LSTM的劣势
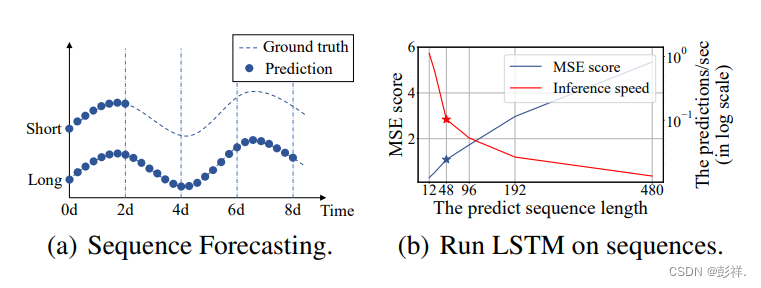
Figure 1: (a) LSTF can cover an extended period than
the short sequence predictions, making vital distinction in
policy-planning and investment-protecting. (b) The prediction capacity of existing methods limits LSTF’s performance. E.g., starting from length=48, MSE rises unacceptably high, and the inference speed drops rapidly.
在Informer中提出,在长序列预测过程中,如果序列越长,那么速度会越慢,同时,效果也会越差。
这并不难理解,由于时间序列预测中 t 时刻依赖 t-1 时刻的输出,那么随着时间序列越长,那么速度也会变慢,同时,也会更加难以收敛,因为无论是LSTM还是RNN,其使用的都是反向传播算法计算损失函数来进行优化,序列越长,那么求梯度也就会越困难,即越难收敛,从而会使效果变差。
