一、AFL简介
AFL(American Fuzzy Lop)号称是当前最高级的Fuzzing 测试工具之一
,是由安全研究员Michał Zalewski(@lcamtuf)开发的一款
基于覆盖引导(Coverage-guided)的
模糊测试工具,它
通过记录输入样本的代码覆盖率,从而调整输入样本以提高覆盖率,增加发现漏洞的概率。
AFL 采用新型的
编译时插桩和
遗传算法自动发现新的测试用例,这些用例会触发目标
二进制文件中的新内部状态。这大大改善了模糊测试的代码覆盖范围。
AFL既可以对源码进行编译时插桩,也可以使用AFL的QEMU mode对二进制文件进行插桩,但是前者的效率相对来说要高很多。
AFL的
优点是可以轻松部署,配置相对简单,测试效率相对较高。
原生的AFL仅适配于C/C++程序的测试,不过目前已经衍生出很多分支,用于适配其他语言的模糊测试,如针对JAVA程序的Kelinci等
。
其
工作流程大致如下:
①从源码编译程序时进行插桩,以记录代码覆盖率(Code Coverage);
②选择一些输入文件,作为初始测试集加入输入队列(queue);
③将队列中的文件按一定的策略进行“突变”;
④如果经过变异文件更新了覆盖范围,则将其保留添加到队列中;
⑤上述过程会一直循环进行,期间触发了crash的文件会被记录下来。
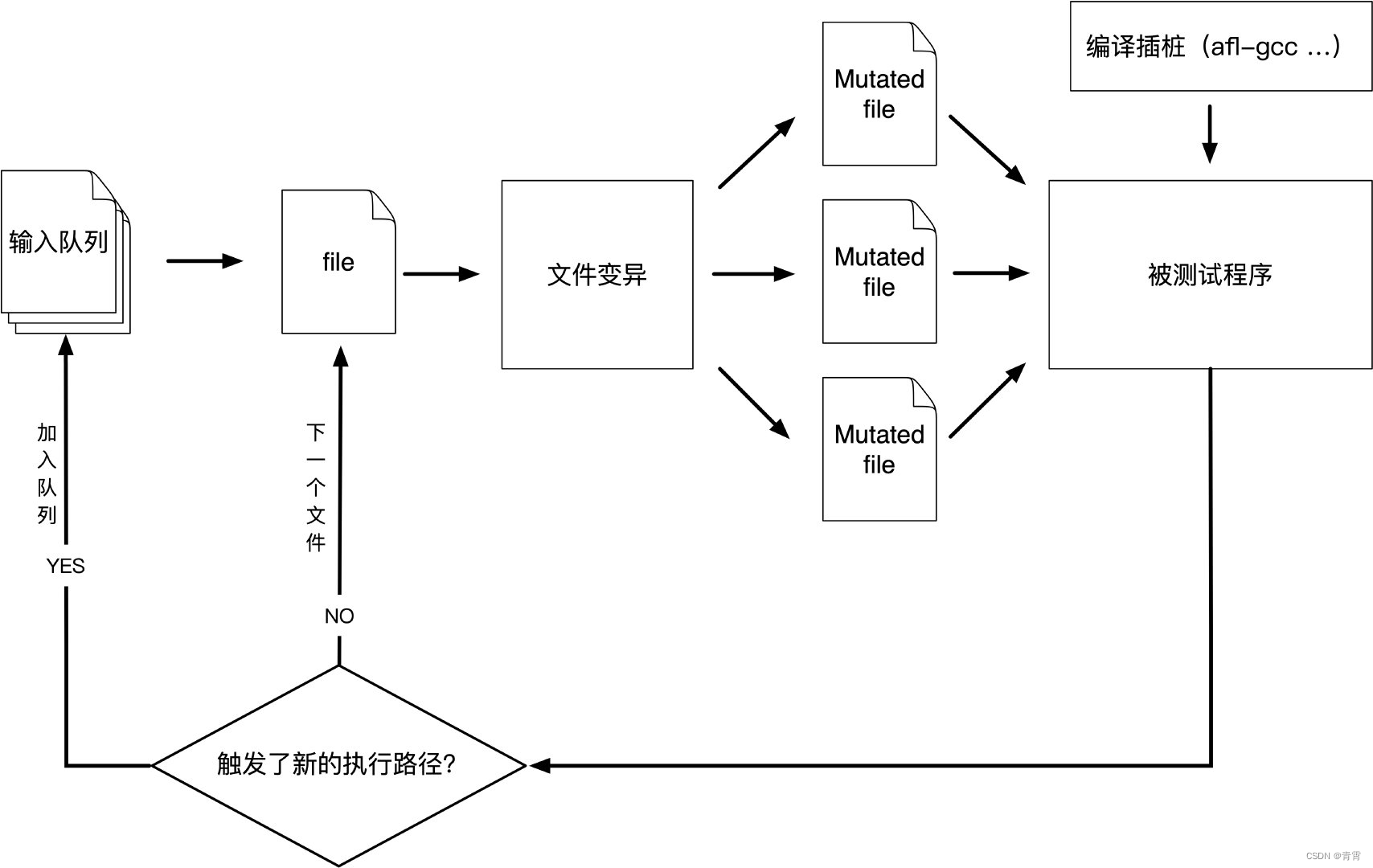
AFL变异的方式
AFL是采用遗传算法,基于变异生成的测试用例,变异的主要类型有下面这几种:
二、AFL安装和使用
利用AFL进行模糊测试的大概
过程:①插桩编译;②设置种子测试用例;③开始fuzz
。模糊测试对于软件测试的帮助很大,其不受限于被测系统的内部实现细节和复杂程度。
2.1、安装
AFL 自带定制版本的 gcc 和 clang 编译器,建议选择 LLVM 的 clang 编译器,可以加快 fuzz 的速度。
下载AFL源码(
GitHub - google/AFL: american fuzzy lop - a security-oriented fuzzer),解压后,编译安装:
