前言
在进行爬虫程序开发和运行时,常常会遇到目标网站的反爬虫机制,最常见的就是IP封禁,这时需要使用IP隐藏技术和代理爬取。

一、IP隐藏技术
IP隐藏技术,即伪装IP地址,使得爬虫请求的IP地址不被目标网站识别为爬虫。通过IP隐藏技术,可以有效地绕过目标网站对于特定IP地址的限制。
1. 随机User-Agent
User-Agent是指客户端程序请求时发送给服务器的字符串信息,通常包含当前客户端的软件版本、操作系统、语言环境和服务商等信息。在进行爬虫开发时,如果使用的User-Agent与浏览器不同,就容易被服务器端识别为爬虫,并对其进行限制。
因此,通过随机生成User-Agent字符串,可以有效地伪装客户端,让服务器认为是真正的用户在访问。下面是一个随机生成User-Agent的示例代码:
import random
def get_user_agent():
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.81 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 OPR/39.0.2256.48"
]
return random.choice(user_agents)2. 设置Header头信息
在进行爬虫请求时,需要设置Request请求的Header头信息,尤其需要设置Referer和Cookie等信息。在设置Header头信息时,也需要注意伪装成真实的用户请求。
import requests
url = "http://www.example.com"
headers = {
"User-Agent": get_user_agent(),
"Referer": "http://www.example.com/",
"Cookie": "xxx"
}
response = requests.get(url, headers=headers)3. 使用动态IP代理
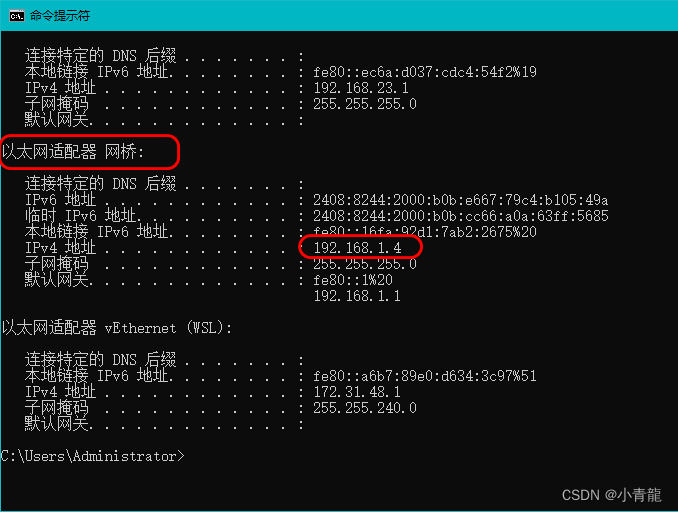
动态IP代理可以帮助我们隐藏真实的IP地址,通过代理服务器来请求目标网站,使得服务器无法识别爬虫程序的真实IP地址。
使用代理需要准备代理池,即多个可用的代理IP地址。可以通过代理IP提供商购买或免费获取。
import requests
def get_proxy():
return {
"http": "http://username:password@proxy_address:port",
"https": "https://username:password@proxy_address:port"
}
url = "http://www.example.com"
response = requests.get(url, proxies=get_proxy())二、代理爬取
在进行代理爬取时,需要注意以下几个问题:
- 代理IP地址需要处于可用状态,否则会影响爬虫程序的运行效率。
- 代理IP地址的数量需要足够,否则会因为频繁的切换导致被服务器封禁。
- 代理IP地址的质量需要优秀,因为低质量的代理IP地址容易出现连接超时或网络错误等情况。
1. 使用代理池
代理池是指多个可用的代理IP地址的集合,通过代理池,可以自动维护可用的代理IP地址,从而避免了手动添加和删除代理IP地址的操作。代理池的实现可以参考下面的示例代码:
import random
import requests
import time
class ProxyPool:
def __init__(self):
self.pool = []
self.index = 0
def get_proxy(self):
if len(self.pool) == 0:
return None
proxy = self.pool[self.index]
self.index += 1
if self.index == len(self.pool):
self.index = 0
return proxy
def add_proxy(self, proxy):
if proxy not in self.pool:
self.pool.append(proxy)
def remove_proxy(self, proxy):
if proxy in self.pool:
self.pool.remove(proxy)
def check_proxy(self, proxy):
try:
response = requests.get("http://www.example.com", proxies=proxy, timeout=10)
if response.status_code == 200:
return True
return False
except:
return False
def update_pool(self):
new_pool = []
for proxy in self.pool:
if self.check_proxy(proxy):
new_pool.append(proxy)
self.pool = new_pool
pool = ProxyPool()
# 添加代理IP地址
pool.add_proxy({"http": "http://username:password@proxy_address:port", "https": "http://username:password@proxy_address:port"})
# 更新代理池
while True:
pool.update_pool()
time.sleep(60)2. 随机切换代理
在进行代理爬取时,需要随机切换代理IP地址,避免因频繁连接同一IP地址而被服务器封禁。可以通过下面的示例代码实现随机切换代理:
import requests
def get_random_proxy():
return {"http": "http://username:password@proxy_address:port", "https": "http://username:password@proxy_address:port"}
url = "http://www.example.com"
for i in range(10):
proxy = get_random_proxy()
response = requests.get(url, proxies=proxy)3. 使用优质代理
在进行代理爬取时,如果使用低质量的代理IP地址,容易出现连接超时或网络错误等情况,从而影响爬虫程序的运行效率。因此,选择优质的代理IP地址非常重要。
可以通过使用代理IP提供商提供的服务,选择优质的代理IP地址。同时,也可以通过定期测试代理IP地址的可用性,及时剔除失效的代理IP地址。下面是一个测试代理IP地址可用性的示例代码:
import requests
def check_proxy(proxy):
try:
response = requests.get("http://www.example.com", proxies=proxy, timeout=10)
if response.status_code == 200:
return True
return False
except:
return False
proxy = {"http": "http://username:password@proxy_address:port", "https": "http://username:password@proxy_address:port"}
if check_proxy(proxy):
print("代理IP地址可用")
else:
print("代理IP地址不可用")三、总结
在进行Python爬虫开发时,常常会遇到目标网站的反爬虫机制,最常见的就是IP封禁。为了绕过这个限制,可以使用IP隐藏技术和代理爬取。IP隐藏技术包括随机User-Agent、设置Header头信息和使用动态IP代理等方法,而代理爬取则需要注意代理IP地址的可用性、数量和质量,可以使用代理池、随机切换代理和选择优质代理等方式实现。