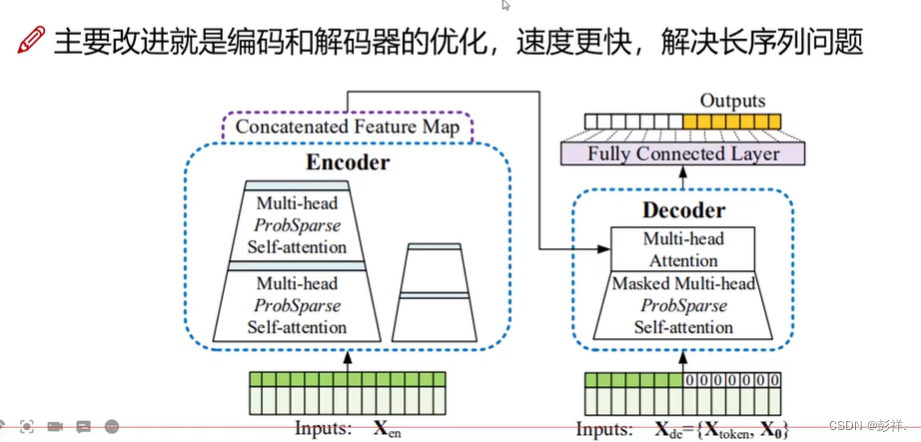
Informer其套用的是Transformer的架构,内含,注意力机制,其能够帮助我们计算出当前时间点与之前哪个时间点的关系密切程度。其为并行的,从而速度上有较大提升。
回顾Transformer
Transformer在self-attention的引入,可以提取有关系的特征,即数据间要有关联,如时间序列,文本翻译等,而对一些传统的数据回归预测问题,其就不见得适用了。
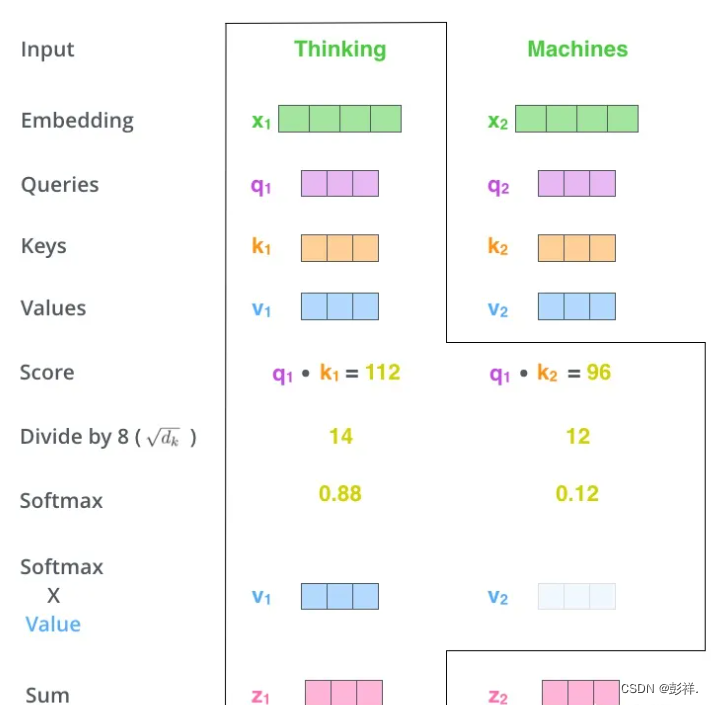
QKV是在Transformer中使用self-attention来进行计算,其时间复杂度为n2,计算成本很大。
在transformer中,decoder是需要依赖前一个进行输出的,这说明其为串行输出的。
encoder是多个encoder堆叠,除了输入输出不同外,其格式完全相同,一次self-attention的计算成本已经是相当昂贵了,更何况是多个叠加,效率很低。
Informer要解决的问题
尽量减少每个层的参数,从而降低计算成本。
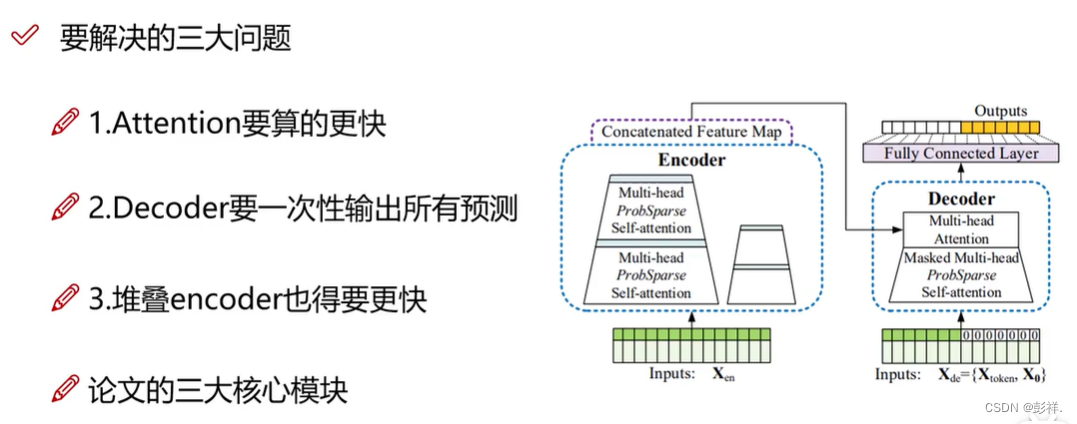
Encoder解决思路
ProbAttention计算方法