AFL使用afl-gcc编译
:
make
sudo make install
#
安装到系统目录
AFL使用afl-clang编译
:
cd llvm_mode
make
cd ..
sudo make install
查看路径可以看到afl安装的文件:

作用分别为
-
afl-gcc 和afl-g++ 分别对应的是gcc 和g++ 的封装
-
afl-clang 和afl-clang++ 分别对应clang 的c 和c++ 编译器封装À。
-
afl-fuzz 是AFL 的主体,用于对目标程序进行fuzz。
-
afl-analyze 可以对用例进行分析,通过分析给定的用例,看能否发现用例中有意义的字段。
-
afl-qemu-trace 用于qemu-mode ,默认不安装 ,需要手工执行qemu-mode 的编译脚本进行编译,后面会介绍。
-
afl-plot 生成测试任务的状态图
-
afl-tmin 和afl-cmin 对用例进行简化
-
afl-whatsup 用于查看fuzz 任务的状态
-
afl-gotcpu 用于查看当前CPU 状态
-
afl-showmap 用于对单个用例进行执行路径跟踪
afl-fuzz指令:
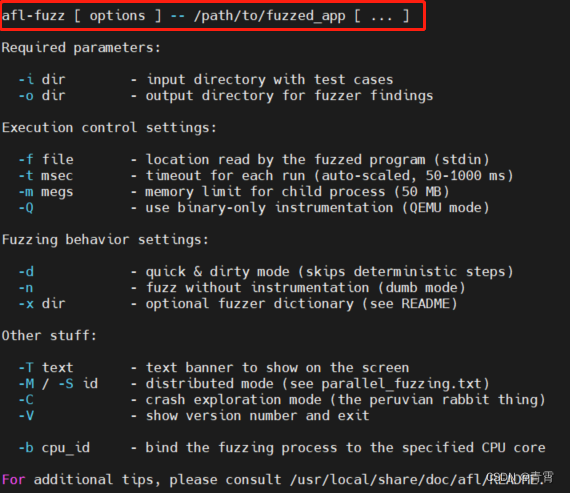
下面我们进行一个简单的AFL实验了解其使用流程。
2.2、准备被测程序
首先创建一个简单的test.c源文件,里面放入我们要测的c程序。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <signal.h>
int AFLTest(char *str)
{
int len = strlen(str);
if(str[0] == 'A' && len == 6)
{
raise(SIGSEGV);
//如果输入的字符串的首字符为A并且长度为6,则异常退出
}
else if(str[0] == 'F' && len == 16)
{
raise(SIGSEGV);
//如果输入的字符串的首字符为F并且长度为16,则异常退出
}
