本章概要
- 集合 Set
- 映射 Map
- 队列 Queue
- 优先级队列 PriorityQueue
- 集合与迭代器
集合Set
Set 不保存重复的元素。 如果试图将相同对象的多个实例添加到 Set 中,那么它会阻止这种重复行为。 Set 最常见的用途是测试归属性,可以很轻松地询问某个对象是否在一个 Set 中。因此,查找通常是 Set 最重要的操作,因此通常会选择 HashSet 实现,该实现针对快速查找进行了优化。
Set 具有与 Collection 相同的接口,因此没有任何额外的功能,不像前面两种不同类型的 List 那样。实际上, Set 就是一个 Collection ,只是行为不同。(这是继承和多态思想的典型应用:表现不同的行为。)Set 根据对象的“值”确定归属性,更复杂的内容将在附录:集合主题中介绍。
下面是使用存放 Integer 对象的 HashSet 的示例:
import java.util.*;
public class SetOfInteger {
public static void main(String[] args) {
Random rand = new Random(47);
Set<Integer> intset = new HashSet<>();
for (int i = 0; i < 10000; i++) {
intset.add(rand.nextInt(30));
}
System.out.println(intset);
}
}

在 0 到 29 之间的 10000 个随机整数被添加到 Set 中,因此可以想象每个值都重复了很多次。但是从结果中可以看到,每一个数只有一个实例出现在结果中。
早期 Java 版本中的 HashSet 产生的输出没有明显的顺序。这是因为出于对速度的追求, HashSet 使用了散列,请参阅附录:集合主题一章。由 HashSet 维护的顺序与 TreeSet 或 LinkedHashSet 不同,因为它们的实现具有不同的元素存储方式。 TreeSet 将元素存储在红-黑树数据结构中,而 HashSet 使用散列函数。 LinkedHashSet 也使用散列来提高查询速度,但是似乎使用了链表来维护元素的插入顺序。显然,散列算法有改动,以至于现在(上述示例中的HashSet ) Integer 是有序的。但是,您不应该依赖此行为(下面例子就没有排序):
import java.util.HashSet;
import java.util.Set;
public class SetOfString {
public static void main(String[] args) {
Set<String> colors = new HashSet<>();
for (int i = 0; i < 100; i++) {
colors.add("Yellow");
colors.add("Blue");
colors.add("Red");
colors.add("Red");
colors.add("Orange");
colors.add("Yellow");
colors.add("Blue");
colors.add("Purple");
}
System.out.println(colors);
}
}
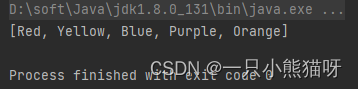
String 对象似乎没有排序。要对结果进行排序,一种方法是使用 TreeSet 而不是 HashSet :
import java.util.*;
public class SortedSetOfString {
public static void main(String[] args) {
Set<String> colors = new TreeSet<>();
for (int i = 0; i < 100; i++) {
colors.add("Yellow");
colors.add("Blue");
colors.add("Red");
colors.add("Red");
colors.add("Orange");
colors.add("Yellow");
colors.add("Blue");
colors.add("Purple");
}
System.out.println(colors);
}
}
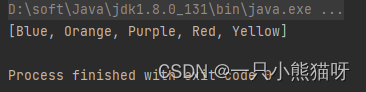
最常见的操作之一是使用 contains() 测试成员归属性,但也有一些其它操作,这可能会让你想起在小学学过的维恩图(译者注:利用图形的交合表示多个集合之间的逻辑关系):
import java.util.*;
public class SetOperations {
public static void main(String[] args) {
Set<String> set1 = new HashSet<>();
Collections.addAll(set1,"A B C D E F G H I J K L".split(" "));
set1.add("M");
System.out.println("H: " + set1.contains("H"));
System.out.println("N: " + set1.contains("N"));
Set<String> set2 = new HashSet<>();
Collections.addAll(set2, "H I J K L".split(" "));
System.out.println("set2 in set1: " + set1.containsAll(set2));
set1.remove("H");
System.out.println("set1: " + set1);
System.out.println("set2 in set1: " + set1.containsAll(set2));
set1.removeAll(set2);
