计算图与CUDA OOM
在实践过程中多次碰到了CUDA OOM的问题,有时候这个问题是很好解决的,有时候DEBUG一整天还是头皮发麻。
最近实践对由于计算图积累导致CUDA OOM有一点新的看法,写下来记录一下。包括对计算图的一些看法和一个由于计算图引发错误的简化实例记录。
本人能力有限,认识片面如果犯了错误希望大家指教!
计算图的存储
计算图是pytorch进行梯度反向传播核心,计算图是在程序运行过程中动态产生的,当tensor变量赋予了requires_grad=True的属性时,torch会自动记录其参与的计算并形成计算图保存在显存中。
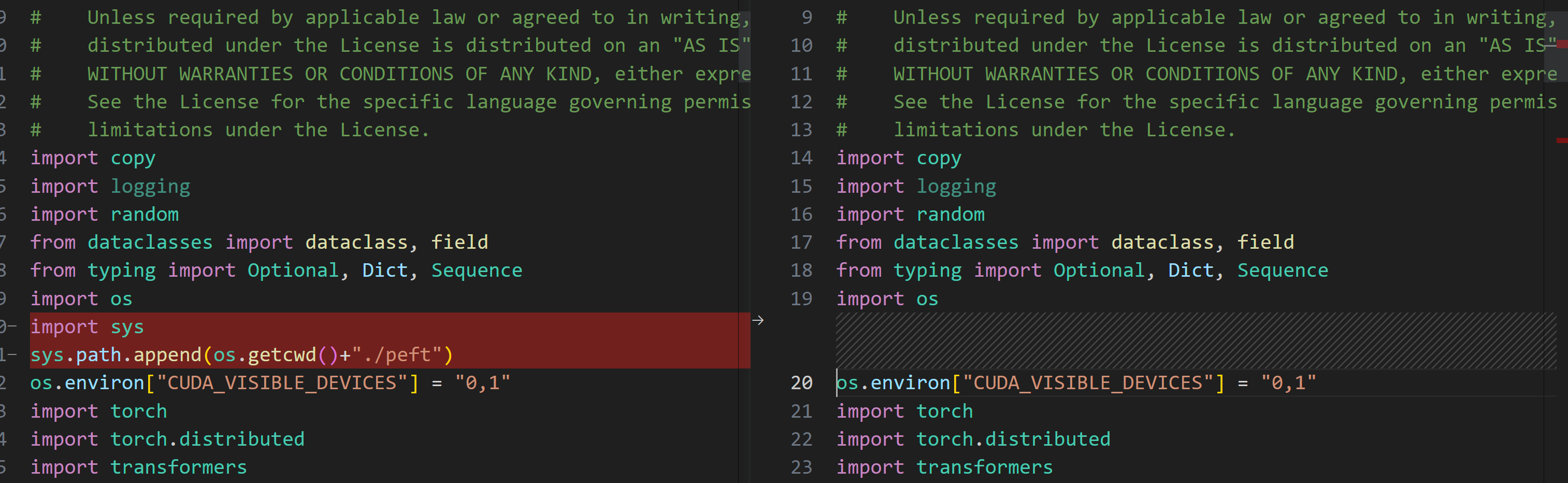
敲重点:计算图是会吃显存的! 本来想截下来描述一下计算图是长什么样的,至少是概念的表述一下,结果去学习了一圈发现:和我想的完全不一样!附上学习链接:传送门。更关键的是我还没完全看懂学会(🐶),有没有大大学会了教我一下,不甚感激!
总的来说一个tensor它内部包含的grad_fn别有洞天,首先grad_fn也是作为一个节点在计算图中的(其在pytorch的C艹中是Node的子类),grad_fn不仅是记录了这个tensor是被什么数学符号计算来的,它还暗搓搓记录了这个tensor是是从哪些数字里头窜出来的,以及其和其他grad_fn的py友谊,还有被包含在其内部context中的信息,我偷那个学习链接的一张图展示一下一个计算图的形态,借花献佛,展示一下grad_fn偷偷摸摸用你的卡干了啥事情。
BTW,提几个小知识点
- 我们常用的
detach()方法,就是通过把tensor的grad_fn扬了从而把tensor从计算图中剥离出来。
>>> x
tensor([1.], requires_grad=True)
>>> y = x+1
>>> y.grad_fn
<AddBackward0 object at 0x7f8306e68b50>
>>> y.detach().grad_fn is None
True
- 关于
*.backward(retain_graph=True)的问题,backward中retain_graph默认是False,其含义是经过默认的*.backward()之后,计算图会被清空从而释放其占用的显存。和detach不一样的是,grad_fn还是那个grad_fn只不过它悄咪咪维持的友谊被杀掉了,如下:
>>> x
tensor([1.], requires_grad=True)
>>> y = x+1; y.grad_fn
<AddBackward0 object at 0x7f8306e68b50>
>>> y.backward(retain_graph=False)
>>> y.grad_fn
<AddBackward0 object at 0x7f8306e68b50>
- 续上面一点的内容,但是内容包含我瞎猜的成分(🐶),我们猜测一下
backward杀掉了grad_fn的什么东西。一般的,我们认为当retain_graph=False的时候,我们只能backward()一次,因为计算图会被清空,第二次尝试反向传播会造成错误。但其实不然!如下实验例子1的尝试,我们连续backwrad并没有报错。AMAZING啊!。进一步的我们进行例子2的实验,我们只是简单的让前向多了一个乘法计算,然后另z反向传播两次,这回顺理成章的报错,同时报错之后我们再次反传y,我们发现反传y又不会报错。我猜测:backward()会清楚grad_fn节点和其他grad_fn的联系,因此z的grad_fn不能联系到y的grad_fn了,于是第二次z.backward()报错,但是y直接和叶子x连接,不需要其他的grad_fn朋友也能自己和自己玩。
例子1:
>>> x
tensor([1.], requires_grad=True)
>>> y = x+1
>>> y.backward(retain_graph=False);y.backward()
返回没有报错!
---------------------------------------------------------------
例子2:
>>> x
tensor([1.], requires_grad=True)
>>> y=x+1;z=2*y #前向过程多了一个乘法
>>> z.backward(retain_graph=False)
>>> z.backward()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/**/opt/anaconda3/lib/python3.8/site-packages/torch/_tensor.py", line 487, in backward
torch.autograd.backward(
File "/Users/**/opt/anaconda3/lib/python3.8/site-packages/torch/autograd/__init__.py", line 200, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.
>>>y.backward()
返回没有报错
一个由于没处理好计算图导致OOM的例子
import torch,time
l1 = torch.nn.Linear(1000,1000).cuda()
l2 = torch.nn.Linear(1000,1000).cuda()
memory = []
for _ in range(10000000):
time.sleep(0.01)
data_input = torch.rand(1000).cuda()
output = l1(l2(data_input))
output.backward(retain_graph=True) #此行与报错无关
memroy.append(output.cpu())
#memory存储的内容通过.cpu()转移在主存上,
#但是与output相关联的l1,l2的计算图依旧停留在显存中,并在循环中一直积累撑爆显存。
...some other operations...
这个例子中,由于每个output不能被正常清除计算图显存,最终导致OOM。
这个例子是某次实践的超级简化版,如果只看这个例子的话,其实只要把最后一行改写成
memory.append(output.detach().cpu())
就会由于output在每次循环后失去引用(detach()创建了新的变量)从而被回收,计算图被自动清空避免OOM。


![[PG]将一行数据打散成多行数据](https://img-blog.csdnimg.cn/22956aaab07c42f4abc39969e97b9dc6.png)