背景
最近公司给客户要做一些数据的预测,但是客户不清楚哪些做起来比较符合他们的,于是在经过与业务方的沟通,瞄准了两个方面的数据
1.工程数据:对工程数据做评估,然后做预警,这个想法是好的,但是由于这方面数据第一是不全,而且数据的准确程度有一些偏差,于是放弃了
2.财务数据:财务数据是个非常好的方向,首先财务数据是很准确的,而且规律性比较明显。
所以最终选了了财务数据分析这个角度。
注:本文中接下来做的所有数据都是虚拟数据,上面说的财务数据只是再说如何分析这个业务方向。
简介
基于以上我大概先说一下这个预测的方向:

由于博主是以做java和spark(scala)为主的人,所以对python用的比较少,过程中有不对的地方请大家批评指正。我们将向刚入行的小白开发者介绍如何使用Python实现AR(自回归)预测模型。AR模型是一种在时间序列预测中常用的模型,它基于过去的观测值来预测未来的值。
我们将按照以下步骤进行操作
| 步骤 | 描述 |
| 1 | 导入所需的库 |
| 2 | 加载时间序列数据 |
| 3 | 拆分数据集为训练集和测试集 |
| 4 | 训练AR模型 |
| 5 | 使用AR模型预测未来值 |
| 6 | 评估模型性能 |
| 7 | 可视化预测结果 |
代码实现:
导入所需的库
首先,我们需要导入一些必要的库,包括pandas用于数据处理和statsmodels用于建立AR模型。
from statsmodels.tsa.ar_model import AR
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from pandas import Series,DataFrame加载时间序列数据
def data_process():
#接受csv格式数据,根据情况修改为自己的地址
df = pd.read_csv(r"C:\Users\123\Downloads\funsbymonth.csv")
fans = df['fans'].values
data=pd.Series(fans)
df['date'] = pd.to_datetime(df['date'])
data_index = df['date'].values
data.index =pd.Index(data_index)
#data.plot(figsize=(12,8))
#plt.show()
return data,fans
#数据处理
data,fans = data_process()这块我封装了一个方法,仅供参考
数据我也提供一下,可以供大家学习使用,需要的自取
date,fans
2021-6-30,12
2021-7-31,52
2021-8-31,58
2021-9-30,82
2021-10-31,65
2021-11-30,66
2021-12-31,16
2022-1-31,23
2022-2-28,54
2022-3-31,61
2022-4-30,78
2022-5-31,64
2022-6-30,56
2022-7-31,18
2022-8-31,16
