在接口自动化测试过程中,构造测试数据是必不可少的一个环节,但如何恢复测试数据也同样值得关注。业内常见的做法有:
1、不恢复:如果是没什么影响的数据,不恢复也无所谓,缺点就是会造成大量数据冗余;另外如果每次构造的都是重复数据且接口存在重复性校验,那么势必会造成接口报错、数据构造失败,从而影响到测试流程;
2、备份/恢复整个数据库:这种做法最简单粗暴,前提是要先备份数据库,然后在执行完测试后恢复数据库;这种对环境有要求,比如最好是一套独立的、可供自动化测试随便折腾的环境,如果在测试的环境还有其他人在用,那么这种做法显然不可取;
3、手动删除数据:可以是页面上手动删除,或者是调用单独的删除接口删除,也可以是手动删除各个数据表中的数据;
4、调用删除接口,形成闭环:这也是目前最常见的做法,即调用新增接口–>查询接口–>修改接口–>删除接口,从而形成一个完整的闭环,既达到了接口业务流程验证的目的,也避免了手动删除测试数据的麻烦;
以上几种方法中,最后一种是最便捷、也是应用最为广泛的。

但现实中,可能部分接口的业务流程并不存在完全闭环的情况,比如我们某个项目有个新增企业的业务,如果按照方式4,那么调用顺序就是新增企业–>修改企业信息–>查询企业信息并断言修改字段是否生效–>删除企业。但实际项目中只有增、查、改接口,并没有删除接口(设计如此)。尤其是新增接口,先会调用一个查询接口,获取第三方数据库视图中的企业列表,拿到添加企业信息的相关字段,再调用新增接口添加到我们系统中来,新增时会校验该企业信息是否已存在,不存在则新增,存在则返回错误码。而在没有提供删除接口的情况下,自动化测试过程中就要确保:
- 要么每次新增的企业数据都不一致(这样就可以不用删除数据,前提是第三方视图中的数据量够大,可以保证一直新增下去);
- 要么每次新增完数据再执行SQL语句一一删除相关数据表中新增企业时产生的数据(这样就相当于曲线救国式地完成了业务闭环,因为即使是提供了删除接口,其背后也是执行相关SQL进行删除各个数据表数据的操作)。注意这里不能是手动删除数据,无论是手动从页面删除还是手动从数据库删除。因为如果运行一次就删除一次,那运行一百次就要手动删除一百次,显然不切实际,这样也与我们自动化的理念背道而驰。
之前我们组小伙伴所写的自动化测试用例中,使用的是上述第一种方式,即每次新增不一样的企业数据,新增后不删除(原因是开发没有提供删除接口,SQL语句涉及的表较多,且表与表之间存在诸多关联,刚好视图中的数据够多,可以一直添加下去,只要保证每次添加的数据不一致就可以了)。这样的实现方式也不是不可以,只是会带来诸多弊端,而今天文章所表述的内容,就是对该实现方式进行优缺点分析,并基于第二种执行SQL删除数据的实现方式进行改造。
一、分析利弊
1.原实现方式
上述背景中已经提到视图中的数据够多,可以一直添加下去,只需保证每次添加的数据不一致即可。添加企业数据前会先调用查询接口,读取第三方企业数据列表,那么就需要设计一种方式使每次读取到的企业数据不一致。原实现方式如下:
① 定义读取和写入ini配置文件的方法
配置文件内容如下:
[company_data]
x = 1 # page
y = 1000 # page_size
next_y = 242 # index
[product_data]
x = 1
y = 1000
next_y = 146
读写配置文件方法如下:
import configparser, os
def get_next_data(ini_name):
"""
ini_name:配置文件中,配置的名字,写在[]里面的那串
方法返回列表,按顺序分别是 x,y,next_y
对应的意思是 当前要请求的页码,当前请求的条数,当前从第几条获取
"""
# 取文件路径
path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 合成配置文件的路径
ini_path = path + '/config/page_config.ini'
cf = configparser.ConfigParser()
cf.read(ini_path)
# 取上一次请求的页码
x = int(cf.get(ini_name, 'x'))
y = int(cf.get(ini_name, 'y'))
next_y = int(cf.get(ini_name, 'next_y'))
if next_y + 1 < y:
# 如果+1还小于当前页码数据,那么下次还在当前页数据
cf.set(ini_name, 'next_y', str(next_y + 1))
else:
# 如果+1等于当前页码数据,那么下次就翻页,x也要+1
cf.set(ini_name, 'x', str(x + 1))
cf.set(ini_name, 'next_y', str(0))
cf.write(open(ini_path, 'w'))
return [x, y, next_y]
在上述方法中,会先读取ini文件中的x、y和next_y,也就是page、page_size、index,如x=1,y=1000,next_y=242 作为入参传给查询接口,x表示请求第1页,y表示每页1000条,next_y则作为索引值、提取这1000条数据中的第242条数据
② 测试用例中调用该方法,读写配置文件
import api_test.config.page_config as page_config
@pytest.mark.rs_smoke
@allure.story("企业管理")
def test_company_manager(self, rs_resource, rs_admin_login, rs_get_admin_user_info, use_db):
"""测试企业增改查接口"""
user_id = rs_admin_login
cpy_id = rs_get_admin_user_info
# 调用方法获取上次读取的位置
config_data = page_config.get_next_data("company_data")
x = config_data[0]
y = config_data[1]
next_y = config_data[2]
get_company_list = rs_resource.get_company_list(cpy_id, user_id, x, y)
company_list = get_company_list["d"]
company_name = company_list[next_y]["a"]
company_simple = company_list[next_y]["a"]
company_num = company_list[next_y]["d"]
company_manager = self.fake.name()
company_phone = self.fake.phone_number()
company_pwd = 123456
company_type = 3
sort_id = str(random.randint(1, 100))
try:
with allure.step("调用添加企业接口"):
add_company = rs_resource.add_company(cpy_id, user_id, company_name, company_manager, company_phone,
company_pwd, company_simple, company_num, company_type)
# 当错误码返回254,说明该企业信息已存在
# 此时再调用get_next_data方法,next_y +1
while add_company["a"] == 254:
config_data = page_config.get_next_data("company_data")
x = config_data[0]
y = config_data[1]
next_y = config_data[2]
get_company_list = rs_resource.get_company_list(cpy_id, user_id, x, y)
company_list = get_company_list["d"]
company_name = company_list[next_y]["a"]
company_simple = company_list[next_y]["a"]
company_num = company_list[next_y]["d"]
add_company = rs_resource.add_company(cpy_id, user_id, company_name, company_manager, company_phone,
company_pwd, company_simple, company_num, company_type)
assert add_company["a"] == 200
self.company_user_id = add_company["d"]
select_db = use_db.execute_sql(
f"SELECT * FROM t_r_company_base WHERE user_id = {self.company_user_id}") # 查询数据库是否存在新增的数据
assert company_name in str(select_db)
从上面的测试用例可以看出:
1、测试用例会先调用读取ini配置文件的方法get_next_data,读取到的配置为x=1、y=1000和next_y=242
2、将配置作为参数传递给get_company_list接口,获取企业列表并提取第242条数据
3、将第242条数据相关字段值传递给add_company新增企业接口,若code为200表示新增成功,若返回的code码是254,则表明企业信息已存在
4、当企业信息已存在时,再次调用读取配置文件方法get_next_data,更改ini配置文件、使next_y+1,提取第243条数据,并继续新增企业,断言返回值,以此循环,直到拿到的是不重复的数据、新增企业成功
5、最后查询数据库,断言返回值中的企业ID与数据库查到的是否一致
2.优缺点分析
在真正回归测试过程中,上述方案是可以正常运行的,但也面临诸多问题,下面深入分析该设计的优缺点:
优点
方便,运行完了,产生的数据可以不用处理,整个过程无需人工干预;
缺点
造成大量数据冗余:因为运行后的数据放任不管,如果运行1000次,那么数据表中就会产生1000条企业数据和相关关联数据,如果次数更多,冗余数据必定会更多,也会给前端页面的使用造成一定的压力;
运行次数有上限:因为是通过配置文件,不断读取第三方视图中的企业数据,然后添加这些企业数据到我们的系统中,尽管目前三方企业数据量较多,大概有一万多条,但总有用完的一天,如果运行一万次,最后一页的最后一条也被添加过了,就会达到数据量上限,那么再次运行必定会造成数据重复、添加失败;
调试不方便、执行效率低:我一直比较倾向于配置写在py文件中,而不是yaml或ini文件中,这样就可以不用再定义一个单独的方法来读取配置,从而减小层层调用而导致的出错概率。不过这个不是重点,重点是会造成执行效率慢的问题,因为我们组内代码是同步到gitlab的,配置文件也包含在内。但如果其中A人员执行了50次,next_y会从242自增到292并写入配置文件,而B人员此时没有更新代码,配置文件的next_y依旧为242,那么他执行时前50次都会重复,因为那50条数据已经被用过了,直到next_y自增到293条数据才能使用,这50条while循环读写产生的时间就是浪费的时间,如果中间相差的次数更多500甚至5000次,那么执行效率就会更加低下;
配置文件不统一,git管理不便:试想一下,每执行一次测试用例,配置文件(nexy_y)就会发生改变一次,git文件状态也就变化一次,也就意味着每执行一次就要提交一次代码!或许你会说不提交就是了,那如果A、B两个测试人员的代码长期不统一,就会陷入上一个问题中由配置文件长时间不同步而造成的执行效率低下的因果循环中去;
说了这么多,总结下来就是:配置文件如果提交,就意味着每次都要提交,然后每个人在执行前git pull一次、执行完了git push一次;不提交的话就意味着每个人的配置文件不一样,其中一个人运行的次数越多,其他人运行的效率就越低。好吧,确实挺痛苦。说到底还是设计模式的问题,配置文件在git管理下不能轻易产生变动,运行结果的好坏更不能严重依赖配置文件!
二、改造过程
既然面临那么多问题,那就只有改造了,俗话说“不破不立”!写代码,不仅要保证代码能运行起来,还要从各个方面确保代码的健壮性。设计产品和设计测试用例也是一样。以下是整体业务分析和测试用例改造过程:
1.日志分析
早在开始之初就听说添加企业这个接口涉及的表查询、插入特别多,会产生诸多的业务关联数据,处理起来也会比较麻烦,今日一试,果然如此。
开发没有提供删除接口,但有新增接口,如果我能找到新增企业时插入了哪些数据,再反向将这些数据一一删除,不也就相当于实现了删除接口的功能了吗?说干就干,先分析接口日志(过程确实比较长,核心思想就是:根据后台日志一点一滴梳理数据的流向,插入了哪张表、哪些数据,并找出数据表中的唯一能代表该条数据的字段值,如ID、手机号等,以便于后面设计删除该条数据的SQL语句):
接口请求及参数
我一遍手动新增一个企业,一遍观察后台日志。在新增企业接口请求及返回的打印日志如下:

