innodb buffer pool原理总结
文章目录
- innodb buffer pool原理总结
- 1. 缓存的重要性
- 2. innodb buffer pool
- 2.1 buffer pool的内部组成
- 2.2 FREE链表
- 2.3 FLUSH链表
- 2.4 LRU链表
- 2.4.1 LRU链表的功能
- 预读
1. 缓存的重要性
我们都知道,对于innodb存储引擎的表来说,无论是索引数据还是真实数据都是以页的形式存在于磁盘上的。当我们在客户端敲上select * from t1;命令时,innodb就会将t1表所在的数据页加载到内存中,等我们下次在用时,直接在缓存中查找,而不会再次向磁盘中调用数据了,毕竟每调用一次就会浪费 一次磁盘IO。
前面我们说到,数据是以页的形式存在于磁盘上的,那么页是从哪里来的呢?又是怎么分配的?首先一个页面的大小是16kb,且不是零散存储于磁盘中,而是通过表空间将他们联系起来,表空间其实是一个虚拟的框框,归根结底,数据还是存储于磁盘上的。关于页的概述可以参考 《表空间》。
2. innodb buffer pool
2.1 buffer pool的内部组成
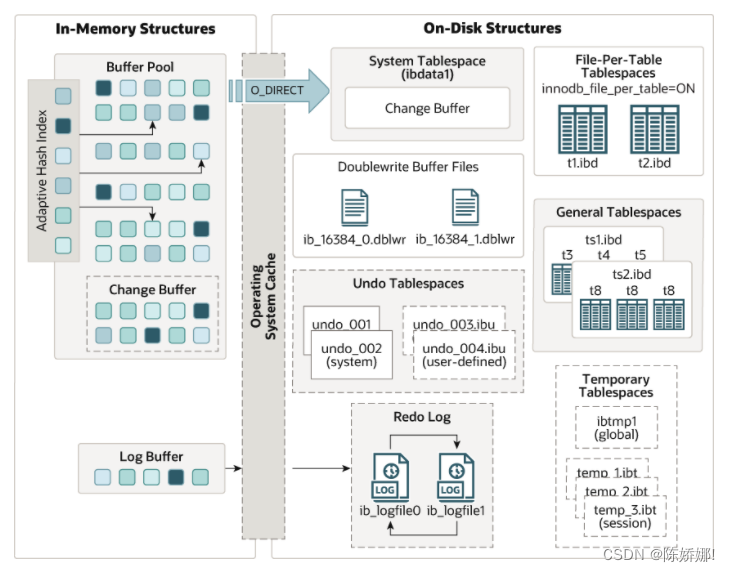
由上图可知,innodb存储引擎在内存中维护了一个缓冲池(buffer pool),主要存储了数据页,索引 页,undo页,自适应哈希索引,change buffer等。
