前言
最近的项目里遇到了字符串乱码的问题,记录一下研究心得。
正文
一、byte数组如何保存字符串
通常情况下,数据的传输和读取都是通过socket,读取socket需要使用byte数组,例如要写入一个字符串到socket中,我们需要先把String转成byte数组:
val s = "123"
// kotlin默认的编码格式是Charsets.UTF_8
val byteArray = s.toByteArray()
对方收到了byte数组后,会再调用
val s1 = byteArray.toString(Charsets.UTF_8)
首先确认一下byteArray里面到底是怎么保存字符串的:
val byteArray = s.toByteArray()
println("byteArray size:${byteArray.size}")
byteArray.forEach {
println(it)
}
// 输出结果
49
50
51
如果你熟悉Unicode编码,你能很快看出来,其实byte数组里就是分别存了1,2,3三个字符的Unicode编码,转成字符串的时候就根据编码查找对应的字符拼接起来。
二、为什么会有乱码
乱码指的是字符解码错误导致显示的字符混乱的现象。我们已经知道byte数组里是按照指定的编码格式保存字符对应的unicode码,显而易见会有两种可能导致乱码:
1、编码格式与解码格式不匹配
这是一种非常常见的错误,比如服务端数据没有指定utf-8格式,客户端根据utf-8去解码得到的数据就是一团乱码,或者本地保存的文件是gbk,用utf-8打开看到的内容就是一坨乱码。解决的方法也很简单,修改编码和解码格式匹配就可以了。
2、byte数组里的unicode码,系统不支持
如果unicode码系统不支持,有两种可能:
- 系统字符集有问题,不支持此unicode。这种情况一般是系统字符集不全导致的部分字符显示不出来或乱码,只需要更新最新的字符集即可;
- 系统字符集是完整的,确实不存在对应的字符,显示的时候系统可能会显示成其他字符;
Unicode码不能是负数,目前Android系统支持0~65535之间的unicode码,如果是范围以外的值,那么需要确认数据的来源是否正确,例如unicode码传错了,或者中间有数据转换异常。
三、如何去掉乱码
- 如果是编码格式和解码异常不匹配导致的乱码,需要修改两者一致;
- 如果是系统字符集问题,那么需要更新系统字符集;
- 确认乱码的unicode,小于等于32考虑使用trim或者根据unicode自行删除;
前两种问题都比较好解决,第三种情况比较特殊,我遇到的问题是数据源的unicode码是0:
var s = "123"
s = s.plus(0.toChar())
println(s)

可以在网上搜索一下unicode字符表:
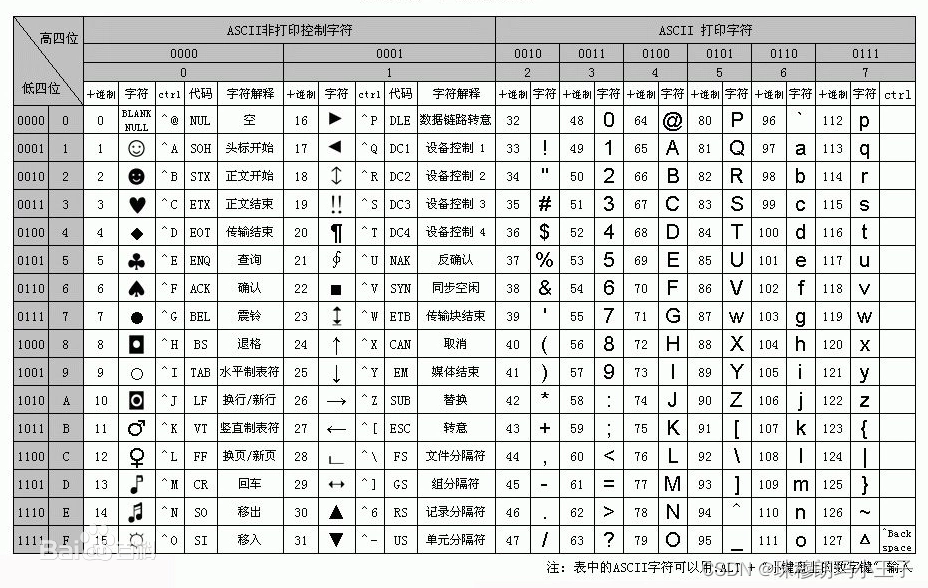
从表格查到unicode = 0表示空字符,但是在不同系统上空字符显示的效果不一样,有的是不可见,有的像我截图的这样是一个其他的字符。接下来我们看一下String源码中的trim方法:
public String trim() {
int len = length();
int st = 0;
while ((st < len) && (charAt(st) <= ' ')) {
st++;
}
while ((st < len) && (charAt(len - 1) <= ' ')) {
len--;
}
return ((st > 0) || (len < length())) ? substring(st, len) : this;
}
trim一般用来去掉字符串头部和尾部的空白字符,按照源码的逻辑,只要是unicode码小于等于空格都会被删掉,从表中查到空格的unicode码是32,所以unicode小于等于32的字符都会被删掉。像我这种情况使用trim就可以有效的去掉乱码。
unicode可以超过65535吗,按照我的实测是不会,目前我们的系统都是16位,那么最多就是65535。比较常见的问题还有:
为什么Java最多只能标识65535个字符
Java代码中一个方法代码不能超出65535字节
目前看String.trim方法已经能覆盖到几乎所有的情况了,所以第三种情况优先考虑使用trim。
4、Kotlin的String.trim和Java的String.trim
刚才Java的String.trim已经看过了,但是Kotlin对String.trim进行了覆盖:
/**