查询手机号

在插入账户表前,会先调用一个c.f.r.m.AccountMapper.queryUserPhone的方法,查询数据库中是否存在相同的手机号,不存在则返回0,只有返回数据为0 ,才会执行后续的插入数据操作
调用注册接口
如果手机号不重复,则会调用注册接口,成功后返回数据:respContent: 473036,即用户的user_id

后面就是调用注册接口后一系列的关联表查询和写入数据了
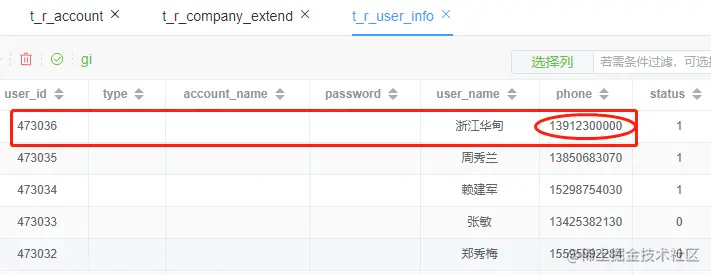
t_r_user_info 表写数据

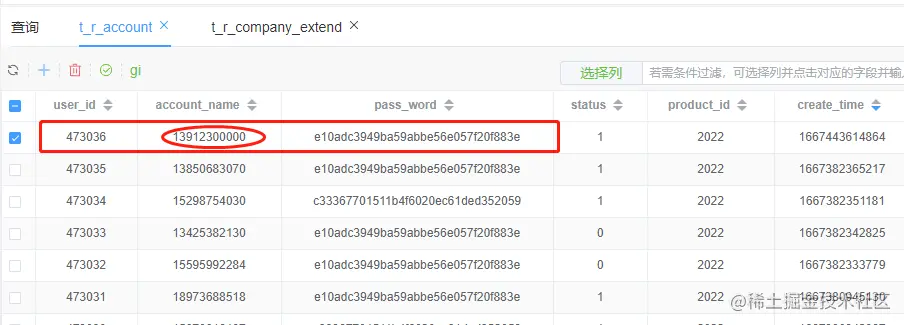
insert into t_r_user_info ( user_id, user_name, phone, `status`, product_id, create_time ) values ( 473036, 浙江华甸, 13912300000, 1, 2022, 1667443614864 )
查看数据表,数据用户信息数据已经写入,由于手机号是唯一的,所以可以根据手机号删除本表对应数据
t_r_account 账户表写数据

select user_id, account_name, pass_word, `status`, product_id, create_time, update_time, ext1, ext2, ext3 from t_r_account where account_name = 13912300000 and product_id = 2022 and status = 1 limit 1
查看数据表,账户数据已经写入,统一也可以根据手机号删除本表对应数据
t_r_post 岗位表查询数据

select id, company_id, post_code, post_name, remark, `status`, creator, create_time, ext1, ext2, ext3,classify from t_r_post where post_code = 16 and company_id = 0 order by status DESC limit 1
查询post_code为16,company_id为0的这条数据
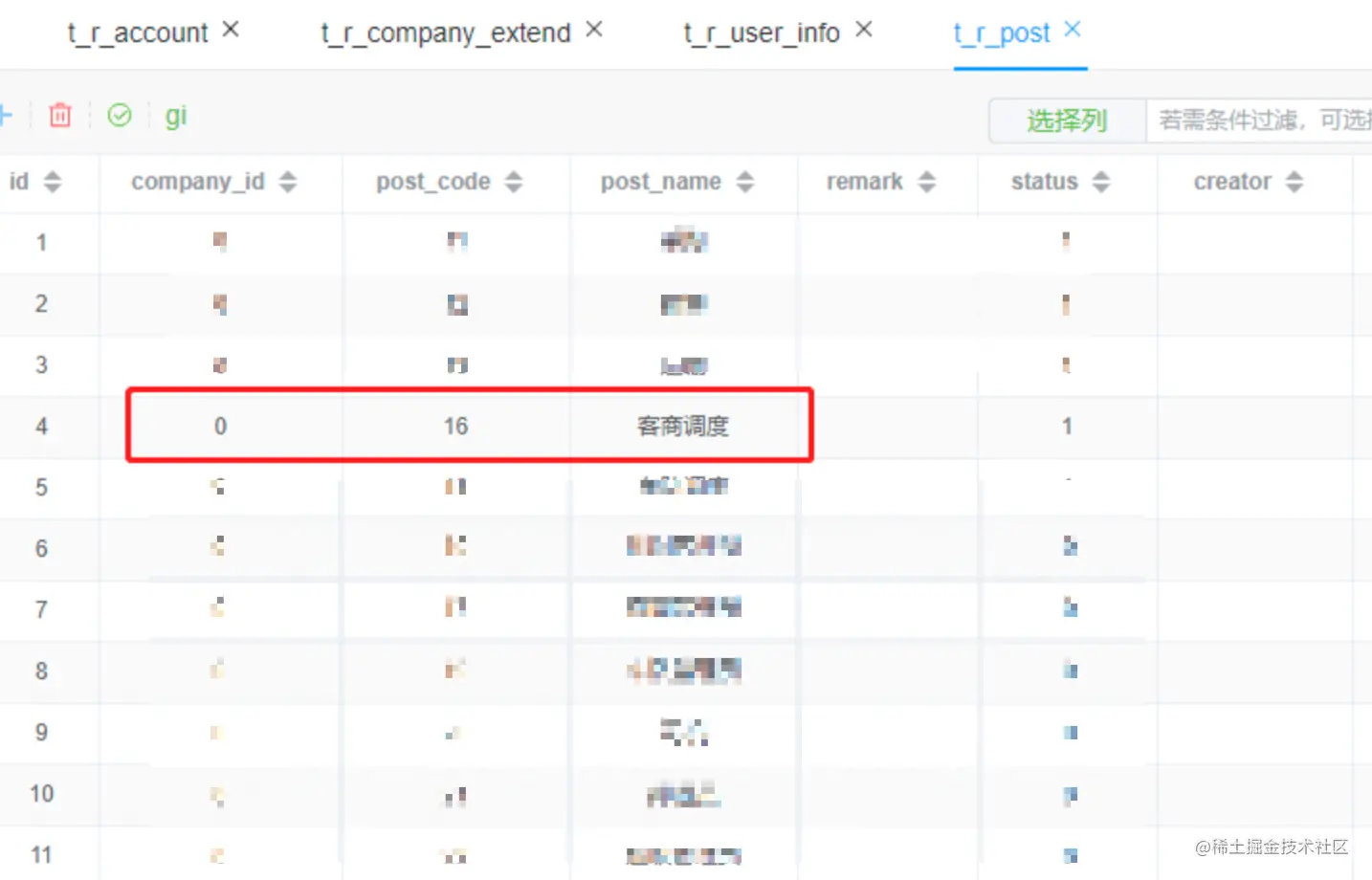
因为是查询操作,所以无需还原数据
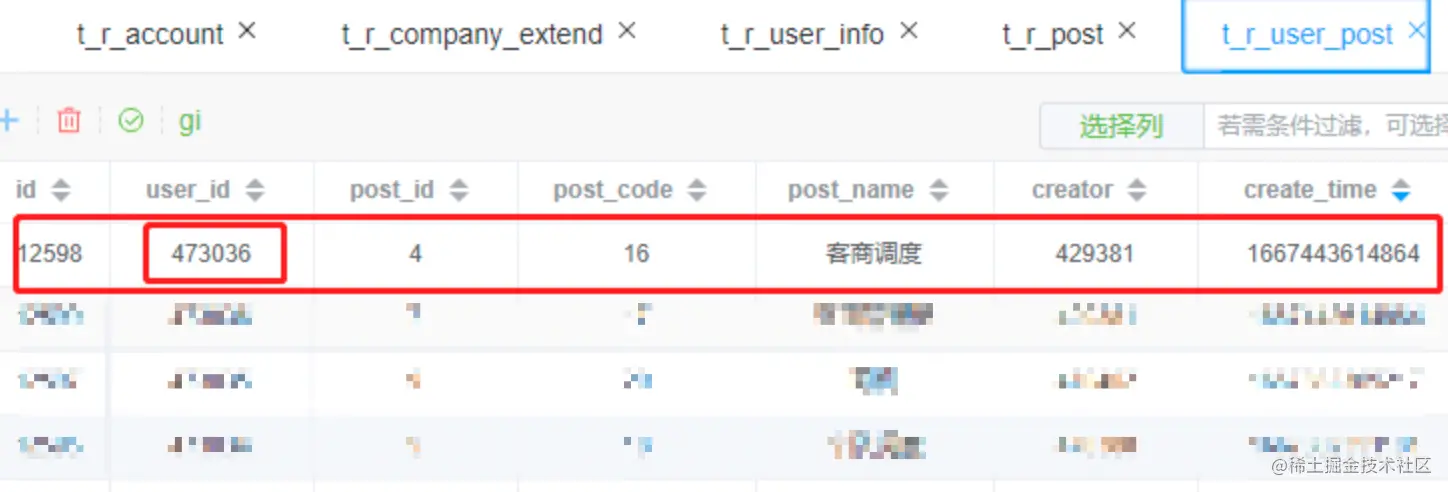
t_r_user_post 人员岗位表写数据