buffer pool 的大小由参数innodb_buffer_pool_size决定 ,默认大概有128M,buffer pool不能设置的太小,最小可以设置为5M,当buffer pool小于5M时,innodb会自动调成5M。
当然,buffer pool里面也是有好多实例的,由innodb_buffer_pool_instance决定 ,每个instance下面又分有多个chunk,每个chunk的大小由innodb_buffer_pool_chunk_size决定,在默认情况下,每个chunk有128M。
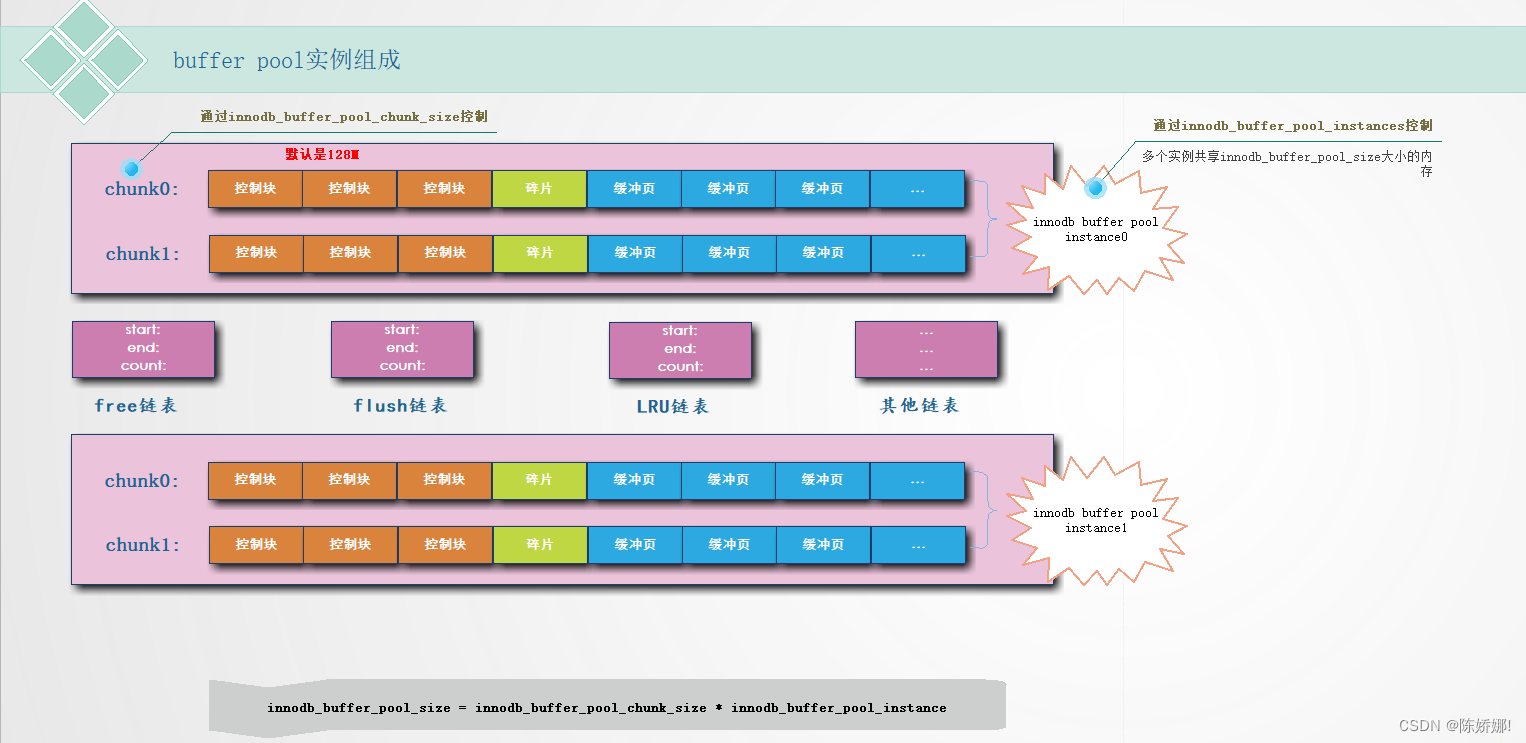
buffer pool 对应一片连续的的内存被划分的页面,页面大小于与innodb表空间能用的页面大小一致,默认是16kb,此处我们称为是缓冲页,每个缓冲页面对应一个控制头,(控制头,你可以理解是缓冲页的属性信息,包括该页面的表空间id,页号,缓冲信息)。每个控制头大概有808字节。所以内存池的实际大小会比innodb_buffer_pool_size大5%左右。说完这些后,再来说碎片,如果控制头和缓冲页分配不均,就会产生一些碎片,如果buffer pool设置的大小刚好,则不会产生碎片了。
上图中我们可以看到每个实例下都有free链表,flush链表和LRU链表。那这些都是做什么的呢?