System.out.println("set2 removed from set1: " + set1);
Collections.addAll(set1, "X Y Z".split(" "));
System.out.println("'X Y Z' added to set1: " + set1);
}
}
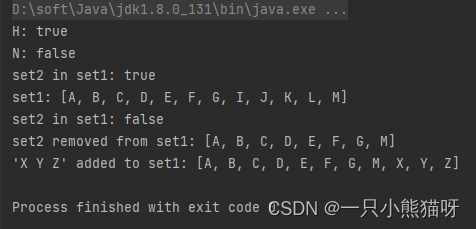
这些方法名都是自解释的,JDK 文档中还有一些其它的方法。
能够产生每个元素都唯一的列表是相当有用的功能。例如,假设想要列出上面的 SetOperations.java 文件中的所有单词,通过使用本书后面介绍的 java.nio.file.Files.readAllLines() 方法,可以打开一个文件,并将其作为一个 List 读取,每个 String 都是输入文件中的一行:
import java.util.*;
import java.nio.file.*;
public class UniqueWords {
public static void
main(String[] args) throws Exception {
// 相对路径未获取到文件
// List<String> lines = Files.readAllLines(Paths.get("SetOperations.java"));
List<String> lines = Files.readAllLines(Paths.get("D:\\onJava\\myTest\\BASE0002\\SetOperations.java"));
Set<String> words = new TreeSet<>();
for (String line : lines) {
for (String word : line.split("\\W+")) {
if (word.trim().length() > 0) {
words.add(word);
}
}
}
System.out.println(words);
}
}

我们逐步浏览文件中的每一行,并使用 String.split() 将其分解为单词,这里使用正则表达式 \ W + ,这意味着它会依据一个或多个(即 + )非单词字母来拆分字符串(正则表达式将在字符串章节介绍)。每个结果单词都会添加到 Set words 中。因为它是 TreeSet ,所以对结果进行排序。这里,排序是按_字典顺序_(lexicographically)完成的,因此大写字母和小写字母是分开的。如果想按_字母顺序_(alphabetically)对其进行排序,可以向 TreeSet 构造器传入 String.CASE_INSENSITIVE_ORDER 比较器(比较器是一个建立排序顺序的对象):
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.*;
public class UniqueWordsAlphabetic {
public static void
main(String[] args) throws Exception {
// 相对路径未获取到文件
// List<String> lines = Files.readAllLines(Paths.get("SetOperations.java"));
List<String> lines = Files.readAllLines(Paths.get("D:\\onJava\\myTest\\BASE0002\\SetOperations.java"));
Set<String> words = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
for (String line : lines) {
for (String word : line.split("\\W+")) {
if (word.trim().length() > 0) {
words.add(word);
}
}
}
System.out.println(words);
}
}

Comparator 比较器将在数组章节详细介绍。
映射Map
将对象映射到其他对象的能力是解决编程问题的有效方法。例如,考虑一个程序,它被用来检查 Java 的 Random 类的随机性。理想情况下, Random 会产生完美的数字分布,但为了测试这一点,则需要生成大量的随机数,并计算落在各种范围内的数字个数。 Map 可以很容易地解决这个问题。在本例中,键是 Random 生成的数字,而值是该数字出现的次数:
import java.util.*;
public class Statistics {
public static void main(String[] args) {
Random rand = new Random(47);
Map<Integer, Integer> m = new HashMap<>();
for (int i = 0; i < 10000; i++) {
// Produce a number between 0 and 20:
int r = rand.nextInt(20);
Integer freq = m.get(r); // [1]
m.put(r, freq == null ? 1 : freq + 1);
}
System.out.println(m);
}
}

- [1] 自动包装机制将随机生成的 int 转换为可以与 HashMap 一起使用的 Integer 引用(不能使用基本类型的集合)。如果键不在集合中,则
get()返回 null (这意味着该数字第一次出现)。否则,get()会为键生成与之关联的 Integer 值,然后该值被递增(自动包装机制再次简化了表达式,但实际上确实发生了对 Integer 的装箱和拆箱)。
接下来的示例将使用一个 String 描述来查找 Pet 对象。它还展示了通过使用 containsKey() 和 containsValue() 方法去测试一个 Map ,以查看它是否包含某个键或某个值:
PetMap.java
