一、grep工具的使用
![]()

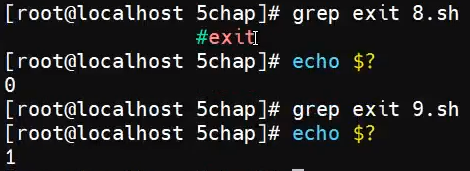
可以通过返回状态码判断文件有没有这个数据,有状态码为0,没有为1。文件不存在状态码为2

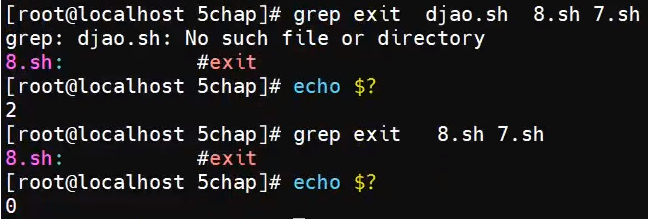

-o:
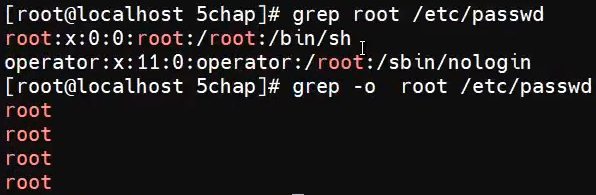


二、正则表达式

1、基本正则表达式

.为匹配任意字符,..两个两个匹配任意字符,...三个三个匹配任意字符
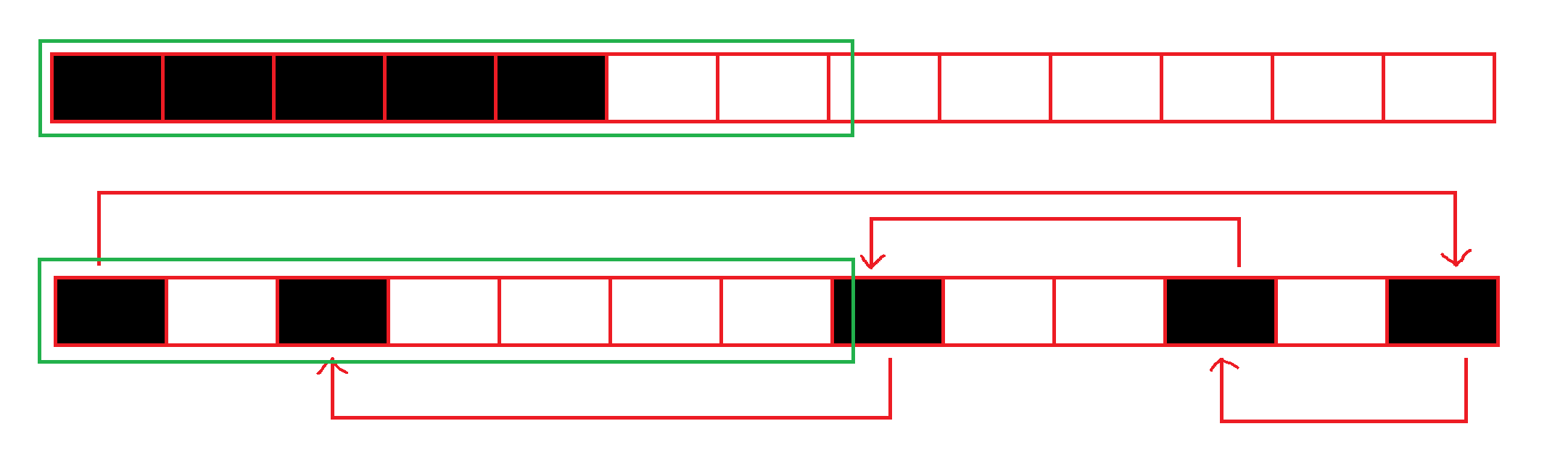
*:对前一项重复0~多次
![]()
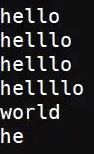

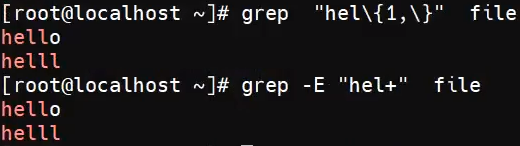
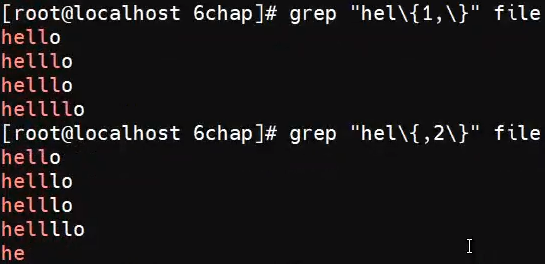
{m, n}指定匹配多少次,需要加\对{}进行转义

匹配一次、匹配两次:
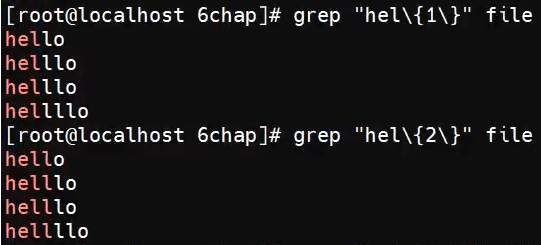
最少一次,最多不管、最多两次,最少不限
匹配[]内的单一字符

不匹配[]中的任意一个字母,即除了h和w其他都匹配

匹配以h或w开头的行:
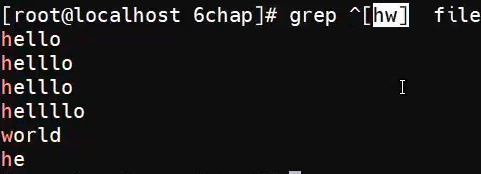
匹配不以h或w开头的行:


任意字符重复0~多次,\1表示第一个()中的字符,即第一个表达式,即love。即匹配love和love之间可以有任意0~多个字符的行



因为文件中test和ceshi之间是空格,而过滤的没有

![]()
![]()


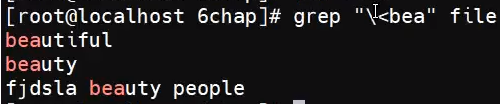
匹配以bea开头的单词,不是行
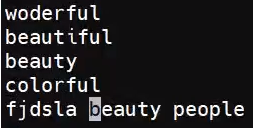
匹配以ful结尾的单词

既有词首锚定,又有词尾锚定表示匹配这个单词

注意:不等同于grey beauty



等同于-w,按照单词匹配

\< \> 也可以用 \b \b

2、扩展正则表达式


匹配字符a或者r:使用基本正则或者扩展正则(|),扩展正则需要加-E

两者区别在于基本正则只能匹配单字符,扩展正则能匹配多字符:

?在命令行中表示匹配任意一个字符,???表示匹配任意三个字符

匹配he,l出现0~1次两种写法:


匹配he,l出现1次~多次两种写法: