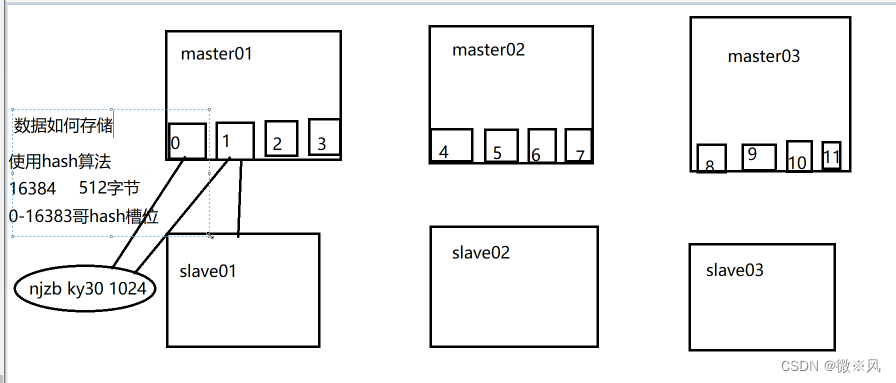
1、背景
经常看到集群的merge限流耗时比较高,所以想分析其原因、造成的影响、以及反思merge的一些优化手段。
比如下图中测试集群相关监控截图:
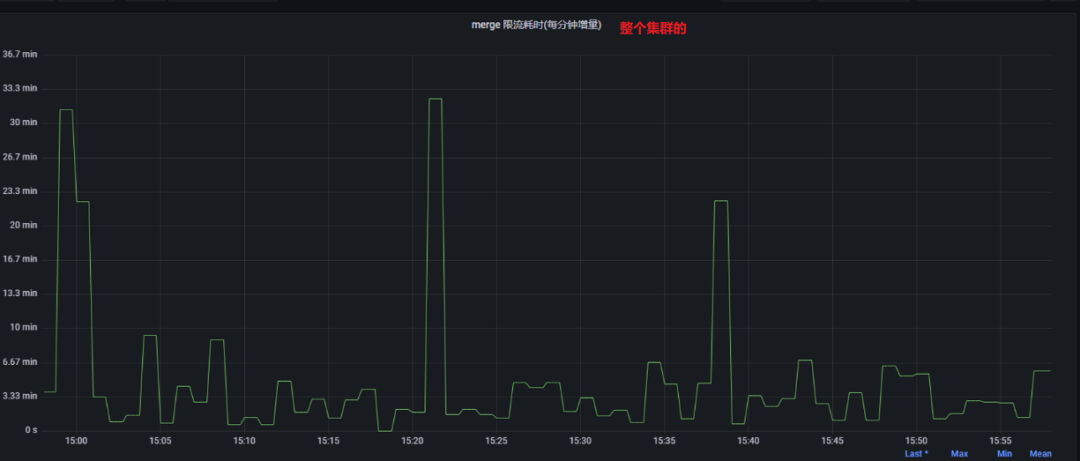
可是从磁盘的写入来看,并不高:
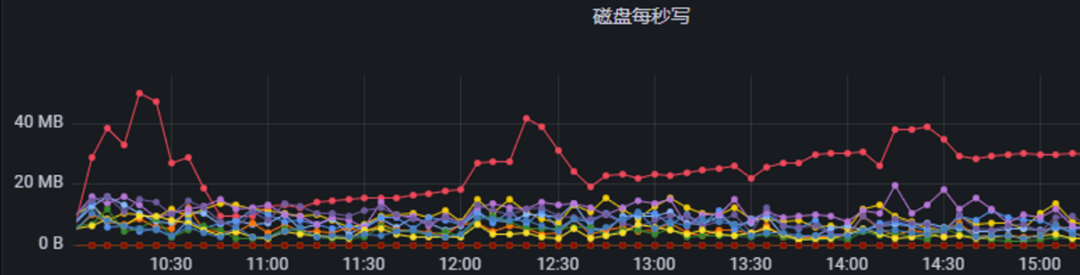
那么目前的情况带来哪些影响?