else if(str[0] == 'L' && len == 66)
{
raise(SIGSEGV);
//如果输入的字符串的首字符为F并且长度为66,则异常退出
}
else
{
printf("it is good!\n");
}
return 0;
}
int main(int argc, char *argv[])
{
char buf[100]={0};
gets(buf);
//存在栈溢出漏洞
printf(buf);
//存在格式化字符串漏洞
AFLTest(buf);
return 0;
}2.3、使用 afl-gcc 插桩编译
(编译插桩是指在代码编译期间修改或新增代码)
用 AFL 编译目标源码,其目的在于插桩,让编译得到的程序,反馈路径覆盖。AFL 自带定制版本的 gcc 和 clang 编译器,建议选择 LLVM 的 clang 编译器,可以加快 fuzz 的速度。
编译过程和普通gcc编译也是一样,除了使用的命令需要带上afl-前缀,因此
afl-gcc -g -o test
test.c
# 针对c文件,
-g选项为使用gdb调试所需,如果不调试就不需加此选项。
在linux下编译链接程序,如果不加-o参数,生成的binary代码的名字都是默认的a.out
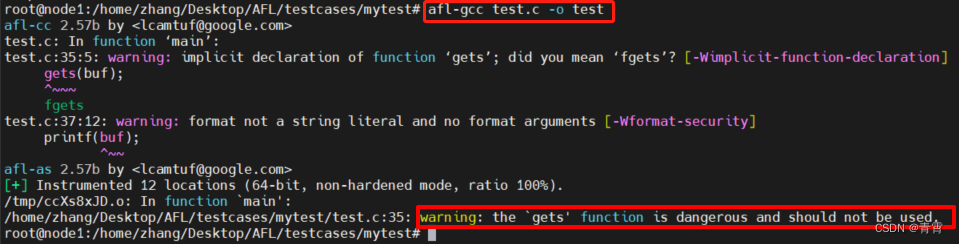
可以看到在编译过程中,编译器已经提示存在漏洞,不理会,用AFL去测试
。
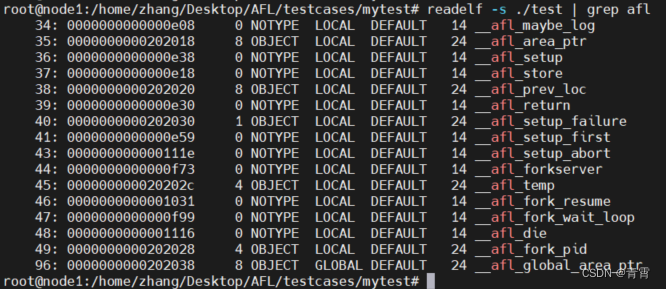
编译后会有插桩符号,使用下面的命令可以验证这一点:
readelf -s ./test | grep afl
注:
针对c++文件,则使用
afl-g++ -g -o test
test.cpp
注意在编译项目时,通常有Makefile,这是就需要在Makefile中添加内容: gcc/g++重新编译程序的方法是:
CC=/path/to/afl/afl-gcc ./configure
make clean all
对于一个C++程序,要设置:
CXX=/path/to/afl/afl-g++.
