一、深度学习
1.1 人工智能
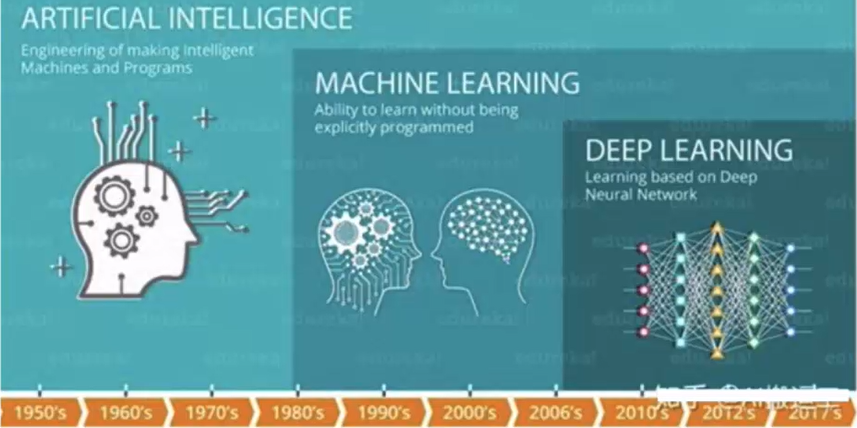
1.2 人工智能,机器学习和深度学习的关系
机器学习是实现人工智能的一种途径,深度学习是机器学习的一个子集,也就是说深度学习是实现机器学习的一种方法。与机器学习算法的主要区别如下图所示[参考:黑马]:

- 传统机器学习算术依赖人工设计特征,并进行特征提取
- 深度学习方法不需要人工,而是依赖算法自动提取特征
深度学习模仿人类大脑的运行方式,从经验中学习获取知识。这也是深度学习被看做黑盒子,可解释性差的原因。随着计算机软硬件的飞速发展,现阶段通过深度学习来模拟人脑来解释数据,包括图像,文本,音频等内容。目前深度学习的主要应用领域有: 语音识别,计算机视觉,自动驾驶
1.3 深度学习发展

- 深度学习所需要的神经网络技术起源于20世纪50年代,叫做感知机。
当时也通常使用单层感知机,尽管结构简单,但是能够解决复杂的问题。后来感知机被证明存在严重的问题,因为只能学习线性可分函数,连简单的异或(XOR)等线性不可分问题都无能为力,1969年Marvin Minsky写了一本叫做《Perceptrons》的书,他提出了著名的两个观点:
1.单层感知机没用,我们需要多层感知机来解决复杂问题
2.没有有效的训练算法。
- 20世纪80年代未期,用于人工神经网络的反向传播算法(也叫Back Propagation算法或者BP算法)的发明,给机器学习带来了希望,掀起了基于统计模型的机器学习热潮。
这个热潮一直持续到今天。人们发现,利用BP算法可以让一个人工神经网络模型从大量训练样本中学习统计规律,从而对未知事件做预测。这种基于统计的机器学习方法比起过去基于人工规则的系统,在很多方面显出优越性。这个时候的人工神经网络,虽也被称作多层感知机 (Multi-layerPerceptron),但实际是种只含有一层隐层节点的浅层模型。
- 20世纪90年代,各种各样的浅层机器学习模型相继被提出
例如支撑向量机 (SVM,SupportVector Machines)、Boosting、最大熵方法(如LR,Logistic Regression)等。这些模型的结构基本上可以看成带有一层隐层节点 (如SVM、Boosting),或没有隐层节点 (如LR)这些模型无论是在理论分析还是应用中都获得了巨大的成功。相比之下,由于理论分析的难度大,训练方法又需要很多经验和技巧,这个时期浅层人工神经网络反而相对沉寂.
- 2006年,杰弗里·辛顿以及他的学生鲁斯兰·萨拉赫丁诺夫正式提出了深度学习的概念。
他们在世界顶级学术期刊《科学》发表的一篇文章中详细的给出了“梯度消失”问题的解决方案--通过无监督的学习方法逐层训练算法,再使用有监督的反向传播算法进行调优。该深度学习方法的提出,立即在学术圈引起了巨大的反响,以斯坦福大学、多伦多大学为代表的众多世界知名高校纷纷投入巨大的人力、财力进行深度学习领域的相关研究。而后又迅速蔓延到工业界中
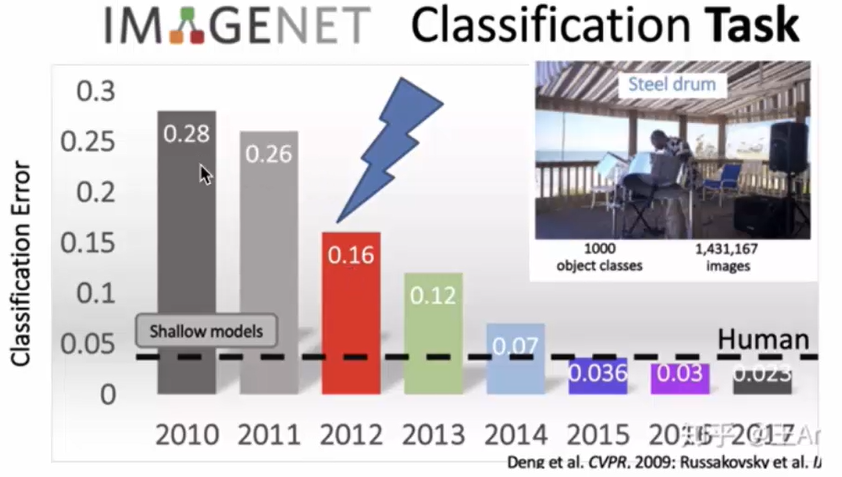
- 2012年,在著名的ImageNet图像识别大赛中,杰弗里·辛顿领导的小组采用深度学习模型AlexNet一举夺冠。
AlexNet采用ReLU激活函数,从根本上解决了梯度消失问题,并采用GPU极大的提高了模型的运算速度。同年,由斯坦福大学著名的吴恩达教授和世界顶尖计算机专家Jeff Dean共同主导的深度神经网络--DNN技术在图像识别领域取得了惊人的成绩,在lmageNet评测中成功的把错误率从26%降低到了15%。深度学习算法在世界大赛的脱颖而出,也再一次吸引了学术界和工业界对于深度学习领域的关注。
- 2016年,随着谷歌公司基于深度学习开发的AphaGo以4:1的比分战胜了国际顶尖围棋高手李世石,深度学习的热度一时无两。后来,AlphaGo又接连和众多世界级围棋高手过招,均取得了完胜。这也证明了在围棋界,基于深度学习技术的机器人已经超越了人类。
2017年,基于强化学习算法的AlphaGo升级版AlphaGo Zero横空出世。其采用“从零开始”、“无师自通”的学习模式,以100:0的比分轻而易举打败了之前的AphaGo。除了围棋,它还精通国际象棋等其它棋类游戏,可以说是真正的棋类”天才”。此外在这一年,深度学习的相关算法在医疗、金融、艺术、无人驾驶等多个领域均取得了显著的成果。所以,也有专家把2017年看作是深度学习甚至是人工智能发展最为突飞猛进的一年。
- 2019年,基于Transformer 的自然语言模型的持续增长和扩散,这是一种语言建模神经网络模型,可以在几乎所有任务上提高NLP的质量。Google甚至将其用作相关性的主要信号之一,这是多年来最重要的更新。
- 2020年,深度学习扩展到更多的应用场景,比如积水识别,路面塌陷等,而且疫情期间,在智能外呼系统,人群测温系统,口罩人脸识别等都有深度学习的应用。
二、 计算机视觉
计算机视觉是指用摄像机和电脑及其他相关设备,对生物视觉的一种模拟。"它的主要任务让计算机理解图片或者视频中的内容,就像人类和许多其他生物每天所做的那样。