ProbSparse Self-attention 机制,在时间复杂度和内存使用方面实现了 O(Llog L),并且具有序列依赖性比对的可比性能。
首先是Attention的计算:
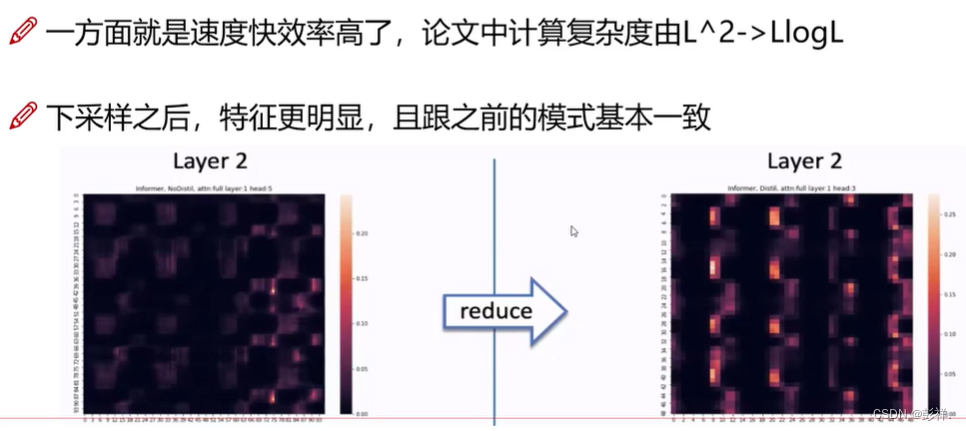
通过研究可知,将Q,K组成矩阵计算内积,及其相关性,发现并非所有的时间点之间是联系密切的,即权值大多少很小,其热力图如左图所示:,分析样本,存在较明显关系的也仅有一小部分,如右图所示。
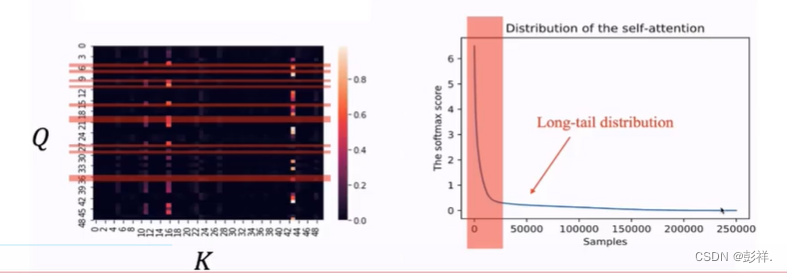
在发现了以上关系后,我们很容易想到,对于那些无关系的我们是否可以选择忽略呢?答案是可以的。那么我们该如何去计算呢。
论文的重点在于如何找到哪些有用的Q,那我们会想,为何要在Q中去寻找呢,我当时的猜想是Q它依旧沿用了Transformer中的意义,相当于一个索引数据,它越准确,付出的代价也就越小,比如我们在查询一些东西时,我们的描述越准确,检索的效率和效果都会越好,那么是否如我猜想的这样呢,我们可以继续看论文中的描述。
我们从Q中摘取两种活跃的与懒散的两种,可以看到活跃的Q所带来的注意力机制计算结果是跌宕起伏有差别的,而懒散的Q则为波澜不惊。
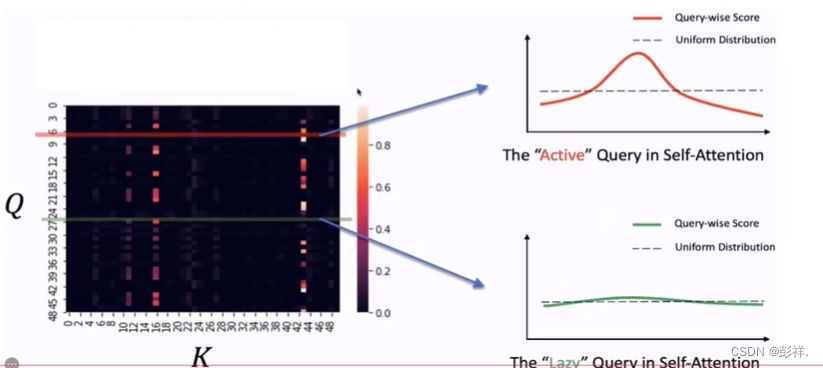
总结出来,这些懒散的Q就像是均匀分布,其没有特点。
而活跃的Q则表现出与某些值的权值差异较大,那我们就可以想到如何去找到这些活跃的Q,即我们可以计算其与均匀分布的差异,差异越大则说明其越活跃,其的作用越大。
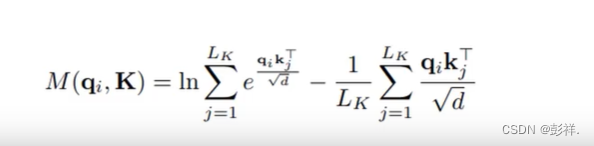
那么具体如何做呢?论文中使用公式进行证明,过程可谓相当复杂,但通过源码分析却能让我们事半功倍,其思路为:
1.我们以步长为96的时间序列为例,其对应产生96个Q,K,V,在之前我们需要使用96个Q和96个K来内积求相关性,现在,我们不再如此,而是首先我们随机选出30个K(注意:我们是要找出有用的Q,计算方法是求其与均匀分布的差值,那么我们找到K即可计算
2.使用96个Q与30个K计算内积,其能够得到一个均匀分布(这是一个管中窥豹的思路)
3.那么接下来便是计算哪个差值更大了,我们可以看到每个Q都有25个QK,这样计算差值就需要969625这种时间复杂度,这是十分巨大的,因此论文中采取了一种更绝的方法,直接选择每25个中最大的那个,这一下便将复杂度再次降为9625
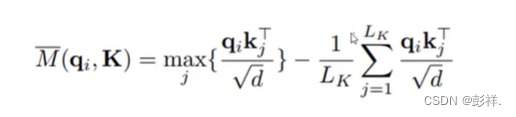
4.此时我们已经选择出了活跃的Q,将选择出来的30个Q再与96个K进行内积求相关性,在进行计算,而其他的Q呢,我们选择使用平均向量来代替,毕竟其与均匀分布类似,那么96个向量中有30个实际更新,其余的我们使用平均向量来代替,从而达到节省计算成本的目的。
计算完成后,我们找出了96个差异值,那么我们将其进行排序只选择前30个,这便是informer中ProbAttention的思想与计算方法。
self-attention Distilling(蒸馏降低复杂程度)
传统Transformer使用堆叠encoder,这就导致attention也要继续堆叠计算,那么如何来减少计算量呢,论文中提出使用1D的maxpool操作来进行下采样,如96的输入序列下次就变成48了,此时的Q,K的采样也由于序列长度变小,也会随之变小,如30->20
将该结构堆叠多次便构成Informer的Encoder架构了。
此时可能就有疑问了,将序列缩小靠谱吗,博主也曾有过类似的疑问,但想想encoder的作用就是提取特征嘛,我们的预测结果是根据之前的特征来进行预测而非前面的96个序列,将其转换后我们将特征提取出来便可以。
可以看出,informer通篇就是在考虑如何减少计算量。
不止是下采样,其也将stamp特征也融合进来了。
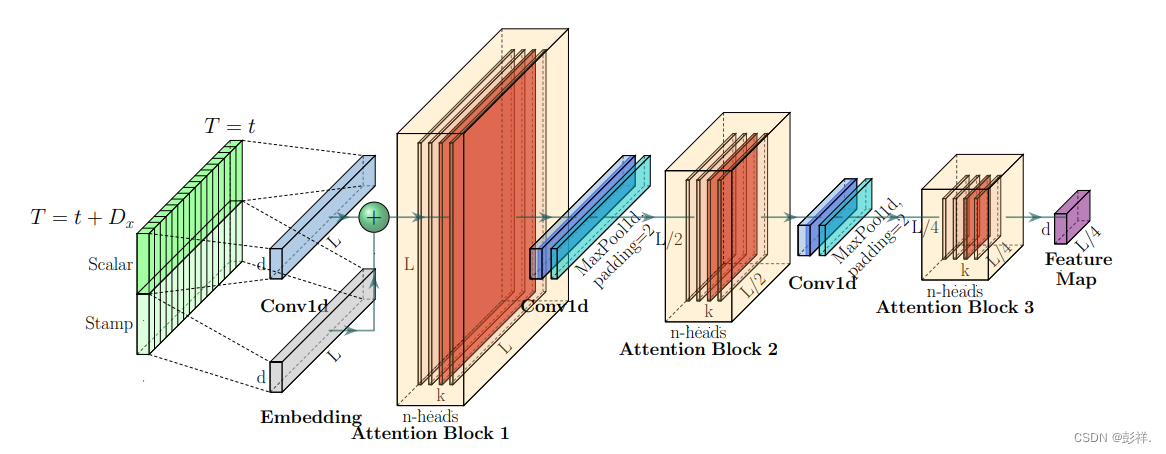
多头注意力即采取不同的方法来计算注意力权重值,head可认为是CNN中的卷积核,即不同的Q,K,V
