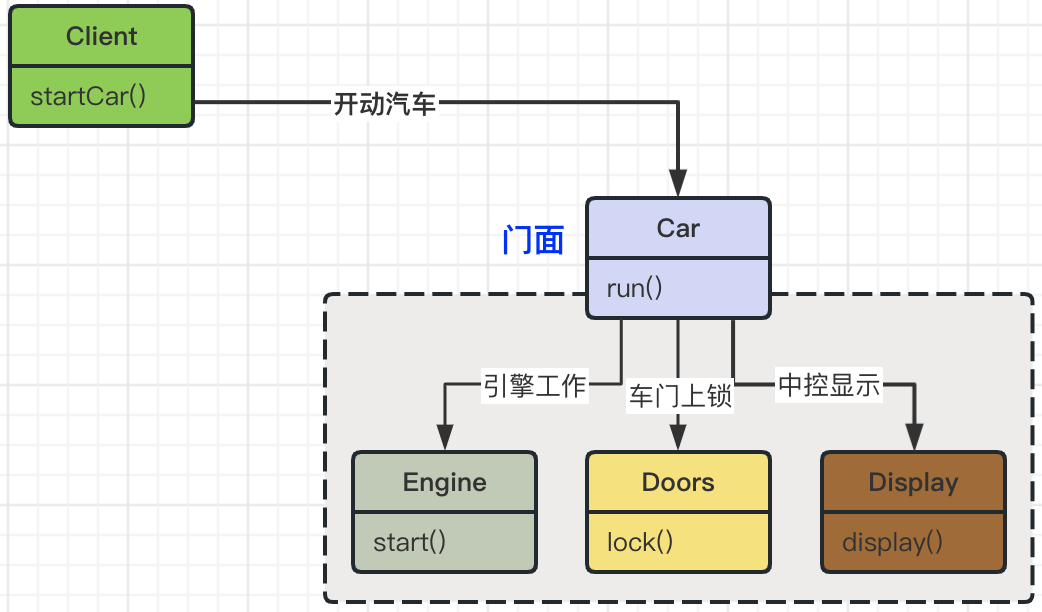
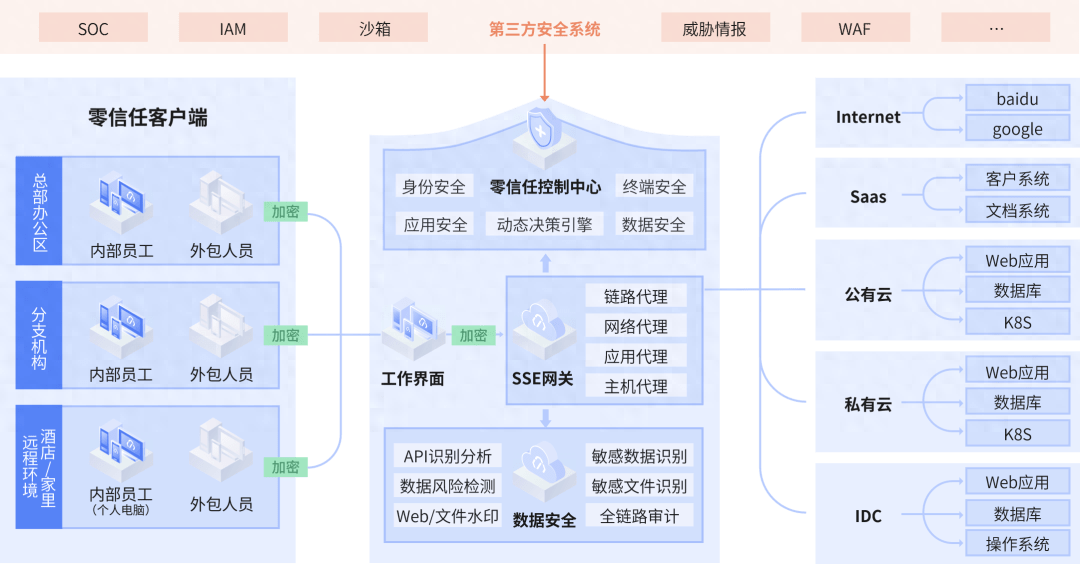
一、SEBlock(通道注意力机制)
先在H*W维度进行压缩,全局平均池化将每个通道平均为一个值。
(B, C, H, W)---- (B, C, 1, 1)
利用各channel维度的相关性计算权重
(B, C, 1, 1) --- (B, C//K, 1, 1) --- (B, C, 1, 1) --- sigmoid
与原特征相乘得到加权后的。
import torch
import torch.nn as nn
class SELayer(nn.Module):
def __init__(self, channel, reduction = 4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) //自适应全局池化,只需要给出池化后特征图大小
self.fc1 = nn.Sequential(
nn.Conv2d(channel, channel//reduction, 1, bias = False),
nn.ReLu(implace = True),
nn.Conv2d(channel//reduction, channel, 1, bias = False),
nn.sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y_out = self.fc1(y)
return x * y二、CBAM(通道注意力+空间注意力机制)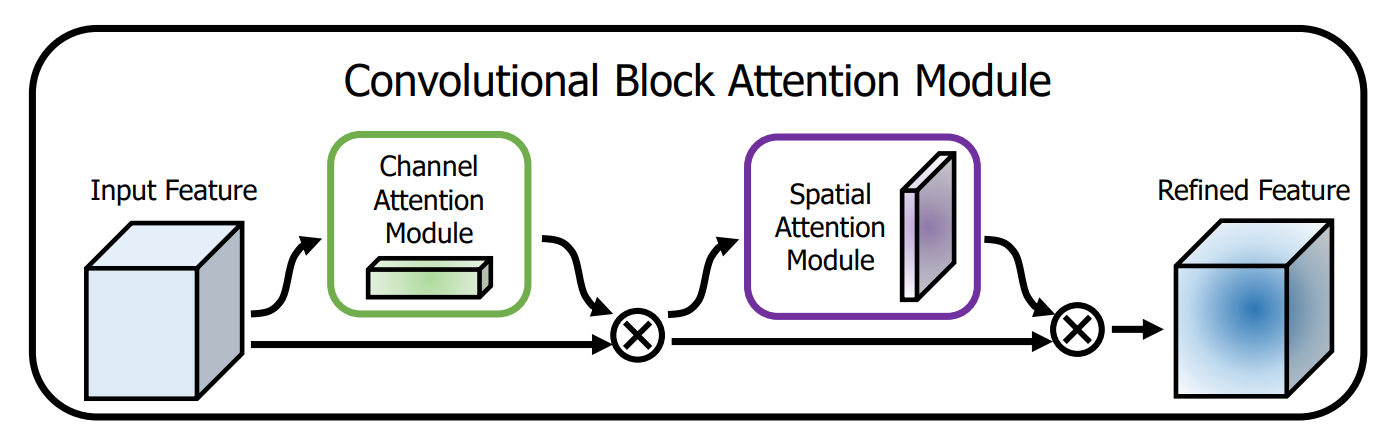
CBAM里面既有通道注意力机制,也有空间注意力机制。
通道注意力同SE的大致相同,但额外加入了全局最大池化与全局平均池化并行。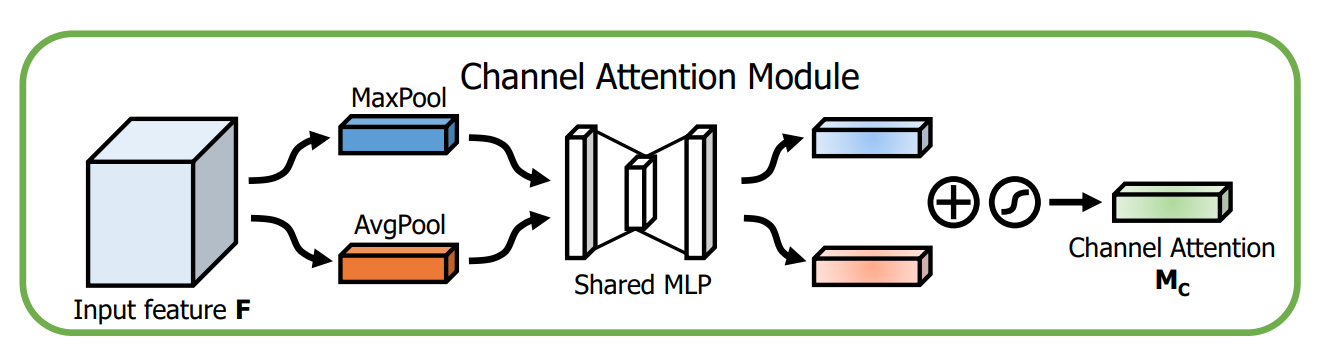
空间注意力机制:先在channel维度进行最大池化和均值池化,然后在channel维度合并,MLP进行特征交融。最终和原始特征相乘。 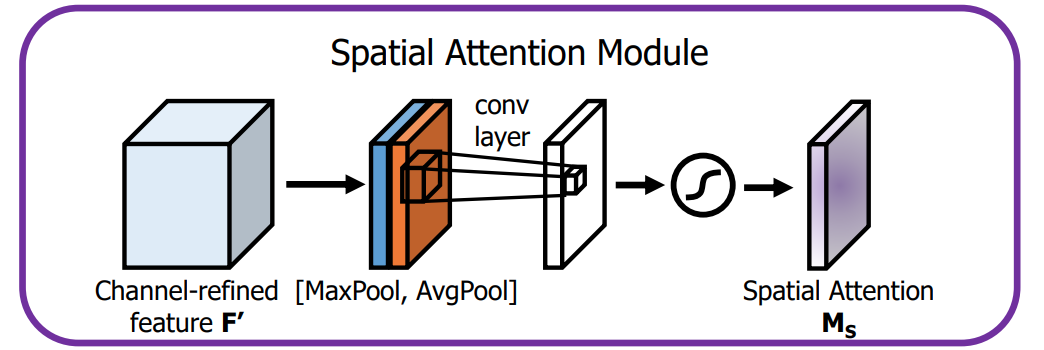
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, channel, rate = 4):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Sequential(
nn.Conv2d(channel, channel//rate, 1, bias = False)
nn.ReLu(implace = True)
nn.Conv2d(channel//rate, channel, 1, bias = False)
)
self.sig = nn.sigmoid()
def forward(self, x):
avg = sefl.avg_pool(x)
avg_feature = self.fc1(avg)
max = self.max_pool(x)
max_feature = self.fc1(max)
out = max_feature + avg_feature
out = self.sig(out)
return x * out
import torch
import torch.nn as nn
class SpatialAttention(nn.Module):
def __init__(self):
super(SpatialAttention, self).__init__()
//(B,C,H,W)---(B,1,H,W)---(B,2,H,W)---(B,1,H,W)
self.conv1 = nn.Conv2d(2, 1, kernel_size = 3, padding = 1, bias = False)
self.sigmoid = nn.sigmoid()
def forward(self, x):
mean_f = torch.mean(x, dim = 1, keepdim = True)
max_f = torch.max(x, dim = 1, keepdim = True)
cat = torch.cat([mean_f, max_f], dim = 1)
out = self.conv1(cat)
return x*self.sigmod(out)