Hive远程模式部署参考:
一、Hive数据仓库应用之Hive部署(超详细步骤指导操作,WIN10,VMware Workstation 15.5 PRO,CentOS-6.7)
文章目录
- 一、事务的设计与特点
- 1、事务的特点
- 2、事务的设计
- 3、事务的实现
- 二、事务表的操作
- 1、事务的开启
- 2、事务表的创建
- 3、数据的插入
- 4、更新操作
- 5、删除操作
一、事务的设计与特点
1、事务的特点
事务是由一系列数据库操作组成的一个完整逻辑过程。在hive中,事务包含四个特性:原子性、隔离性、一致性以及持久性。
原子性:一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。
隔离性:数据库允许并发执行的各个事务之间互不干扰,一个事务内部的操作及使用的数据,对于并发的其他事务是隔离的。
一致性:在事务开始之前和事务结束以后,数据库保持一致性和正确性,满足数据完整性约束。
持久性:事务处理结束后,数据库中对应数据的状态变更是永久性的。
2、事务的设计
Hive的数据文件存放在HDFS中,是不支持对文件进行修改的,只允许追加数据。同时当数据追加到HDFS时,HDFS不具备对读取数据文件的用户提供一致性。因为Hive采用增量的形式去记录数据的更新与删除。
Hive事务表中的数据一般会被设计成两种类型的文件,一种是基础文件,用于存放Hive事务表中的原始数据;一种是增量文件,用于存储Hive事务表中新增、更新、删除的数据,以Hive桶的形式进行存储。
在实际使用过程中, 每一个事务处理的数据都会被单独创建一个增量文件夹用于存储数据,当用户读取事务表的数据时,会将基础文件和增量文件都读取到内存中进行合并,合并的过程会判断原始数据中哪些数据进行了修改或删除等操作,最终将合并后的结果返回给查询。
3、事务的实现
Hive通过HiveServer2或Metastore中运行的一组后台进程Compactor实现事务的支持。随着修改表的操作增加,增量文件的数量也会随之增加,这个时候就需要使用Compactor对增量文件进行压缩。压缩分为主要压缩和次要压缩,主要压缩处理一个或多个桶的增量文件和基本文件,将它们重写为每个桶新的基本文件;次要压缩会获取一组现有的增量文件,并将每个增量文件夹重写为单个增量文件。
二、事务表的操作
1、事务的开启
Hive在默认情况下并不会开启事务的支持,但是为了保证ACID原则的规范,Hive需要进行额外的处理,这将带来性能方便的影响,需要手动配置开启Hive事务。
以创建好的集群node-01、node-02、node-03为例,由于使用node-02的Hive客户端工具Beeline远程连接node-01中的HiveServer2服务的方式操作Hive,因此修改node-01的Hive配置文件hive-site.xml,在配置文件的中添加以下内容。
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>1</value>
</property>
hive.support.concurrency:开启Hive锁管理器,提供多事务并发执行的功能。
hive.enforce.bucketing:开启自动按照分桶表指定的桶数进行分桶。
hive.exec.dynamic.partition.mode:关闭Hive的严格模式。
hive.txn.manager:管理Hive中的事务和锁。
hive.compactor.initiator.on:开启Initiator。
hive.compactor.initiator.on:指定运行Compactor的工作线程数。
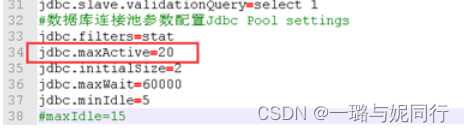
进入hive-site.xml的方法如下图所示:

2、事务表的创建
在开启Hive事务的情况下, 创建的Hive表并不会直接变为事务表,需要在创建Hive表时通过属性值transactional声明创建的Hive表属于事务表。
例如在Hive中创建一个基于分桶的事务表tran_clustered_table,该表中包含列id、name、gender、age和dept,建表指令如下:
CREATE TABLE hive_database.tran_clustered_table (
id STRING,name STRING,gender STRING,age INT,dept STRING)
CLUSTERED BY (dept) INTO 3 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS ORC
TBLPROPERTIES ("transactional"="true",
"compactor.mapreduce.map.memory.mb"="2048",
"compactorthreshold.hive.compactor.delta.num.threshold"="4",
"compactorthreshold.hive.compactor.delta.pct.threshold"="0.5"
);
“transactional”=“true”:表示创建的表为事务表。
“compactor.mapreduce.map.memory.mb”=“2048”:表示压缩任务触发的MapReduce任务使用的内存。
“compactorthreshold.hive.compactor.delta.num.threshold”=“4”:表示超过4个增量文件会触发次要压缩。
“compactorthreshold.hive.compactor.delta.pct.threshold”=“0.5”:表示增量文件的大小超过基础文件的50%触发主要压缩。

3、数据的插入
向事务表中插入数据的操作和向基础表中插入数据的操作一致,向刚刚创建的事务表中插入相关数据。
INSERT INTO TABLE hive_database.tran_clustered_table VALUES
("001","user01","male",20,"YanFa"),
("002","user02","woman",23,"WeiHu"),
("003","user03","woman",25,"YanFa"),
("004","user04","woman",30,"RenShi"),
("005","user05","male",28,"YanFa"),
("006","user06","male",27,"CeShi"),
("007","user07","woman",33,"ShouHou"),
("008","user08","male",32,"CeShi");
上述指令执行完成之后,事务表tran_clustered_table在HDFS的存储目录/user/hive_local/warehouse/hive_database.db/tran_clustered_table/下会生成一个以delta开头的文件夹,该文件夹内的数据文件属于插入操作的增量文件。
4、更新操作
Hive事务表中的更新操作是指更新事务表中某一列的值或多个列的值,更新操作的语法格式如下:
UPDATE tablename SET column = value [, column = value ...]
[WHERE expression]
UPDATE表示更新操作的HiveQL语句;tablename表示事务表名称;SET子句指定更新的列以及对应的值;column = value表示列名和对应的值;WHERE expression可选,表示通过WHERE子句指定条件expression根据指定条件更新列的值。
例如将刚刚创建并插入数据的表tran_clustered_table中员工姓名为user01的员工id更新为009,年龄更新为21,具体指令如下:
UPDATE hive_database.tran_clustered_table
SET age = 21,id="009"
WHERE name = "user01";
此时,事务表tran_clustered_table在HDFS的存储目录/user/hive_local/warehouse/hive_database.db/tran_clustered_table/下会生成一个以delta开头的文件夹,该文件夹内的数据文件为更新操作的增量文件。
注意事项:
- 更新的列必须在事务表中存在;
- 不能指定分区表中的分区字段作为更新列;
- 不能指定分桶表中的分桶字段作为更新列。
5、删除操作
Hive事务表的删除操作是指删除Hive表中符合指定条件的所有数据,这里的Hive表只支持事务表,有关Hive中删除操作的语法格式如下:
DELETE FROM tablename [WHERE expression]
DELETE表示删除事务表数据的语句;FROM子句指定删除数据的事务表;WHERE expression可选,表示通过WHERE子句指定条件expression。
例如删除事务表tran_clustered_table中员工姓名为user01的员工,具体指令如下:
DELETE FROM hive_database.tran_clustered_table WHERE name = "user01";
此时,事务表tran_clustered_table在HDFS的存储目录/user/hive_local/warehouse/hive_database.db/tran_clustered_table/下会生成一个以delta开头的文件夹,该文件夹内的数据文件为更新操作的增量文件。
参考文献:黑马程序员.Hive数据仓库应用[M].北京:清华大学出版社,2021.