afl-clang和afl-clang++的使用方法类似。
2.4、准备种子语料库
2.4.1、搜集种子语料库
作为模糊测试,AFL需要提供初始的种子输入,
变异算法会根据此种子变异生成各种测试用例,喂给程序。但实际上,你完全可以提供任何无意义的输入作为种子,模糊测试也一般能达到效果,只不过效率会低一些而已,是否提供有意义种子?提供多少?无外乎在种子获取难度和测试的效率要求之间进行权衡而已。
这里,借用 Freebuf 提供的资料,给出一些开源的语料库
-
libav sample s
-
ffmpeg samples
-
fuzzdata
-
moonshine
-
afl generated image test sets
-
fuzzer-test-suite
事实上很多程序也会自带一些案例,也可以作为测试用例。
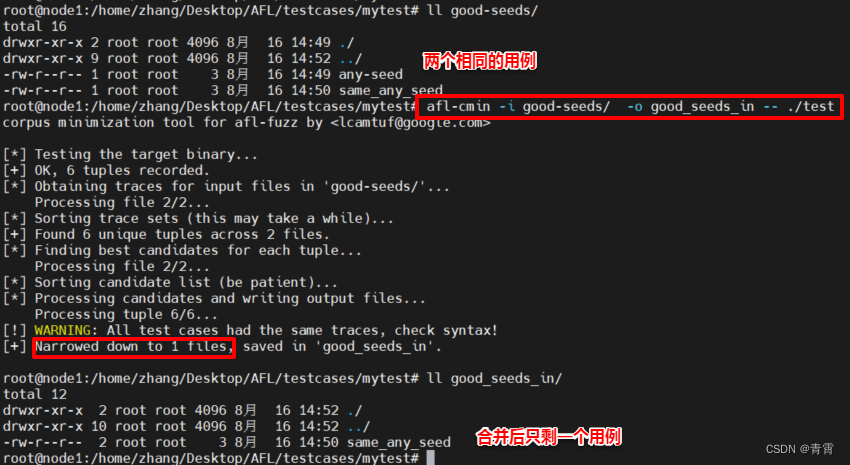
在这里我们生成一好一坏两个种子语料库:
mkdir good-seeds bad-seeds
echo '1+1' > good-seeds/any-seed
echo 'this is a bad seed' > bad-seeds/any-seed
2.4.2、精简语料库
找到语料库之后,最好能够进行修剪,
合并重复用例,裁剪体积。
afl 推荐的每个用例体积小于 1KB,不然会影响 fuzz 的效率。
2.4.2.1、去重
afl-cmin 可以精简语料库,去掉可能重复的测试用例,可大大减少无用的 fuzz 用例
afl-cmin -i input_dir -o output_dir -- /path/to/tested/program [params]
更多的时候,我们是从文件中获取输入,因此,往往使用 @@ 替代 params(参数),即
afl-cmin -i input_dir -o output_dir -- /path/to/tested/program @@
2.4.2.2、裁剪体积
afl-tmin
可以缩短文件体积,因为
afl 要求测试用例的大小最好小于 1KB
,因此最好将精简后的用例进一步缩小体积。afl-tmin 有两种工作模式,
instrumented mode
和
crash mode
。默认的工作方式是instrumented mode
afl-tmin -i input_file -o output_file -- /path/to/tested/program [params] @@
由于 afl-cmin 一次性只能精简单个文件,如果用例特别多,需要手动花费很长时间,其实一条简单的 shell 脚本即可完成
for i in *; do afl-tmin -i $i -o tmin-$i -- ~/path/to/tested/program [params] @@; done;