public class PetMap {
public static void main(String[] args) {
Map<String, Pet> petMap = new HashMap<>();
petMap.put("My Cat", new Cat("Molly"));
petMap.put("My Dog", new Dog("Ginger"));
petMap.put("My Hamster", new Hamster("Bosco"));
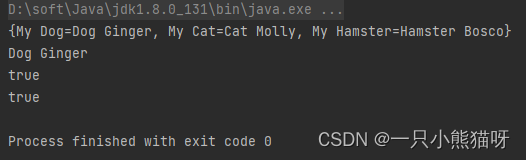
System.out.println(petMap);
Pet dog = petMap.get("My Dog");
System.out.println(dog);
System.out.println(petMap.containsKey("My Dog"));
System.out.println(petMap.containsValue(dog));
}
}
Pet.java
public class Pet extends Individual {
public Pet(String name) { super(name); }
public Pet() { super(); }
}
Cat.java
public class Cat extends Pet {
public Cat(String name) { super(name); }
public Cat() { super(); }
}
Dog.java
public class Dog extends Pet {
public Dog(String name) { super(name); }
public Dog() { super(); }
}
Map 与数组和其他的 Collection 一样,可以轻松地扩展到多个维度:只需要创建一个 Map ,其值也是 Map (这些 Map 的值可以是其他集合,甚至是其他的 Map )。因此,能够很容易地将集合组合起来以快速生成强大的数据结构。例如,假设你正在追踪有多个宠物的人,只需要一个 Map<Person, List> 即可:
MapOfList.java
import java.util.*;
public class MapOfList {
public static final Map<Person, List<? extends Pet>>
petPeople = new HashMap<>();
static {
petPeople.put(new Person("Dawn"),
Arrays.asList(
new Cymric("Molly"),
new Mutt("Spot")));
petPeople.put(new Person("Kate"),
Arrays.asList(new Cat("Shackleton"),
new Cat("Elsie May"), new Dog("Margrett")));
petPeople.put(new Person("Marilyn"),
Arrays.asList(
new Pug("Louie aka Louis Snorkelstein Dupree"),
new Cat("Stanford"),
new Cat("Pinkola")));
petPeople.put(new Person("Luke"),
Arrays.asList(
new Rat("Fuzzy"), new Rat("Fizzy")));
petPeople.put(new Person("Isaac"),
Arrays.asList(new Rat("Freckly")));
}
public static void main(String[] args) {
System.out.println("People: " + petPeople.keySet());
System.out.println("Pets: " + petPeople.values());
for (Person person : petPeople.keySet()) {
System.out.println(person + " has:");
for (Pet pet : petPeople.get(person)) {
System.out.println(" " + pet);
}
}
}
}
Cat.java
public class Cat extends Pet {
public Cat(String name) { super(name); }
public Cat() { super(); }
}
Cymric.java
public class Cymric extends Manx {
public Cymric(String name) { super(name); }
public Cymric() { super(); }
}
Dog.java
public class Dog extends Pet {
public Dog(String name) { super(name); }
public Dog() { super(); }
}
Individual.java
import java.util.Objects;
public class
Individual implements Comparable<Individual> {
private static long counter = 0;
private final long id = counter++;
private String name;
public Individual(String name) {
this.name = name;
}
// 'name' is optional:
public Individual() {
}
@Override
public String toString() {
return getClass().getSimpleName() +
