)
- 四、曼哈顿距离(Manhattan Distance)
- 五、切比雪夫距离(Chebyshev Distance)
- 六、闵可夫斯基距离(Minkowski Distance)
- 七、Jaccard Index
- 八、Haversine Distance
- 九、Sørensen-Dice Index
- References
世界上最遥远的距离,不是生与死的距离,不是天各一方,而是,我就站在你的面前,你知道我爱你。 —— 木子李
学习数据科学中距离的度量方法,这里有一篇来自知乎的中文博文可以阅读,原文中有的内容就不赘述了,以下只是我对这些距离衡量方法的提炼、思考和理解。
距离本身的意思是,两个地点之间相距的距离,但被延申后距离应该指两个对象之间相异的程度(即有多大的不同或相同),差异不同于远近,因此我不认为计算机中的许多术语翻译成距离是合适的,距离一词容易让人联想到现实中的距离,差异比距离更合适,例如余弦距离,应该叫余弦差异,余弦相似度的翻译是取“差异”的反面。
一、欧式距离(Euclidean Distance)
D ( x , y ) = ∑ i = 1 n ( x i − y i ) 2 D(x,y) = \sqrt{\sum_{i=1}^{n}{(x_i - y_i)^2}} D(x,y)=i=1∑n(xi−yi)2
文章中说:“欧式距离不是尺度不变的,这意味着所计算的距离可能会根据特征的单位发生倾斜”,根据上述公式,即便是同样的距离如100cm和1m,单位为cm所计算出的数值会比单位m“大100倍,这就是根据特征的单位发生倾斜的含义的具体表现之一。
文中又说:“随着数据维数的增加,欧式距离的作用就越小。这与维数灾难(curse of dimensionality)有关。”,这里我貌似理解,但没有实际的例子可供举例。
二、余弦相似度(Cosine Similarity)
D ( x , y ) = c o s ( θ ) = x ⋅ y ∣ ∣ x ∣ ∣ ∣ ∣ y ∣ ∣ D(x,y) = cos(\theta) = \frac{x·y}{||x||||y||} D(x,y)=cos(θ)=∣∣x∣∣∣∣y∣∣x⋅y
当数据是高维,且向量的大小不重要时,使用余弦相似度。
三、汉明距离(Hamming Distance)
又叫海明距离,可用于计算机网络传输时的错误纠正/检测,此处需复习计算机网络。
四、曼哈顿距离(Manhattan Distance)
D ( x , y ) = ∑ i = 1 k ∣ x i − y i ∣ D(x,y) = \sum_{i=1}^{k}{|x_i - y_i|} D(x,y)=i=1∑k∣xi−yi∣
“当数据有离散或二进制属性时,此距离似乎很起效。”
五、切比雪夫距离(Chebyshev Distance)
切比雪夫距离定义为两个向量在任意坐标维度上的最大差值。但是它为什么又被称作棋盘距离?
国王可以上下左右斜着走,如果将国王所处位置视作原点,其向量是(0,0),而从该点出发到其它棋格的向量视作(x,y),套用刚刚的“两个向量在任意坐标维度上的最大差值”,则可以得到下面这张图,用来展示国王走到其它棋格的最小步数,来自百度百科。

实践中,切比雪夫距离经常用于仓库物流,道理也简单,机械臂可以同时沿着x轴与y轴移动。
六、闵可夫斯基距离(Minkowski Distance)
D ( x , y ) = ( ∑ i = 1 n ∣ x i − y i ∣ p ) 1 p D(x,y) = (\sum_{i=1}^{n}{|x_i - y_i|}^p)^{\frac{1}{p}} D(x,y)=(i=1∑n∣xi−yi∣p)p1
这么美的公式,会不会有什么直观的几何含义? 换言之,这公式可视化出来是什么样子?在维度是二维(对于上面这个公式就是
n
=
2
n=2
n=2)的前提下,图形长这个样子[4],蓝色线的含义是,蓝线上的点与原点
O
O
O之间的距离,套用上面的公式时,其计算值都一样,类似于等高线,最显眼的形状分别是
p
=
1
,
2
,
∞
p=1,2,\infty
p=1,2,∞ 。
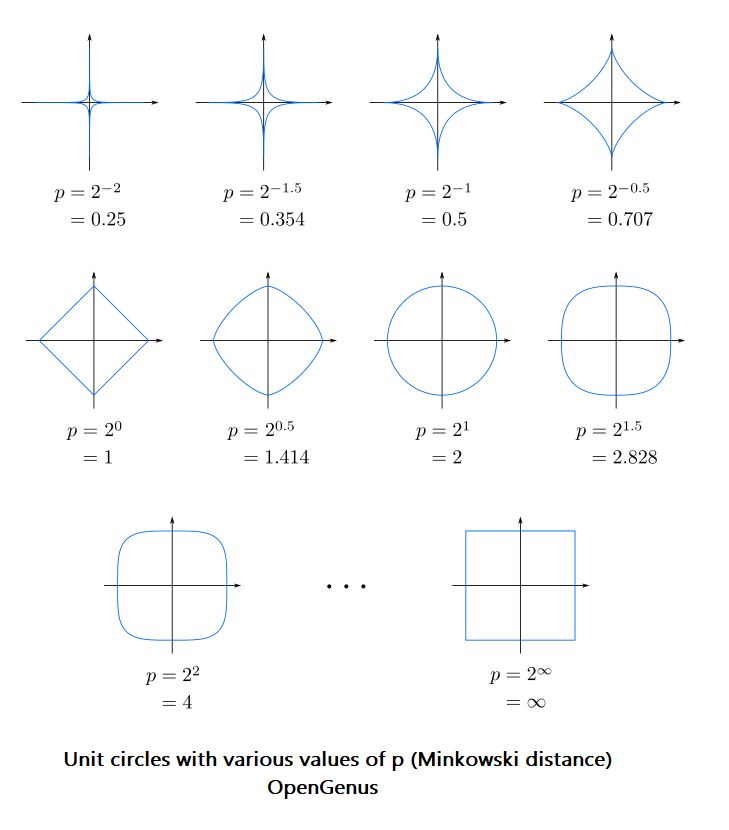
其中,有点意思的是
p
=
∞
p=\infty
p=∞的推导过程,我们只取两个点,一个点是
(
x
,
y
)
(x,y)
(x,y),一个点是
(
0
,
0
)
(0,0)
(0,0),维度
n
=
2
n = 2
n=2,由于计算时带了绝对值,所以只考虑第一象限
