前言:线程安全是整个多线程中,最为复杂的部分,也是最重要的部分。
目录
什么是线程安全问题?
线程不安全的原因
⁜⁜总结 :线程安全问题的原因 ⁜⁜
解决方法1 ——加锁 synchronized (监视器锁monitor lock)
synchronized 的 特性
—— 互斥
—— 可重入
死锁
可重入锁
死锁拓展
哲学家就餐问题
如何解决或者避免死锁?
死锁的的成因
解决死锁(重点⁜⁜)
—— 3. 请求保持
—— 4. 循环等待/环路等待
解决方法2 —— volatile 关键字
内存可见性
volatile
什么是线程安全问题?
有些代码,在单个线程中执行,完全正确,但如果同样的代码,让多个线程同时执行,就可能会出现bug。代码运行的结果不符合我们预期,
这种情况我们就称为 “线程安全问题” 或 “线程不安全”。
接下来我们结合具体的代码示例来理解一下 :
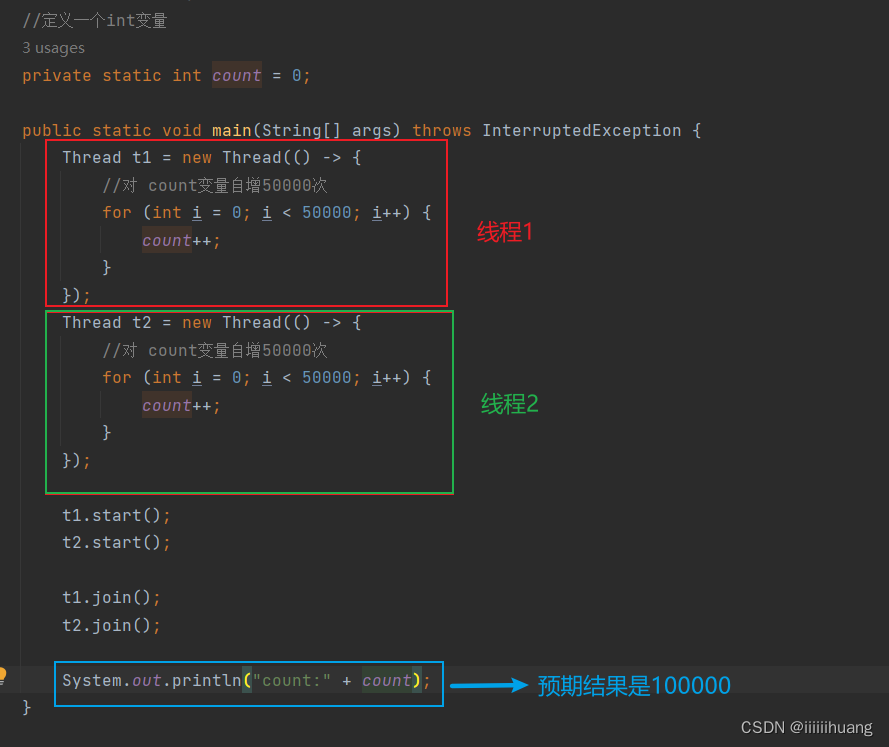
注意:这两个 join 必须得有,不然上面两个线程还没自增完,就开始打印了,count很有可能就打印个0
ps: join在之前的博客中有介绍,线程等待那部分,链接https://blog.csdn.net/iiiiiihuang/article/details/132587614?spm=1001.2014.3001.5501
那 我们来看看上述代码的执行结果是否是我们所预期的:

很明显,这不是我们预期的结果100000,那我们把这个代码再执行一遍,发现这个结果又变了


每次运行结果都不一样。
上述的情况就是典型的线程安全问题 。

这个代码 如果放在单个线程中执行,那一定是对的,但是当两个线程 并发执行了上述循环,此时逻辑就可能出现问题了
线程不安全的原因
----- 上述代码为什么会出现这样的情况呢 ?
因为两个线程 并发执行了。
当我们把join 的位置换一下