(name == null ? "" : " " + name);
}
public long id() {
return id;
}
@Override
public boolean equals(Object o) {
return o instanceof Individual &&
Objects.equals(id, ((Individual) o).id);
}
@Override
public int hashCode() {
return Objects.hash(name, id);
}
@Override
public int compareTo(Individual arg) {
// Compare by class name first:
String first = getClass().getSimpleName();
String argFirst = arg.getClass().getSimpleName();
int firstCompare = first.compareTo(argFirst);
if (firstCompare != 0) {
return firstCompare;
}
if (name != null && arg.name != null) {
int secondCompare = name.compareTo(arg.name);
if (secondCompare != 0) {
return secondCompare;
}
}
return (arg.id < id ? -1 : (arg.id == id ? 0 : 1));
}
}
Manx.java
public class Manx extends Cat {
public Manx(String name) { super(name); }
public Manx() { super(); }
}
Mutt.java
public class Mutt extends Dog {
public Mutt(String name) { super(name); }
public Mutt() { super(); }
}
Person.java
public class Person extends Individual {
public Person(String name) { super(name); }
}
Pet.java
public class Pet extends Individual {
public Pet(String name) { super(name); }
public Pet() { super(); }
}
Pug.java
public class Pug extends Dog {
public Pug(String name) { super(name); }
public Pug() { super(); }
}
Rat.java
public class Rat extends Rodent {
public Rat(String name) { super(name); }
public Rat() { super(); }
}
Rodent.java
public class Rodent extends Pet {
public Rodent(String name) { super(name); }
public Rodent() { super(); }
}
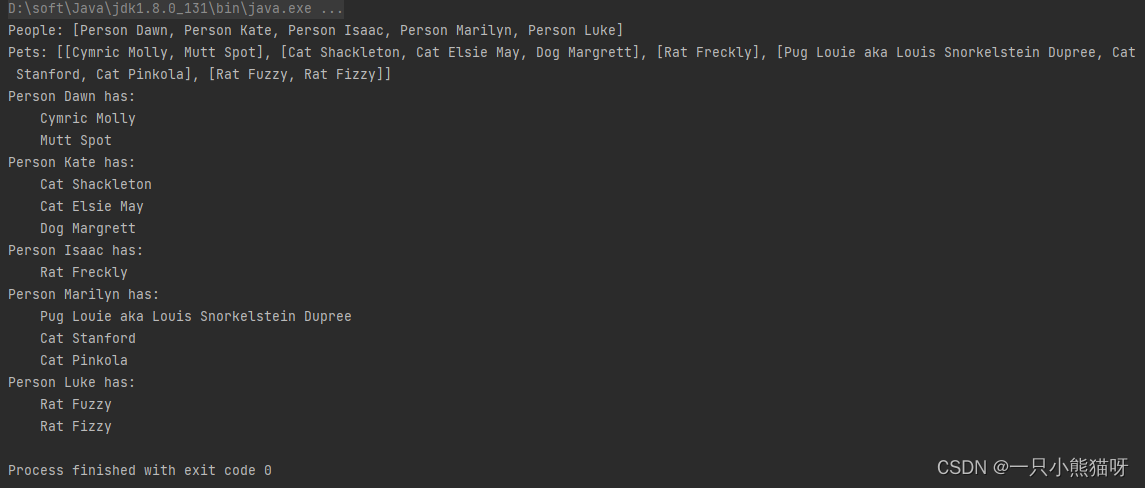
Map 可以返回由其键组成的 Set ,由其值组成的 Collection ,或者其键值对的 Set 。 keySet() 方法生成由在 petPeople 中的所有键组成的 Set ,它在 for-in 语句中被用来遍历该 Map 。
队列Queue
队列是一个典型的“先进先出”(FIFO)集合。 即从集合的一端放入事物,再从另一端去获取它们,事物放入集合的顺序和被取出的顺序是相同的。队列通常被当做一种可靠的将对象从程序的某个区域传输到另一个区域的途径。队列在并发编程中尤为重要,因为它们可以安全地将对象从一个任务传输到另一个任务。
LinkedList 实现了 Queue 接口,并且提供了一些方法以支持队列行为,因此 LinkedList 可以用作 Queue 的一种实现。 通过将 LinkedList 向上转换为 Queue ,下面的示例使用了在 Queue 接口中的 Queue 特有(Queue-specific)方法:
import java.util.*;
public class QueueDemo {
public static void printQ(Queue queue) {
while (queue.peek() != null) {
System.out.print(queue.remove() + " ");
}
System.out.println();
}
public static void main(String[] args) {
Queue<Integer> queue = new LinkedList<>();
Random rand = new Random(47);
for (int i = 0; i < 10; i++) {
queue.offer(rand.nextInt(i + 10));
}
printQ(queue);
Queue<Character> qc = new LinkedList<>();
for (char c : "Brontosaurus".toCharArray()) {
qc.offer(c);
}
printQ(qc);
}
}
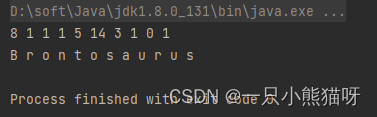
