今年早些时候,当我们与数据库互动时,我们的应用程序在两周的时间里出现了间歇性的超时问题。
尽管我们尽了最大的努力,但我们不能立即确定一个明确的原因;我们并没有进行任何明显改变数据库使用方式的代码更改,也没有突然的流量变化,我们的日志、追踪或仪表板中也没有任何警告性的内容。
在那两周内,我们部署了24个不同的以性能和可观测性为重点的更改来解决这个问题。
在这篇文章中,我将分享一些关于这些更改是什么以及我们从中获得的价值。
初步调查
当我们注意到这些减速并收到一个客户的报告,以及在我们的错误报告工具Sentry中看到了大量的“context canceled”错误后,我们首先对这些减速进行了调查。
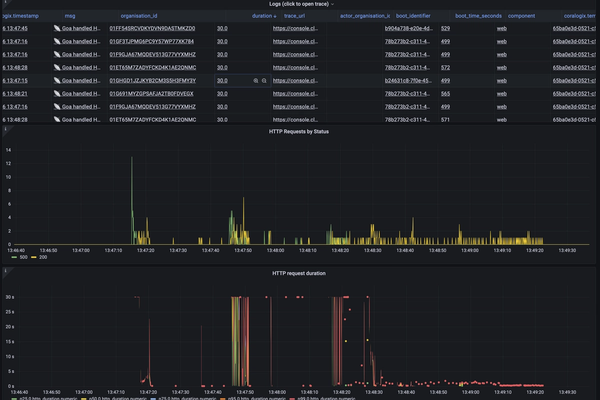
我们的值班工程师,Aaron,启动了一个事件并开始进行调查。他打开了我们在Grafana中的API仪表板,该仪表板提供了我们API健康状况的高级概览。
他确认我们确实在某些API请求上超时了,但在一分钟之内,我们已经恢复了正常服务。
更多技术干货请关注公号【云原生数据库】
在更新事件以让每个人都知道事情似乎正常之后,他开始调查是什么原因导致的这个问题。
打开一个单一失败的追踪,Aaron注意到这个HTTP请求几乎等待了20秒才从连接池中获取到一个可用的连接。
什么是连接池?当我们的应用程序与我们的数据库通信时,它使用一个在database/sql Go包中实现的客户端连接池。该包使用这些池来限制我们的应用程序中可以随时与数据库通信的进程数。当一个操作使用数据库时,它将该查询发送到database/sql包,该包试图从其连接池中获取一个连接。如果所有可用的连接都在使用中,该操作实际上会被阻塞,直到它可以获得一个连接。
这种阻塞是Aaron在追踪中看到的20秒的延迟。幸运的是,我们已经有了可观测性来识别这个问题。我们使用一个go.patch文件来修补database/sql包并向ConnectionPoolWait方法添加追踪来实现它。这可能不是最稳健的方法,但为了在追踪中添加一个单一的跨度,它做得很好。
从我们的追踪中,Aaron发现我们有各种各样的请求卡在等待连接池上。在这一点上,我们转向Kibana,以更好地了解这些请求的类型分布。
--- /tmp/sql.go 2022-08-01 23:45:55.000000000 +0100+++ /opt/homebrew/Cellar/go/1.19/libexec/src/database/sql/sql.go 2022-09-16 13:06:58.000000000 +0100@@ -28,6 +28,8 @@"sync""sync/atomic""time"++ "go.opencensus.io/trace")var (@@ -1324,6 +1326,9 @@return conn, nil}+ ctx, span := trace.StartSpan(ctx, "database.sql.ConnectionPoolWait")+ defer span.End()+// Out of free connections or we were asked not to use one. If we're not// allowed to open any more connections, make a request and wait.if db.maxOpen > 0 && db.numOpen >= db.maxOpen {
这将使我们能够确认这是少数几个端点争夺一个数据库连接池的争用,还是许多端点可能都使用不同的池。

我们发现的是,这个问题相当普遍——没有一个单一的连接池受到影响。
我们曾希望它是一个单一的池,因为那样就更容易锁定那个池中的工作并对其进行优化。
鉴于此,我们开始查看一般的数据库健康情况。历史HTTP流量和PubSub指标并没有表明我们在那个时候收到的任何东西都是非常普通的。Heroku的Postgres统计数据也显示了一个相当正常的数据库负载,尽管它确实突出了一些被忽视的查询,随着我们的数据库的增长,这些查询变得越来越慢。
由于没有明显的出发点,我们决定修复任何看起来缓慢并且是快速胜利的东西。我们已经发布了许多优化,包括:
-
将策略违规转移到使用一个物化视图,而不是必须拉取策略和所有相关的事件,只是为了为每个请求进行那种计算。
-
添加一些新的数据库索引来加速缓慢的查询。
-
重写了一些首先连接,然后过滤那些没有被索引的列的查询,当它们可以在一个已经存在于连接中的索引表上过滤同一列时。
在这一点上,我们觉得我们已经投入了大量时间来调查这次中断,我们已经发布了大量的低挂果实;我们结束了这一天,并关闭了事件。
【squids.cn】数据库备份、迁移、同步工具
再次发生的减速
在处理初次事件的几天内,闪电再次袭来——我们再次超时。这次轮到我值班,我被拉入了生成的事件。我打开了我们的仪表板,再次看到我们由于等待连接池而超时。看着Kibana和Google Cloud Trace,我们的慢请求中没有可辨识的模式。
我们的一名工程师,Lawrence,加入了事件,他建议,而不是玩打地鼠游戏,不停地修补查询,给我们所有的事务添加一秒钟的锁定超时。
由于我们的状态不佳,这至少让我们能够快速确定哪些请求比我们希望的持有事务的时间更长。
我们部署了这一变化,幸运的是,没有任何东西中断,但不幸的是,这意味着我们仍然没有更接近于确定我们减速的原因。