在经过这一系列过程后,Encoder的改进效果:效率提高的同时,特征也越发鲜明。
Decoder解决思路
传统Encoder-Decoder
传统的Encoder-Decoder,是串行的,是基于前一个的,是一种SeqtoSeq的,依赖于先前预测的序列。是十分浪费时间的。
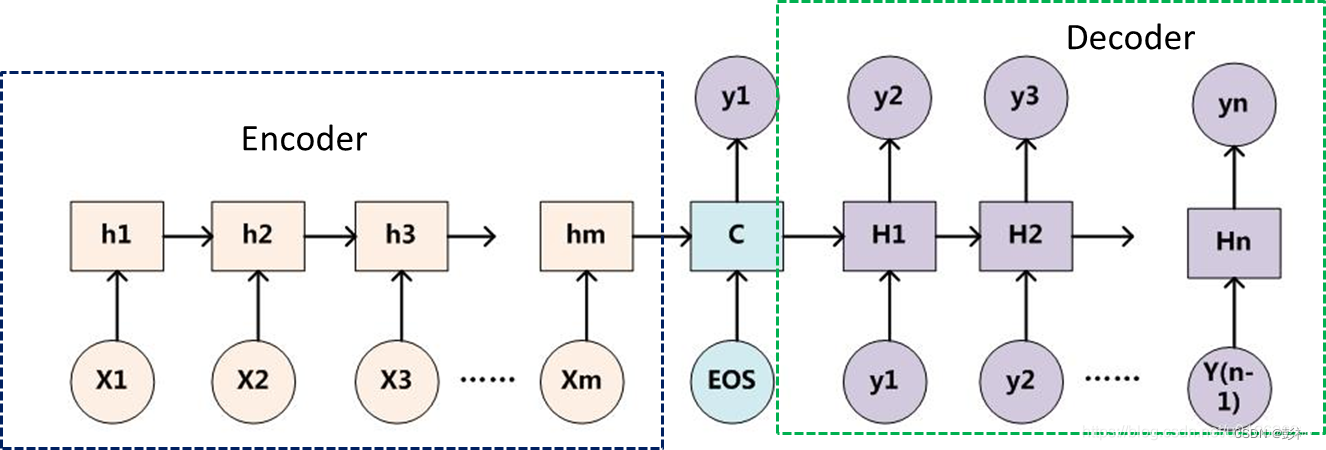
不论输入和输出的长度是什么,中间的“向量c”长度都是固定的(这是它的缺陷所在)。
根据不同的任务可以选择不同的编码器和解码器(例如,CNN、RNN、LSTM、GRU等)
Encoder-Decoder的一个显著特征就是:它是一个end-to-end的学习算法。
只要符合这种框架结构的模型都可以统称为Encoder-Decoder模型。
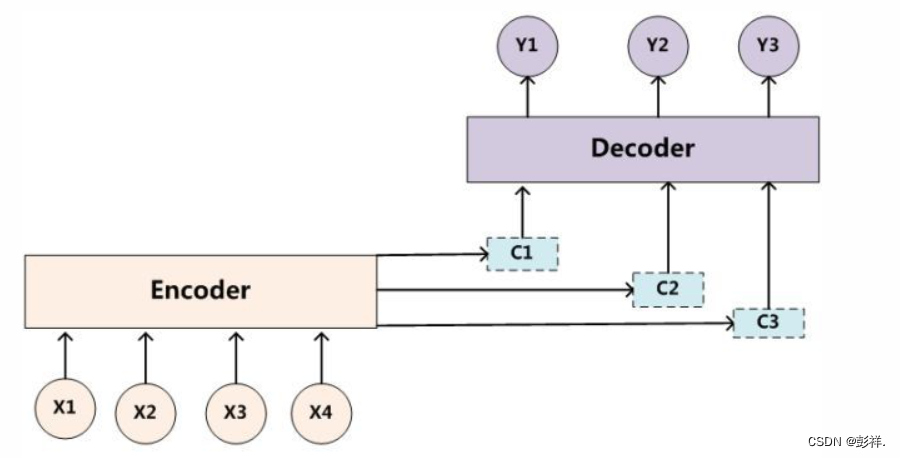
基础的Encoder-Decoder是存在很多弊端的,最大的问题就是信息丢失。Encoder将输入编码为固定大小的向量的过程实际上是一个“信息有损的压缩过程”,如果信息量越大,那么这个转化向量的过程对信息的损失就越大,同时,随着序列长度(sequence length)的增加,意味着时间维度上的序列很长,RNN模型就会出现梯度弥散的问题。