文章目录
- 检测是否支持
- HTTP Range 语法
- Range请求cURL示例
- 单一范围
- 多重范围
- 条件式分片请求
- Range分片请求的响应
- 文件整体下载
- 文件分片下载
- 文本下载
- 图片下载
- 封装下载方法
HTTP分片异步下载是一种下载文件的技术,它允许将一个大文件分成多个小块(分片),然后分别下载这些分片,从而实现更快速、稳定的下载过程。这种技术常用于大文件的下载,例如视频、游戏、软件等。或者与文件下载的断点续传功能搭配使用时非常有用。
比如当你正在看大片时,网络断了,你需要继续看的时候,文件服务器不支持断点的话,则你需要重新等待下载这个大片,才能继续观看。而支持HTTP Range的话,客户端就会记录了之前已经看过的视频文件范围,网络恢复之后,则向服务器发送读取剩余Range的请求,服务端只需要发送客户端请求的那部分内容,而不用整个视频文件发送回客户端,以此节省网络带宽,带来更流畅的用户体验。
检测是否支持
检测服务器端是否支持分片请求。
假如在响应头中存在 Accept-Ranges(并且它的值不为none),那么表示该服务器支持分片请求。例如,你可以使用 cURL 发送一个 HEAD 请求来进行检测。
curl -I https://xxx.jpg
HTTP/1.1 200 OK
...
Accept-Ranges: bytes
Content-Length: 146515
在上面的响应中, Accept-Ranges: bytes 表示界定范围的单位是 bytes。这里 Content-Length 也是有效信息,因为它提供了要检索的图片的完整大小。
如果站点未响应 Accept-Ranges,那么它们有可能不支持分片请求。一些站点会明确将其值设置为 none,以此来表明不支持。在这种情况下,某些应用的下载管理器会将暂停按钮禁用。
curl -I https://xxx.movie
HTTP/1.1 200 OK
...
Accept-Ranges: none
HTTP Range 语法
Range是一个HTTP请求头,告知服务器要返回文件的哪一部分,即:哪个区间范围(字节)的数据。
Range: <unit>=<range-start>-
Range: <unit>=<range-start>-<range-end>
Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end>
Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end>, <range-start>-<range-end>
-
<unit>:范围所采用的单位,通常是字节(bytes) -
<range-start>:一个整数,表示在特定单位下,范围的起始值。(下标从0开始) -
<range-end>:一个整数,表示在特定单位下,范围的结束值。这个值是可选的,如果不存在,表示此范围一直延伸到文档结束。
Range: bytes=200-1000 就是下载 200-1000 字节的内容(两边都是闭区间),服务端返回 206 的状态码,并带上这部分内容。
可以省略右边部分,代表一直到结束:Range: bytes=200-
也可以省略左边部分,代表从头开始:Range: bytes=-1000
而且可以请求多段 range,服务端会返回多段内容:Range: bytes=200-1000, 2000-6576, 19000-
Range请求cURL示例
从服务器端请求特定的范围。
单一范围
我们可以请求资源的某一部分。这次我们依然用 cURL 来进行测试。-H 选项可以在请求中追加一个首部行,在这个例子中,是用 Range 首部来请求图片文件的前 1024 个字节。
curl http://xxx.jpg -i -H "Range: bytes=0-1023"
这样生成的请求如下:
GET /xxx.jpg HTTP/1.1
Host: i.imgur.com
Range: bytes=0-1023
服务器端会返回状态码为 206 Partial Content 的响应:
HTTP/1.1 206 Partial Content
Content-Range: bytes 0-1023/146515
Content-Length: 1024
...
(binary content)
在这里,Content-Length 首部现在用来表示先前请求范围的大小(而不是整张图片的大小)。Content-Range 响应首部则表示这一部分内容在整个资源中所处的位置。
多重范围
Range 头部也支持一次请求文档的多个部分。请求范围用一个逗号分隔开。
curl https://xxx.jpg -i -H "Range: bytes=0-50, 100-150"
服务器返回 206 Partial Content 状态码,Content-Type:multipart/byteranges,boundary=3d6b6a416f9b5 头部。
- Content-Type:multipart/byteranges 表示这个响应有多个 byterange。
- 每一部分 byterange 都有他自己的 Content-type 头部和 Content-Range,并且使用 boundary 参数对 body 进行划分。
HTTP/1.1 206 Partial Content
Content-Type: multipart/byteranges; boundary=3d6b6a416f9b5
Content-Length: 282
--3d6b6a416f9b5
Content-Type: text/html
Content-Range: bytes 0-50/1270
<!doctype html>
<html>
<head>
<title>Example Do
--3d6b6a416f9b5
Content-Type: text/html
Content-Range: bytes 100-150/1270
eta http-equiv="Content-type" content="text/html; c
--3d6b6a416f9b5--
条件式分片请求
当(中断之后)重新开始请求更多资源片段的时候,必须确保自从上一个片段被接收之后该资源没有进行过修改。
The If-Range 请求首部可以用来生成条件式分片请求:
- 假如条件满足的话,条件请求就会生效,服务器会返回状态码为 206 Partial 的响应,以及相应的消息主体。
- 假如条件未能得到满足,那么就会返回状态码为 200 OK 的响应,同时返回整个资源。
该首部可以与 Last-Modified 验证器或者 ETag 一起使用,但是二者不能同时使用。
If-Range: Wed, 21 Oct 2015 07:28:00 GMT
Range分片请求的响应
与分片请求相关的有三种状态:
- 在请求成功的情况下,服务器会返回
206 Partial Content状态码。请求多个部分,服务器会以multipart文件的形式将其返回。 - 在请求的范围越界的情况下(范围值超过了资源的大小),服务器会返回
416 Requested Range Not Satisfiable(请求的范围无法满足)状态码。 - 在不支持分片请求的情况下,服务器会返回
200 OK状态码。
文件整体下载
以下实例采用node作为后端。
下载文件是一个常见的需求,只要服务端设置 Content-Disposition 为 attachment 就可以。
比如这样:
const express = require('express');
const app = express();
app.get('/download',(req, res, next) => {
res.setHeader('Content-Disposition','attachment; filename="test.txt"')
res.end('donwloadfileContent');
})
app.listen(3000, () => {
console.log(`server is running at port 3000`)
})
设置 Cotent-Disposition 为 attachment,指定 filename。
然后 html 里加一个 a 标签:
<!DOCTYPE html>
<html lang="en">
<body>
<a href="http://localhost:3000/download">download</a>
</body>
</html>
- 下载
http-servernpm包,在当前文件目录运行http-server命令跑起静态服务器。 - 点击链接就可以下载。若需要在服务器端js文件修改后动态生效,则可以安装
nodemonnpm包,进而执行nodemon index.js命令。
当文件过大,则需要对文件进行分片来下载,下面使用案例进行讲解。
文件分片下载
文本下载
添加这样一个路由:
app.get('/downloadRange', (req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.download('downloadRange.txt', {
acceptRanges: true
})
})
downloadRange.txt与index.js在同级目录下。
设置允许跨域请求,因为前端起的静态服务为http://localhost:8080,而node服务为http://localhost:3000,非同域。
res.download 是读取文件内容返回,acceptRanges 选项为 true 就是会处理 range 请求(其实默认就是 true)。
文件 downloadRange.txt 的内容是这样的:
0123456789
然后在 html 里访问一下这个接口:
<!DOCTYPE html>
<html lang="en">
<body>
<script>
fetch('http://localhost:3000/downloadRange', {
headers: {
Range: 'bytes=0-4',
}
})
.then(res => res.text())
.then(res => {
console.log(res) // 输出01234
})
.catch((err) => {
console.log(err);
})
</script>
</body>
</html>
访问页面,可以看到返回的是 206 的状态码!

