Redis,作为一款高性能的内存数据库,一直以来都因其出色的速度而闻名。然而,Redis的速度之快究竟源自何处,其中隐藏着怎样的奥秘?在这篇博客中,我们将深入探索Redis速度之谜,揭开其快速性能背后的原理和机制。通过分析Redis的架构、内存存储、复制和事件驱动等关键方面,我们将带您进入Redis的速度奇观,一同探索其中的秘密。
下面先用Redis 自带了一个压力测试工具redis-benchmark来测试下速度:
> redis-benchmark -t set -q
SET: 51975.05 requests per second> redis-benchmark -t set -P 2 -q
SET: 91240.88 requests per second一、Redis到底为啥这么快?
Redis 是一个开源的内存数据存储系统,也被称为键值存储数据库。它以高性能和灵活的数据结构操作而闻名,并且具有广泛的应用领域。那么下面先简单介绍下到底都用了什么技术能让它如此之快:
- 单线程模型:Redis 使用单线程模型,即所有的命令都在单个线程中执行。这是为了避免多线程之间的竞争和同步开销,提高性能。单线程模型下,Redis 通过使用非阻塞的 I/O 多路复用机制来实现高并发。
- 内存存储:Redis 将所有数据存储在内存中,这使得它能够实现极快的读写操作。Redis 通过使用数据结构来存储不同类型的数据,如字符串、哈希、列表、集合和有序集合等。
- 持久化:Redis 支持两种持久化方式,即快照(snapshotting)和日志(append-only file)。快照是通过将数据保存到磁盘上的二进制文件来实现的,而日志则是通过追加方式记录每个写操作到日志文件。这样即使 Redis 重启,也可以通过加载快照或重放日志来恢复数据。
- 复制:Redis 支持主从复制,可以将主服务器的数据复制到一个或多个从服务器上。主服务器将写操作记录到内存中的缓冲区,并将这些写操作传播给从服务器,从服务器接收到写操作后执行相同的操作,从而实现数据的同步复制。
- 集群:Redis 集群通过分片(sharding)将数据分布到多个节点上。每个节点负责管理部分数据,客户端可以直接连接到任意一个节点来进行读写操作。Redis 集群使用分布式一致性算法来保证数据的一致性和高可用性。
- 事件驱动:Redis 使用事件驱动的方式来处理客户端的请求和网络 I/O。它使用基于事件的网络库,如 epoll、kqueue 或 select,在有新请求到达时触发相应的事件处理函数。
通过这些底层架构原理,Redis 实现了高性能、高并发、低延迟和数据持久化等特性,使其成为一种非常流行的数据存储解决方案。
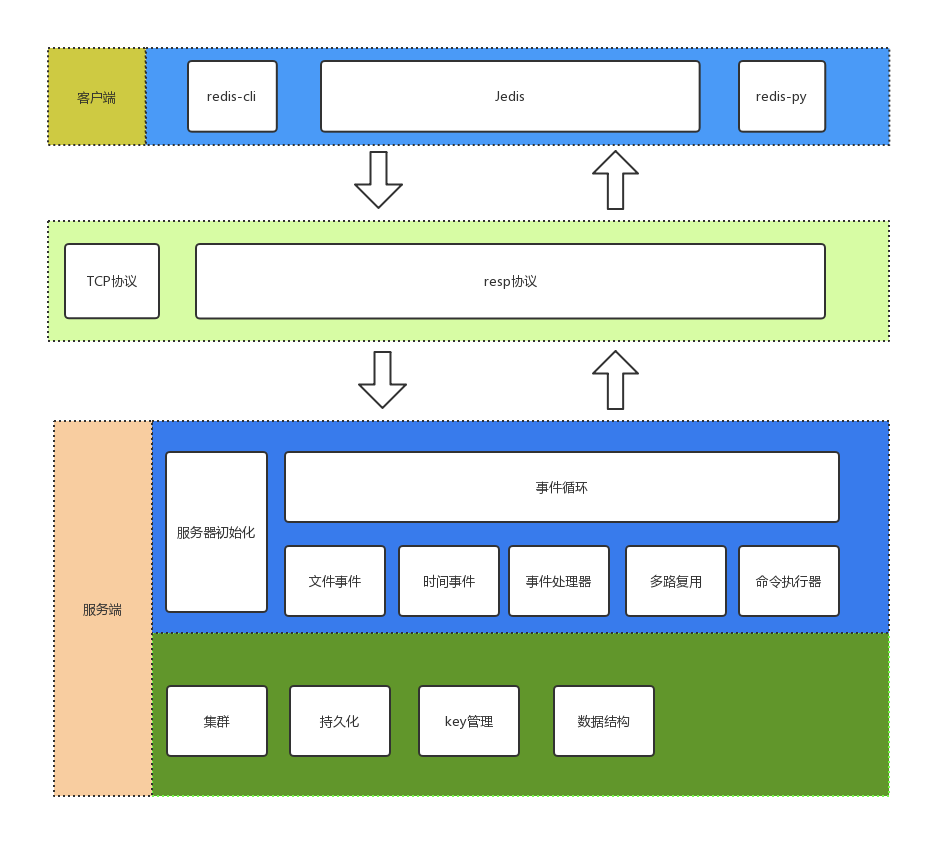
接下来我们在看下redis的通信架构图,这里就能够非常清晰的看到redis底层运行情况:
二、单线程模型
Redis的单线程模型的详细说明:
- 命令请求接收:当客户端发送一个命令请求到Redis服务器时,服务器会将请求放入一个队列中,这个队列被称为客户端请求队列。Redis服务器会按照请求的顺序依次处理这些命令请求。
- 命令执行:Redis服务器会从客户端请求队列中取出一个命令请求进行处理。它会解析命令,执行相应的操作,并将结果返回给客户端。由于Redis是单线程的,因此一次只能处理一个命令请求。
- 非阻塞的I/O多路复用:在命令执行过程中,如果需要与客户端进行网络通信,Redis使用非阻塞的I/O多路复用技术。它能够同时监听多个套接字的可读或可写事件,从而实现高效的事件驱动。常见的I/O多路复用机制有select、poll、epoll和kqueue等。