2.5、开始测试
在执行afl-fuzz前,如果系统配置为将核心转储文件(core)通知发送到外部程序,将导致将崩溃信息发送到Fuzzer之间的延迟增大,进而可能将崩溃被误报为超时,所以我们得临时修改core_pattern文件:
echo core >/proc/sys/kernel/core_pattern
对于可以直接从stdin读取输入的目标程序来说,执行命令,
afl-fuzz
-i good-seeds/ -o good-outputs -- ./test
对从文件读取输入的目标程序来说,要用“@@”:
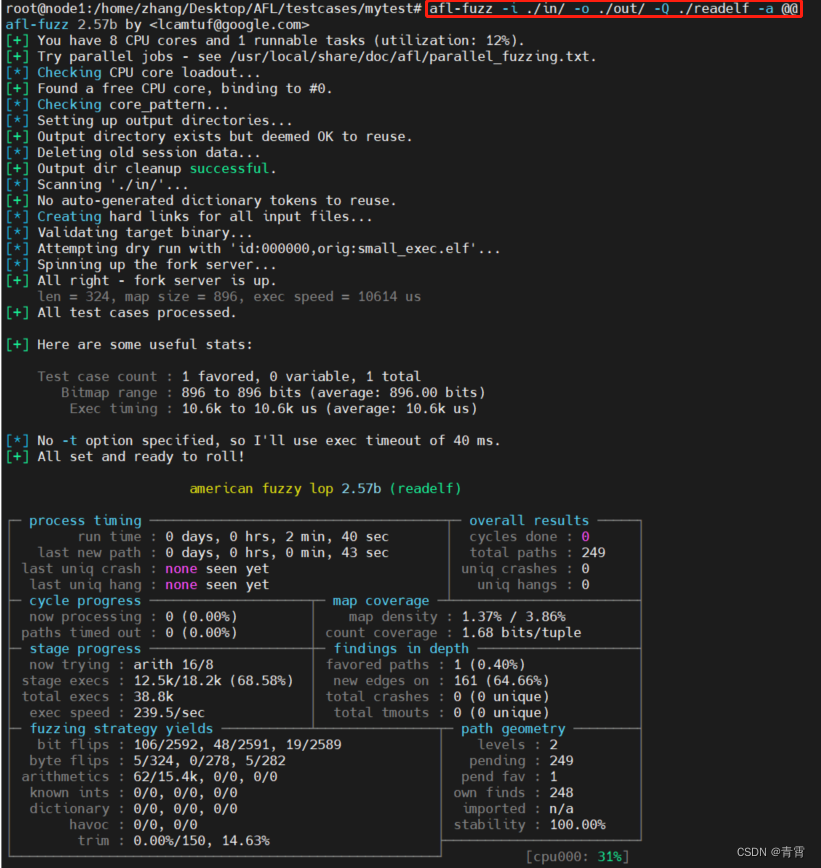
afl-fuzz -i ./in/ -o ./out/ -Q ./readelf -a @@
# 开始fuzz,
@@表示从in
文件夹中找elf作为输入
,实际上是在执行readelf -a 文件名

ctrl-C结束fuzz,共找到了6个crash,可以看到当前目录下已经多出了good-outputs目录,这是本次模糊测试的结果。
process timing:展示的是fuzzer的运行时间,也可以看到最近一次发现新路径的时间,最近一次崩溃的时间和最近一次挂起的时间。

overall result:运行的总周期数,总路径数,崩溃次数和挂起次数

cycle progress:fuzzer正在处理的测试样例的编号和由于超时放弃的的输入数量,从而得知fuzzer处理了多少样例,队列中还剩多少
map coverage:
第一行显示的是已经命中了多少分支元组与位图可以容纳的数量的比例。左边的是当前输入,右边的是整个输入语料库的值。
第二行显示的是二进制文件中元组命中计数的变化,如果对于所有尝试的输入,每个采用的分支都采用固定的次数。读数显示为1.00, 当设法触发每个分支的其他命中计数时,读数向8.00移动(8位映射命中每一位),但可能永远不会到达极限。
这些值可以用于比较不同的模糊测试对于同一检测二进制文件的覆盖范围。
stage progress:显示了正在测试的策略(AFL变异方式),进度,总执行次数和执行速度。一般正常的执行速度应该在500以上。
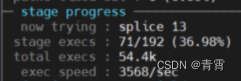
findings in depth:
这一部分的数据对一般的使用者用处不大,包括基于应用到代码的最小化算法获得的fuzzer最喜欢的路径数和真正获取更好的边缘覆盖率的测试用例数,还有超时和崩溃的计数器,注意这里的timeout和hang有所不同,timeout计数器包括了所有超过超时的测试用例,即使它们没有超过超时足够的幅度而分类为hangs(挂起)