资源利用率低下
从写IO监控可以看出,其实ES节点的IO压力并不大, 这导致IO资源的浪费
pendingMerges队列增加,导致很多待合并的段一直等待
队列中的元素迟迟无法得到处理,严重的甚至浪费内存
合并太慢,段就多,占用内存也比较多
影响查询性能
每个段都是一个可搜索的基础单元,段越多,搜索过程就需要跨更多的段,必然性能下降
存储空间释放缓慢
段合并才会将索引中的文档进行真正的删除, 这个时候才会释放空间
所以本文尝试深入分析调度细节,找到merge限流的根本原因以及思考是否存在优化的手段。
💡 注:本文中没有特别说明的话,索引指Lucene的索引,即Elasticsearch中的分片。2、merge指标统计分析

我们从ES返回的响应出发,看关键的一些指标是如何计算的。
total_throttled_time_in_millis && total_stopped_time_in_millis
在这个类中:org.elasticsearch.index.engine.ElasticsearchConcurrentMergeScheduler
private final CounterMetric totalMergeThrottledTime = new CounterMetric();org.elasticsearch.index.engine.ElasticsearchConcurrentMergeScheduler#doMerge:
long stoppedMS = TimeValue.nsecToMSec( merge.getMergeProgress().getPauseTimes().get(MergePolicy.OneMergeProgress.PauseReason.STOPPED) ); long throttledMS = TimeValue.nsecToMSec( merge.getMergeProgress().getPauseTimes().get(MergePolicy.OneMergeProgress.PauseReason.PAUSED) ); // 记录的是停止的时间 totalMergeStoppedTime.inc(stoppedMS); // 记录的是暂停的时间 totalMergeThrottledTime.inc(throttledMS);具体这两种时间又什么区别,后文分析。
total_auto_throttle_in_bytes
这个分片的OneMerge的限流速率大小,后文分析
current && current_docs && current_size_in_bytes
current:当前进行的OneMerge的个数,正在进行的merge。
current_docs:当前进行的OneMerge的文档数。
current_size_in_bytes:当前进行的 OneMerge的totalMergeBytes,有别于estimatedMergeBytes。totalMergeBytes 表示参与合并的所有段的总大小,不考虑删除文档的影响,用于跟踪合并操作涉及的总数据量。
前面提到的 estimatedMergeBytes 含义:估计了合并后生成的段的大小,考虑了删除文档的影响,用于预测合并后的段的大小 (调整限速是用这个属性)
类似的还有total总数的统计:total发生merge次数, 总耗时total_time_in_millis, 总文档数total_docs, 总字节大小total_size_in_bytes
3、ElasticsearchConcurrentMergeScheduler 分析
从merge指标统计来看,都是在这个ElasticsearchConcurrentMergeScheduler 中完成的,所以对其进行简单分析。
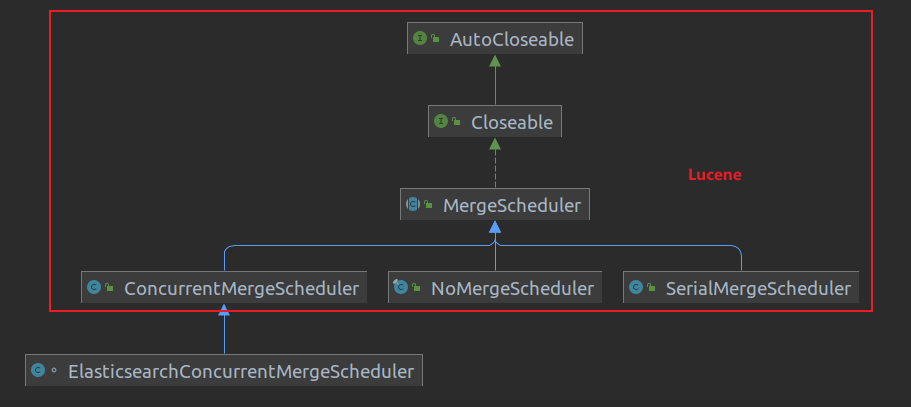
ElasticsearchConcurrentMergeScheduler 继承自Lucene中的ConcurrentMergeScheduler。
4、ConcurrentMergeScheduler 分析
当合并策略(默认为TieredMergePolicy)得到一些待合并的段(n个OneMerge, OneMerge 提供执行单个原始合并操作所需的信息,从而生成单个新段。合并规范包括要合并的段的子集以及新段是否应使用复合文件格式)之后,就会交给MergeScheduler去执行合并,Merge有三个子类,默认为ConcurrentMergeScheduler。
NoMergeScheduler : 并不会执行合并。
SerialMergeScheduler:indexWriter在执行调用merge的时候会updatePendingMerges,这个函数中会从合并策略中获取到OneMerge,然后通过registerMerge加入到pendingMerges列表当中,既然是串行,那么这个会从这个列表中逐个拿出OneMeger进行合并,业务中可能一个indexWriter会被多个线程持有并触发merge,SerialMergeScheduler的meger上加上了synchronized来保证顺序性。
@Override synchronized public void merge(MergeSource mergeSource, MergeTrigger trigger) throws IOException { while(true) { MergePolicy.OneMerge merge = mergeSource.getNextMerge(); if (merge == null) { break; } mergeSource.merge(merge); } }ConcurrentMergeScheduler:顾名思义,是并行的,本文侧重分析ConcurrentMergeScheduler的执行流程和细节。
他可以指定同时运行的最大线程数以及同时合并的最大数量。如果合并数量超过最大线程数,则最大的合并将暂停,直到较小的合并之一完成。如果请求的合并次数超过最大合并数量,则该类将通过暂停来强制限制传入线程,直到又有一次合并完成。
4.1 ConcurrentMergeScheduler 基类 MergeScheduler
这个抽象类的逻辑都在内部接口中。
4.1.1 内部接口MergeSoure
这个接口提供新的merge并执行具体的merge,在Lucene 8.11.2中,只有唯一实现org.apache.lucene.index.IndexWriter.IndexWriterMergeSource。简单分析一下IndexWriterMergeSource的重要方法。
getNextMerge:获取下一个需要Merge,具体会从IndexWriter的pendingMerges中获取到OneMerge
onMergeFinished:merge完成时的回调,调用org.apache.lucene.index.IndexWriter#mergeFinish, 后文分析
merge :执行merge,调用org.apache.lucene.index.IndexWriter#merge, 其实merge的逻辑是由这个来实现的,之后的文章会再做分析
hasPendingMerges:是否还有需要待合并的merge
4.2 重要属性
4.2.1 mergeThreads && maxThreadCount && maxMergeCount
protected final List<MergeThread> mergeThreads // 保存每个merge线性的列表
private int maxThreadCount = AUTO_DETECT_MERGES_AND_THREADS;
private int maxMergeCount // 最大合并数,实际上,这个是才是最大并发的mergeThread数启动的时候,会判断是否为ssd硬盘:
如果是的话,maxThreadCount为max(1, min(4, cpuCoreCount/2))
(linux环境下才有这些逻辑,windows直接认为非ssd)
否则,设置为1
默认情况下, maxMergeCount = maxThreadCount + 5
💡 注: 1.可通过这个方法org.apache.lucene.index.ConcurrentMergeScheduler#setMaxMergesAndThreads设置MaxMergesCounter和MaxThreadCount,从而不进行动态生成。2.是否创建新的mergeThread是看当前的线程和maxMergeCount 比较的, 所以实际上,最大的运行线程数是maxMergeCount。判断逻辑在org.apache.lucene.index.ConcurrentMergeScheduler#maybeStall中的mergeThreadCount() >= maxMergeCount
3.既然maxMergeCount控制着线程数,那么maxThreadCount 到底起什么作用呢?maxThreadCount 控制同时进行merge的最大线程数,在updateMergeThreads的时候会控制大于maxThreadCount的线程速率为0
4.2.3 限流相关
doAutoIOThrottle
是否需要对每个mergeThread进行限流,默认true
MIN_MERGE_MB_PER_SEC
默认5M, 当有限流的时候,最少也会写5M每s
MAX_MERGE_MB_PER_SEC
默认10G, 当有限流的时候,最大会写10GB每s
当由IndexWriter shutdown触发的merge的时候,限流将变成MAX_MERGE_MB_PER_SEC
START_MB_PER_SEC
初始化限流大小,20MB
targetMBPerSec
当前的IO限流大小, 一开始等于START_MB_PER_SEC, 之后会变化,具体变化见下文。
MIN_BIG_MERGE_MB
默认50MB,当OneMerge的预估大小小于50MB,则不会进行先限流,因为本身这个IO也很小。
当OneMerge的预估大小大于等于50MB,则会认定为是一个“大”的merge。
forceMergeMBPerSec
对于forceMerge的限制字节大小阈值,默认是Double.POSITIVE_INFINITY; 可以说是没限制。
4.3 merge 执行流程分析
具体的实现在:org.apache.lucene.index.ConcurrentMergeScheduler#merge
4.3.1 触发 merge
在org.apache.lucene.index.MergeTrigger 中定义好几种触发merge的方式:
SEGMENT_FLUSH
当一个索引段被刷新时触发合并。
FULL_FLUSH
当进行全量FLUSH, 全量刷新可以由提交操作、NRT(Near Real-Time)读取器的重启,或者IndexWriter的shutdown操作引起。
EXPLICIT
当用户显式地触发合并操作时,如调用特定的合并方法。用户可以根据需要手动触发合并以优化索引。
MERGE_FINISHED
当一个合并操作成功完成后触发合并。
CLOSING
IndexWriter的shutdown操作引起的,shutdown的时候会调用org.apache.lucene.index.IndexWriter#waitForMerges等待所有的挂起的合并进行合并,实际上IndexWriter会执行很多操作,包括
flush ,也会引起merge
waitForMerges , 引起merge
commit, 也会引起merge
COMMIT
由commit提交触发merge
GET_READER
在打开 NRT 读取器(Near Real-Time)时触发合并。org.apache.lucene.index.IndexWriter#getReader(boolean, boolean)
NRT 读取器是一种允许在索引写入的同时,不需要执行IndexWriter close或调用commit 也可以做到近实时搜索,但是也不是绝对实时,具体时间有多种因素影响
这些在深入分析ES的flush, refresh等具体细节流程中还会再提到,我们这里暂时只看Lucene的merge调度执行流程。
第一步:判断是否是CLOSE类型的merge
如果是,需要放开限流,即targetMBPerSec = MAX_MERGE_MB_PER_SEC;
第二步:死循环不断处理OneMerge
不断从pendingMerges列表中获取OneMerge,
判断是否需要开启一个新的merger线程
如果pendingMerges列表不为空,并且当前的mergeThreadCount大于maxMergeCount,则一直不断wait 0.25秒进行等待,否则就可以创建一个新的mergeThread
当能开启新线程的时候,
会新建一个MergeThread 并执行当前merge线程的限流:updateIOThrottle 流程,
MergeThread启动之后,再执行updateMergeThreads 流程,更新所有的merge线程的限流
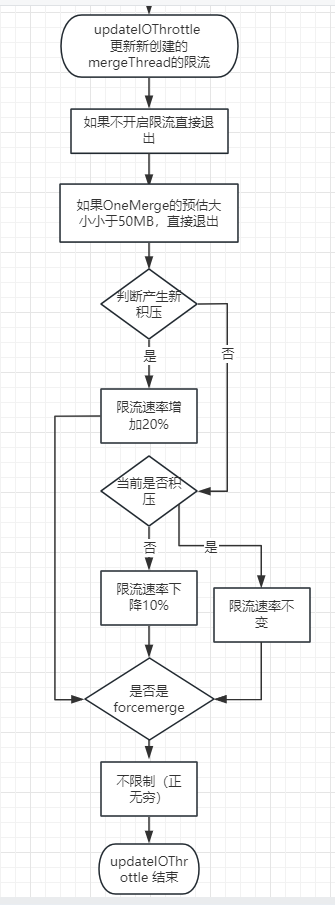
updateIOThrottle 流程如下
当一个新的mergeThread创建的时候,需要更新其的IO限流
具体的执行流程为:
如果doAutoIOThrottle 为false,则退出
如果OneMerge的预估大小小于50MB,直接退出,因为这个预估大小合并的起来IO本身就很小,那就不会限制速率。
简单的闭环反馈控制:如果我们发现任何其他类似的大小的合并正在运行,就表示我们落后了,所以提高 IO 速率,否则我们降低它。
a. 有一个当前是否有积压curBacklog和是否产生新积压newBacklog。
b. 判断是否产生新积压,获取到其他活跃的mergeThead,只要有一条mergeThread 运行已经超过3s并且预估大小超出50MB并且他的预估大小在我的30%到300%之间,是则认为产生新积压。
-
当产生了新积压——限流速率增加20%。
当没有产生新积压并且当前有积压,限流速率不变newMBPerSec = targetMBPerSec;判断是否当前有积压,判断逻辑和上面一样,另外如果mergeThreads的数量大于maxThreadCount则认定为当前有积压。
如果既没有新积压,当前也没积压,则限流速率减少10%。
判断是否是forcemerge,如果是则使用forceMergeMBPerSec 的限制,否则就用上面计算出的限流,应用到MergeeRateLimiter中(后文详细分析)
💡 其实在这段逻辑中, 完全可以先判断是否是forcemerge, 不需要先判断是否是积压,因为forcemerge会覆盖之前的限流速率判断。整体流程如下:
其实这样的一个逻辑,在32C、Elasticsearch默认的配置下:
index.merge.scheduler.max_thread_count是4
index.merge.scheduler.max_merge_count是9
index.merge.scheduler.auto_throttle为true
会导致限流不断下降,最终稳定在一个平稳值,可以看到下图中的test-2023-08-25中的三个分片的限流速率先后降低到5M。
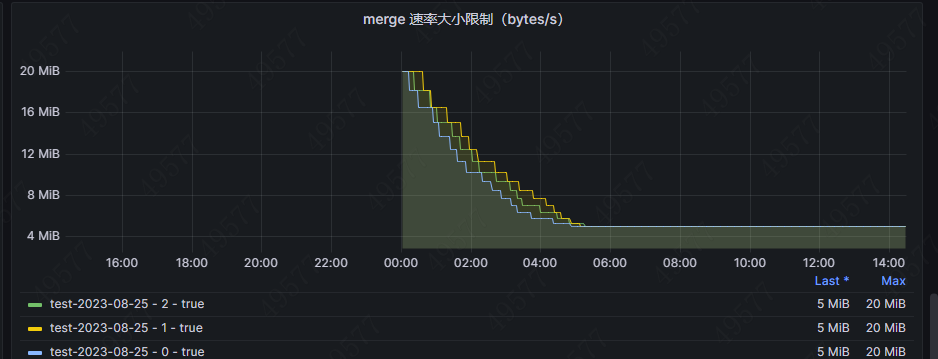
将index.merge.scheduler.max_thread_count(官方推荐非SSD, 设置为1)和index.merge.scheduler.max_merge_count都设置成1, 也同样会存在速率下降,因为前几次的merge必定满足没有新积压和当前没积压的情况。
其实如果能开放START_MB_PER_SEC和MIN_BIG_MERGE_MB的配置会更好:
START_MB_PER_SEC
灵活统一配置初始值,默认是20MB,感觉有点小,如果可以动态配置就可以更好地控制暂停时间,调节磁盘吞吐大小
MIN_BIG_MERGE_MB
小于这个就不限制啦,默认50MB,感觉50MB有点小
第三步:启动merge线程 && 更新所有的merge线程的IO限流
开启一个新线程去执行merge,这个归属到IndexWriter中merge中去完成,会在后续的文章中详细分析。
newMergeThread.start();
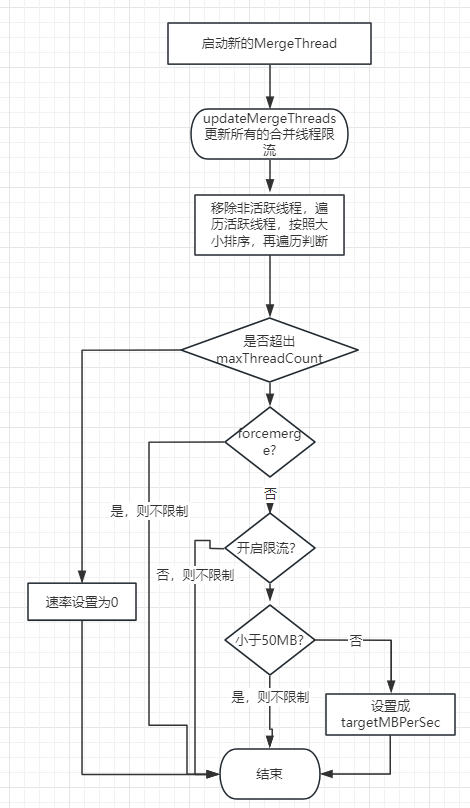
updateMergeThreads();updateMergeThreads 流程如下
每当正在运行的合并发生更改时调用,以设置合并 IO 限制。此处的更改是指:
MergeThread的增加或者减少
每个merge 的 IO 限流发生变更(包含forceMerge的限流配置,限流的开关)
indexWriter的shutdown, 触发MergeTrigger.CLOSING类型的merge, 将会把限流调整到MAX_MERGE_MB_PER_SEC,相当于不限制
此方法按合并大小按降序对合并线程进行排序,然后从第一个到最后一个暂停/取消暂停线程,这样可以保证较小的合并在较大的合并之前运行。
具体的执行流程如下:
对活跃的mergeThread线程的estimatedMergeBytes进行排序得到排序列表,在这个过程中顺便清理掉非活跃的线程
计算“大”merge线程的数量(判断依据就是看是否大于等于MIN_BIG_MERGE_MB)
从头循环遍历活跃的合并线程:对于每个合并线程,根据不同的条件来计算新的 IO 速率限制newMBPerSec,并设置到对应mergeThread中的rateLimiter对象中
其序号大于maxThreadCount,则停止merge,速率设置为0 (如果设置为0,那就是STOP了, 从ES的监控来看就是total_stopped_time_in_millis会增加)
如果是forcemerge,则不限制
如果doAutoIOThrottle=false, 则不限制
如果merge不是”大”merge线程,则不限制
其他情况速率 newMBPerSec = targetMBPerSec; 这边不一定是不变的,因为在上一个函数updateIOThrottle中是可能会改变targetMBPerSec的。
整体流程如下:
5、MergeRateLimiter 的限流控制
5.1 merge的进度管理
每一个MergeThread都有对应的MergeRatelimiter, 而MergeRatelimiter都持有OneMerge的OneMergeProgress, MergeRateLimiter 主要是通过OneMergeProgress 来进行暂停、恢复合并线程,或者完全中止合并的。这有助于对合并操作的执行进行更好的控制和管理。
暂停的原因是一个枚举,有以下值:
STOPPED
速率被设置成0了。关于什么时候设置成0,可以看上面的updateMergeThreads 逻辑
PAUSED
速率超过限制,临时暂停
OTHER
其他原因
OneMergeProgress 对每种原因的暂停都有一个AtomicLong去计数。
private final ReentrantLock pauseLock = new ReentrantLock();
private final Condition pausing = pauseLock.newCondition();这两个变量控制暂停以及恢复,先看核心方法暂停:org.apache.lucene.index.MergePolicy.OneMergeProgress#pauseNanos, 从这个方法看出,无论是哪种原因,都是挂起当前线程,
// 暂停当前线程pauseNanos时间,直到满足某些条件
public void pauseNanos(long pauseNanos, PauseReason reason, BooleanSupplier condition) throws InterruptedException {
// 判断线程归属
// ...
long start = System.nanoTime();
AtomicLong timeUpdate = pauseTimesNS.get(reason);
pauseLock.lock();
try {
while (pauseNanos > 0 && !aborted && condition.getAsBoolean()) {
pauseNanos = pausing.awaitNanos(pauseNanos);
}
} finally {
pauseLock.unlock();
// 当被唤醒,或者中止等情况就结束暂停,记录时间
timeUpdate.addAndGet(System.nanoTime() - start);
}
}恢复方法就很简单了。
public void wakeup() {
pauseLock.lock();
try {
pausing.signalAll(); // 唤醒暂停
} finally {
pauseLock.unlock();
}
}5.2 流控逻辑
在单个线程的updateIOThrottle 以及所有线程的updateMergeThreads 方法中,都会去调用org.apache.lucene.index.MergeRateLimiter#setMBPerSec
在这个函数中会设置一个minPauseCheckBytes, 只有写的增量大于minPauseCheckBytes(Math.min(10241024, (long) ((25 / 1000.0) * 设置的速率 1024 * 1024)), 最多写入超过1G会进行一次检测)的时候才会去做是否暂停的尝试
org.apache.lucene.store.RateLimitedIndexOutput#checkRate:
@Override
public void writeBytes(byte[] b, int offset, int length) throws IOException {
bytesSinceLastPause += length;
checkRate();
delegate.writeBytes(b, offset, length);
}
private void checkRate() throws IOException {
if (bytesSinceLastPause > currentMinPauseCheckBytes) {
rateLimiter.pause(bytesSinceLastPause);
bytesSinceLastPause = 0;
currentMinPauseCheckBytes = rateLimiter.getMinPauseCheckBytes();
}
}接下来关注暂停的判定:这块maybePause的函数中的变量名有点歧义,第一次看,可能会懵逼,我详细解释一下:
@Override
public long pause(long bytes) throws MergePolicy.MergeAbortedException {
totalBytesWritten.addAndGet(bytes);
long paused = 0;
long delta;
// 只要maybePause 返回>0 则需要暂停
while ((delta = maybePause(bytes, System.nanoTime())) >= 0) {
paused += delta;
}
return paused;
}
private long maybePause(long bytes, long curNS) throws MergePolicy.MergeAbortedException {
double rate = mbPerSec; // read from volatile rate once.