offer() 是 Queue 的特有方法之一,它在允许的情况下,在队列的尾部插入一个元素,或者返回 false 。 peek() 和 element() 都返回队头元素而不删除它,但如果队列为空,则 peek() 返回 null , 而 element() 抛出 NoSuchElementException 。 poll() 和 remove() 都删除并返回队头元素,但如果队列为空,则 poll() 返回 null ,而 remove() 抛出 NoSuchElementException 。
自动包装机制会自动将 nextInt() 的 int 结果转换为 queue 所需的 Integer 对象,并将 char c 转换为 qc 所需的 Character 对象。 Queue 接口窄化了对 LinkedList 方法的访问权限,因此只有适当的方法才能使用,因此能够访问到的 LinkedList 的方法会变少(这里实际上可以将 Queue 强制转换回 LinkedList ,但至少我们不鼓励这样做)。
Queue 的特有方法提供了独立而完整的功能。 换句话说, Queue 无需调用继承自 Collection 的方法,(只依靠 Queue 的特有方法)就有队列的功能。
优先级队列PriorityQueue
先进先出(FIFO)描述了最典型的_队列规则_(queuing discipline)。队列规则是指在给定队列中的一组元素的情况下,确定下一个弹出队列的元素的规则。先进先出:下一个弹出的元素应该是等待时间最长的那一个。
优先级队列 :下一个弹出的元素是最需要的元素(具有最高的优先级)。例如,在机场,飞机即将起飞的、尚未登机的乘客可能会被拉出队伍(作最优先的处理)。如果构建了一个消息传递系统,某些消息比其他消息更重要,应该尽快处理,而不管它们到达时间先后。在Java 5 中添加了 PriorityQueue ,以便自动实现这种行为。
当在 PriorityQueue 上调用 offer() 方法来插入一个对象时,该对象会在队列中被排序。默认的排序使用队列中对象的_自然顺序_(natural order),但是可以通过提供自己的 Comparator 来修改这个顺序。 PriorityQueue 确保在调用 peek() , poll() 或 remove() 方法时,获得的元素将是队列中优先级最高的元素。
让 PriorityQueue 与 Integer , String 和 Character 这样的内置类型一起工作易如反掌。在下面的示例中,第一组值与前一个示例中的随机值相同,可以看到它们从 PriorityQueue 中弹出的顺序与前一个示例不同:
import java.util.*;
public class PriorityQueueDemo {
public static void main(String[] args) {
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
Random rand = new Random(47);
for (int i = 0; i < 10; i++) {
priorityQueue.offer(rand.nextInt(i + 10));
}
QueueDemo.printQ(priorityQueue);
List<Integer> ints = Arrays.asList(25, 22, 20, 18, 14, 9, 3, 1, 1, 2, 3, 9, 14, 18, 21, 23, 25);
priorityQueue = new PriorityQueue<>(ints);
QueueDemo.printQ(priorityQueue);
priorityQueue = new PriorityQueue<>(ints.size(), Collections.reverseOrder());
priorityQueue.addAll(ints);
QueueDemo.printQ(priorityQueue);
String fact = "EDUCATION SHOULD ESCHEW OBFUSCATION";
List<String> strings = Arrays.asList(fact.split(""));
PriorityQueue<String> stringPQ = new PriorityQueue<>(strings);
QueueDemo.printQ(stringPQ);
stringPQ = new PriorityQueue<>(strings.size(), Collections.reverseOrder());
stringPQ.addAll(strings);
QueueDemo.printQ(stringPQ);
Set<Character> charSet = new HashSet<>();
for (char c : fact.toCharArray()) {
charSet.add(c); // Autoboxing
}
PriorityQueue<Character> characterPQ = new PriorityQueue<>(charSet);
QueueDemo.printQ(characterPQ);
}
}
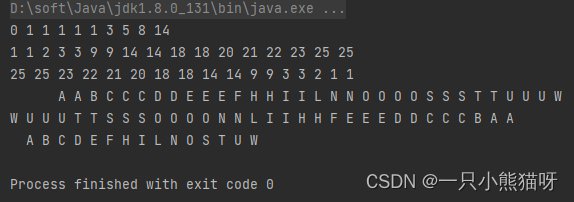
PriorityQueue 是允许重复的,最小的值具有最高的优先级(如果是 String ,空格也可以算作值,并且比字母的优先级高)。为了展示如何通过提供自己的 Comparator 对象来改变顺序,第三个对 PriorityQueue 构造器的调用,和第二个对 PriorityQueue 的调用使用了由 Collections.reverseOrder() (Java 5 中新添加的)产生的反序的 Comparator 。
最后一部分添加了一个 HashSet 来消除重复的 Character。
Integer , String 和 Character 可以与 PriorityQueue 一起使用,因为这些类已经内置了自然排序。如果想在 PriorityQueue 中使用自己的类,则必须包含额外的功能以产生自然排序,或者必须提供自己的 Comparator 。在附录:集合主题中有一个更复杂的示例来演示这种情况。
集合与迭代器