(
x
>
0
,
y
>
0
)
(x>0, y>0)
(x>0,y>0),其余象限可以用对称性推导出来。
D
=
lim
p
→
∞
[
(
x
−
0
)
p
+
(
y
−
0
)
p
]
1
p
=
lim
p
→
∞
(
x
p
+
y
p
)
1
p
=
y
=
a
x
lim
p
→
∞
[
x
p
+
(
a
x
)
p
]
1
p
=
lim
p
→
∞
[
(
1
+
a
p
)
x
p
]
1
p
=
lim
p
→
∞
(
1
+
a
p
)
1
p
x
(
a
>
0
)
D = \lim_{p \rightarrow \infty}[(x-0)^p + (y-0)^p]^{\frac{1}{p}} \\ =\lim_{p \rightarrow \infty}(x^p + y^p)^{\frac{1}{p}} \\ \overset{y=ax}= \lim_{p \rightarrow \infty}[x^p + (ax)^p]^{\frac{1}{p}} \\ = \lim_{p \rightarrow \infty}[(1 + a^p)x^p]^{\frac{1}{p}} \\ = \lim_{p \rightarrow \infty}(1 + a^p)^{\frac{1}{p}}x \space\space\space\space\space(a>0)
D=p→∞lim[(x−0)p+(y−0)p]p1=p→∞lim(xp+yp)p1=y=axp→∞lim[xp+(ax)p]p1=p→∞lim[(1+ap)xp]p1=p→∞lim(1+ap)p1x (a>0)
分类讨论:
(1)当 a = 1 a = 1 a=1时。 D = lim p → ∞ ( 2 x p ) 1 p = lim p → ∞ 2 1 p x = x D =\lim_{p \rightarrow \infty} (2x^p)^{\frac{1}{p}} = \lim_{p \rightarrow \infty} 2^{\frac{1}{p}}x = x D=limp→∞(2xp)p1=limp→∞2p1x=x,此时 y = a x = x y = ax = x y=ax=x。
符号
p
p
p 作为自由变量,大多数人的眼睛应该是看不习惯的,下面,回归到纯粹的高等数学习题上,将符号
p
p
p 替换成符号
x
x
x ,久违的高数习题的感觉扑面而来,请求以下式子的极限值
lim
x
→
∞
(
1
+
a
x
)
1
x
(
a
>
0
,
a
≠
1
)
\lim_{x \rightarrow \infty}(1 + a^x)^{\frac{1}{x}} \space\space\space\space\space(a>0, a\neq1)
x→∞lim(1+ax)x1 (a>0,a=1)
(2)当
a
<
1
a < 1
a<1时。令
a
x
=
u
a^x = u
ax=u,则
x
=
l
o
g
a
u
x = log_{a}{u}
x=logau,原式等价于求
lim
u
→
0
(
1
+
u
)
1
log
a
u
=
lim
u
→
0
(
1
+
u
)
l
n
a
l
n
u
=
lim
u
→
0
[
(
1
+
u
)
1
l
n
u
]
l
n
a
=
lim
u
→
0
[
e
l
n
(
1
+
u
)
1
l
n
u
]
l
n
a
=
lim
u
→
0
[
e
l
n
(
1
+
u
)
l
n
u
]
l
n
a
=
洛
lim
u
→
0
[
e
u
1
+
u
]
l
n
a
=
1
l
n
a
=
1
\lim_{u \rightarrow 0}(1 + u)^{\frac{1}{\log_{a}{u}}} \\ = \lim_{u \rightarrow 0}(1 + u)^{\frac{lna}{lnu}} \\ = \lim_{u \rightarrow 0} [(1 + u)^{\frac{1}{lnu}}]^{lna} \\ = \lim_{u \rightarrow 0} [e^{ln(1+u)^{\frac{1}{lnu}}}]^{lna} \\ = \lim_{u \rightarrow 0} [e^{ \frac{ln(1+u)}{lnu} }]^{lna} \\ \overset{洛}{=} \lim_{u \rightarrow 0} [e^{ \frac{u}{1+u} }]^{lna} \\ = 1^{lna} \\ = 1