这意味着当 t1 正在运行的过程中,t2 是不会启动的,也就是说,虽然上述代码是写在两个线程中的,但是并不是 “同时” 执行的 。
此时结果就是预期的100000

---- 那为什么同时(并发)执行时就出问题了呢?
因为count++, 这个操作,本质上是分三步执行的,(站在CPU的角度上,count++ 是由CPU通过三个指令来实现的)
- 指令一: load 把数据从内存 读到 CPU寄存器中。
- 指令二: add 把寄存器中的数据进行 +1.
- 指令三: save 把寄存器中的数据,保存到内存中。
上述过程单个线程肯定是没什么问题,
但是多个线程就要出问题了,因为当多个线程执行上述代码时,由于线程之间的调度顺序时随机的,就会导致在有些调度顺序下,上述的逻辑会出现问题。
接下来我们画图看一下多个线程执行的情况。

还有其他情况



............
--- 上面已经有7种情况了,那这里到底有多少种情况呢?
无数种
因为也可能存在,t1 执行一次 count++ 的时候,t2执行了 2 次 ,3次 ......
结合了上述的讨论,我们意识到了,在多线程程序中,最困难的一点:线程的随机调度 ,
使两个线程执行逻辑的顺序有诸多可能(不一定都是对的)。我们必须保证在所有可能的情况下,代码都是正确的!
⁜⁜总结 :线程安全问题的原因 ⁜⁜
1.在操作系统中,线程的调度顺序是 随机的(抢占式执行)。【万恶之源】
2.两个线程,针对同一个变量进行修改。
3.修改操作,不是原子的。
(前面的 count++, 就属于是 非原子 的操作。(先读,再修改),类似的,如果一段逻辑 中,需要根据一定的条件来决定是否修改,也是存在类似的问题)
4.内存可见性问题。
5.指令重排序问题。
(4,5后面会介绍)
ps: 什么是原子性?
我们把一段代码想象成一个房间,每个线程就是要进入这个房间的人。如果没有任何机制保证,A进入房间之后,还没有出来;B 是不是也可以进入房间,打断 A 在房间里的隐私。这个就是不具备原子性的。
解决方法1 ——加锁 synchronized (监视器锁monitor lock)
前两个原因,我们一般很难调整
那我们就集中在第三条了,我们可以想办法让 count++ 成为原子的。------ 加锁!
--- 那如何给 Java 中的代码加锁呢?
就是使用 synchronized 关键字,接下来我们就来介绍 synchronized 关键字.
synchronized 的 特性
—— 互斥
synchronized 在使用时要搭配代码块{ }, 进入 代码块{ } 就会加锁 ,出了代码块{ } 就会解锁。
在已经加锁的状态中,另一个线程尝试同样加这个锁,就会产生 “锁冲突/锁竞争”,后一个线程就会堵塞等待,一直到前一个线程解锁为止。(本质上是把 “并发执行” 改为 “串行执行”)。
接下来我们具体写一下代码