Collection 是所有序列集合共有的根接口。它可能会被认为是一种“附属接口”(incidental interface),即因为要表示其他若干个接口的共性而出现的接口。此外,java.util.AbstractCollection 类提供了 Collection 的默认实现,你可以创建 AbstractCollection 的子类型来避免不必要的代码重复。
使用接口的一个理由是它可以使我们创建更通用的代码。通过针对接口而非具体实现来编写代码,我们的代码可以应用于更多类型的对象。因此,如果所编写的方法接受一个 Collection ,那么该方法可以应用于任何实现了 Collection 的类——这也就使得一个新类可以选择去实现 Collection 接口,以便该方法可以使用它。标准 C++ 类库中的集合并没有共同的基类——集合之间的所有共性都是通过迭代器实现的。在 Java 中,遵循 C++ 的方式看起来似乎很明智,即用迭代器而不是 Collection 来表示集合之间的共性。但是,这两种方法绑定在了一起,因为实现 Collection 就意味着需要提供 iterator() 方法:
import pets.Pet;
import pets.PetCreator;
import java.util.*;
public class InterfaceVsIterator {
public static void display(Iterator<Pet> it) {
while (it.hasNext()) {
Pet p = it.next();
System.out.print(p.id() + ":" + p + " ");
}
System.out.println();
}
public static void display(Collection<Pet> pets) {
for (Pet p : pets) {
System.out.print(p.id() + ":" + p + " ");
}
System.out.println();
}
public static void main(String[] args) {
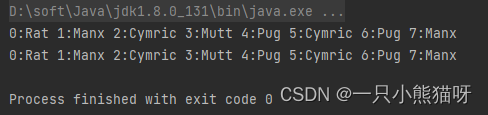
List<Pet> petList = new PetCreator().list(8);
Set<Pet> petSet = new HashSet<>(petList);
Map<String, Pet> petMap = new LinkedHashMap<>();
String[] names = ("Ralph, Eric, Robin, Lacey, Britney, Sam, Spot, Fluffy").split(", ");
for (int i = 0; i < names.length; i++) {
petMap.put(names[i], petList.get(i));
}
display(petList);
display(petSet);
display(petList.iterator());
display(petSet.iterator());
System.out.println(petMap);
System.out.println(petMap.keySet());
display(petMap.values());
display(petMap.values().iterator());
}
}
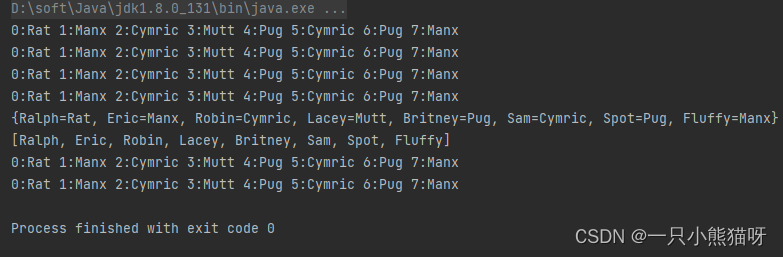
两个版本的 display() 方法都可以使用 Map 或 Collection 的子类型来工作。 而且Collection 接口和 Iterator 都将 display() 方法与低层集合的特定实现解耦。
在本例中,这两种方式都可以奏效。事实上, Collection 要更方便一点,因为它是 Iterable 类型,因此在 display(Collection) 的实现中可以使用 for-in 构造,这使得代码更加清晰。
当需要实现一个不是 Collection 的外部类时,由于让它去实现 Collection 接口可能非常困难或麻烦,因此使用 Iterator 就会变得非常吸引人。例如,如果我们通过继承一个持有 Pet 对象的类来创建一个 Collection 的实现,那么我们必须实现 Collection 所有的方法,纵使我们不会在 display() 方法中使用它们,也要这样做。尽管通过继承 AbstractCollection 会容易些,但是 AbstractCollection 还有 iterator() 和 size()没有实现(抽象方法),而 AbstractCollection 中的其它方法会用到它们,因此必须以自己的方式实现这两个方法:
CollectionSequence.java
import pets.Pet;
import pets.PetCreator;
import java.util.*;
public class CollectionSequence extends AbstractCollection<Pet> {
private Pet[] pets = new PetCreator().array(8);
@Override
public int size() {
return pets.length;
}
@Override
public Iterator<Pet> iterator() {
return new Iterator<Pet>() { // [1]
private int index = 0;
@Override
public boolean hasNext() {
return index < pets.length;
}
@Override
public Pet next() {
return pets[index++];
}
@Override
public void remove() { // Not implemented
throw new UnsupportedOperationException();