* Returns a string having leading and trailing whitespace removed.
*/
@kotlin.internal.InlineOnly
public inline fun String.trim(): String = (this as CharSequence).trim().toString()
/**
* Returns a sub sequence of this char sequence having leading and trailing whitespace removed.
*/
public fun CharSequence.trim(): CharSequence = trim(Char::isWhitespace)
/**
* Returns a sub sequence of this char sequence having leading and trailing characters matching the [predicate] removed.
*/
public inline fun CharSequence.trim(predicate: (Char) -> Boolean): CharSequence {
var startIndex = 0
var endIndex = length - 1
var startFound = false
while (startIndex <= endIndex) {
val index = if (!startFound) startIndex else endIndex
val match = predicate(this[index])
if (!startFound) {
if (!match)
startFound = true
else
startIndex += 1
} else {
if (!match)
break
else
endIndex -= 1
}
}
return subSequence(startIndex, endIndex + 1)
}
Kotlin的String.trim被覆盖为:只删掉头部和尾部的空白字符:
public static boolean isWhitespace(int codePoint) {
// We don't just call into icu4c because of the JNI overhead. Ideally we'd fix that.
// Any ASCII whitespace character?
if ((codePoint >= 0x1c && codePoint <= 0x20) || (codePoint >= 0x09 && codePoint <= 0x0d)) {
return true;
}
if (codePoint < 0x1000) {
return false;
}
// OGHAM SPACE MARK or MONGOLIAN VOWEL SEPARATOR?
if (codePoint == 0x1680 || codePoint == 0x180e) {
return true;
}
if (codePoint < 0x2000) {
return false;
}
// Exclude General Punctuation's non-breaking spaces (which includes FIGURE SPACE).
if (codePoint == 0x2007 || codePoint == 0x202f) {
return false;
}
if (codePoint <= 0xffff) {
// Other whitespace from General Punctuation...
return codePoint <= 0x200a || codePoint == 0x2028 || codePoint == 0x2029 || codePoint == 0x205f ||
codePoint == 0x3000; // ...or CJK Symbols and Punctuation?
}
// Let icu4c worry about non-BMP code points.
return isWhitespaceImpl(codePoint);
}
就以我遇到的unicode是0,这里返回的是false,所以没办法去掉乱码。如果你用的Kotlin又想要使用Java的String.trim方法,只能自己实现:
String.trim { it <= ' ' })