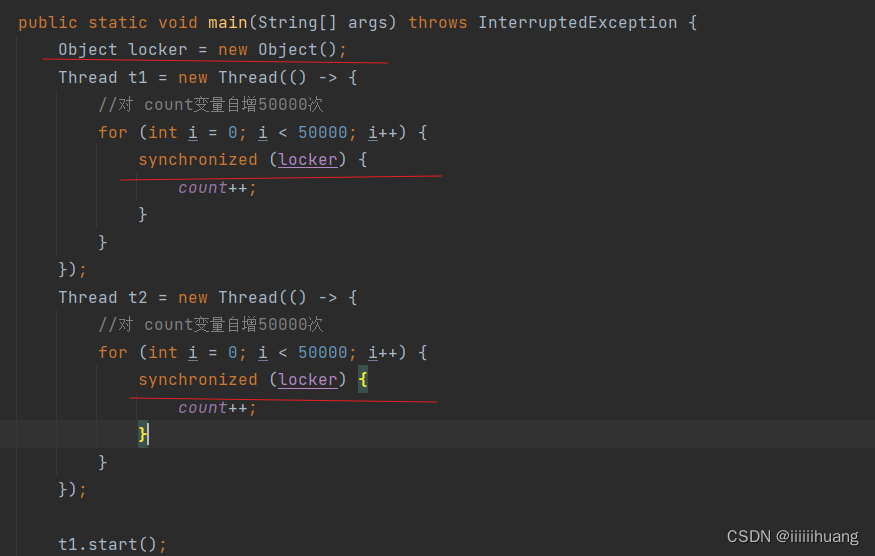
执行结果是100000 ,因为加锁的对象是同一个,此时就产生了 ”锁冲突“。

synchronized 除了修饰代码块之外,还可以修饰一个 实例方法,或者修饰一个 静态方法 。
----- 修饰一个 实例方法
我们把count 搞成一个方法 。


如果没有加什么锁,那结果仍然会出现线程安全问题

那我们现在就进行一个加锁的大动作:
直接在这个方法这加

这时候就是我们所期待的10000了。

这么看,synchronized 似乎没有 锁对象,其实是有的,此时就相当于 使用 this 作为 锁对象 。
这两种等价,可以认为 1 是 2 的简化版本。

----- 修饰一个 静态方法
如果修饰静态方法,相当于是针对 类对象 加锁。

这两个写法也是等价的 ,1 是 2 的简化版本。

但大家注意:我强调一下,这个锁对象是什么,不重要!!! 重要的是两个线程中 锁对象 是否是同一个对象。
synchronized 用的锁是存在 Java 对象头 里的。

Java 的一个对象,对应的内存空间中,除了我们自己定义的属性之外,还有一些自带的属性。
这些自带的属性就是 对象头。 在对象头中,就有属性表示当前对象 是否加锁。
—— 可重入
所谓的可重入锁,指的是,一个线程 连续针对一把锁 加锁两次,不会出现死锁。
满足这个要求,就是 “可重入”, 不满足这个要求,就是 “不可重入”。
我们上述内容中,涉及到了死锁,那我们接下来就来介绍一些什么是死锁:
死锁
类似下面的代码,针对同一个对象,连续加锁两次

假设 第一次 加锁成功,那 locker 就属于是 “被锁定” 的状态,
那接下来,进行第二次 加锁,问题来了,此时locker 已经是锁定状态了,原则上来说,第二次加锁操作,应该是要 “阻塞等待” 的。应该要等待到,第一次的锁被释放之后,第二次才能加成功。
但是实际上,第二次加锁阻塞等待,那第一次加锁 的代码块就走不完,锁就释放不了,那第二次加锁就加不上 ....... 无法进行了,这就死锁了(线程卡死了)。bug!!!
在日常开发中, 这种情况难以避免,当然不是像上边那样的啦~~~,举例:
可能一个加锁在func1里,一个在func4里,这些方法里,又存在调用关系 ,然后就死锁了

为了避免这种情况,我们就把 synchronized 设计成 “可重入锁” ,就能有效解决上述死锁问题了
可重入锁
就是让锁记录一下,是哪个线程把它锁住的,后续再加锁的时候,如果要加锁的线程已经是持有锁的线程了,那就直接加锁成功!!!
欸嘿:那在下面的代码中,如果 synchronized 是可重入锁,没有因为第二次加锁而死锁 ,但是当代码执行到 “ } ①”,此时,锁是否应该释放呢? 进一步来讲,如果上述加锁过程有N层,释放的时机该如何判定?