insert into t_r_user_post ( user_id, post_id, post_code, post_name, creator, create_time ) values ( 473036, 4, 16, 客商调度, 429381, 1667443614864 )
插入后的数据如下,可以根据id和user_id来删除本条数据
t_r_post 岗位表查询数据

select id, company_id, post_code, post_name, remark, `status`, creator, create_time, ext1, ext2, ext3,classify from t_r_post where post_code = 17 and company_id = 0 order by status DESC limit 1
查询到的数据如下:
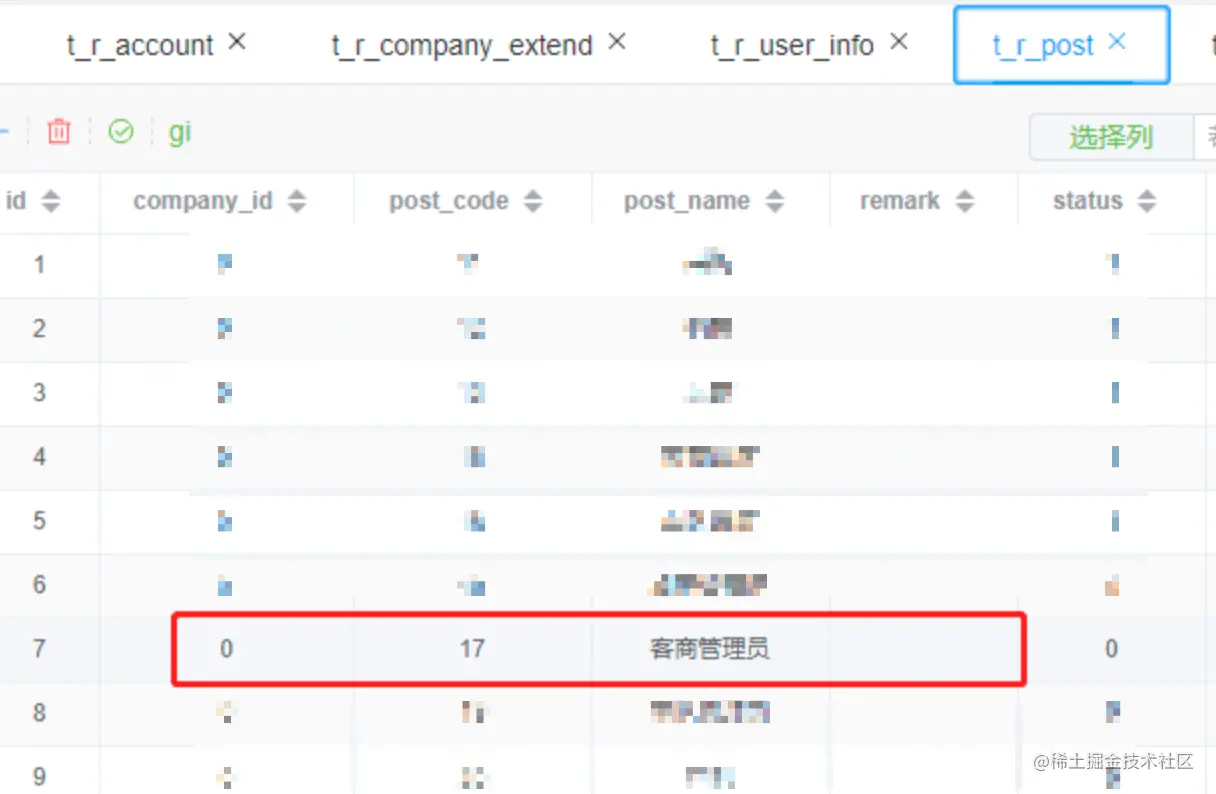
因为是查询操作,所以无需还原数据
t_r_user_post 人员岗位表写数据

insert into t_r_user_post ( user_id, post_id, post_code, post_name, creator, create_time ) values ( 473036, 7, 17, 客商管理员, 429381, 1667443614864 )
插入数据如下:
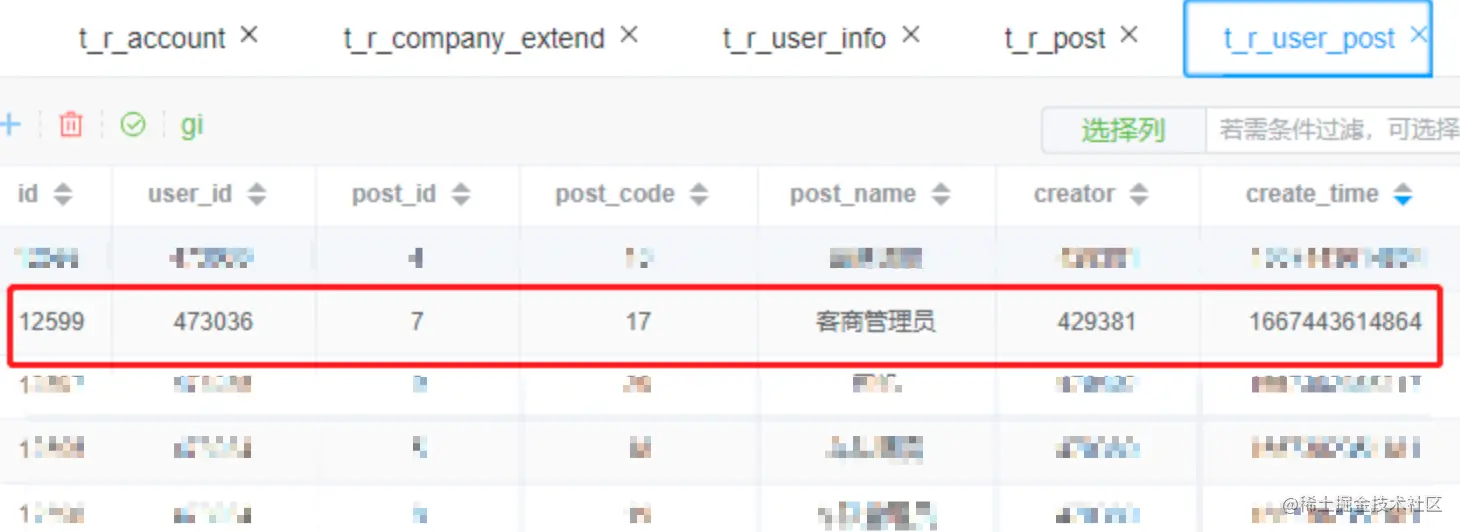
其实稍微观察一下就可以发现,t_r_user_post表写了两次数据,也就是插入了两条user_id为473036的数据(因为新增的用户会默认同时存在两个角色,因此本表会插入两条数据,一个岗位ID为16-客商调度,一个岗位ID为17-客商管理员)。所以可以根据user_id删除对应数据
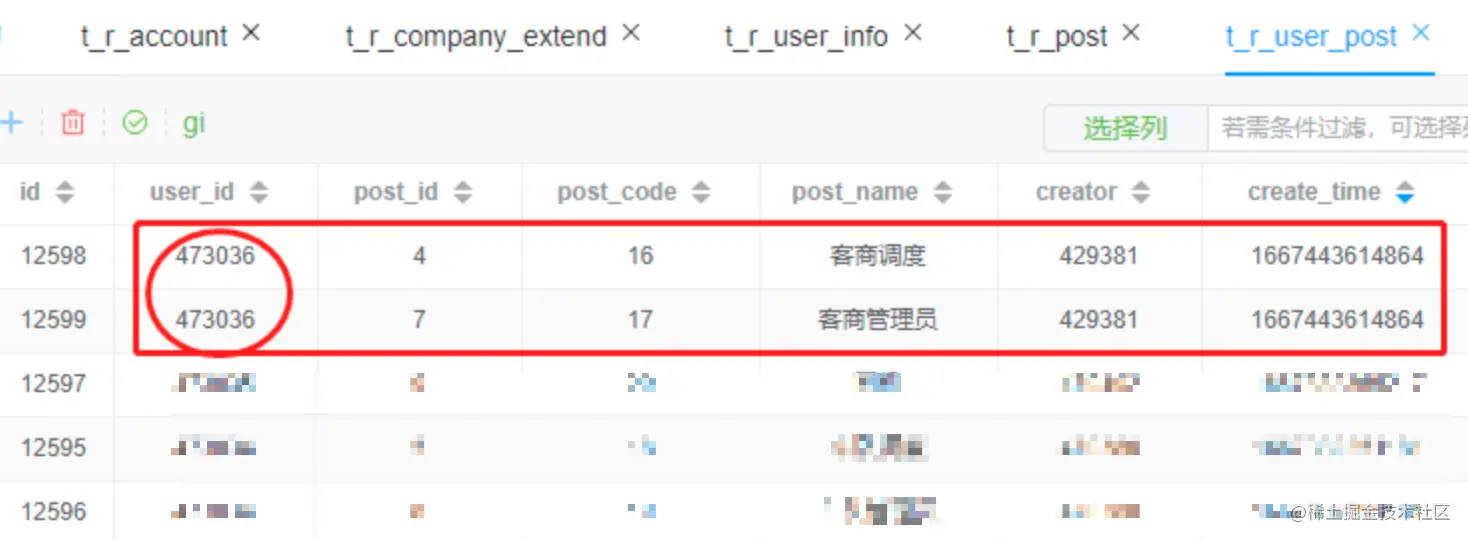
t_r_user_company 人员客商关系表写入数据