u→0lim(1+u)logau1=u→0lim(1+u)lnulna=u→0lim[(1+u)lnu1]lna=u→0lim[eln(1+u)lnu1]lna=u→0lim[elnuln(1+u)]lna=洛u→0lim[e1+uu]lna=1lna=1
(3)当
a
>
1
a > 1
a>1时。沿用上面的式子
=
洛
lim
u
→
∞
[
e
u
1
+
u
]
l
n
a
=
e
l
n
a
=
a
\overset{洛}{=} \lim_{u \rightarrow \infty} [e^{ \frac{u}{1+u} }]^{lna} \\ = e^{lna} \\ = a
=洛u→∞lim[e1+uu]lna=elna=a
总结:
(1)当 a = 1 a = 1 a=1时。 D = ( 2 x p ) 1 p = 2 1 p x = x D = (2x^p)^{\frac{1}{p}} = 2^{\frac{1}{p}}x = x D=(2xp)p1=2p1x=x,此时 y = a x = x y = ax = x y=ax=x。
(2)当 a < 1 a < 1 a<1时, D = 1 ⋅ x = x D = 1·x = x D=1⋅x=x,此时 y = a x < x y = ax < x y=ax<x。
(3)当 a > 1 a > 1 a>1时。 D = a ⋅ x = y D = a·x = y D=a⋅x=y,此时 y = a x > x y = ax > x y=ax>x。
也就是说,取两个向量在任意坐标维度上的最大差值。这也就是切比雪夫距离,又叫棋盘距离。
闵可夫斯基这属于犯规了,一个公式可以根据不同的参数,把欧氏距离,曼哈顿距离(这词就他发明的),切比雪夫距离全部包括进去,生的晚还是有好处的。
七、Jaccard Index
D ( x , y ) = 1 − ∣ x ⋂ y ∣ ∣ x ⋃ y ∣ D(x,y) = 1 - \frac{|x \bigcap y|}{| x \bigcup y|} D(x,y)=1−∣x⋃y∣∣x⋂y∣
文中说:“Jaccard索引经常用于使用二进制或二进制化数据的应用程序中。当你有一个深度学习模型来预测一幅图像(例如一辆汽车)的片段时,Jaccard索引就可以用来计算给出真实标签的预测片段的准确性。同样,它也可以用于文本相似度分析,以衡量文档之间的选词重叠程度。因此,它可以用来比较模式集。”
八、Haversine Distance
d = 2 R ⋅ a r c s i n ( s i n 2 ( φ 2 − φ 1 2 ) + c o s ( φ 1 ) c o s ( φ 2 ) s i n 2 ( λ 2 − λ 1 2 ) ) d = 2R·arcsin \big(\space \sqrt{ sin^2{ (\frac{\varphi_2 - \varphi_1}{2}) } + cos(\varphi_1)cos(\varphi_2)sin^2{ (\frac{\lambda_2 - \lambda_1}{2}) } } \space \big) d=2R⋅arcsin( sin2(2φ2−φ1)+cos(φ1)cos(φ2)sin2(2λ2−λ1) )
哈弗辛距离是球面上的两点在给定经纬度条件下的距离,公式的证明见 Distance between the Points on the Earth’s Surface[5] 一文,链接置于文末。此处可以说一句,嗯,我爱数学。
九、Sørensen-Dice Index
D ( x , y ) = 2 ∣ x ∩ y ∣ ∣ x ∣ + ∣ y ∣ D(x,y) = \frac{2|x\cap y|}{|x|+|y|} D(x,y)=∣x∣+∣y∣2∣x∩y∣
“它衡量的是样本集的相似性和多样性,通常用于图像分割任务或文本相似度分析。”
References
[1] 一图看遍9种距离度量,图文并茂,详述应用场景!—— 知乎
[2] 9 Distance Measures in Data Science —— 原文
[3] [美]特南鲍姆(Tanenbaum, A.S.),[美]韦瑟罗尔(Wetherall, D.J.). 计算机网络(第5版)[M].严伟,潘爱民.北京:清华大学出版社,2012.
[4] Minkowski distance [Explained]
[5] Distance between the Points on the Earth’s Surface