- 单线程保证数据一致性:由于Redis是单线程的,它不需要考虑多线程之间的竞争条件和同步开销。这使得Redis能够在保持简单性的同时,确保数据的一致性。Redis使用一种称为**事件循环(Event Loop)**的机制来按顺序处理客户端请求和网络I/O事件,确保每个请求的顺序执行。
虽然Redis的命令处理是单线程的,但它通过以下方式实现高性能:
- 高效的数据结构:Redis使用高效的数据结构,如哈希表、跳跃表、压缩列表等,以在单线程下实现高效的数据存储和访问。
- 异步操作:Redis支持异步操作,例如异步持久化和异步复制。这样可以将某些耗时的操作移出主线程,提高整体性能。
- 内存访问速度:Redis将所有数据存储在内存中,通过内存访问速度快的特性,实现快速的读写操作。
需要注意的是,虽然Redis的命令处理是单线程的,但它在某些情况下会使用多个线程来处理一些后台任务,如持久化、复制、集群等。但这些线程不参与命令的处理和数据的读写操作,仅用于辅助功能。
Redis 单线程模型的一些关键点:
- 避免多线程竞争和同步开销:使用单线程模型可以避免多个线程之间的竞争和同步开销。多线程环境下,需要使用锁机制来保护共享数据,而锁机制会引入额外的开销和复杂性。Redis 的单线程模型简化了并发控制和数据一致性的问题。
- 高性能的非阻塞 I/O 多路复用:Redis 使用非阻塞的 I/O 多路复用技术,通常使用 epoll、kqueue 或 select,来处理多个客户端连接。通过这种方式,Redis 可以同时处理大量的并发连接请求,提供高吞吐量和低延迟的性能。
- 快速内存访问:由于 Redis 将数据存储在内存中,它可以实现快速的内存访问。内存访问速度比磁盘或网络访问速度快得多,这使得 Redis 可以在毫秒级别的时间内处理请求。此外,Redis 使用高效的数据结构和算法,进一步提高了内存访问的效率。
- 单线程模型的限制:尽管 Redis 的单线程模型具有高性能和低延迟的优势,但也存在一些限制。由于 Redis 在任何时刻只能处理一个请求,如果某个请求需要耗费大量的计算时间,会导致其他请求的等待。因此,长时间运行的命令或复杂的计算可能会阻塞其他请求的处理。
尽管 Redis 是单线程的,但通过使用非阻塞 I/O 多路复用和异步操作,它可以实现高并发和高吞吐量。此外,Redis 通过将短暂或计算密集型的操作委托给其他线程或进程,如持久化操作和主从复制,进一步提高了性能和可靠性。总体而言,Redis 的单线程模型是通过充分利用内存和优化网络 I/O 来实现高效的数据存储和访问的。
三、内存存储
Redis内存存储的详细解释:
- 内存存储结构:Redis使用多种数据结构来存储数据,包括字符串(string)、哈希(hash)、列表(list)、集合(set)、有序集合(sorted set)等。每种数据结构都有对应的操作命令,使得Redis可以灵活地处理不同类型的数据。
- 数据持久化:尽管Redis将数据存储在内存中,但为了防止数据丢失,Redis提供了两种数据持久化机制:
- 快照(Snapshotting):通过创建数据的快照来定期将内存中的数据写入磁盘。快照可以通过将内存中的数据写入RDB(Redis数据库)文件实现。快照可以在Redis服务器启动时自动加载。
- 日志(AOF,Append-Only File):将每个写操作追加到一个只能进行追加操作的日志文件中,从而记录下所有数据变更的命令。Redis可以通过重放这些命令来还原数据。AOF文件可以在Redis服务器启动时自动加载。
3.内存优化:为了更好地利用内存资源,Redis采用了以下优化策略:
- 数据压缩:对于一些特定的数据类型,如列表、集合等,当数据量较大时,Redis会尝试对其进行压缩,以节省内存空间。