2022-9-30,60
2022-10-31,75
2022-11-30,90
2022-12-31,63
2023-1-31,69
2023-2-28,15
2023-3-31,10
2023-4-30,60
2023-5-31,62
2023-6-30,78
2023-7-31,71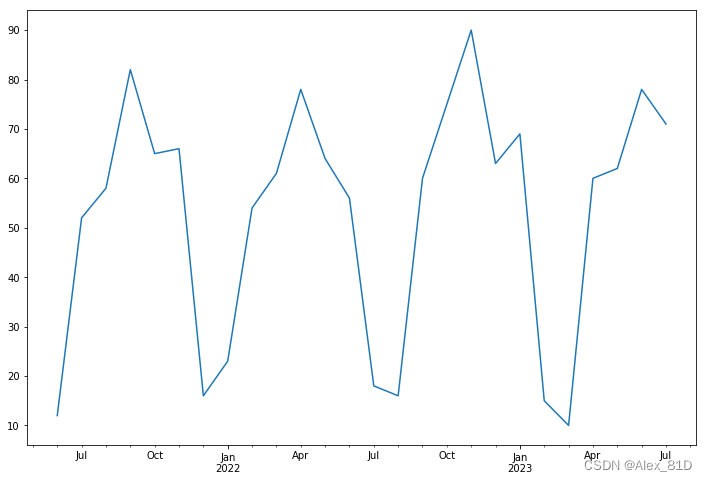
拆分数据集
在建立AR模型之前,我们需要将数据集拆分为训练集和测试集。一般情况下,我们将大部分数据用于训练模型,少部分数据用于测试模型的预测效果。这里我们假设将前80%的数据用于训练,后20%的数据用于测试。
train_data = data.iloc[:int(0.8*len(data))]
test_data = data.iloc[int(0.8*len(data)):]训练AR模型并预测
接下来,我们可以使用训练集的数据来训练AR模型。在这里,我们使用statsmodels库来构建AR模型。
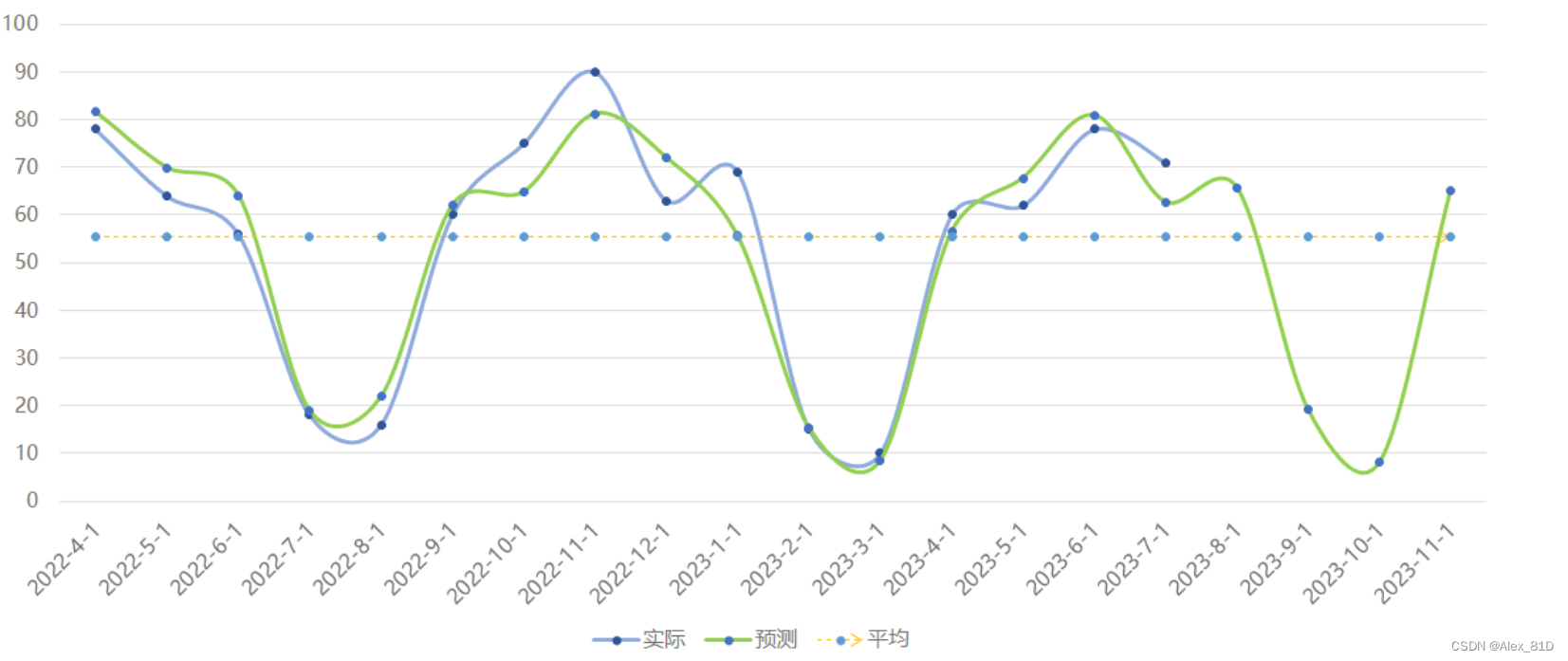
def model_fit3(data,start,end,starTime):
ar = AR(data).fit()
arpredict_y3 =ar.predict(start=start, end=end ,dynamic = False)
fig, ax = plt.subplots(figsize=(12, 8))
ax = data.ix[starTime:].plot(ax=ax)
arpredict_y3.plot(ax=ax)
plt.show()
return arpredict_y3
start = 10
end = len(fans)+3
starTime = '2022-1-31'
arpredict_y = model_fit3(data,start,end,starTime)
可视化结果
https://blog.51cto.com/u_16175449/6933670
https://blog.51cto.com/u_16175427/6815175
https://bbs.csdn.net/topics/392418314
https://blog.csdn.net/weixin_44034053/article/details/94359052
https://blog.51cto.com/u_13389043/6230021
https://blog.51cto.com/u_13389043/6230021
这里我在提供一种模型:自回归模型 AutoReg
上代码看看,数据集还是上面的数据集
import pandas as pd
from statsmodels.tsa.ar_model import AutoReg
import matplotlib.pyplot as plt
def data_process():
#接受csv格式数据,根据情况修改为自己的地址
df = pd.read_csv(r"C:\Users\allen_sun\Downloads\funsbymonth.csv")