这时候 Content-Length 就代表返回的内容的长度。
还有个 Content-Range 代表当前 range 的长度以及总长度。
此时响应内容为01234

当然,你也可以访问 5 以后的内容
Range: 'bytes=5-'
响应头内容是这样的:
Content-Length: 5
Content-Range: bytes 5-9/10
返回的内容是这样的:
56789
这俩连接起来就是整个文件的内容。这样就实现了简易版的断点续传。
我们再来试试如果超出 range 会怎么样:
Range: 'bytes=50-60',
请求 50-60 字节的内容,这时候响应头是这样的:
Status Code: 416 Range Not Satisfiable
返回的是 416 状态码,代表 range 不合法。
Range 不是还可以设置多段么?多段内容是怎么返回的呢?
我们来试一下:
Range: 'bytes=0-1, 3-4, 6-'
重新访问一下,这时候报了一个跨域的错误,说是发送预检请求失败。
Access to fetch at 'http://localhost:3000/downloadRange' from origin 'http://localhost:8080' has been blocked by CORS policy: Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource. If an opaque response serves your needs, set the request's mode to 'no-cors' to fetch the resource with CORS disabled.
浏览器会在三种情况下发送预检(preflight)请求:
- 用到了非 GET、POST 的请求方法,比如 PUT、DELETE 等,会发预检请求看看服务端是否支持
- 用到了一些非常规请求头,比如用到了 Content-Type,会发预检请求看看服务端是否支持
- 用到了自定义 header,会发预检请求
为啥 Range 头单个 range 不会触发预检请求,而多个 range 就触发了呢?
因为多个 range 的时候返回的 Content-Type 是不一样的,是 multipart/byteranges 类型,比较特殊。
预检请求是 options 请求,那我们就支持一下:
app.options('/downloadRange', (req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.setHeader('Access-Control-Allow-Headers', 'Range')
res.end('');
});
然后重新访问,这时候你会发现虽然状态码为200,且返回的是整个内容!
这是因为 express 只做了单 range 的支持,多段 range 可能它觉得没必要支持吧。
毕竟你发多个单 range 请求就能达到一样的效果。
图片下载
下面我们就用 range 来实现下文件的分片下载,最终合并成一个文件的功能。
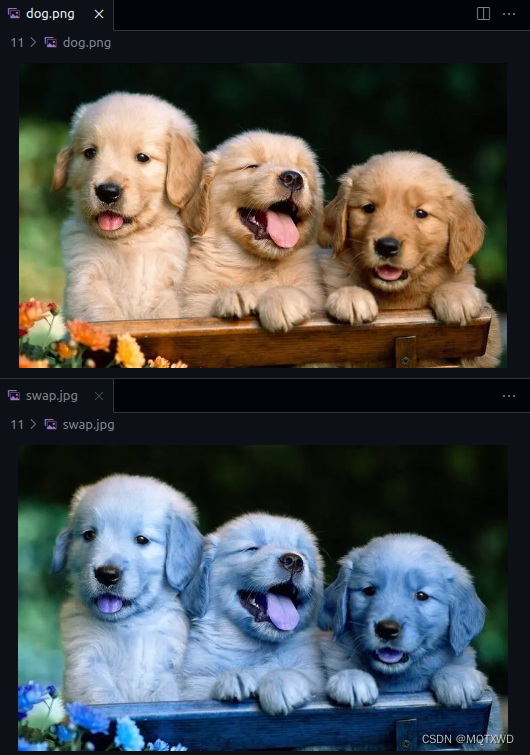
我们来下载一个图片吧,分成两块下载,然后下载完合并起来。
就用这个图片好了:

node代码修改如下
app.options('/downloadPicRange', (req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.setHeader('Access-Control-Allow-Headers', 'Range')
res.end('');
});
app.get('/downloadPicRange', (req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.download('1681859964629.png', {
acceptRanges: true
})
})
我们写下分片下载的代码,就分两段:这个图片是 56585 字节,也就是大概55.2k,那我们就分成 0-20000 和 20001- 两段:
<!DOCTYPE html>
<html lang="en">
<body>
<script>
const p1 = fetch('http://localhost:3000/downloadPicRange', {
headers: {
Range: 'bytes=0-20000',
}
})
const p2 = fetch('http://localhost:3000/downloadPicRange', {
headers: {
Range: 'bytes=20001-',
}
})
Promise.all([p1, p2])
.then(res => {
return Promise.all(res.map(resBody => resBody.blob()))
})
.then(res => {
const completeBlob = new Blob(res, { type: res[0].type})
console.log(completeBlob)
console.log(URL.createObjectURL(completeBlob))
})
.catch(err => {
console.log(err)
})
</script>
</body>
</html>
两个响应头Content-Range分别是这样的:
Content-Range: bytes 0-20000/56585
Content-Range: bytes 20001-56584/56585
第一个响应还能看到图片的预览,只能看到上部分:

然后我们要把两段给拼起来,怎么拼呢?
- 这里由于使用fetch进行请求,我们可以直接获取响应内容的文件对象为
blob类型。 - 然后将两段blob类型文件对象,合并到新的blob文件对象中。
- 通过
URL.createObjectURL获取文件对象的资源在本地的链接,将其粘贴到浏览器中,可以看到组合的图片正常显示。
封装下载方法
当然,一般不会这么写死来用,我们可以封装一个通用的文件分片下载工具。
但分片之前需要拿到文件的大小,所以要增加一个接口,调用这个接口返回文件大小:
const fs = require('fs');
app.get('/length',(req, res, next) => {
res.setHeader('Access-Control-Allow-Origin', '*');
res.end('' + fs.statSync('./1681859964629.png').size);
})
然后我们来做分片:
async function fileDownloadRange(path, size, chunkSize) {
let chunkNum = Math.ceil(size / chunkSize);
const downloadTask = [];
for (let i = 1; i <= chunkNum; i++) {
const rangeStart = chunkSize * (i - 1);
const rangeEnd = chunkSize * i - 1;
downloadTask.push(
fetch(path, {
headers: {
Range: `bytes=${rangeStart}-${rangeEnd}`,
},
})
)
}
return await Promise.all(downloadTask.map(task => task.then(res => res.blob())))
}
这部分代码不难理解:
首先根据 chunk 大小来计算一共几个 chunk,通过 Math.ceil 向上取整。
然后计算每个 chunk 的 range,构造下载任务的 promise。
Promise.all 等待所有下载任务完成,并获取下载内容为blob文件类型
我们来验证下:
async function fileDownloadRange(path, size, chunkSize) {
let chunkNum = Math.ceil(size / chunkSize);
const downloadTask = [];
for (let i = 1; i <= chunkNum; i++) {
const rangeStart = chunkSize * (i - 1);
const rangeEnd = chunkSize * i - 1;
downloadTask.push(
fetch(path, {
headers: {
Range: `bytes=${rangeStart}-${rangeEnd}`,
},
})
)
}
return await Promise.all(downloadTask.map(task => task.then(res => res.blob())))
}
(async function () {
const fileLength = await fetch('http://localhost:3000/length').then(res => res.text())
const blobArr = await fileDownloadRange('http://localhost:3000/downloadPicRange', fileLength, 15000);
const fileCompleted = new Blob(blobArr, { type: blobArr[0].type });
console.log(URL.createObjectURL(fileCompleted))
})();



![[VSCode] 替换掉/去掉空行](https://img-blog.csdnimg.cn/f7d004f2c4d74e63b2121af213b8230b.png)