- 数据编码:对于字符串类型的数据,Redis会根据数据的特点选择合适的编码方式。例如,对于较短的字符串,Redis会使用内嵌编码(inline encoding)来减少内存开销。
- 内存回收:Redis使用了一种称为内存回收机制的方法来回收不再使用的内存空间。当Redis中的某个数据结构删除了一些元素或者整个结构被删除时,Redis会尝试将这部分内存重新分配给其他数据结构使用。
4.数据持久化与内存容量的权衡:由于Redis的数据存储在内存中,对于内存容量的需求相对较高。为了在有限的内存容量下存储更多的数据,可以通过以下方法进行权衡:
- 使用压缩数据结构:Redis提供了一些压缩的数据结构,如压缩列表(ziplist)和压缩集合(intset),可以减少数据的内存占用。
- 使用LRU算法:通过设置合适的LRU(Least Recently Used)算法策略,将最近最少使用的数据进行淘汰,以释放内存。
- 使用LFU算法:将最近不经常使用的数据进行淘汰,以释放空间。
- 定期删除过期数据:通过设置数据的过期时间,并定期删除过期数据,可以释放内存空间。
- 持久化选择:根据实际需求选择合适的持久化方式。RDB快照可以将数据在指定时间点保存到磁盘上,适合快速的备份和恢复;AOF日志记录了每个写操作,提供更可靠的数据持久化,但相对会占用更多的磁盘空间和写入性能。
- 使用分片和分布式架构:将数据分片存储在多台机器的内存中,可以扩展内存容量。通过使用分布式架构,可以将数据均匀地分布在多台机器上,进一步提高整体的存储容量和处理能力。
四、redis的复制
Redis复制的详细说明:
- 主从角色:Redis复制涉及两种角色,即主实例(master)和从属实例(slave)。主实例负责接收客户端的写操作,并将写操作的数据发送给从属实例。从属实例接收主实例的数据,并在接收到数据后进行数据同步。
- 复制过程:Redis复制的过程包括初始同步和命令传播两个阶段。
- 初始同步:在初始同步阶段,从属实例需要和主实例建立连接,并向主实例发送同步命令。主实例接收到同步命令后,会将自己当前的数据集发送给从属实例。从属实例接收到数据后,会将数据写入自己的数据库,并标记自己的复制偏移量。初始同步完成后,从属实例会进入命令传播阶段。
- 命令传播:在命令传播阶段,主实例会将自己接收到的写操作命令发送给从属实例。从属实例接收到命令后,会在自己的数据库上执行相同的命令,以保持和主实例相同的数据状态。命令传播过程中,主实例会将命令打包成复制命令(replication command)发送给从属实例。
- 数据同步:Redis的复制采用异步的方式进行数据同步,即主实例将数据发送给从属实例后,不会等待从属实例的回复。这样可以保证主实例的性能不受从属实例的影响,但也可能导致主从实例之间的数据延迟。
- 故障恢复:当从属实例与主实例的连接断开后,它会尝试重新连接主实例。一旦连接恢复,从属实例会请求主实例进行部分重同步(partial resynchronization),只传输从断开连接之后的数据。这样可以尽快恢复从属实例的数据状态。
- 读写分离:通过复制,从属实例可以提供读操作,从而实现读写分离的架构。客户端可以将读操作发送给从属实例,从而减轻主实例的负载。
五、redis集群
Redis集群的详细说明:
- 数据分片:Redis集群将数据分片存储在多个节点上。每个节点负责存储一部分数据,称为槽(slot)。Redis集群使用哈希槽分片算法,根据键的哈希值将数据分配到不同的槽中。
- 节点角色:Redis集群包含多个节点,每个节点可以扮演不同的角色。
- 主节点(Master):主节点负责处理客户端的读写请求,并将数据复制到从节点。