// 这次写bytes字节需要耗时多少s
double secondsToPause = (bytes/1024./1024.) / rate;
// 我需要花费secondsToPause,lastNS 可以简单认为是上次写入时间,上次写入时间 + 这次需要花费的时间
long targetNS = lastNS + (long) (1000000000 * secondsToPause);
long curPauseNS = targetNS - curNS;
// 第一次进入这个函数,lastNS 是为0的,所以必然targetNS < MIN_PAUSE_NS
// 这个时候就记录一下时间,curNS是System.nanoTime(), 由于pause调用完就调用write写入,所以可以认为为这个是上一次写入时间
// 当pause中不断调用maybePause的时候,最后一次,调用的时候,肯定会走到这里来,也将lastNS 设置成了curNS
if (curPauseNS <= MIN_PAUSE_NS) {
lastNS = curNS;
return -1;
}
if (curPauseNS > MAX_PAUSE_NS) {
curPauseNS = MAX_PAUSE_NS;
}
long start = System.nanoTime();
try {
mergeProgress.pauseNanos(
curPauseNS,
rate == 0.0 ? PauseReason.STOPPED : PauseReason.PAUSED,
() -> rate == mbPerSec);
} catch (InterruptedException ie) {
throw new ThreadInterruptedException(ie);
}
return System.nanoTime() - start;
}一开始感觉这个算法有点问题, 不应该根据这次的字节大小去等待,应该使用上一次的字节写入去等待才行。比如下面的程序
MergeRateLimiter rateLimiter = new MergeRateLimiter(new MergePolicy.OneMergeProgress());
rateLimiter.setMBPerSec(10);
LocalTime currentTime = LocalTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("HH:mm:ss");
String formattedTime = currentTime.format(formatter);
System.out.println("Current time: " + formattedTime);
rateLimiter.pause(1024* 1024* 1024);
currentTime = LocalTime.now();
formattedTime = currentTime.format(formatter);
System.out.println("Current time: " + formattedTime);
rateLimiter.pause(1024* 1024* 1024);
currentTime = LocalTime.now();
formattedTime = currentTime.format(formatter);
System.out.println("Current time: " + formattedTime);打印为:从结果看出来,102s,我放走了2G的流量,其实是20MB每秒,并非10MB,
Current time: 19:18:53
Current time: 19:18:53
Current time: 19:20:35假设我第一次写入是1024字节,第二次去写1G数据的时候,我依旧会暂停102s, 这个就差不多10MB每s,
假设我第一次写入是1024字节,第二次去写1G数据,之后的N次都是10.2MB(2ms之内不暂停) ,N+1次是1G,那么从整体来看,随着时间的推移,整体速率会比较趋近于10MB
小结一下:
何时暂停?暂停多久