insert into t_r_user_company(user_id, cpy_id, type, create_time, creator_id, updater_id, update_time, ext1, ext2, ext3,company_id) values (473036, 10306, 2, 1667443614864, 429381, null, null, null, null, null,10306)
插入数据如下,可以根据user_id删除对应数据
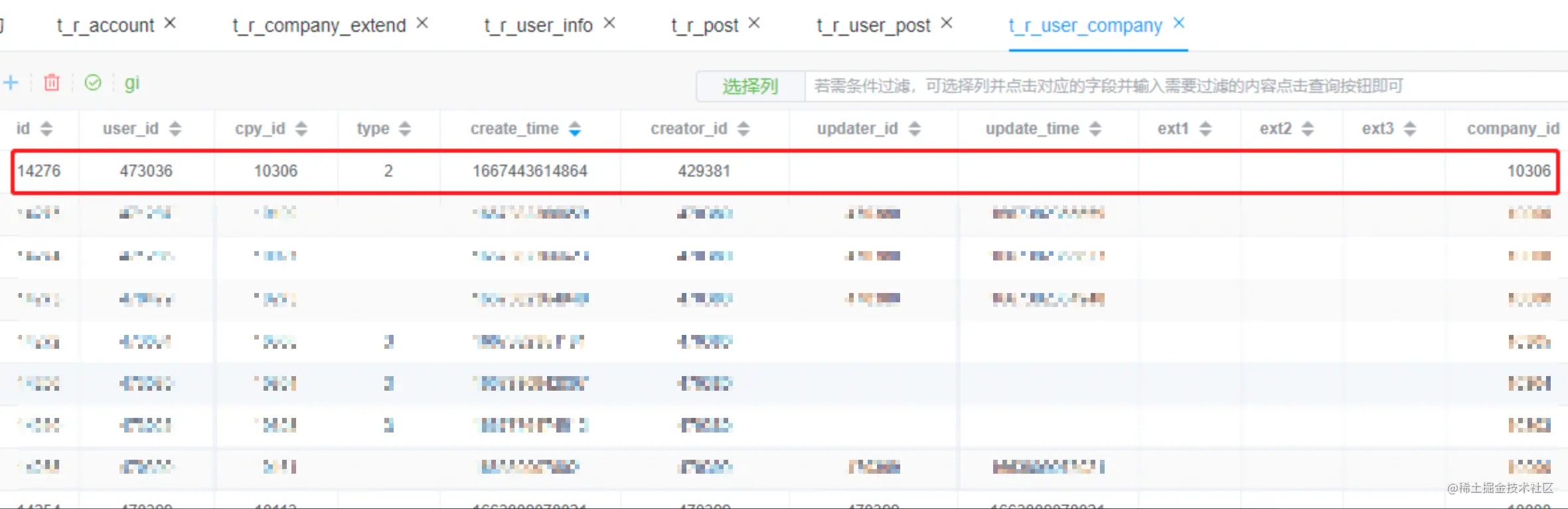
t_r_company_extend 企业扩展表写数据

insert into t_r_company_extend (company_id, ext_name, ext_code, ext_value, create_time) values (10306, 简称,cpySimpleName, 浙江华甸防雷科技, 1667443614864) , (10306, 企业编码,cpyCode, xchdfl, 1667443614864)
根据日志和SQL语句可以得知,插入了两条数据,插入的数据如下图所示。后续可以根据cpy_id删除本表对应数据
t_r_location 坐标表写入数据

insert into t_r_location ( company_id, `name`, addr, addr_detail, addr_point, `status`, contact_company, contact_name, contact_phone, user_id, create_time ) values ( 10306, 浙江华甸防雷科技, 山西省-长治市-襄垣县, 山西省长治市襄垣县古韩镇山西机电职业技术学院(东湖校区), 113.065637,36.542198, 1, 浙江华甸防雷科技股份有限公司(String), 浙江华甸, 13912300000, 473036, 1667443614864 )
插入数据如下,后续可以根据company_id删除记录表中的数据
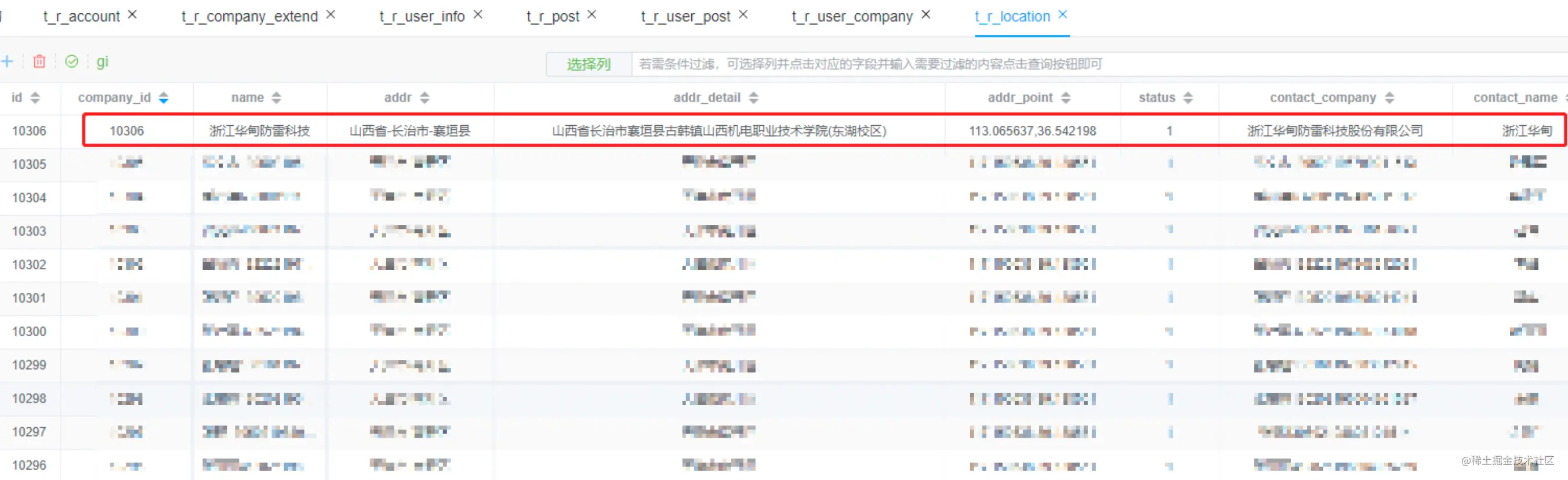
t_r_location与t_r_company_base 坐标表与企业基础表连表查询数据
select l.id, l.company_id, l.`name`, l.addr, l.addr_detail, l.addr_point, l.`status`, l.contact_company, l.contact_name, l.contact_phone, l.user_id, l.create_time from t_r_location l left join t_r_company_base b on l.company_id = b.id where b.ext1 = 1 and b.status = 1
查询到的数据如下:
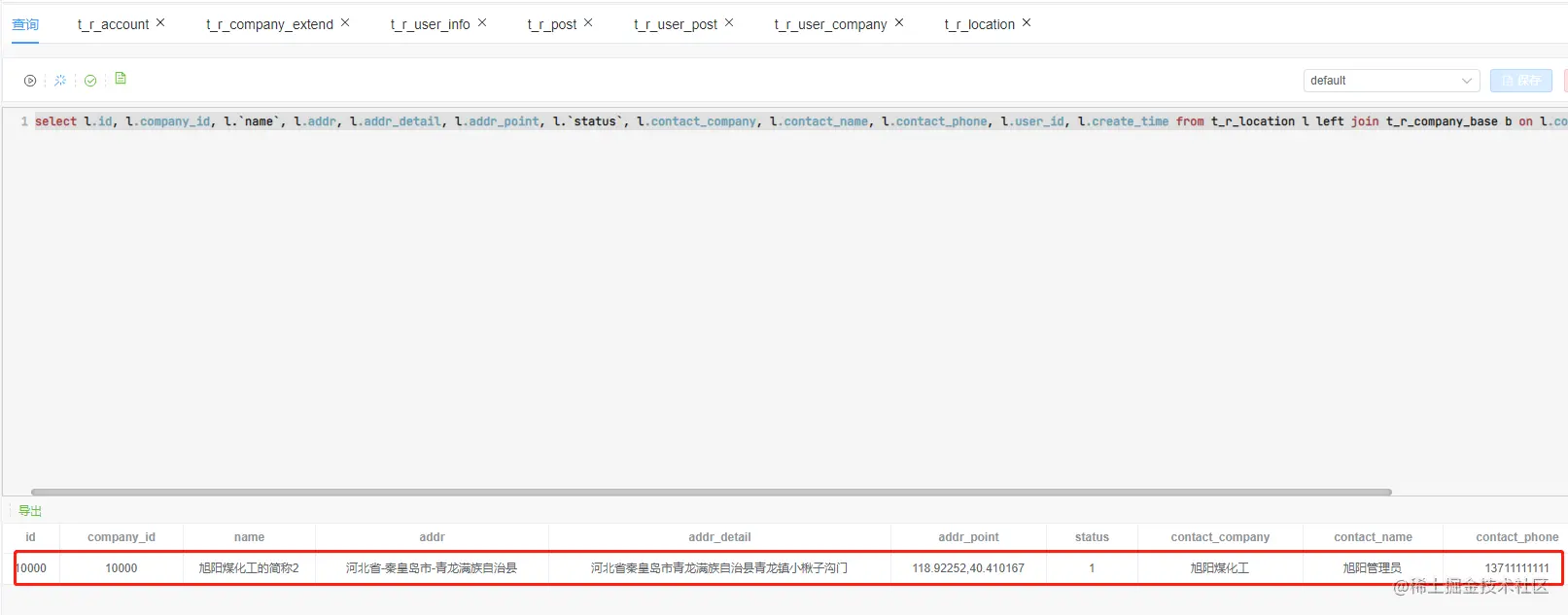
因为是查询操作,所以无需还原数据
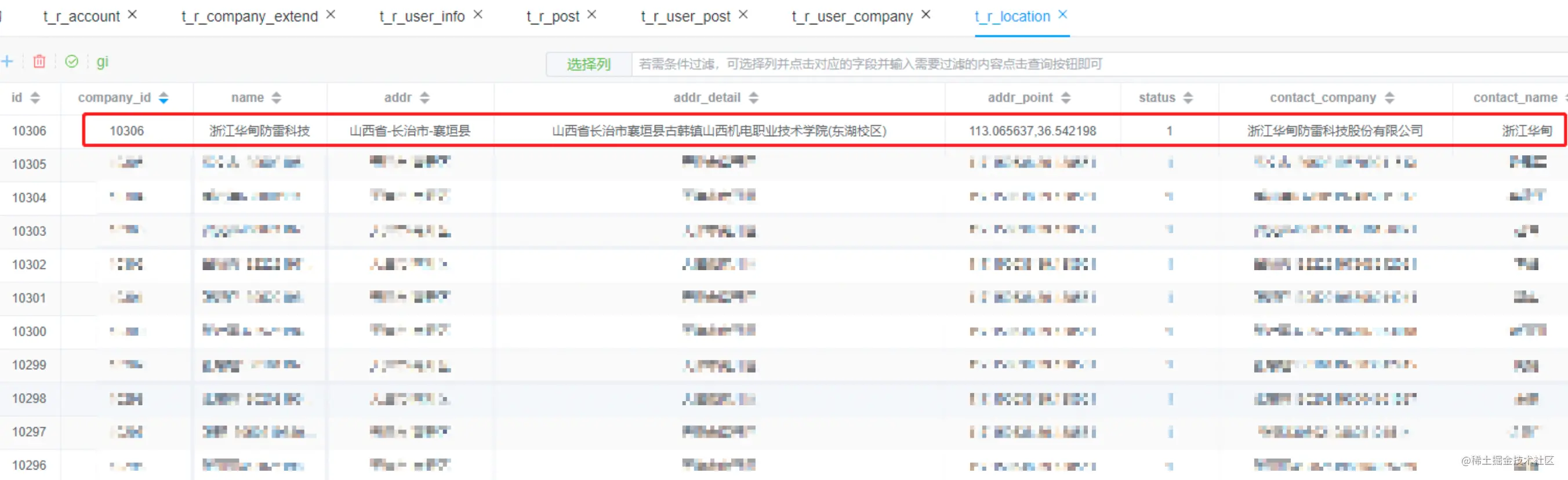
t_r_transport_line 运输线路表中插入数据