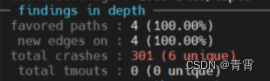
fuzzing strategy yields:用于追踪各种fuzzing策略所获得的路径和尝试执行的次数的比例,用于验证各种方法的有效性。
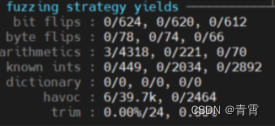
path geometry:
第一个数据指的是fuzzing过程中达到的路径深度,通常用户提供的测试用例视为1级,传统模糊测试从中获得的测试用例视为2级,通过它们作为后续模糊测试回合的输入得到的结果为3级,以此类推。
下一个数据pending指的是还有多少输入数据没有经过任何测试。pend fav时指fuzzer在这个队列中真正想到达的条目。接下来的是这个fuzzing部分找到的新路径数量和在进行并行化fuzzing时从其他fuzzer实例导入的路径数量 。
最后一个数据可以衡量观测到痕迹的一致性,如果程序对相同的输入始终表现相同,则为100%,若数值较低但仍然显示为紫色,测试过程不太可能受到负面影响,而显示红色说明出现了问题,afl可能难以区分调整输入文件的有意义的效果和幻象效果
2.6、fuzz结果分析
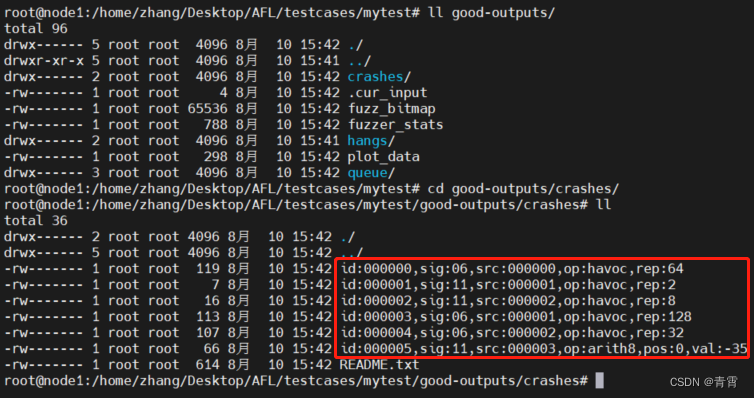
crashes:导致目标接收致命signal而崩溃的独特测试用例
queue:存放所有具有独特执行路径的测试用例。
AFL输出文件:
-
crashes/README.txt:保存了目标执行这些crashes文件的命令行参数。
-
hangs:导致目标超时的独特测试用例。
-
fuzzer_stats:afl-fuzz的运行状态。
-
plot_data:用于afl-plot绘图。
查看第1个crash,发现符合栈溢出漏洞的crash情况(最长输入100字符):

查看第2个crash:发现符合首字符为A且字符串长度为6的异常退出情况:
查看第3个crash:发现符合首字符为F且字符串长度为16的异常退出情况:
查看第4个crash,发现符合栈溢出漏洞的crash情况(最长输入100字符):

查看第5个crash,发现符合栈溢出漏洞的crash情况(最长输入100字符):

查看第6个crash:发现符合输入的字符串的首字符为L并且长度为66的异常退出情况:

AFL编译后的是一个普通的可执行文件,可以直接在命令行使用
./test启动运行,然后此时你需要在终端进行输入,然后又会在终端获得输出:

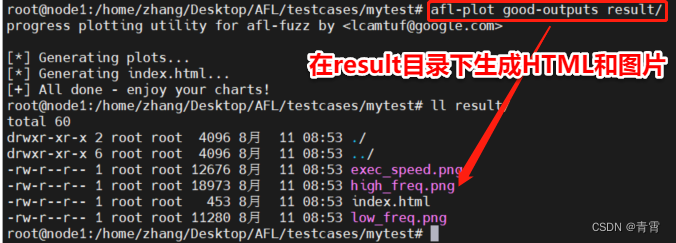
afl-plot 可以绘制更加直观的结果,利用的就是 fuzzer 生成的 plot_data 文件。当然,要使用 afl-plot ,需要先安装
