今天是哈希表的实现,哈希表也是一种数据结构,我个人认为还是比较简单的,先给大家看看我 的实现代码吧,如下:
#pragma once
#include <iostream>
#include <set>
#include <map>
#include <vector>
#include <string>
#include <assert.h>
//哈希捅实现哈希表
using namespace std;
namespace cc
{
//哈希捅的每个节点
template<class K,class V>
struct hashnode
{
pair<K, V> _val;
hashnode<K, V>* _next = nullptr;
hashnode(const pair<K,V>& x)
:_val(x)
{}
};
//哈希表
template<class K, class V>
class hash
{
public:
typedef hashnode<K, V> node;
hash()
{}
hash(const hash<K, V>& h)
{
_table.resize(h._table.size(), nullptr);
for (size_t i = 0; i < _table.size(); i++)
{
if (h._table[i] != nullptr)
{
node* cur = h._table[i];
while (cur)
{
node* copy = new node(cur->_val);
copy->_next = _table[i];
_table[i] = copy;
cur = cur->_next;
}
}
}
_size = h._size;
}
bool insert(const pair<K, V>& x)
{
//如果需要扩容或是此时是一个空表
//注意:这里其实有个负荷因子,因为STL中的用哈希桶实现的哈希表中,负荷因子的大小是1,所以就是相等,如果用线性探测或是二次探测
//的方法,就不能控制在1,最好控制在0.7-0.8左右就开始扩容,扩容其实根据专业人士的研究,扩容的大小最好是质数的,出现哈希碰撞的几率
//就比较少
if (_size == _table.size())
{
vector<node*> tem;
tem.resize(_table.size() == 0 ? 10 : _table.size() * 2, nullptr);
//旧表节点移动到新表
for (size_t i = 0; i < _table.size(); i++)
{
node* cur = _table[i];
while (cur)
{
cur->_next = tem[i];
tem[i] = cur;
cur = cur->_next;
}
}
//移动完成,交换两个表
tem.swap(_table);
}
node* newnode = new node(x);
int ret = newnode->_val.first % _table.size();
//头插
newnode->_next = _table[ret];
_table[ret] = newnode;
_size++;
return true;
}
node* find(const K& key)
{
int ret = key % _table.size();
node* prev = nullptr;