insert into t_r_transport_line ( company_id, `name`, load_location_id, unload_location_id, create_time, creator_user_id ) values ( 10306, 旭阳煤化工的简称2-浙江华甸防雷科技, 10000, 10306, 1667443614864, 429381 )
插入数据如下,因为线路是双向的,所以有两条数据。后续可以根据company_id删除数据
t_r_transport_line_point 线路途经点信息表写入数据
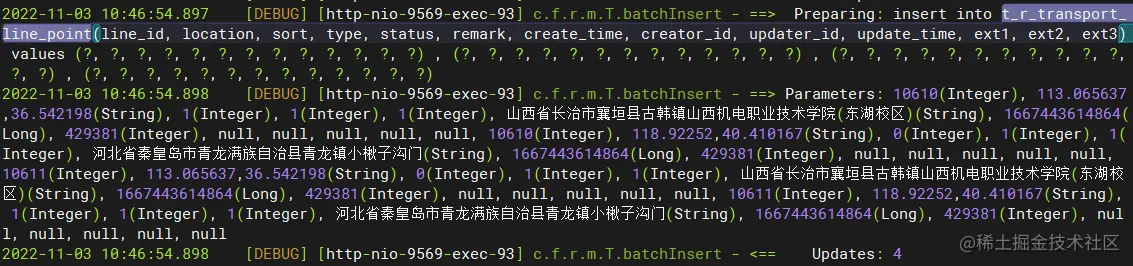
insert into t_r_transport_line_point(line_id, location, sort, type, status, remark, create_time, creator_id, updater_id, update_time, ext1, ext2, ext3) values (10610, 113.065637,36.542198, 1, 1, 1, 山西省长治市襄垣县古韩镇山西机电职业技术学院(东湖校区), 1667443614864, 429381, null, null, null, null, null) , (10610, 118.92252,40.410167, 0, 1, 1, 河北省秦皇岛市青龙满族自治县青龙镇小楸子沟门, 1667443614864, 429381, null, null, null, null, null) , (10611, 113.065637,36.542198, 0, 1, 1, 山西省长治市襄垣县古韩镇山西机电职业技术学院(东湖校区), 1667443614864, 429381, null, null, null, null, null) , (10611, 118.92252,40.410167, 1, 1, 1, 河北省秦皇岛市青龙满族自治县青龙镇小楸子沟门, 1667443614864, 429381, null, null, null, null, null)
根据日志和SQL语句可以得知,插入了4条数据,插入的数据如下图所示
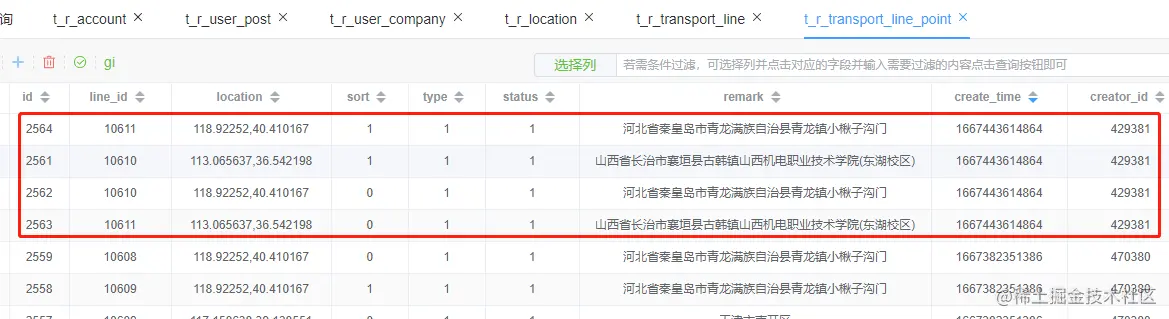
这里数据删除比较麻烦,这里要先从t_r_transport_line表中根据company_id查到id,该id也就是t_r_transport_line_point表中的line_id,再根据line_id进行删除。
执行指定实现类

