将图像输入到transformer的思想

把每个像素点按照顺序拿出来,作为token,这样做的话输入参数规模是:假如是1通道的灰度图: 224x224x1=50176,bert才512,是bert的100倍。
改进方法:

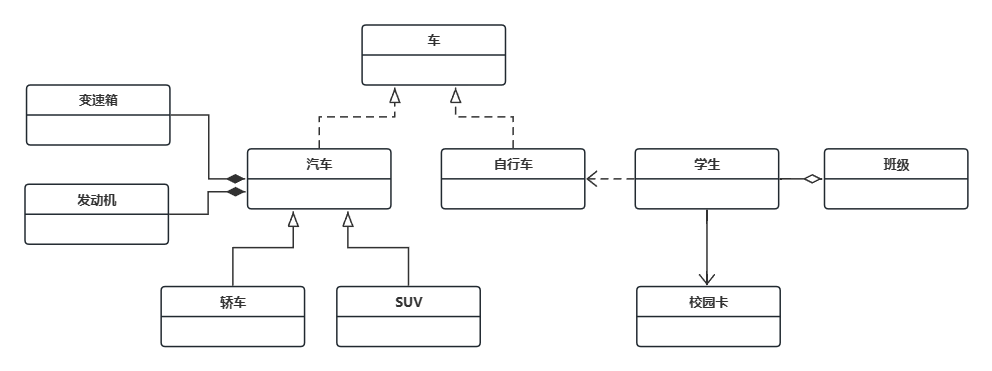
VIT模型架构图

步骤二:linear Projection of Flattened Patches
把图片切分成一个一个的Patch,这些patch不能直接作为transformer的输入,要把patch转为固定维度的embedding。
比如一个patch是16x16,直接展平=256
假如transformer要求的输入是768。那么就需要Linear Projection of Flattened Patchs将256维映射成768维。
步骤三:位置embedding 和 tokens embedding相加
1.生成一个cls的token Embedding

2.生成所有序列的位置编码
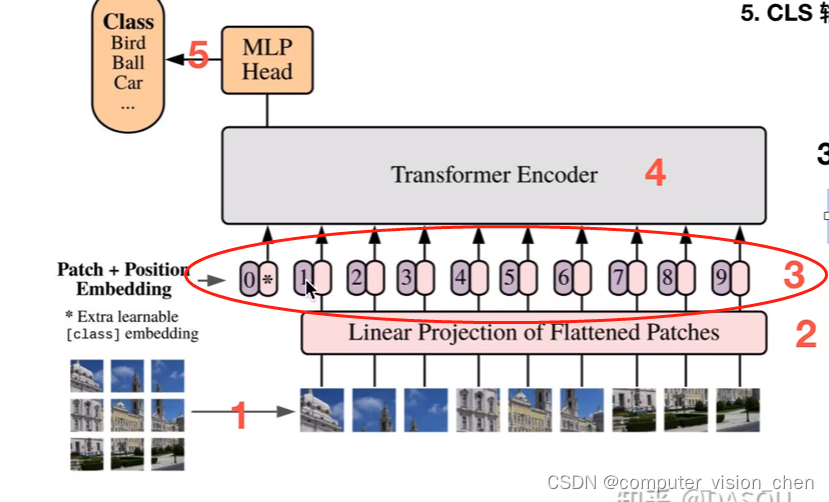
位置编码是紫色。patch对应的embedding是粉色。
3.token + 位置编码
由于内容是一起输入到transformer中的,没有先后和位置之分,所以需要位置编码。如果没有位置编码,模型不知道谁在前谁在后。
patch + Position Embedding
补充
token的中文意思?解释transformer的token
“Token” 这个词在中文中的意思是 “标记” 或者 “令牌”。在计算机科学和自然语言处理领域,“token” 通常指的是文本中的最小单元,可以是一个单词、一个字符或者其他一些文本片段,根据特定的上下文和任务而定。在 Transformer 模型中,“token” 是指输入文本被拆分成的最小单位,通常是一个单词或一个子词(subword)。