第一次进入pause函数必定不会暂停,但是会记录上一次写入的时间戳每次写超出速率的大小就基本都会等待
等待(上次写入时间戳 + 这次需要花费的时间(字节/rate) - 当前时间戳 )
如果小于2ms则不等待
如果大于250ms则拆分成每个250ms等待
这里的限流并不是类似消息队列的削峰填谷的平滑限流,这个限流只能保证较长的时间段是能趋近于设置的速率,可能还是会有IO突刺。
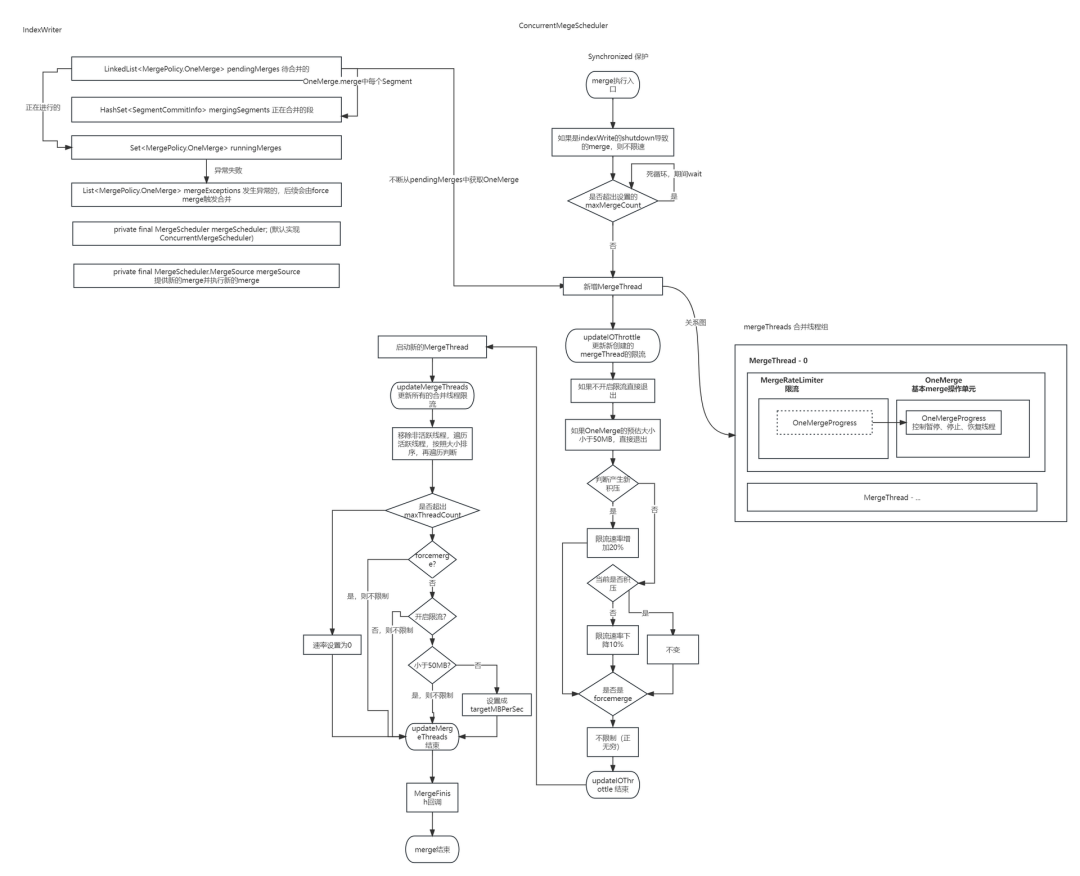
6、整体逻辑图
本文的最后再从几个方面思考优化merge的手段。
7、merge 优化手段思考
7.1 调度方面
这一块能给我们调节的地方很有限:
| Elasticsearch配置(都是索引级别动态) | ES 默认值 | 对应Lucene配置(变量) | Lucene 默认值 | 最佳实践&说明 |
|---|---|---|---|---|
| index.merge.scheduler.max_thread_count | Math.max(1, Math.min(4, EsExecutors.allocatedProcessors(s) / 2)) | maxThreadCount | 1. 非ssd或者windows就是1; 2.否则 max(1, min(4, cpuCoreCount/2)) | 控制同时进行merge的mergeThread线程数; EsExecutors.allocatedProcessors(s)的返回: 1.node.processors 配置(一般是不会配置的,除非ES和其他组件混合部署,或者多个ES在同一个机器) 2.没有上面的配置就返回 Runtime.getRuntime().availableProcessors() 无论是ES官方还是Lucene官方都建议非SSD修改成1 :https://www.elastic.co/guide/en/elasticsearch/reference/7.10/index-modules-merge.html |
| index.merge.scheduler.max_merge_count | max_thread_count + 5 | maxMergeCount | maxThreadCount + 5 | 控制同时存在的活跃mergeThread线程数 |
| index.merge.scheduler.auto_throttle | true | doAutoIOThrottle | true | 是否开启自动限流 |
7.2 段生成方面
减少refresh频率
refresh interval 调整大点,业务场景允许就可以设置成分钟级别
增大indices.memory.index_buffer_size
尽量减少文档更新
并不是每次文档更新都会去refresh,其中引入了安全和不安全的version map来减少refresh次数,具体可看#19813
7.3 mergePolicy方面 && forcemerge
见:从源码角度剖析 Elasticserach 段合并调优策略
8、总结
每个Elasticserach分片都有独立的一套ConcurrentMergeScheduler, 限流的原因是因为当前要合并的段大小超出速率,因此导致限流时间增加,官方提供的参数不足以灵活控制速率进而控制限流耗时;但是我们更多的可以从段生成、段合并策略以及forcemerge的角度去优化。
9、作者简介
He Chengbo,互联网安全独角兽公司资深工程师,死磕 Elasticsearch 星球资深活跃技术专家。
在此,感谢铭毅老师提供这个宝贵的平台发表文章,也感谢您给予的指导和鼓励!
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事
从源码角度剖析 Elasticserach 段合并调优策略

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

一个人可以走得很快,但一群人走得更远!
![[html]当网站搭建、维护的时候,你会放个什么界面?](https://img-blog.csdnimg.cn/c12ae3d45dd1423aa5c06d1eeaef9bd6.png)