t_r_orgination 组织表写入数据
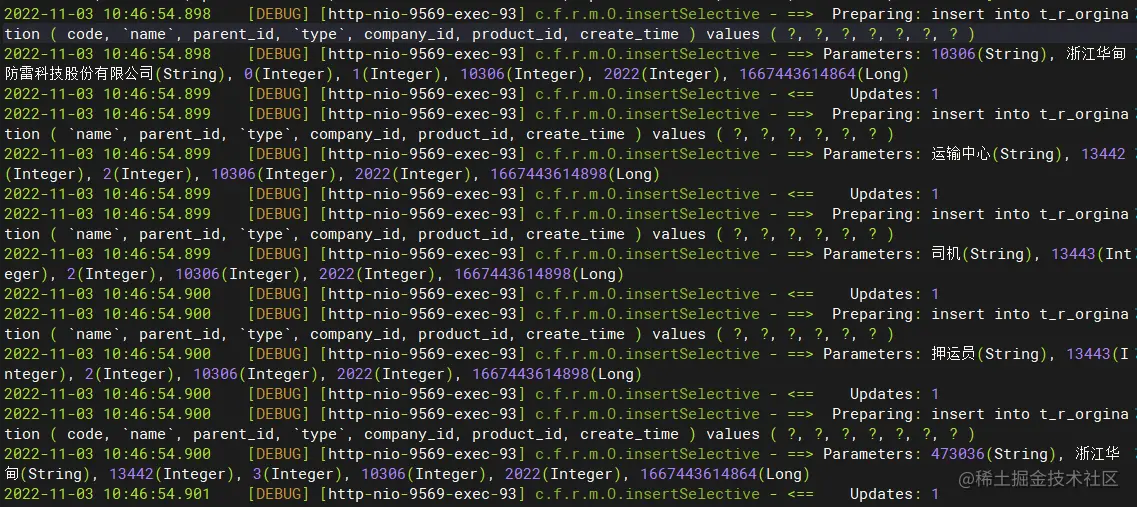
一共执行5条insert操作
insert into t_r_orgination ( code, `name`, parent_id, `type`, company_id, product_id, create_time ) values ( 10306, 浙江华甸防雷科技股份有限公司, 0, 1, 10306, 2022, 1667443614864 )
insert into t_r_orgination ( `name`, parent_id, `type`, company_id, product_id, create_time ) values ( 运输中心, 13442, 2, 10306, 2022, 1667443614898 )
insert into t_r_orgination ( `name`, parent_id, `type`, company_id, product_id, create_time ) values ( 司机, 13443, 2, 10306, 2022, 1667443614898 )
insert into t_r_orgination ( `name`, parent_id, `type`, company_id, product_id, create_time ) values ( 押运员, 13443, 2, 10306, 2022, 1667443614898 )
insert into t_r_orgination ( code, `name`, parent_id, `type`, company_id, product_id, create_time ) values ( 473036, 浙江华甸, 13442, 3, 10306, 2022, 1667443614864 )
一共插入了5条数据,后续可以根据company_id删除对应数据
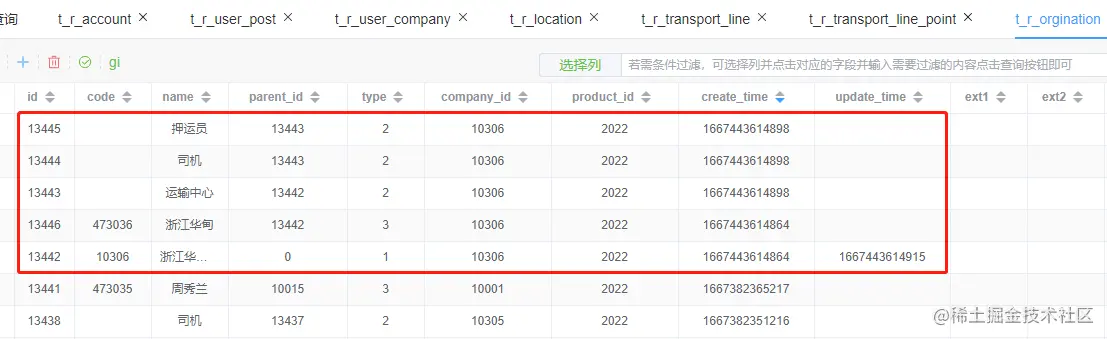
t_r_orgination 组织表查询数据

select id, code, `name`, parent_id, `type`, company_id, product_id, create_time, update_time, ext1, ext2, ext3,person_count,im_group_id from t_r_orgination where id = 13442
因为是查询操作,所以无需还原数据
t_r_orgination 组织表更新数据

update t_r_orgination SET code = 10306, `name` = 浙江华甸防雷科技股份有限公司, parent_id = 0, `type` = 1, company_id = 10306, product_id = 2022, create_time = 1667443614864, person_count = 1, im_group_id = 0 where id = 13442
t_r_orgination 表查询数据

select id, code, `name`, parent_id, `type`, company_id, product_id, create_time, update_time, ext1, ext2, ext3,person_count,im_group_id from t_r_orgination where id = 0
从日志可以看出,没查到任何数据
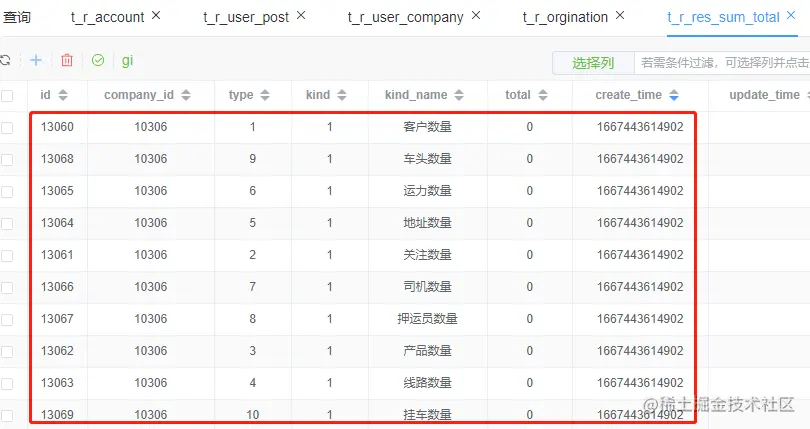
t_r_res_sum_total 资料统计表插入数据
insert into t_r_res_sum_total (company_id, `type`, kind, kind_name, total, create_time, update_time, ext1, ext2, ext3) values (10306, 1, 1, 客户数量, 0, 1667443614902, null, null, null, null) , (10306, 2, 1, 关注数量, 0, 1667443614902, null, null, null, null) , (10306, 3, 1, 产品数量, 0, 1667443614902, null, null, null, null) , (10306, 4, 1, 线路数量, 0, 1667443614902, null, null, null, null) , (10306, 5, 1, 地址数量, 0, 1667443614902, null, null, null, null) , (10306(, 6, 1, 运力数量, 0, 1667443614902, null, null, null, null) , (10306, 7, 1, 司机数量, 0, 1667443614902, null, null, null, null) , (10306, 8, 1, 押运员数量, 0), 1667443614902, null, null, null, null) , (10306, 9, 1, 车头数量, 0, 1667443614902, null, null, null, null) , (10306, 10, 1, 挂车数量, 0, 1667443614902, null, null, null, null)
一共插入了10条数据,后续可以根据company_id删除数据
t_o_product 表查询数据

通过日志可以看出,没有任何参数,所以未查出数据
结束 执行公共实现类

调用操作日志记录接口
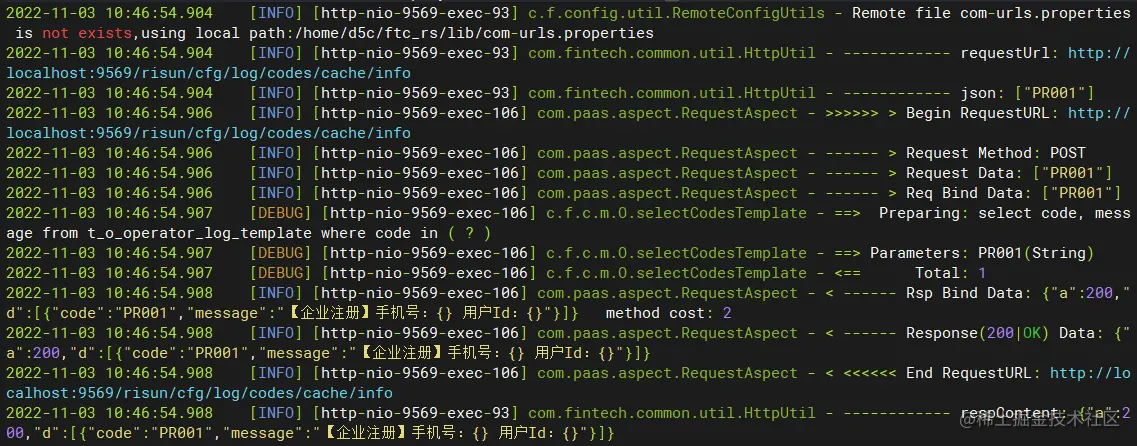
t_r_operator_log 操作日志表写入数据
insert into t_r_operator_log ( order_id, code, `type`, remark, company_id, user_id, create_time ) values ( 473036, PR001, 1, 【企业注册】手机号:13912300000 用户Id:473036, 10000, 429381, 1667443614908 )
插入数据如下,后续可以根据company_id删除数据
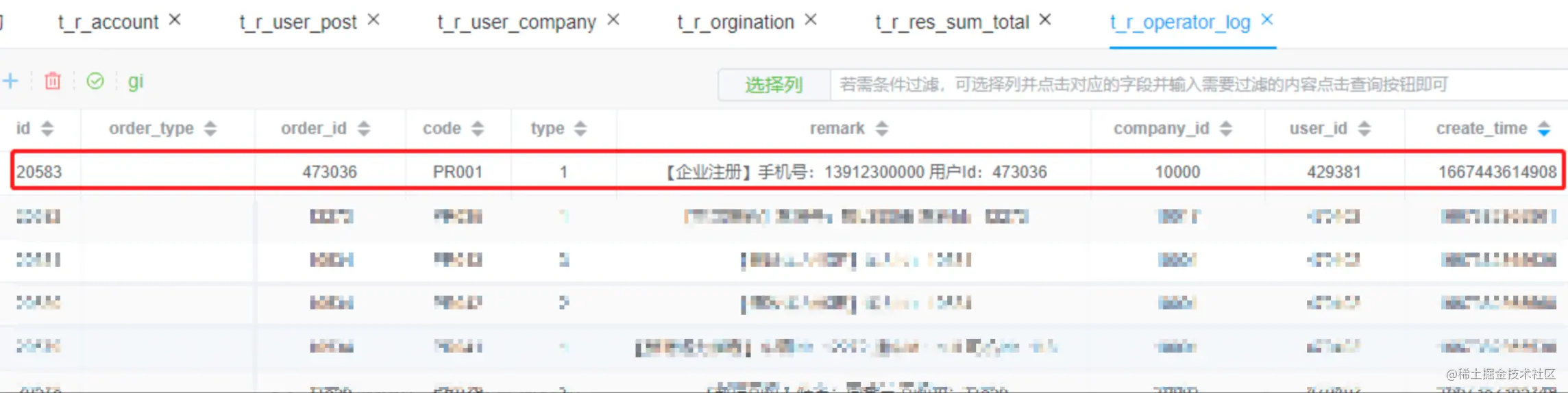
t_r_orgination 组织表查询数据