2.2 FREE链表
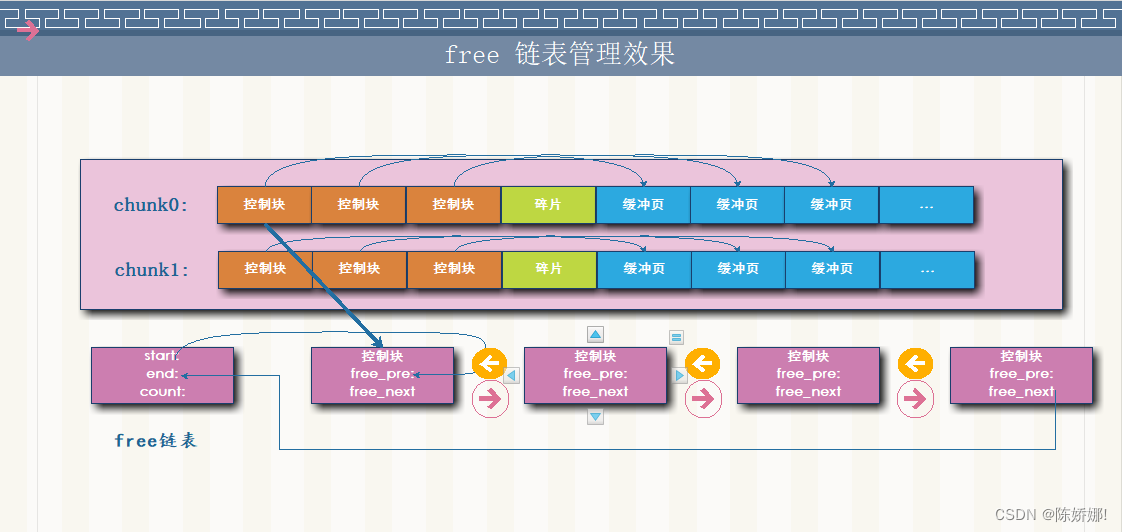
从图中可以看出,free 链表的主要工作是为了将控制块连接起来,更好的管理。其中,free链表里分为start,end,count,分别是定义了链表的头节点,尾节点,以及当前链表的数量。
此外的LRU链表和FLUSH链表的节点和此相似。
2.3 FLUSH链表
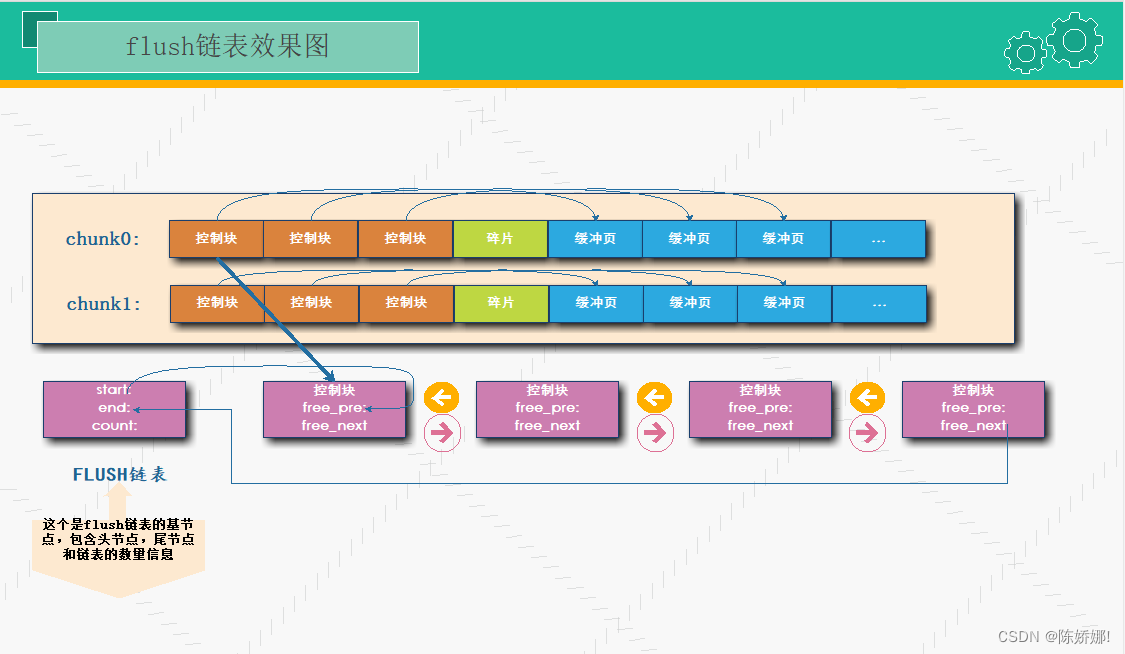
在学习表空间章节时,我们也接触过FLUSH链表。当修改过内存中的表数据,就会产生脏页,然后就会将此页面的指针指向到FLUSH链表,表示这个链表的数据页是需要被刷写到磁盘上的。
那么是有脏页产生后立即刷写到磁盘吗?也不是,这个是要先写redo后,再根据刷脏策略而定的。
2.4 LRU链表
在buffer pool对应的内存是有限的,随着用户不断写数据,将页从磁盘上加载到内存的buffer pool中,再将缓冲页变成脏页,刷写到磁盘,free链表里能用的页越来越少,将没有多少空闲页了,那么这时就要将flush链表中的数据腾出一些给free链表了,那腾出哪一些呢?当然是不经常访问的页了,LRU类似是一个栈,先进先出,随着在内存中的页越来越多,这些使用的页的控制头就会依次加入到LRU链表中,如果一个页很久都没使用了,就会率先将它剔除。
- 如果该页不在buffer pool中,在把该页从磁盘加载到buffer pool中的缓冲页时,就把该缓冲页对应的控制 块作为节点加载到LRU链表的头部了
- 如果该页已经加载到buffer pool中了,则直接把该页对应的控制块移动到LRU链表的头部。
2.4.1 LRU链表的功能
预读
-
预读的含义
就是说InnoDB认为执行当前的请求时,可能会读到哪些数据页,自动将数据页加载到buffer pool中去。 -
预读的分类
- 线性预读
innodb_read_ahead_threshold如果顺序的访问的某个区的页面超过这个系统变量的值(默认值56) ,就会触发一次异步读取下一个区中全部的页面到buffer pool中的请求。 - 随机预读