此时我们做出的一个显著变化是开始异步处理Slack事件。每当Slack频道中发生事件时,我们的机器人都可以访问它;我们通过webhook收到通知。此外,每当Slack同步工作区的用户时,我们都会为每次更改接收webhooks。这些可以加起来成为很多事件,而Slack经常一次性发送给我们大量的这些事件。
起初,当我们从Slack接收到此事件时,在该HTTP请求的生命周期内,我们会执行我们需要的任何响应,例如,为用户刚在频道中发布的GitHub链接提供附加链接。无论操作如何,我们总是会执行一些数据库查询,例如查找带有该Slack团队ID的组织。
为了帮助缓解高流量时段,我们开始异步处理这些事件。所以,当一个Slack webhook进来时,我们现在只是直接将其转发给PubSub,避免进行任何数据库查询。
通过使用PubSub,我们可以更多地限制对数据库的访问,如果我们愿意,我们可以免费获得一些重试逻辑。缺点是我们引入了处理事件所需的额外延迟,但我们认为这是一个合理的权衡。
这感觉像一个相当重大的变化,所以我们再次结束一天的工作,希望这是我们超时的最后一次。
提高我们的可观察性
尽管我们尽了最大努力,第二天,我们看到了另一个超时时期。此时,我们已经做了一些感觉上会有帮助的更改,但并没有取得明显的进展。我们意识到我们必须加倍努力来提高我们的可观察性,这样我们就可以找出问题的根源。
我们想要的金蛋是能够在一段时间内对操作进行分组,并累加该操作持有连接池的总时间。这将使我们能够查询诸如“哪些API端点挂在数据库连接上时间最长?”这样的事情。
每当我们处理一个PubSub消息或处理一个HTTP请求时,我们都会记录一个指标。通过这个,我们知道“这个操作花了多长时间”,“这是什么操作”,“它属于哪组服务?”所以,我们考虑用连接池使用情况的额外信息更新该日志。
理论上,计算我们在连接池中花费的时间听起来很容易,但不幸的是,这并不像'start timer, run query, end timer'那么简单。首先,我们不能围绕我们运行的每一个数据库查询放一个计时器,所以我们需要一个全局应用的中间件。此外,每当我们打开一个数据库事务,连接池在事务的生命周期内都会被持有,所以我们需要设计一种方法来检测我们是否处于事务中,并根据需要更改我们的计数逻辑。
对于中间件,我们最初考虑在Gorm——我们的ORM中插入一些东西。但我们很快意识到Gorm提供的钩子包括我们在连接池上等待的时间,所以我们会计算我们已经知道的东西。
相反,我们在ngrok/sqlmw包中实现了一个中间件,它允许我们在查询或事务发生之前和之后的代码中钩入。在这里,我们调用了一个新方法我们添加的 - trackUsage ——它利用了go的Context来维护我们的新计数器。
func trackUsage(ctx context.Context) (end func()) {inTransaction, _ := ctx.Value(InTransactionContextKey).(bool)startTime := time.Now()return func() {duration := time.Since(startTime)log.AddCounter(ctx, log.DatabaseDurationCounterKey, duration)// If we're inside a transaction, the connection is held for the entire// transaction duration, so we avoid double-counting each individual// statement within the transactionif !inTransaction {log.AddCounter(ctx, log.DatabaseConnectionDurationCounterKey, duration)}}}
现在,我们可以根据每个操作在数据库连接池中保持的时间来过滤我们的日志和追踪。
使用像Grafana这样的工具,我们可以按操作类型分组,并在一段时间内累加值。但是,我们尚未真正利用这一点。当我们等待一些有用的数据时,我们发布了另一个改变,解决了我们减速的根本原因。
最终的修复
当我们通过日志检查:“经过昨天的修复,我们现在看起来怎么样?”和“我们的连接池计数器是否工作?”时,我们注意到了每次处理Slack模态的提交时都会打开的不必要的事务。这是Slack在用户使用如/inc这样的斜杠命令时看到的视图中按下确认按钮时调用的HTTP端点。
我们为大多数模态提交移除了事务,在需要事务性保证的情况下,我们为这些代码路径明确地添加了事务。
直到几天后,我们才意识到这是我们问题的根源。由于超时是间歇性的,不是每天都发生,所以确认问题需要一点时间。但现在已经过去四个月,我们已经没有了数据库超时。
这确实证实了我们之前的怀疑——没有一个明显的慢事务导致了这个问题。相反,是许多短事务加在一起,给我们带来了一些真正的问题。
总结
在与这个问题斗争了几天后,没有一个“啊哈!”的时刻,我们一下子解决了所有问题,这有点令人失望。
但是,从好的一面看,我们现在更有能力在未来诊断类似的问题。我们还进行了一些真正的性能改进,这应该会使我们的应用对用户更快。
如果我们为应用的不同部分使用了不同的数据库,我们很可能会更早地找到这个问题。但是,那也绝对不是免费的。有了那个,我们就必须开始考虑分布式事务,我们的开发环境会不那么流畅,但我们目前对我们做出的权衡感到满意。
作者:Rory Bain