Preparing: select id, code, `name`, parent_id, `type`, company_id, product_id, create_time, update_time, ext1, ext2, ext3,person_count,im_group_id from t_r_orgination WHERE company_id = 10306 and code = 10306 and `type` = 1 order by create_time desc,id desc limit 1
t_r_orgination 组织表更新数据

update t_r_orgination SET code = 10306, `name` = 浙江华甸防雷科技股份有限公司, parent_id = 0, `type` = 1, company_id = 10306, product_id = 2022, create_time = 1667443614864, update_time = 1667443614915, person_count = 1, im_group_id = 111150 where id = 13442
更新数据如下,后续可以根据company_id删除数据
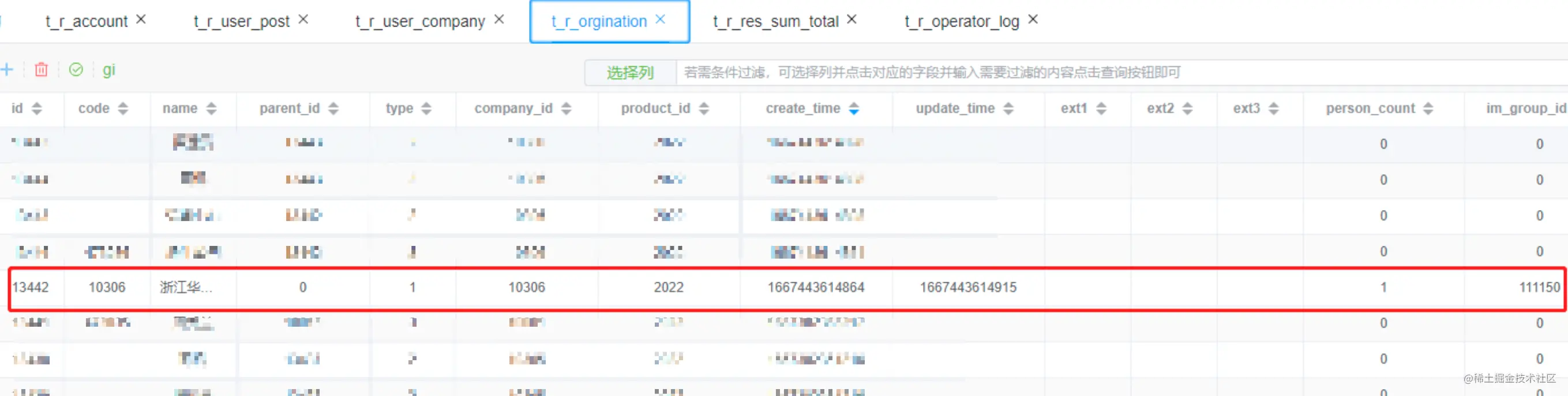
t_r_qualification_alert_config 资质告警资料配置表插入数据
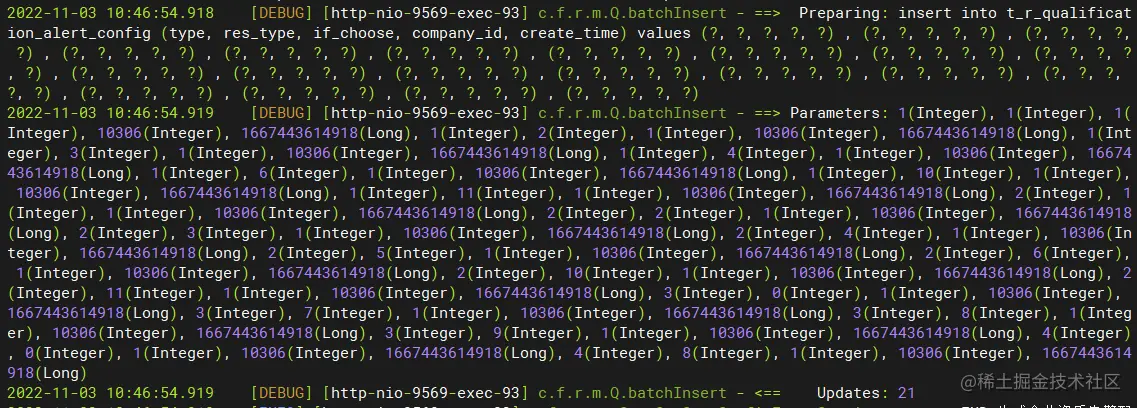
一共插入了21条数据,插入数据如下,后续可以根据company_id删除数据
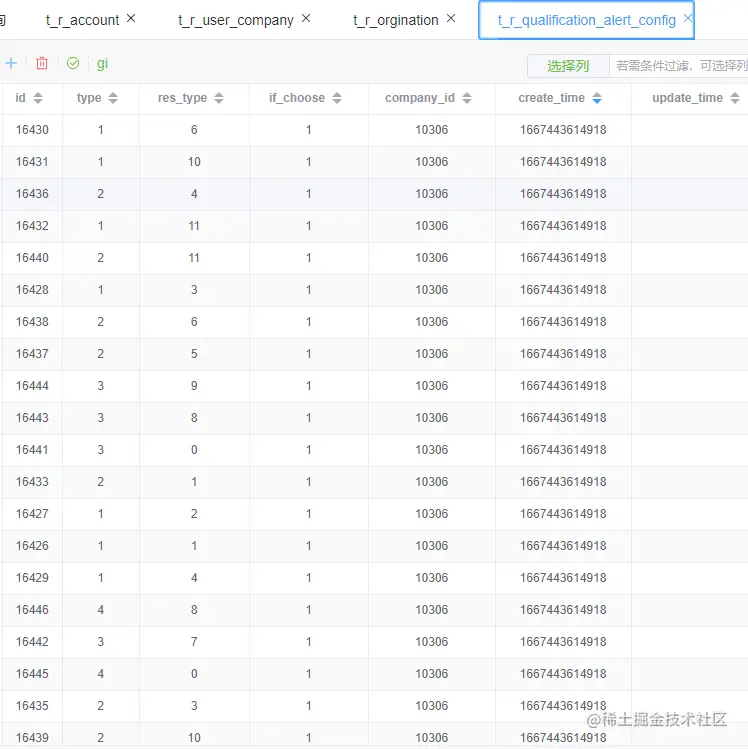
2.设计删除策略
从上述的日志分析过程可以看出,添加企业这个动作,一共涉及了15张数据表的查询、插入、更新和删除操作,其中14张表涉及到数据插入。查询就不管了,只分析哪几张表写入了哪些数据以及如何删除即可。经过梳理总结,得出:
t_r_company_base 表写入1条数据,可根据phone_number查询到id和user_id,这一步最关键,这个id实际就是其他数据表所用到的company_id,可通过phone_number删除;
t_r_user_info 表写入1条数据,可通过user_id删除;
t_r_account 表写入1条数据,可通过user_id删除;
t_r_user_post 表写入2条数据,可通过user_id删除;
t_r_user_company 表写入1条数据,可通过company_id删除;
t_r_msds_company 表写入1条数据,可通过code(company_id)删除;
t_r_company_extend 表写入2条数据,可通过company_id删除;
t_r_orgination 表共写入5条数据,可通过company_id删除;
t_r_location 表写入1条数据,可通过company_id删除;
t_r_transport_line 表写入2条数据,可通过company_id删除;
t_r_res_sum_total 表共写入10条数据,可通过company_id删除;
t_r_operator_log 表写入1条数据,可通过company_id删除;
t_r_qualification_alert_config 表共写入21条数据,可通过company_id删除;
t_r_transport_line_point 表共写入4条数据,这个处理稍微繁琐一点,先从t_r_transport_line表中根据company_id查到id,该id也就是t_r_transport_line_point表中的line_id,再根据line_id进行删除;
3.编写删除数据的SQL语句
SQL语句如下,将其直接封装到一个静态方法delete_company_data中,直接在测试用例中调用即可,这样做的好处是:
1、可以避免测试用例代码较多,只需调用该方法、传入一个企业联系人手机号和一个数据库实例;
2、即使后面添加企业接口发生变更,产生了更多关联数据,也只需修改本方法,而无需修改测试用例;
@staticmethod
def delete_company_data(use_db, phone_number):
"""
删除新增企业产生的相关数据
:param use_db: 数据库实例
:param phone_number: 企业联系人手机号
:return:
"""
# 查询企业ID
select_add_company_id = f"SELECT id FROM t_r_company_base WHERE `contact_phone`={phone_number};"
# 查询用户ID
select_add_user_id = f"SELECT user_id FROM t_r_company_base WHERE `contact_phone`={phone_number};"
add_company_id = use_db.execute_sql(select_add_company_id)[0]
add_user_id = use_db.execute_sql(select_add_user_id)[0]
# 查询线路ID
select_line_id = f"SELECT id FROM t_r_transport_line WHERE `company_id`={add_company_id};"
line_ids = use_db.execute_sql(is_fetchall=True, sql=select_line_id)
line_id_1 = line_ids[0][0]
line_id_2 = line_ids[1][0]
# 根据company_id删除资质告警资料配置
delete_sql_1 = f"DELETE FROM t_r_qualification_alert_config WHERE company_id={add_company_id};"
# 根据company_id删除组织表相关数据
delete_sql_2 = f"DELETE FROM t_r_orgination WHERE company_id={add_company_id};"
# 根据company_id删除操作日志
delete_sql_3 = f"DELETE FROM t_r_operator_log WHERE company_id={add_company_id};"
# 根据company_id删除操作资料统计
delete_sql_4 = f"DELETE FROM t_r_res_sum_total WHERE company_id={add_company_id};"
# 删除途经点信息
delete_sql_5 = f"DELETE FROM t_r_transport_line_point WHERE line_id={line_id_1} or line_id={line_id_2};"
# 删除运输线路表数据
delete_sql_6 = f"DELETE FROM t_r_transport_line WHERE company_id={add_company_id};"
# 删除坐标表数据
delete_sql_7 = f"DELETE FROM t_r_location WHERE company_id={add_company_id};"
# 删除企业扩展表数据
delete_sql_8 = f"DELETE FROM t_r_company_extend WHERE company_id={add_company_id};"
# 删除人员客商关系表数据
delete_sql_9 = f"DELETE FROM t_r_user_company WHERE company_id={add_company_id};"
# 删除人员岗位表数据
delete_sql_10 = f"DELETE FROM t_r_user_post WHERE user_id={add_user_id};"
# 删除账户表数据
delete_sql_11 = f"DELETE FROM t_r_account WHERE user_id={add_user_id};"
