👏作者简介:大家好,我是爱发博客的嗯哼,爱好Java的小菜鸟
🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
📝社区论坛:希望大家能加入社区共同进步
🧑💼个人博客:智慧笔记
📕系列专栏:
文章目录
- 前言
- MySQL整体架构
- join和left join执行流程
- 有一个表有索引
- 两个表都有索引
- 两表都没索引
- join和left join区别
- 为什么left join左表为驱动表
- left join特殊情况
- 结语
前言
相信大家都知道在MySQL中的join、left join和right join,在业务中,需要两表联查总会用到联合查询语句。但大家却有可能并不太了解他们底层是如何进行处理的,也就无法在业务量大的情况下,去优化这些sql语句。
本节我就为大家通过执行流程层面进行一些讲解,相信大家看完本篇文章对以后的优化处理也就不会毫无头绪了。
MySQL整体架构
如果大家对于MySQL架构一点都不了解,可以去看一下这篇MySQL基本架构
在了解一种技术之前,最主要的就是知道其底层架构。只有知道了底层架构,才能在后续的基础上更轻松的掌握整体。
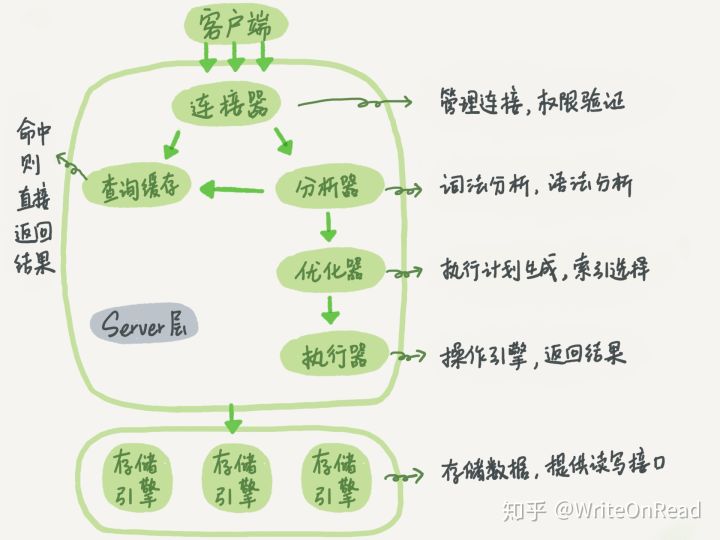
MySQL主要分为两个层面,一个是Server层,即MySQL官方自己的核心层面。另一个就是存储引擎层,这个相当于一个插件,所有人都可以基于MySQL官方给的结构进行实现存储引擎。
而要谈论的核心就是存储引擎层。使用不同的存储引擎,优化的方式也就不一样。而我们要谈论的是当前官方默认的存储引擎—InnoDB存储引擎。

这张就是innodb的缓冲池,而和join优化相关的缓冲就是最不起眼的那个—额外的缓冲池。
相信大家都知道缓冲池的功能,这里就不再过多赘述了。
join和left join执行流程
在join类型语句执行时一般会有两个表,一个为驱动表,另一个为被驱动表。首先执行引擎会去磁盘找到驱动表第一行数据,再去磁盘找到跟第一行匹配的语句。直到找完驱动表对应的所有匹配数据。
大家或许有疑问了,驱动表有什么好处呢?
这就用到上面的缓冲池这个东西了,执行引擎会将驱动表取出来放入缓冲池中,在内存遍历一行行数据去磁盘匹配对应的被驱动表数据。内存的速度是磁盘的几百倍,这样的话会比两表都在磁盘遍历快上很多倍。
有一个表有索引
既然大家知道了join过程会使用缓冲池,那当一个表有索引的时候,应该选哪个表作为驱动表合适?
首先驱动表会被加载到内存遍历所有行,而被驱动表只能在磁盘遍历。假设驱动表有n条数据,被驱动表有m条数据。
如果索引表做驱动表。
对于驱动表来说,每行都要走一次,时间复杂度为N。
而被驱动表没有索引,也需要全表扫描,时间复杂度为N*M。
执行过程近似时间复杂度为N+N*M。
如果索引表做被驱动表
对于被驱动表来说,时间复杂度大概是logM,查询到主键回表又是logM,需要查询N次,总共时间复杂度为N*2 *logM。
因此执行过程近似时间复杂度是N+N*2 *logM。
所以索引表做被驱动表的话,会大大提升查询效率。
因此业务中,在join查询时出现慢查询情况,可以将被驱动表加上索引。
两个表都有索引
当两个表都有索引的时候,时间复杂度为N+N*2 *logM,N占主导地位。
因此选择表数据小的做驱动表。
业务中,建议小表驱动大表。
两表都没索引
这时候你或许有疑问了,两表都没索引时间复杂度不都是遍历两张表全表吗?
当然是不同的,首先驱动表是在内存中遍历的,要比磁盘快。如果放入内存中的数据多一点,磁盘io次数就少了。性能不久提升了。
话是这样说的,但这里面有一个大坑。
先把结论放出来:
- 如果此时两个小表。选择相对大的做驱动表。
- 如果此时一个小表,一个大表。选择小表做驱动表。
- 如果此时两个大表。选择相对小的做驱动表。
为什么这样做呢?
首先缓冲区是有大小限制的,并不是无限的。因此,放入过大的表就会放不下。所以尽量能放入能放下的表。
对于放不下的大表也有优化方法。
MySQL使用BNL算法,将大表分块放入缓冲区中,对于每块都对驱动表进行全表扫描。
join和left join区别
这时候你已经知道了join和left join的大致执行流程了。但你或许还不知道他俩区别到底在哪里。这里就来详细说说。
首先join时inner join的缩写,意思是找到两个表同时成立的数据。

而left join查找的结果除啦inner join的结果,还有左表剩余的结果,以及右表对应的null值。

一般来说left join语句左表是驱动表,而inner join语句是优化器选择驱动表。
为什么left join左表为驱动表
这里就和上面执行流程有关了。
大家回忆一下,驱动表是不是存储在内存当中。而left join结果是不是需要左表的所有数据。而右表返回的刚好是符合条件的数据。剩下的左表查询不到的直接返回null值,刚好结果集对应left join需要的结果。
如果left join将右表作为驱动表有什么后果呢?
首先右表遍历所有数据找到对应左表的符合条件数据作为结果集。然后再次去磁盘查找左表剩余的数据。
这时候效率显而易见的会变低,因此一般都会将左表作为驱动表。right join也同理。
left join特殊情况
当然,left join左表驱动不是一定存在的。
left join和inner join一样,在表中现根据on条件选出结果集。如果出现where语句的时候,where会对结果集进行筛除。这时候where就会将左表出现右表却没有匹配的数据都给筛除掉。
当出现where的时候,left join就跟inner join相同了,筛选出同时成立的数据行。此时left join就会转换为inner join,由优化器指定驱动表。
所以left join不一定左表一定是驱动表。
结语
每个人都有自己独特的才华和潜能,在这个广袤的世界上,你的存在是有意义的。无论你是谁,你的背景如何,你所处的环境怎样,只要你敢于跨出舒适区,付出努力,追求卓越,你就能够开创属于自己的辉煌。
我们下期见。
每一次努力都是一次进步,即使进展缓慢,也要坚持不懈。
往期文章推荐:
- JUC详解
- 缓存穿透、缓存击穿和缓存雪崩
- 消息中间件相关面试题
- Java集合相关面试题
- Java集合详解
- 微服务相关面试题
- redis相关面试题
- 图解 Paxos 算法