由于基础的Encoder-Decoder模型链接Encoder和Decoder的组件仅仅是一个固定大小的状态向量,这就使得Decoder无法直接无关注输入信息的更多细节。为了解决这些缺陷,随后又引入了Attention机制以及Bi-directional encoder layer等。Attention模型的特点是Encoder不再将整个输入序列编码为固定长度的中间向量,而是编码成一个【向量序列】。
Transformer模型图
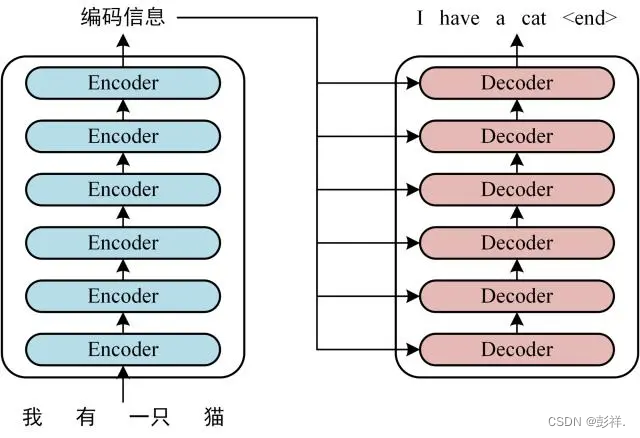
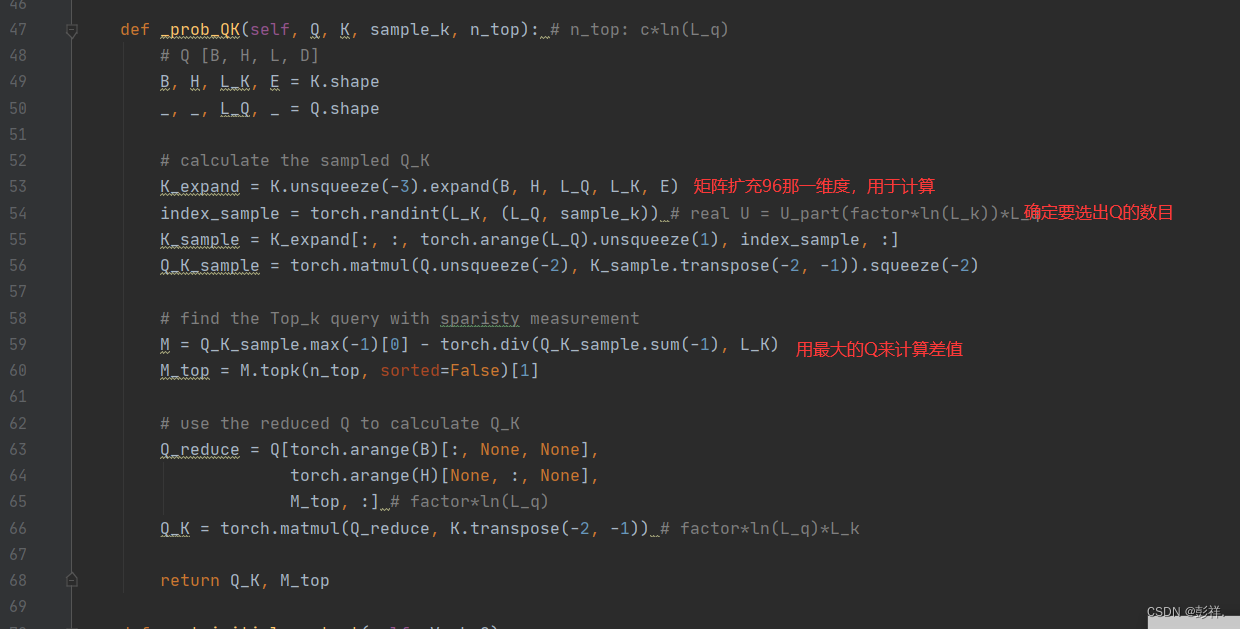
其亦可简化为该图:encoder与decoder之间的是Attention,它们内部使用self-attentionl来代替RNN抓取时间序列特征。
SeqtoSeq
所谓的Sequence2Sequence任务主要是泛指一些Sequence到Sequence的映射问题,Sequence在这里可以理解为一个字符串序列,当我们在给定一个字符串序列后,希望得到与之对应的另一个字符串序列(如 翻译后的、如语义上对应的)时,这个任务就可以称为Sequence2Sequence了。这种结构最重要的地方在于输入序列和输出序列的长度是可变的
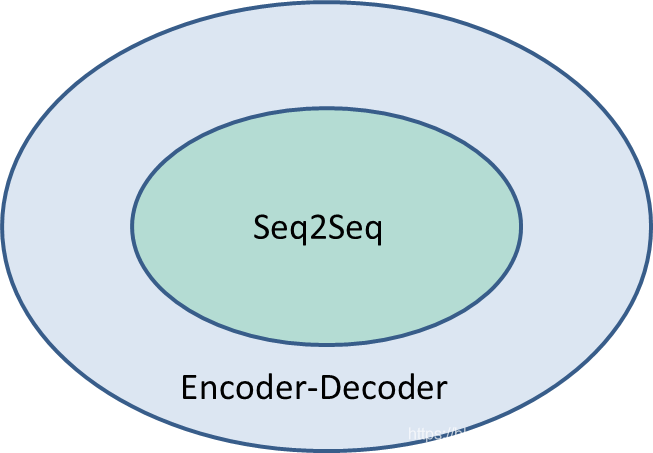