我们可以将其任务目标拆分为:
- 目标分类:让计算机理解图片中的场景 (办公室,客厅,咖啡厅等),让计算机识别场景中包含的物体 (宠物,交通工具,人等)
- 目标检测:让计算机定位物体在图像中的位置 (物体的大小,边界等)
- 让计算机理解物体之间的关系或行为 (是在对话,比赛或吵架等),以及图像表达的意义(喜庆的,悲伤的等)
OpenCV阶段,主要学习图像处理,而图像处理主要目的是对图像的处理,比如平滑,缩放等,想、从而为其他任务 (比如“计算机视觉”) 做好前期工作。
2.1 任务
根据上述对计算机视觉目标任务的分解,可将其分为三大经典任务: 图像分类、目标检测、图像分割。

图像分类 (Classification): 即是将图像结构化为某一类别的信息,用事先确定好的类别(category)来描述图片。
目标检测 Detection):分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息 (classification+ocalization)
图像分割 (Segmentation): 分割是对图像的像素级描述,它赋予每个像素类别 (实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
2.2 计算机视觉的发展
1963年,Larry Roberts发表了CV领域的第一篇专业论文,用以对简单几何体进行边缘提取和三维重建。

1966年,麻省理工学院(MIT)发起了一个夏季项目,目标是搭建一个机器视觉系统,完成模式识别(pattern recognition)等工作。虽然未成功,但是计算机视觉作为一个科学领域的正式诞生的标志。
1982年,学者David Marr发表的著作《Vision》从严谨又长远的角度给出了CV的发展方向和-些基本算法,其中不乏现在为人熟知的"图层”的概念、边缘提取、三维重建等,标志着计算机视觉成为了一门独立学科。
1999年David Lowe提出了尺度不变特征变换 (SIFT,Scaleinvariant feature transform) 目标检测算法,用于匹配不同拍摄方向、纵深、光线等图片中的相同元素。

2009年,由Felzenszwalb教授在提出基于HOG的deformable parts model,可变形零件模型开发,它是深度学习之前最好的最成功的object detection & recognition算法。

Everingham等人在2006年至2012年间搭建了一个大型图片数据库,供机器识别和训练,称为PASCAL Visual object Challenge,该数据库中有20种类别的图片,每种图片数量在一千至-万张不等。
2009年,李飞飞教授等在CVPR2009上发表了一篇名为《ImageNet:ALarge-ScaleHierarchicallmage Database》的论文,发布了lmageNet数据集,这是为了检测计算机视觉能否识别自然万物,回归机器学习,克服过拟合问题。

2012年,Alex Krizhevsky、llya Sutskever 和 Geoffrey Hinton 创造了一个“大型的深度卷积神经网络”,也即现在众所周知的AlexNet,赢得了当年的ILSVRC。这是史上第一次有模型在lmageNet 数据集表现如此出色。自那时起,CNN才成了家喻户晓的名字。