不行哦~~~ ,不能释放哦,你想如果 “ } ①” 和 “ }② ” 中间还有代码呢,是不是这里的代码就没办法受到锁的保护了,就可能会出现线程安全问题。所有不能在“ } ①”, 要在“ }② ”这释放。
所有假设有 N 层,我们应该要在最外层进行释放。
那如何知道多少层呢? ———— 这里我们就 引用计数 :
锁对象 中,不光要记录是谁拿了锁,还要记录,锁被加了几次,
每加锁一次,计数器就 +1,每解锁一次,计数器就 - 1,
出了最后一个大括号,恰好就减成 0 了,这时才真正释放锁。
死锁拓展
1.一个线程,针对一把锁,连续加锁两次,如果是不可重入锁,就死锁了。 (我们Java这边的synchronized 不会出现不可重入锁,但是C++ 的 std::mutex 就是不可重入锁,就会出现死锁。)
2.两个线程 两把锁,此时无论是不是可重入锁,都会死锁。
—— 2 是什么意思呢?
就假如现在有 线程t1 和 线程t2,还有两把锁 A,B
现在t1 获取锁A,t2 获取锁B,然后t1 尝试获取锁B,t2 尝试获取锁A, 这时候也死锁了
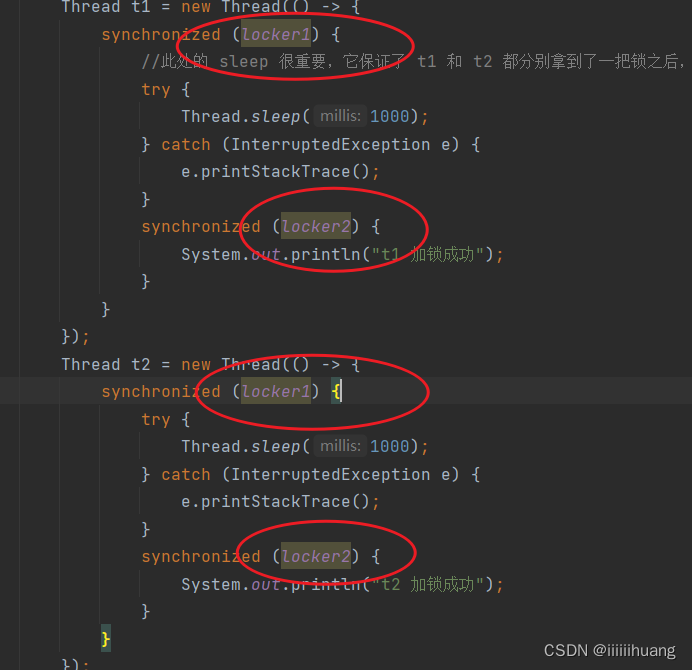
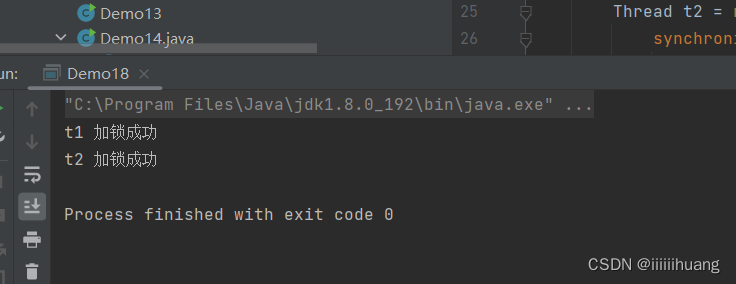
我们用代码来演示一下 两把锁死锁情况:
此处的 sleep 很重要,它保证了 t1 和 t2 都分别拿到了一把锁之后,再进行后续动作
package thread;
/**
* @Author: iiiiiihuang
*/
public class Demo18 {
//两把锁
private static Object locker1 = new Object();
private static Object locker2 = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
synchronized (locker1) {
//此处的 sleep 很重要,它保证了 t1 和 t2 都分别拿到了一把锁之后,再进行后续动作
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker2) {
System.out.println("t1 加锁成功");
}
}
});
Thread t2 = new Thread(() -> {
synchronized (locker2) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (locker1) {
System.out.println("t2 加锁成功");
}
}
});
t1.start();
t2.start();
}
}我们运行看一下,啥也没有,死锁了


我们可以借助 jconsole 来看看两个线程的状态:

这个Thread-0 和 Thread-1 就是刚才两个线程

我们看看Thread-0线程具体的 状态和调用栈,可以看到这个线程是 BLOCKED 状态(因为锁竞争导致的阻塞),这个要等待(竞争)的锁是 Thread-1 持有的
我们再看看Thread-1线程