}
};
}
public static void main(String[] args) {
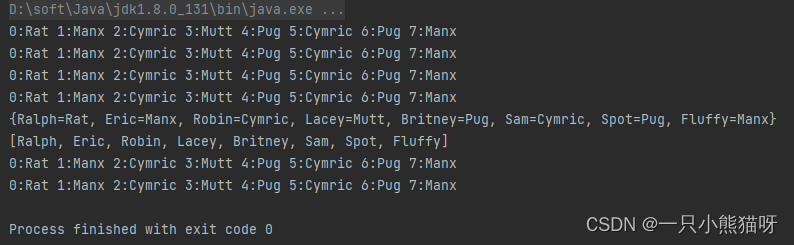
CollectionSequence c = new CollectionSequence();
InterfaceVsIterator.display(c);
InterfaceVsIterator.display(c.iterator());
}
}
InterfaceVsIterator.java
import pets.Pet;
import pets.PetCreator;
import java.util.*;
public class InterfaceVsIterator {
public static void display(Iterator<Pet> it) {
while (it.hasNext()) {
Pet p = it.next();
System.out.print(p.id() + ":" + p + " ");
}
System.out.println();
}
public static void display(Collection<Pet> pets) {
for (Pet p : pets) {
System.out.print(p.id() + ":" + p + " ");
}
System.out.println();
}
public static void main(String[] args) {
List<Pet> petList = new PetCreator().list(8);
Set<Pet> petSet = new HashSet<>(petList);
Map<String, Pet> petMap = new LinkedHashMap<>();
String[] names = ("Ralph, Eric, Robin, Lacey, " +
"Britney, Sam, Spot, Fluffy").split(", ");
for (int i = 0; i < names.length; i++) {
petMap.put(names[i], petList.get(i));
}
display(petList);
display(petSet);
display(petList.iterator());
display(petSet.iterator());
System.out.println(petMap);
System.out.println(petMap.keySet());
display(petMap.values());
display(petMap.values().iterator());
}
}
remove() 方法是一个“可选操作”,这里可以不必实现它,如果你调用它,它将抛出异常。
- [1] 你可能会认为,因为
iterator()返回 Iterator ,匿名内部类定义可以使用菱形语法,Java可以推断出类型。但这不起作用,类型推断仍然非常有限。
这个例子表明,如果实现了 Collection ,就必须也实现 iterator() ,而单独只实现 iterator() 和继承 AbstractCollection 相比,并没有容易多少。但是,如果类已经继承了其他的类,那么就没法再继承 AbstractCollection 了。在这种情况下,要实现 Collection ,就必须实现该接口中的所有方法。此时,继承并提供创建迭代器的能力(单独只实现 iterator())要容易得多:
import pets.Pet;
import pets.PetCreator;
import java.util.*;
public class InterfaceVsIterator {
public static void display(Iterator<Pet> it) {
while (it.hasNext()) {
Pet p = it.next();
System.out.print(p.id() + ":" + p + " ");
}
System.out.println();
}
public static void display(Collection<Pet> pets) {
for (Pet p : pets) {
System.out.print(p.id() + ":" + p + " ");
}
System.out.println();
}
public static void main(String[] args) {
List<Pet> petList = new PetCreator().list(8);
Set<Pet> petSet = new HashSet<>(petList);
Map<String, Pet> petMap = new LinkedHashMap<>();
String[] names = ("Ralph, Eric, Robin, Lacey, " +
"Britney, Sam, Spot, Fluffy").split(", ");
for (int i = 0; i < names.length; i++) {
petMap.put(names[i], petList.get(i));
}
display(petList);
display(petSet);
display(petList.iterator());
display(petSet.iterator());
System.out.println(petMap);
System.out.println(petMap.keySet());
display(petMap.values());
display(petMap.values().iterator());
}
}
生成 Iterator 是将序列与消费该序列的方法连接在一起的耦合度最小的方式,并且与实现 Collection 相比,它在序列类上所施加的约束也少得多。