文章目录
- 前言
- 抽选规则
- 实现思路
- 代码实现
- 1.获取评论数据
- 2.过滤符合抽选规则的评论者
- 3.获取粉丝数据
- 4.过滤符合抽选规则的粉丝
- 5.增加公众号留言权重
- 6.抽选粉丝
- 完整的代码
- 效果展示
- 结语
前言
为了回馈粉丝们一直以来的的关注和支持,我近期开启了赠书活动,活动期间会在每一期的文章评论中随机抽选几位粉丝赠送本期书籍。为了确保绝对的公平,我借鉴了@东离与糖宝的想法,编写了一个评论区抽选粉丝程序。秉行公平、公正、公开原则,本文会将抽选粉丝程序的思路以及代码的实现展示给大家。
抽选规则
抽选评论区中的粉丝要符合以下条件:
- 关注了我的博客,即成为我的粉丝。
- 评论一次权重+1,最多3次,评论内容见当期参与方式。
同时,关注公众号并留言权重+3,留言内容见当期参与方式。
活动见赠书专栏
实现思路
- 首先需要获取该博客文章的所有评论者。
- 筛选符合条件的评论者。
- 是否为我的粉丝。
- 是否评论当期要求内容(可选)。
- 对于既是当期内容评论者又是公众号的粉丝,给予更高的权重值。
- 在符合条件的粉丝中随机抽选幸运读者。
代码实现
1.获取评论数据
虽然CSDN不提供直接获取文章评论者的接口,但这难不倒一个开发人员。我们可以在文章所在页面开启调试模式拿到这个接口:https://blog.csdn.net/phoenix/web/v1/comment/list/132678231?page=1&size=20,参数清晰明了,响应格式如下:
{
"code":200,
"message":"success",
"traceId":"b3e6eb62-396d-4289-a937-710767e68680",
"data":{
"count":86,
"pageCount":83,
"floorCount":83,
"foldCount":1,
"list":[
{
"info":{
"commentId":28613264,
"articleId":132678231,
"parentId":0,
"postTime":"2023-09-09 16:16:10",
"content":"这里是评论内容",
"userName":"qq_28314431",
"digg":0,
"diggArr":[
],
"loginUserDigg":false,
"parentUserName":"qq_28314431",
"parentNickName":"叫我二蛋",
"avatar":"https://profile-avatar.csdnimg.cn/55e249ffc0b54ab287ecde8615968cca_qq_28314431.jpg!1",
"nickName":"这里是用户昵称",
"dateFormat":"前天 16:16",
"years":8,
"vip":true,
"vipIcon":"https://img-home.csdnimg.cn/images/20210121052537.png",
"vipUrl":"https://mall.csdn.net/vip",
"companyBlog":false,
"companyBlogIcon":"",
"flag":false,
"flagIcon":"",
"levelIcon":"https://csdnimg.cn/identity/blog6.png",
"commentFromTypeResult":{
"index":1,
"key":"pc",
"title":"PC"
},
"isTop":true,
"isBlack":false,
"region":"IP:陕西省",
"orderNo":"",
"redEnvelopeInfo":null
},
"sub":[
],
"pointCommentId":null
}
]
}
}
这里基于Python直接发起POST请求获取评论数据,代码如下:
import requests
commentUrl = "https://blog.csdn.net/phoenix/web/v1/comment/list/132678231?page=1&size=20"
# 发送Post请求
headers = {"User-Agent": ""}
response = requests.get(commentUrl,headers=headers)
# 如果请求成功,接收的响应会是一个Response对象
if response.status_code == 200:
# 使用json()方法将响应内容解析为JSON
data = response.json()
print(data)
else:
print("请求失败,状态码:", response.status_code)
2.过滤符合抽选规则的评论者
获取的评论数据中我们只需要评论内容和评论者昵称这两个数据,及字段content、nickName,接下来就可以根据条件筛选评论者,并且评论一次权重+1,代码如下:
commentList = data["data"]["list"]
commentUsers={}
for item in commentList:
nickName = item["info"]["nickName"]
content = item["info"]["content"]
if needcomment in content:
commentCount=commentUsers.get(nickName)
if commentCount is None:
commentUsers[nickName]=1;
else:
commentUsers[nickName]=commentCount+1;
commentUsers最终会输出一个字典类型,key为昵称,value为权重值,格式如:{'EmotionFlying': 1, '小 王': 1}。
符合条件的评论者筛选出来后要确定是否为我的粉丝,不是的话将其从commentUsers移除。
3.获取粉丝数据