fans = df['fans'].values
data=pd.Series(fans)
df['date'] = pd.to_datetime(df['date'])
data_index = df['date'].values
data.index =pd.Index(data_index)
#data.plot(figsize=(12,8))
#plt.show()
return data,fans
#数据处理
data,fans = data_process()
train_data = data.iloc[:int(0.8*len(data))]
test_data = data.iloc[int(0.8*len(data)):]
#模型训练
order = 9 # AR模型的阶数为2
model = AutoReg(train_data, lags=order)
model_fit = model.fit()
#模型预测
predictions = model_fit.predict(start=len(train_data), end=len(data)-1)
#模型评估
from sklearn.metrics import mean_squared_error, mean_absolute_error
#均方误差(MSE),结果越小越好
mse = mean_squared_error(test_data, predictions)
#平均绝对误差(MAE), 结果越小越好
mae = mean_absolute_error(test_data, predictions)
mse
mae
#print(predictions)
#预测起止点
start = 10
#预测长度,此长度表示向后预测4个阶段
end = len(fans)+3
order = 9 # AR模型的阶数为2
model = AutoReg(train_data, lags=order)
model_fit = model.fit()
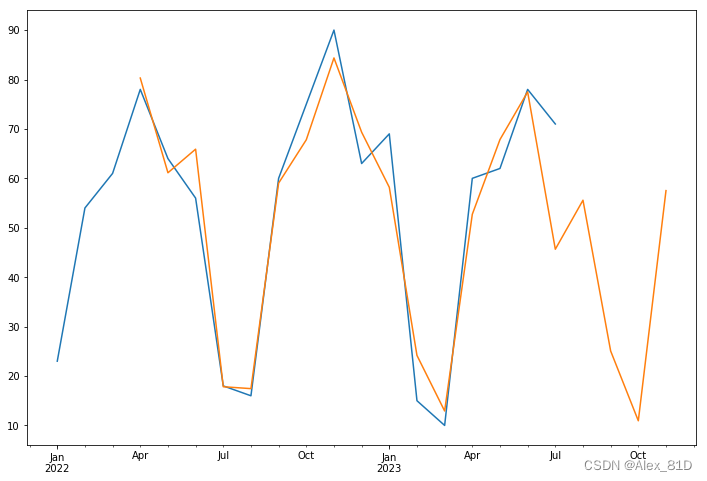
arpredict_y3 =model_fit.predict(start=start, end=end ,dynamic = False)
fig, ax = plt.subplots(figsize=(12, 8))
#python自带的绘制曲线开始日期
starTime = '2022-1-31'
ax = data.ix[starTime:].plot(ax=ax)
arpredict_y3.plot(ax=ax)
plt.show()评估项中的参数:
1.均方误差(MSE),结果越小越好。
2.误差均方根(RMSE),结果越小越好。
3.平均绝对误差(MAE),结果越小越好。
4.平均绝对百分误差(MAPE),结果越小越好。
效果:(也还行)
https://blog.csdn.net/qq_40206371/article/details/121103377