Encoder-Decoder强调的是模型设计(编码-解码的一个过程),Seq2Seq强调的是任务类型(序列到序列的问题)。
Informer中的Decoder如何预测?
要求前面有辅助的。
在decoder中要做两种self-attention,一个是dncoder的输入,即计算辅助时间序列和预测时间序列做self-attention。
但要注意的是Transormer中提到的mask,即前面的只能被后面用,而不能反过来。所以并不是所有的Q和所有的K做内积
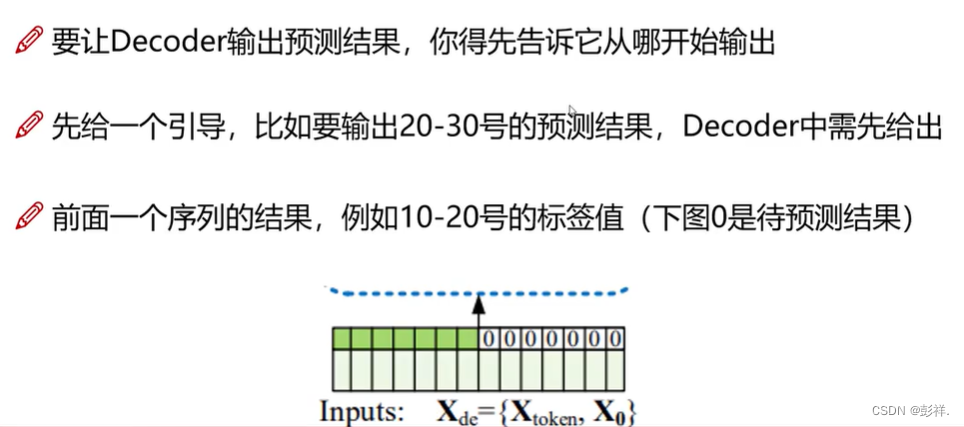

最后一步于encoder的计算注意力机制,并非self-attention
最终其能够一口气之间输出预测的长序列。
为何能够如此呢?传统的decoder内部是RNN,LSTM等,其是有时间依赖性的,而decoder中self-attention计算时的mask操作已经将这种依赖关系考虑进来了,那么也就没有依赖前一个序列的限制,从而一口气输出。
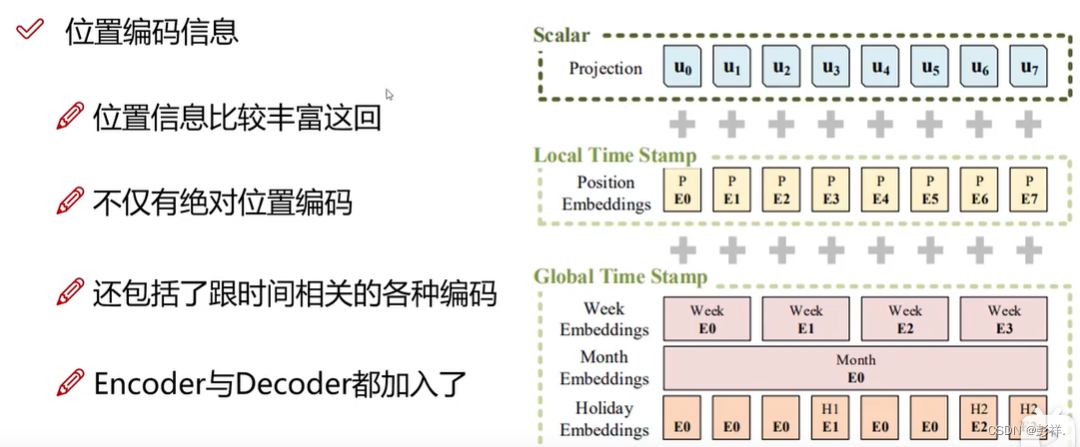
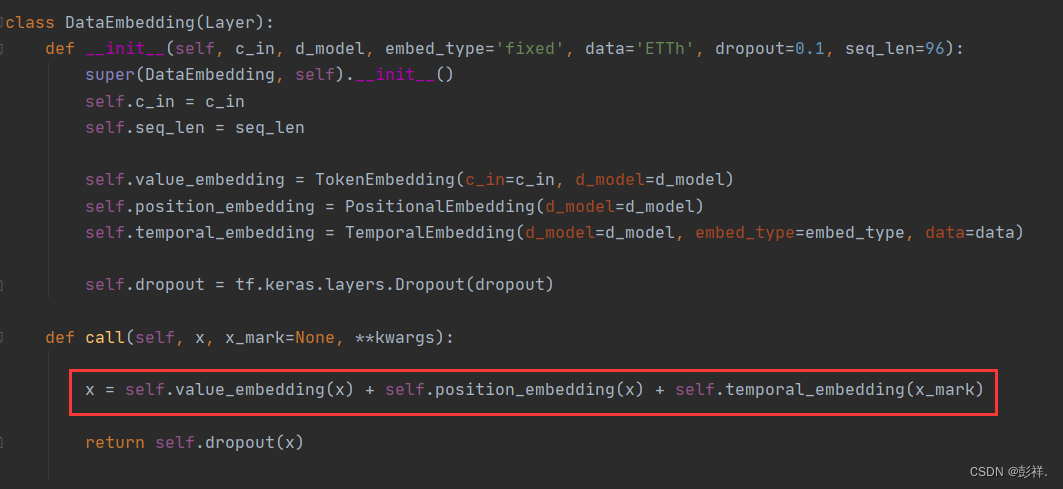
位置编码问题(针对时间序列,丰富特征)
是为了让时间特征更加丰富,使用加法,对特征向量进行融入即可。
总结