BLOCKED 状态,这个要等待(竞争)的锁是 Thread-0 持有的
大家注意,上面的死锁代码,两个 synchronized 是嵌套关系,不是并列关系,
嵌套关系说明,是在占用一把锁的前提下,获取另一把锁(则是可能出现死锁),
并列关系,则是先释放前面的锁,再获取下一把锁(不会死锁)。
N个线程,M把锁 ,此时更容易出现死锁。
这里有个经典描述 N个线程,M把锁 的死锁的模型———— 哲学家就餐问题
哲学家就餐问题
一个桌子上有一碗面,桌子周围 坐这 5个哲学家, 每两个哲学家 中间放一根筷子(共五根)

规则(哲学家):(1)思考人生,放下筷子,啥都不干
(2)吃面条, 拿起左右两边的筷子,开始吃面条
(3)哲学家啥时候吃面条,啥时候思考人生,是随机的
(4)哲学家正在吃面条的过程中,会持有左右两侧的筷子,此时相邻的哲学家 如果也想吃面条,就需要阻塞等待
(哲学家就 等于 线程 , 筷子就等于锁)
基于上述规则,通常情况下,整个系统,可以良好运转,但是极端情况下,就会出问题,
比如,同一时刻,五个哲学家都想吃面条,同时拿起了左手的筷子 ,此时,五个哲学家发现,他们的右手都没有筷子,于是他们就都得阻塞等待,等待过程中,他们都不会放下左手筷子,
那就谁都吃不了了,就进入死锁状态。
死锁,是属于严重的Bug,那如何解决或者避免死锁呢?
如何解决或者避免死锁?
死锁的的成因
首先我们要了解死锁的的成因,这里涉及四个 必要条件 (数学里的必要条件)
- 互斥使用(上面讲到了,这里再说一遍):锁的基本特性,当一个线程持有一把锁之后,另一个线程也想获取到同一把锁,就要阻塞等待。
- 不可抢占:锁的基本特性,当锁已经被线程1拿到之后,线程2 只能等线程1 主动释放,不能强行抢过来。
- 请求保持:代码结构,一个线程尝试获取多把锁,(先拿到锁1 之后,再尝试获取锁2,获取的时候,锁1 不会释放(吃着碗里的,看着锅里的))。
- 循环等待/环路等待:等待的依赖关系,形成环了,就像上面介绍的哲学家就餐极端情况
要想出现死锁,得把上面的4条全都占了,
所有解决死锁,核心就是破坏上诉必要条件,只要破坏一个,死锁就形成不了。
解决死锁(重点⁜⁜)
—— 3. 请求保持
1和2,无法破坏,对于 3 ,只需要调整代码结构,避免编写 “锁嵌套” 逻辑。

比如说我们把上面的代码变一下 ,把嵌套变为并列关系。

执行:

加锁成功了 。
但是这个不一定好使,因为有时候,可能就需要进行“锁嵌套”的操作(获取多个锁),所有我们看看 4.
—— 4. 循环等待/环路等待
对于4来说,可以约定加锁的顺序,就可以避免循环等待。
比如,针对锁,进行编号,约定 加多把锁的时候,先加编号小的锁,后加编号大的锁。(所有的线程都要遵守这个规则)
我们还拿哲学家就餐问题来看 :
1.先给筷子(锁)编号
2.约定,每个滑稽都是先拿起编号小的筷子,后拿起编号大的筷子。