同样,还是在页面中拿到“我的粉丝”接口:https://mp-action.csdn.net/interact/wrapper/pc/fans/v1/api/getFansOffsetList?pageSize=500&username=qq_28314431&fanId=,该接口中的fanId可以理解为‘page’页码,每次请求成功后会返回下一个fanId。获取粉丝数据代码如下:
import requests
fanUrl = "https://mp-action.csdn.net/interact/wrapper/pc/fans/v1/api/getFansOffsetList?pageSize=500&username=qq_28314431&fanId="
# 发送Post请求
headers = {"User-Agent": ""}
response = requests.get(fanUrl,headers=headers)
# 如果请求成功,接收的响应会是一个Response对象
if response.status_code == 200:
# 使用json()方法将响应内容解析为JSON
data = response.json()
print(data)
else:
print("请求失败,状态码:", response.status_code)
4.过滤符合抽选规则的粉丝
在获取到粉丝后,将commentUsers中不在粉丝列表的数据移除就好,代码如下:
fansNickname = list(set([d['nickname'] for d in fansList]) & set(list(commentUsers.keys())))
fans = {nickname: commentUsers.pop(nickname) for nickname in fansNickname}
fans 就是符合抽选规则的粉丝。
5.增加公众号留言权重
对于公众号留言的粉丝,需要手动将他们的昵称作为一个参数传入程序中,直接遍历fans,增加其权重,代码如下
gzhfans=["粉丝1","粉丝2"]
gzhfans = [fan for fan in gzhfans if fan in fans and isinstance(fans[fan], int)]
fans = fans | {fan: fans[fan] + 3 for fan in gzhfans}
fans 就是最终抽选粉丝的集合数据。
6.抽选粉丝
最后,就可以基于fans随机抽选粉丝了,这里用python 自带的random.choices随机方法,代码如下:
random.choices(list(fans.keys()), weights=list(fans.values()))[0]
完整的代码
由于接口中存在分页问题,同时为了提高代码的可读性和可用性,我对剩余的代码进行了完善,以下是完善后的代码:
import sys
import random
import requests
'''
介绍
- 该脚本用来随机抽选评论区粉丝
使用方法:
- python3 selectFans.py
- blogID: 博客ID
- bloggerID: 博主ID
- selectCount:抽选粉丝个数
- needcomment: 符合的评论内容
- gzhfans: 公众号留言的粉丝,添加权重
依赖:
- python3
- random
- requests
'''
# 评论数据接口
commentUrlT = "https://blog.csdn.net/phoenix/web/v1/comment/list/{}?page={}&size={}"
# 每次获取接口数据的数量,csdn的上限
pageSize = 500
# 粉丝数据接口
fansUrlT = "https://mp-action.csdn.net/interact/wrapper/pc/fans/v1/api/getFansOffsetList?pageSize={}&username={}&fanId={}"
# 抽选粉丝
def select_fans():
try:
fans = satisfied_fans()
assert fans, "没有符合抽选规则的粉丝"
add_weight(fans, gzhfans);
print("——————开始抽选粉丝——————")
for i in range(1, selectCount + 1):
luckfans = weighted_random_choice(list(fans.keys()), list(fans.values()))
# 移除该粉丝
fans.pop(luckfans)
print("恭喜第{}为幸运粉丝:{}".format(i, luckfans))
except Exception as e:
print(e)
# 添加公众号留言粉丝的权重
def add_weight(fans, gzhfans):
print("——————添加公众号留言粉丝的权重——————")
if gzhfans:
gzhfans = [fan for fan in gzhfans if fan in fans and isinstance(fans[fan], int)]
fans = fans | {fan: fans[fan] + 3 for fan in gzhfans}
print("权重增加后的粉丝:{}".format(fans))
else:
print("没有公众号留言的粉丝")
# 符合抽选规则的粉丝
def satisfied_fans():
satisfiedFans = {}
commentUsers = get_comment_users()
assert commentUsers, "没有符合条件的评论者"
fanId = ""
one = True;
# 如果是第一次或者 fanId 有值 ,并且评论者未被移除完,继续筛选。
while one or (fanId is not None and commentUsers):