- 从节点(Slave):从节点是主节点的备份节点,负责复制主节点的数据,并在主节点故障时接管主节点的角色。
- 数据复制:Redis集群通过数据复制来实现数据的高可用性和故障恢复。每个主节点都有若干个从节点,主节点将写入的数据复制到所有从节点上。当主节点故障时,集群会自动选举一个从节点作为新的主节点。
- 故障转移:当主节点发生故障或下线时,Redis集群会通过故障转移来选举新的主节点。它会从所有的从节点中选举一个节点作为新的主节点,并将其它从节点切换到新的主节点的复制模式。
- 客户端路由:Redis集群使用客户端分区来实现负载均衡。客户端根据键的哈希值选择合适的节点进行读写操作。集群维护一个槽到节点的映射表,客户端通过查询映射表来确定数据所在的节点。
- 集群管理:Redis集群提供了集群管理工具,例如Redis Cluster命令行工具和Redis Sentinel。这些工具可以用于集群的配置、监控、维护和扩展等操作。
通过Redis集群,可以实现数据的高可用性和横向扩展,提高系统的吞吐量和并发能力。它充分利用了分布式存储和数据复制的机制,确保数据的可靠性和可用性。同时,Redis集群还提供了简单易用的管理工具,方便管理和维护集群的运行状态。
六、redis的事件驱动
Redis事件驱动的详细说明:
- 事件循环:Redis使用一个称为事件循环(Event Loop)的机制来按顺序处理事件。事件循环是一个无限循环,在循环中等待事件的发生,并根据事件类型执行相应的操作。
- 事件类型:Redis支持多种事件类型,包括文件事件(file event)和时间事件(time event)。
- 文件事件:文件事件是Redis与客户端之间的网络I/O事件。它包括客户端连接请求、命令请求和命令结果返回等事件。当文件事件发生时,Redis会调用相应的处理函数进行事件处理。
- 时间事件:时间事件是Redis内部的定时事件。它包括周期性的定时任务和延迟任务。Redis会在指定的时间点触发时间事件,并执行相应的操作。
- 非阻塞I/O多路复用:为了处理文件事件,Redis使用非阻塞I/O多路复用机制。它能够同时监听多个套接字的可读或可写事件,并在事件发生时通知Redis进行处理。常见的I/O多路复用机制有select、poll、epoll和kqueue等。
- 事件驱动流程:Redis的事件驱动流程如下:
- 事件注册:Redis在启动时会初始化一个事件注册表,用于管理文件事件和时间事件的注册和取消注册。
- 事件循环:事件循环是Redis的核心部分。它会不断地等待事件的发生,并根据事件类型执行相应的操作。
- 事件分派:当事件发生时,事件循环会将事件分派给对应的事件处理函数。文件事件会分派给文件事件处理器,时间事件会分派给时间事件处理器。
- 事件处理:事件处理函数会根据事件的类型执行相应的操作。对于文件事件,它会处理客户端的连接请求、命令请求和命令结果返回等操作。对于时间事件,它会执行定时任务和延迟任务。
- 回调函数:在事件处理过程中,Redis还支持回调函数的机制。回调函数可以在事件处理过程中被触发,执行一些额外的操作。
通过事件驱动模型,Redis能够高效地处理并发请求,减少了线程切换和同步的开销,同时提供了良好的可扩展性和性能表现。它充分利用了操作系统和底层I/O多路复用机制的特性,实现了高效的事件处理。
通过本文的探索和解析,我们对Redis速度之谜有了更深入的理解。Redis之所以如此快速,是因为其独特的单线程模型、高效的内存存储和复制机制,以及强大的事件驱动机制。它的设计和实现使得Redis能够在众多应用场景下展现出卓越的性能表现。希望本文能够给您带来启发,并为您在使用Redis时提供一些有益的指导和思考。让我们一同在Redis的速度之谜中不断探索和创新,迈向更快、更高效的数据存储世界!