High Performance Chiplet and Interconnect Architectures,2022年6月19日,第一届会议(连同第49界ISCA会议)于美国纽约举行。
第一届会议议程及slice:(HiPChips Chiplet Workshop @ ISCA Conference)[https://www.opencompute.org/events/past-events/hipchips-chiplet-workshop-isca-conference]
主题
- Chiplet-based accelerator level parallelism (ALP)
- Chiplet architecture for large scale system design
- Physical and logical inter-die interface design for heterogeneous architectures
- Coherent and non-coherent data sharing protocols via fast chiplet interconnection
- Chiplet architectures for in-memory computing and other emerging technologies
- ODSA-based 3D architecture for efficient ML acceleration
- Chiplet-based secure computing
- Power evaluation and performance modeling of chiplet architecture
- Software optimization framework with fast inter-chiplet network
- Chiplet topology aware ML optimizations
- Scheduling for massive heterogeneous chiplet-based processors
如何将数据在chiplets间划分,以及为了更高效的并行处理而优化数据迁移成为成功的关键。
议题
Memory Centric Computing
系统功耗的62.7%都花在数据迁移上。
Amirali Boroumand, Saugata Ghose, Youngsok Kim, Rachata Ausavarungnirun, Eric Shiu, Rahul Thakur, Daehyun Kim, Aki Kuusela, Allan Knies, Parthasarathy Ranganathan, and Onur Mutlu, "Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks"Proceedings of the 23rd International Conference on Architectural Support for Programming
Languages and Operating Systems (ASPLOS), Williamsburg, VA, USA, March 2018.
Chiplet-based Waferscale Computing
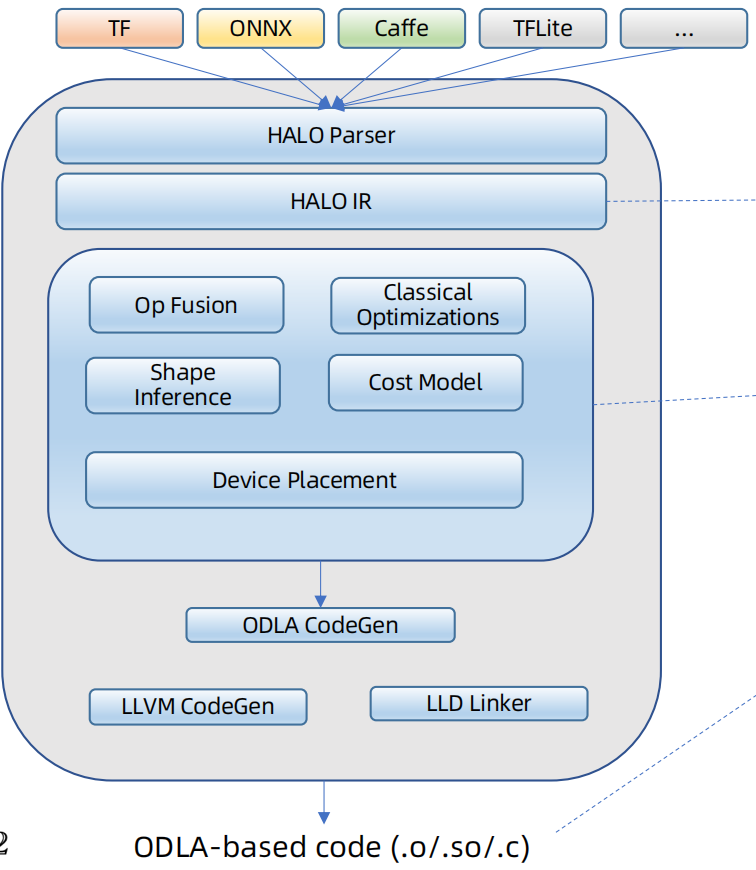
HALO: A Compiler Framework for Chiplet Architectures
异构架构的软件编译框架。
研究者:Weiming Zhao, Weifeng Zhang
High-Bandwidth Density, Energy-Efficient, Short-Reach Signaling that Enables Massively Scalable Parallelism
能够大规模并行标量计算的高带宽密度、能效、短距的信号输出。
Speaker: John Wilson ( Nivida )
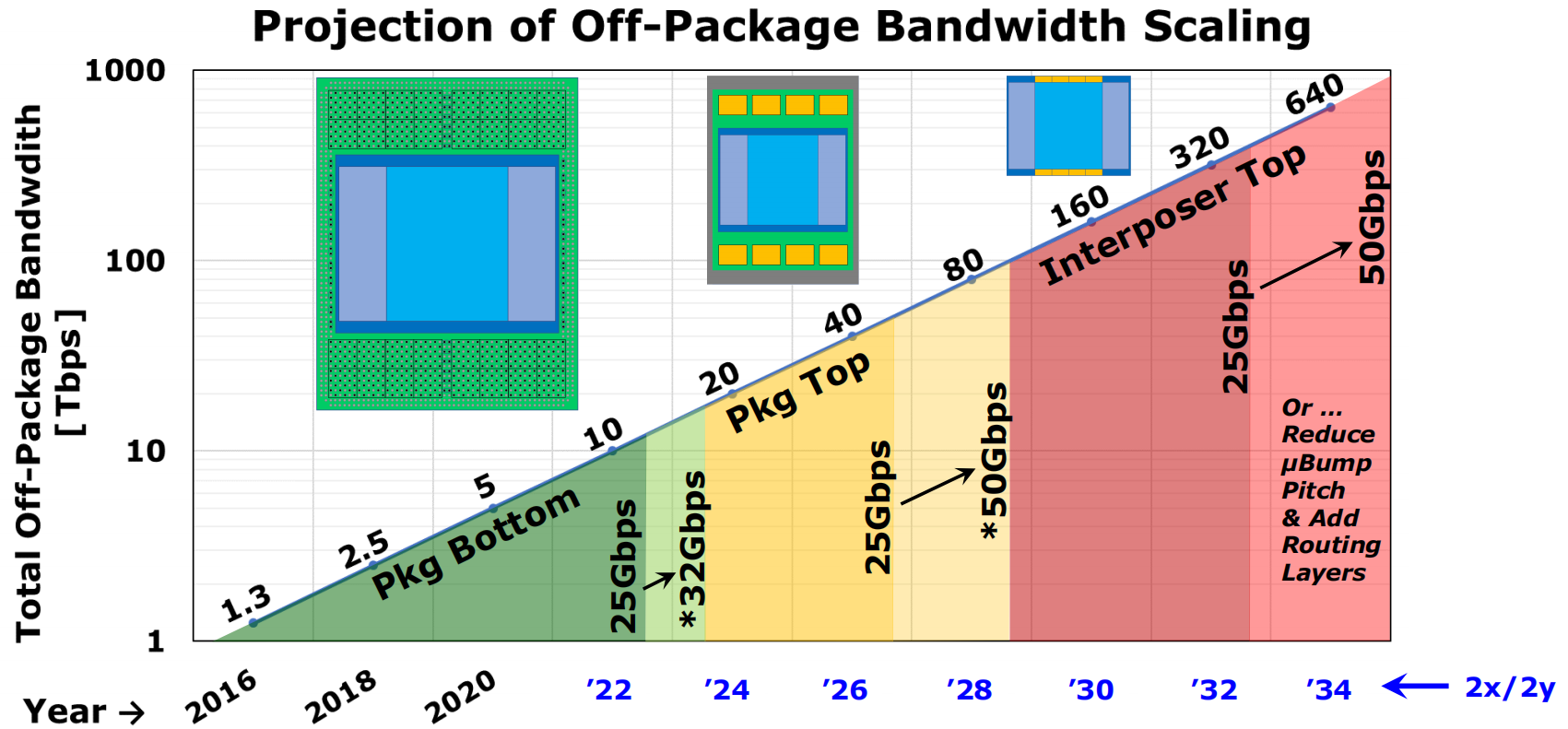
讨论了off-chip和off-package的带宽极限,描述了大量数据传输场景下提高的chip-to-chip传输带宽的单端信号的输出方法,提出了在organic封装和PCB层级的方法 Ground-Referenced Signaling,在interposer层级使用Simultaneous Bidirectional Signaling;也说明了2.5D封装的chip-to-chip大带宽传输仍然存在数据传输功耗过大的挑战。
计算架构升级的目标:每watt增加的计算性能
封装外带宽的演变:
Heterogeneous Chiplet-based Architecture for In-Memory Acceleration of DNNs
用于DNN存内计算加速的异构chiplet架构
提出了一个新的chip-let架构SIAM