有一个哲学家,没有拿 5 号筷子 ,而是拿到 1 号筷子,(因为这个哲学家两边是 1 和 5,1 < 5, 所以他拿1 筷子,)但是1 被占了,那这个哲学家就得阻塞等待一下,这就给拿 4 号筷子的哲学家一个机会,拿起 5 号筷子,这样他就可以吃面了,他吃完了,就可以放下 4,5号筷子,那拿 3号筷子的人就可以拿起 4号了,以此类推 。此时循环等待就破除了,这不就不死锁。
代码演示 (从锁编号小的开始)
加锁成功了
上面加锁方法是解决 原因 3:原子问题,那 4 和 5 该如果解决,这就需要volatile 关键字了
解决方法2 —— volatile 关键字
1.保证内存可见性
2.禁止指令重排序
内存可见性
计算机运行的程序/代码,经常要访问一些数据,这些数据,往往还存储再 内存中 ,比如我们定义一个变量,变量就是在内存中的,
当CPU使用这个变量时,就会把这个内存中的数据,先读出来,放到CPU的寄存器中,之后再参与运算(这个就是上面的load操作)。
那此时问题就来了,CPU读取内存的操作,其实非常慢(相对来说 读取速度:寄存器 > 内存 > 硬盘)
CPU在进行大部分操作时都很快,但是操作到读/写 内存时,速度就慢下来了。
这时候,编译器为了解决上述问题,提高效率,就可能对代码做出优化,把一些本来要读内存的操作,优化成读取 寄存器,减少读内存的次数,也就可以提高整体程序的效率了。(⁜⁜)
这个就是内存可见性的基本情况。
接下来我们用代码演示一下, 内存可见性引发的线程安全问题:

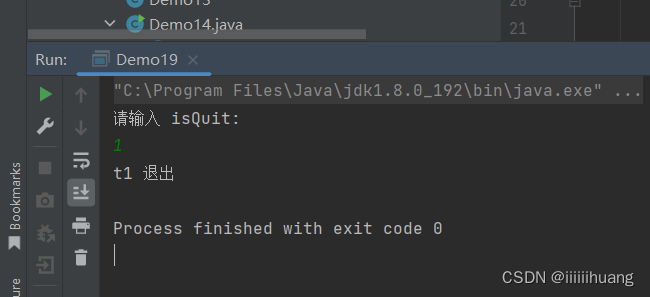
我们现在运行一下程序,预期结果:用户输入 非0值后,t1线程 退出
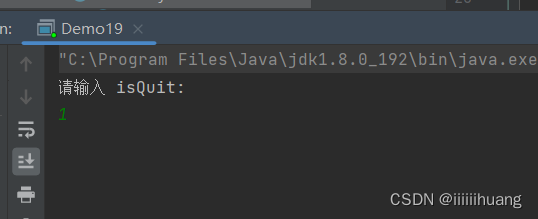
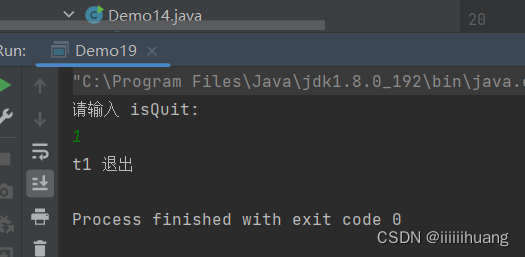
但当我们输入 1 时(非0),t1线程并没有结束退出 ,我们通过jconsole 也能看到,t1线程正在执行(RUNNABLE)

这与预期的不一样,是个bug,且这个bug 是由 多线程引起的,这也是线程安全问题。
我们发现这个问题和之前的count++ 那里还不一样,之前是两个线程,同时修改同一个变量(count) 出了问题,现在是一个线程读(t1),一个线程修改(t2),也可能出现问题。
这样的问题就是由于 内存可见性 引起的
我们来解释一下:

但是 这个循环里面啥都没有,导致循环速度飞快,短时间内,就会进行大量的循环,也就是进行大量的load 和 cmp 操作,
此时,编译器就发现了,虽然进行了这么多次 load,但是load 出来的结果都一样,这个isQuit就一直没变过,(load操作有非常费时间,一次load相当于上万次 cmp 了)
所有,我们编译器就决定,只是第一次循环的时候,才读了内存,后续都不会再读内存了,而是直接从寄存器中,取出isQuit 的值,