如果某个区的13个连续的页面都加载到了buffer pool,无论这些页面是不是随机读取的,就会触发随机预读,通过innodb_random_read_ahead变量控制,默认是off。
- 线性预读
-
预读的弊端
- 假如执行
select * from t1;,t1表中一亿行,可能分布在300个页面上,当加载到buffer pool中时可能就会将LRU之前保存的数据剔除掉,还会影响命中率
- 假如执行
-
优化预读
-
通过
innodb_old_blocks_pct将LRU链表分为两段,一段是热数据,一段是冷数据 。此变量默认值是3/8,表示冷数据占用3/8,热数据占用5/8.
当遇到一次写请求,Innodb将所需要的数据页首先会加载到LRU链表的头部,如果是本来已经存在LRU链表的数据就会将页移动到链表头部。那么这就有个问题了,如果这个页面本来就在LRU链表的5/8处只是没有在LRU链表的头部,那还移动吗?
innodb规定,如果此页面在LRU链表头部的1/4内处,就不会移动了。 -
回到上个问题,如果
select * from t1,t1表有很多数据,可能分布在多个页面上,加载到buffer pool中时就会将LRU之前保存的数据一并剔除,针对这一点的优化策略如下:- innodb规定,在对某个处于old区域的缓冲页面进行第一次访问时,就在它对应的控制 块中记录下这个访问时间,如果 后续的访问时间与第一次的访问时间在某个时间间隔内,那么该页就不会从冷数据区移动到热数据区了。通过
innodb_old_blocks_time控制 。 - 如果把
innodb_old_blocks_time的值设置为0,那么每次访问一个页面时,就会把该页面放到热数据的头部。
- innodb规定,在对某个处于old区域的缓冲页面进行第一次访问时,就在它对应的控制 块中记录下这个访问时间,如果 后续的访问时间与第一次的访问时间在某个时间间隔内,那么该页就不会从冷数据区移动到热数据区了。通过
-
-
相关参数
innodb_lru_scan_depth控制 lru列表中可用页的数量 ,默认是1024
参考:
https://dev.mysql.com/doc/refman/8.0/en