apt-get install gnuplot
三、并行fuzz测试
在使用afl-fuzz时,每个进程只会占用一个CPU核心。如果我们的机器是多核处理器,我们可以通过进行分布式fuzz来提高fuzz速度。
首先先看自己有多少内核:
afl-gotcpu
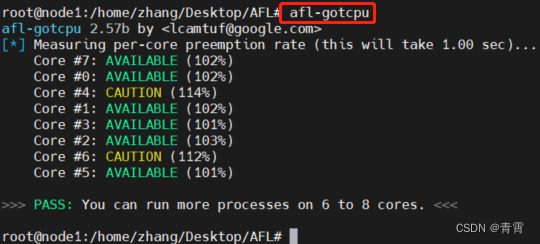
以上可以看出可以运行6~8个实例。
首先指定主实例 -M 用于主实例,将 -S 添加到所有从属实例。注意,
这里-o跟的参数一定要保持一致,这个是用来同步各个fuzz进程的。
-
主实例: afl-fuzz -M master -i good-seeds/ -o good-outputs -m none -- ./test
-
从实例1 : afl-fuzz -S slave1 -i good-seeds/ -o good-outputs -m none -- ./test
-
从实例2: afl-fuzz -S slave2 -i good-seeds/ -o good-outputs -m none -- ./test
若分布式意外退出可以使用以下命令继续fuzz任务:
-
主实例: afl-fuzz -M master -i- -o good-outputs -m none -- ./test
-
从实例1 : afl-fuzz -S slave1 -i- -o good-outputs -m none -- ./test
-
从实例2: afl-fuzz -S slave2 -i- -o good-outputs -m none -- ./test
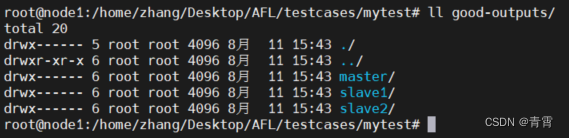
运行后会在good_outputs文件夹会多出三个不同的文件夹master、slave1、slave2:
四、黑盒 fuzz(无源码AFL测试)
以上 fuzz 过程,依赖于我们有程序的源码,并且在编译过程中进行了插桩,但很多时候,我们并
没有源码,这时候就要靠 afl 提供的 qemu_mode 模式了(
只要在之前的命令的基础上加上-Q的参数即可
)。原版本的 afl qemu 模式由于版本过老,已不能正常运行,推荐使用 github 上的
AFLplusplus
或者
afl-unicorn。AFLplusplus 更容易安装,而 afl-unicorn 针对 qemu 模式更加友好。
4.1、qemu_mode模式安装
无论是下载的哪个版本的 afl,根目录下都会有 qemu_mode 文件夹,进入此目录,运行以下脚本,如果没有出错,就代表 qemu_mode 成功了:
cd qemu_mode
sudo ./build_qemu_support.sh
cd ..