这就是编译器优化。编译器是希望能够提高程序的效率,但是提高效率的前提是保证逻辑不变,此时由于修改isQuit 的代码是另一个线程的操作,编译器没有正确的判定,上述可知,编译器以为没人修改isQuit, 就做出了这样的优化,就引起了bug
所以,之后t2修改了isQuit ,但是t1 感知不到内存的变化,
这个问题我们就称为“内存可见性问题”
volatile就是解决方案
volatile
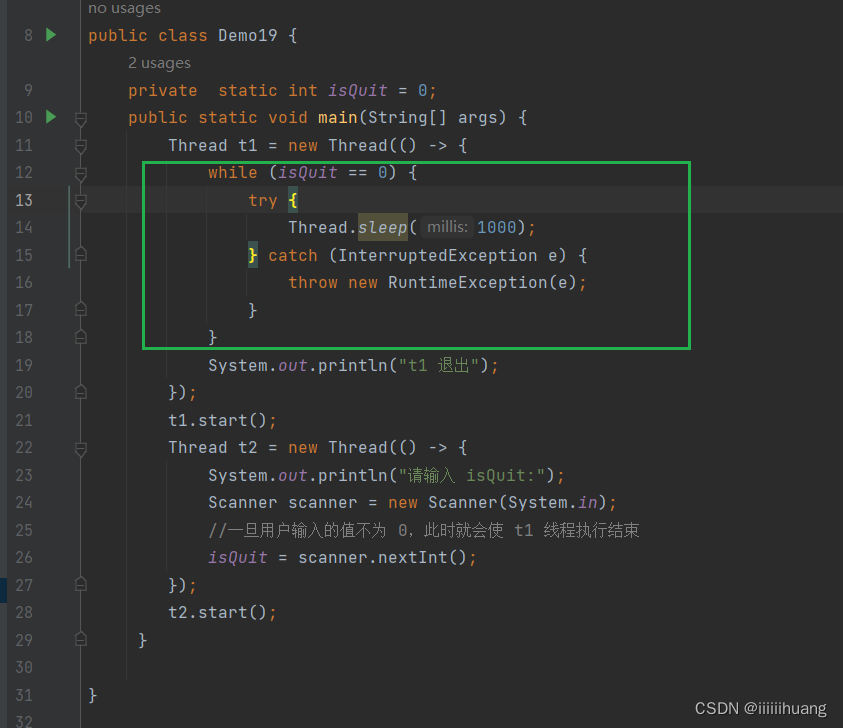
在多线程环境下,编译器对于是否要进行这样的优化,判定不一定准,这就需要程序员通过 volatile 关键字,来告诉编译器,这里不要优化!
上述的问题,我们只需要给isQuit 加上volatile 修饰,编译器就会禁止上述优化了

运行成功
但是如果你在循环里加一个 sleep,不加volatile,t1线程也可以顺利退出,因为加了sleep的循环速度慢了,次数就少了,load操作开销就不大了,因此,优化就没必要进行了,不触发load 的优化,也就没有 触发 内存可见性问题。
但是吧,到底啥时候代码优化了,啥时候又没优化,又说不清,所有使用volatile 是更好的选择。
总结:
volatile 修饰的变量, 能够保证 "内存可见性"
(保证读内存次数不被操作系统优化掉,多看到内存,内存可见性)
volatile 和 synchronized 都能对线程安全起到一定的积极作用,但是,volatile 是不能保证原子性的
拓展 :
关于内存可见性,还涉及到了一个关键概念 —— JMM(Java Memory Model,Java内存模型),这个是Java 规范文档上的叫法,它把我们的 存储空间 划分为了 主内存 和 工作内存。
t1 线程,对应的 isQuit 变量,本身是在主内存中的,由于此处的优化,就会把isQuit 变量放到工作内存中,进一步的导致 t2线程 修改主内存的 isQuit,不会影响到 t1线程的工作内存。
上面的话,和我们之前说的 逻辑是一样的,只是换了名称(翻译的问题) :
主内存(main memory) —— 我们说的内存
工作内存 (work memory) —— cpu 寄存器
关注,点赞,评论,收藏 ,支持一下 ╰(*°▽°*)╯╰(*°▽°*)╯╰(*°▽°*)╯