one = False
fanId, fans = get_satisfied_fans(commentUsers, fanId)
satisfiedFans = satisfiedFans | fans
print("符合抽选规则的粉丝:{}".format(satisfiedFans))
return satisfiedFans
# 获取符合抽选规则的粉丝
def get_satisfied_fans(commentUsers, fanId):
fanId, fansList = get_fans(fanId)
# 在粉丝列表中的评论者
fansNickname = list(set([d['nickname'] for d in fansList]) & set(list(commentUsers.keys())))
# 移除并返回commentUsers的粉丝
return fanId, {nickname: commentUsers.pop(nickname) for nickname in fansNickname}
# 获取符合条件的评论者
def get_comment_users():
commentUsers = {}
for item in get_comments():
# 解析评论者ID
userName = item["info"]["userName"]
if userName == bloggerID:
continue
# 解析评论者
nickName = item["info"]["nickName"]
# 解析评论内容
content = item["info"]["content"]
# 判断评论内容是否符合要求
if len(needcomment) == 0 or needcomment in content:
commentCount = commentUsers.get(nickName)
# 组装评论者及其权重
if commentCount is None:
commentUsers[nickName] = 1
else:
if commentUsers[nickName] < 3:
commentUsers[nickName] = commentCount + 1
print("符合条件的评论者{}".format(commentUsers))
return commentUsers
# 获取到所有的评论
def get_comments():
commentUrl = commentUrlT.format(1, pageSize)
data = request(commentUrl)
# 解析到总页数
total_pages = data["data"]["pageCount"]
# 解析到评论数据
commentList = data["data"]["list"]
assert len(commentList) > 0, "该博客没有评论数据"
for page in range(2, total_pages + 1):
commentUrl = commentUrlT.format(page, pageSize)
_data = request(commentUrl)
_commentList = _data["data"]["list"]
# 将所有评论数据合并
commentList = commentList + _commentList
return commentList
# 获取到所有的粉丝
def get_fans(fanId):
fansUrl = fansUrlT.format(fanId)
data = request(fansUrl)
# 解析到下一fanId
fanId = data["data"]["fanId"]
# 解析到粉丝数据
fansList = data["data"]["list"]
return fanId, fansList
# 调用接口获取数据
def request(url):
headers = {"User-Agent": ""}
response = requests.get(url, headers=headers)
# 如果请求成功,接收的响应会是一个Response对象
if response.status_code == 200:
# 使用json()方法将响应内容解析为JSON
return response.json()
else:
print("请求失败,状态码:", response.status_code)
def weighted_random_choice(choices, weights):
return random.choices(choices, weights=weights)[0]
if __name__ == '__main__':
# 博客ID
blogID = input("博客ID:")
# 博主ID
bloggerID = input("博主ID:")
# 抽选粉丝个数
selectCount = int(input("抽选粉丝个数:"))
# 符合的评论内容
needcomment = input("符合的评论内容(不填写则不对评论内容有要求):")
# 公众号留言的粉丝
gzhfans = input("公众号留言的粉丝,可以为空,以','分隔:").split()
# 评论数据接口
commentUrlT = commentUrlT.format(blogID, "{}", "{}")
# 粉丝数据接口
fansUrlT = fansUrlT.format(
pageSize, bloggerID, "{}")
select_fans()
效果展示
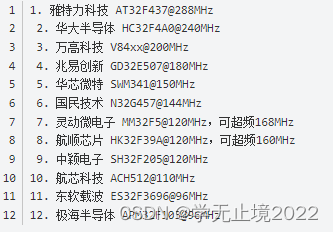
执行代码中的使用示例后结果如下图,如果粉丝过于多,可能需要等待数秒,因为粉丝接口一次最多只能读500条,希望官方看到后可以为我们开个口子😁。

结语
为了方便大家的使用,我已将程序打包成可执行文件,支持Windows和Mac系统,需要的可以联系博主获取。