make install

安装注意事项:
-
修改build_qemu_support.sh文件中的 QEMU_URL=" https://download.qemu.org/qemu- ${VERSION}.tar.xz",不然提示404
-
参考 我的AFL入门之路 - 知乎 (zhihu.com) ,更改一些配置:
-

4.2、示例
>>> 继续使用上面简单c代码进行测试,但
这次采用gcc进行编译,而不是afl-gcc。将test.c编译为test2:

执行命令:
afl-fuzz -Q -i good-seeds/ -o good-outputs -- ./test2
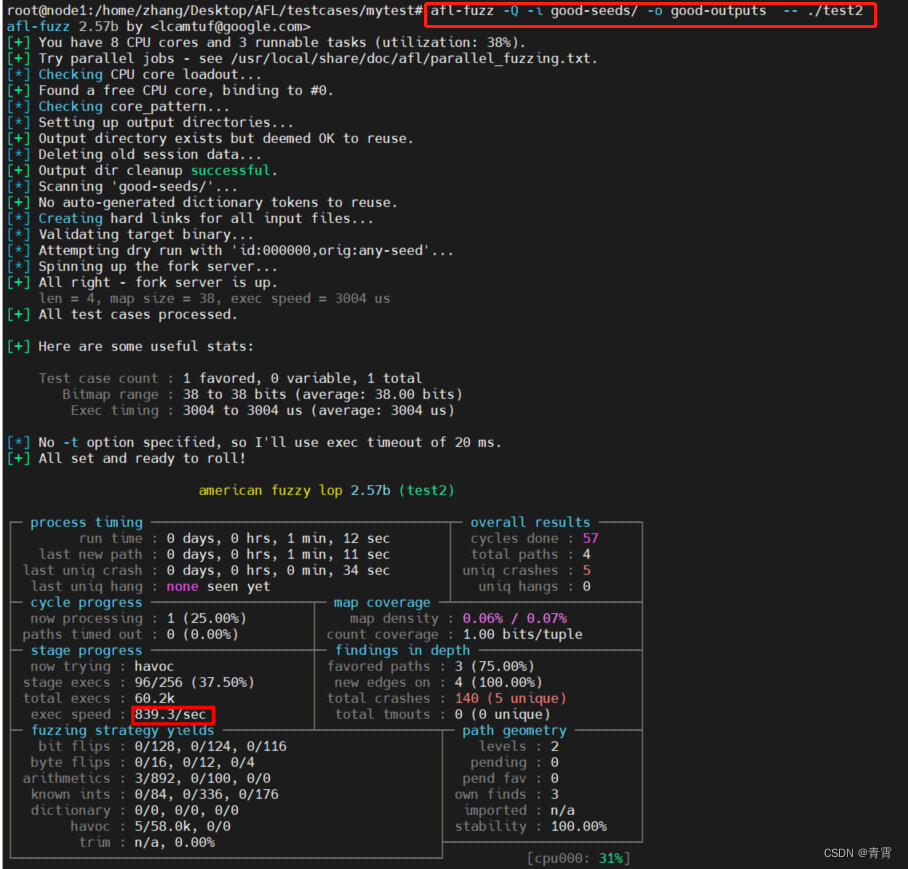
可以看出:同样的程序,在qemu 模式下比在源码编译插桩的模式下会慢很多。(通过观察stage progress下的exec speed)
>>> 一个Fuzz实例
测试readelf。 由于readelf的输入其实就是elf文件,因此需要在in目录下放一个输入elf。 按照流程创建文件夹和测试用的elf。
cd AFL/testcases/mytest
mkdir in out
cd in
cp ../../others/elf/small_exec.elf .
# afl目录中自带一些常用文件的testcase
cd ..
cp /usr/bin/readelf .
# 将readelf复制到mytest
目录下
afl-fuzz -i ./in/ -o ./out/ -Q ./readelf -a @@
#
开始fuzz,@@表示从in文件夹中找elf作为输入,实际上是在执行readelf -a 文件名
五、参考
google/AFL: american fuzzy lop - a security-oriented fuzzer (github.com)
入门AFL | I'm dev (i-m.dev)
我的AFL入门之路 - 知乎 (zhihu.com)
AFL实战_Elwood Ying的博客-CSDN博客
经典 Fuzzer 工具 AFL 模糊测试指南_swift fuzzer工具_江下枫的博客-CSDN博客
模糊测试技术线上分享_哔哩哔哩_bilibili