node* cur = _table[ret];
while (cur)
{
if (cur->_val.first == key)
return cur;
prev = cur;
cur = cur->_next;
}
return nullptr;
}
bool erase(const K& key)
{
if (_size == 0)
{
cout << "无法删除空表的内容" << endl;
return false;
}
int ret = key % _table.size();
node* prev = nullptr;
node* cur = _table[ret];
while (cur)
{
if (cur->_val.first == key)
{
if (prev)
prev->_next = cur->_next;
else
_table[ret] = cur->_next;
delete cur;
_size--;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
private:
size_t _size = 0;
vector<node*> _table;
};
}
上面就是我用哈希捅实现的哈希表,思维逻辑还是比较简单的,但是还是要注意的点。
先来说说哈希表的作用吧。我个人感觉哈希表就是寻找方便,时间复杂度是O(1),个人认为这应该是查找的天花板了吧,就连各种效率都很优的AVL树和红黑树都是log(n),所以个人认为这个数据结构应该是查找的天花板了,但是他的缺点也很明显。我们先来看看下面的图,来看看他的原理:
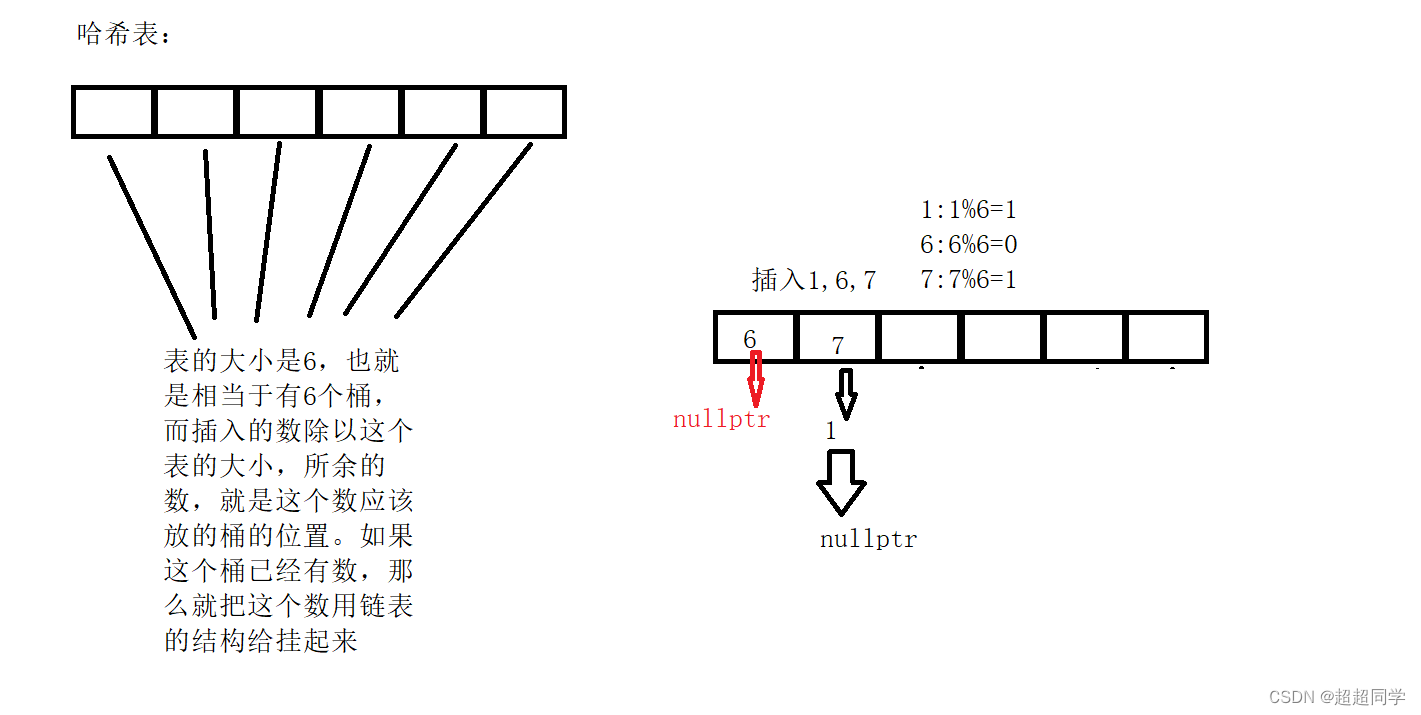
如上,它的原理其实就是这样的,而哈希捅的实现其实使用链表来实现的,也就是每个桶都挂了一个单向链表,其实不仅可以挂单向链表,双向链表其实也可以挂,但是不用双向链表的原因是,双向链表比单链表的消耗大,所以才用的单链表,而在同一个桶的位置,挂数的时候,我们普遍用头插,这个就不说了,很容易理解,头插的时间复杂度是O(1)。
其实很多人在看到这种情况的时候,可能会懵,这中结构怎么查找的时间复杂度是O(1)呢?如果我查找的桶刚好是一个挂的非常多的,这不是就相当于O(N)了嘛,其实这个我刚开始也有这种疑惑,但是到现在我就比较释然了,我们打个比喻,最坏的情况是所有插入的数在一个桶的位置,这个是最坏的情况,但是不知道大家测试过吗?这种情况除非是人为的,也就是自己故意的,不然基本是不会出现的,因为我测试过,插入随机的十万个左右的树,它的桶数是大概好像是十二万多,而每个桶所挂起的数,最多的才是3个,普遍都是一个桶挂一个数,所以你担心的情况所出现的概率是非常低的。几乎没有,除非你是自己故意的。所以他的每个桶所挂起的数,基本是常数级别的,所以就是O(1),如果你实现是担心,其实他的每个桶的位置不一定要挂链表,也可以挂红黑树啊,这样效率不就是越来越高了嘛,所以我们不要看到一点点的缺点就不放过,而且他的这个缺点出现的概率实在是太低太低了。
我们可以看到的是,它的查找效率几乎是无敌的,因为不管查找什么,他都是映射的关系,直接映射到它的桶的位置,但是其实他的缺点也非常的大,它的缺点就是扩容的消耗太大了,因为他扩容还要把所有的数据再给新扩的这个表拷贝一份,所以这个是他的缺点。
还有就是线性探测与二次探测的方法来实现哈希表,这个后面会陆续的发。
本篇内容如果对你有用的话,希望带你一下赞吧!!!