# 删除用户信息表数据
delete_sql_12 = f"DELETE FROM t_r_user_info WHERE user_id={add_user_id};"
# 删除企业物料绑定关系数据
delete_sql_13 = f"DELETE FROM t_r_msds_company WHERE code={add_company_id};"
# 删除企业基础表数据
delete_sql_14 = f"DELETE FROM t_r_company_base WHERE id={add_company_id};"
# 执行各个SQL
use_db.execute_sql(delete_sql_1)
use_db.execute_sql(delete_sql_2)
use_db.execute_sql(delete_sql_3)
use_db.execute_sql(delete_sql_4)
use_db.execute_sql(delete_sql_5)
use_db.execute_sql(delete_sql_6)
use_db.execute_sql(delete_sql_7)
use_db.execute_sql(delete_sql_8)
use_db.execute_sql(delete_sql_9)
use_db.execute_sql(delete_sql_10)
use_db.execute_sql(delete_sql_11)
use_db.execute_sql(delete_sql_12)
use_db.execute_sql(delete_sql_13)
use_db.execute_sql(delete_sql_14)
4.本地调试
前面查询日志过程中已经手动添加了一个企业,手机号为13213213132,这里来验证上面定义的删除策略能否成功删除数据。直接在测试用例类中新增一条用例,引用删除数据方法,执行SQL。
def test_1111(self, use_db, rs_resource):
rs_resource.delete_company_data(use_db=use_db, phone_number=13213213132)
执行结果如下,不过这个方法并没有定义执行SQL后打印任何内容,所以在执行完成后只是正常运行没报错,看不出来是否成功删除了数据,后面还存在优化空间。
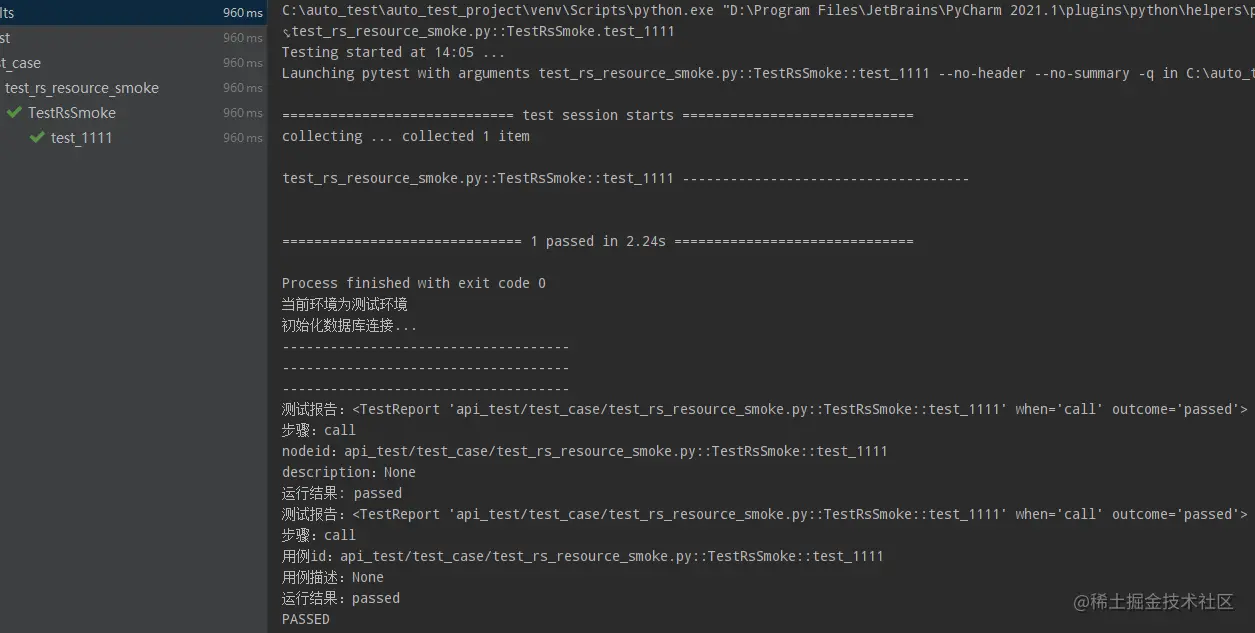
我通过手动查询各个数据表,确认各个关联数据均已删除。再次选择同一条企业数据进行新增时,依然能新增成功。
5.改造测试用例
本地调试通过后,即可改造测试用例中的逻辑。改造内容如下:
@pytest.mark.rs_smoke
@allure.story("企业管理")
def test_06_company_manager(self, rs_resource, rs_admin_login, rs_get_admin_user_info, use_db):
"""测试企业增改查接口"""
user_id = rs_admin_login
cpy_id = rs_get_admin_user_info
# 此处去除读取ini配置文件逻辑
# 随便传入一个页码,就算每次都从这一页开始,后面也会删除数据,不会导致数据重复
page = 120
get_company_list = rs_resource.get_company_list(cpy_id, user_id, page, 10)
company_list = get_company_list["d"]
company_name = company_list[0]["a"]
company_simple = company_name[0:5]
company_num = company_list[0]["d"]
company_manager = self.fake.name()
company_phone = self.fake.phone_number()
company_pwd = 123456
company_type = 3
sort_id = str(random.randint(1, 100))
try:
logger.info(f"新增企业'{company_name}'信息...")
with allure.step("调用添加企业接口"):
add_company = rs_resource.add_company(cpy_id, user_id, company_name, company_manager, company_phone,
company_pwd, company_simple, company_num, company_type)
while add_company["a"] == 254:
# 以防万一,还是加入了页码自增+1逻辑,防止这一页的数据被手动用过
page = page + 1
get_company_list = rs_resource.get_company_list(cpy_id, user_id, page, 10)
company_list = get_company_list["d"]
company_name = company_list[0]["a"]
company_simple = company_name[0:5]
company_num = company_list[0]["d"]
add_company = rs_resource.add_company(cpy_id, user_id, company_name, company_manager, company_phone,
company_pwd, company_simple, company_num, company_type)
assert add_company["a"] == 200
self.company_user_id = add_company["d"]
select_db = use_db.execute_sql(
f"SELECT * FROM t_r_company_base WHERE user_id = {self.company_user_id}") # 查询数据库是否存在新增的数据
assert company_name in str(select_db)
logger.info(f"企业'{company_name}'新增信息成功")
logger.info(f"修改企业'{company_name}'信息...")
with allure.step("调用修改企业信息接口"):
select_db = use_db.execute_sql(
f"SELECT id FROM t_r_company_base WHERE user_id = {self.company_user_id}") # 查询新增的数据的id
self.company_id = int(select_db[0])
modify_company = rs_resource.modify_company(cpy_id, user_id, self.company_id, company_name,
company_simple, company_manager)
assert modify_company["a"] == 200
logger.info(f"修改企业'{company_name}'信息成功")
logger.info(f"修改企业'{company_name}'账号...")
with allure.step("调用修改企业账号接口"):
company_new_phone = self.fake.phone_number()
modify_company_phone = rs_resource.modify_company_phone(cpy_id, user_id, self.company_user_id,
self.company_id, company_new_phone)
assert modify_company_phone["a"] == 200
logger.info(f"修改企业'{company_name}'账号成功")
logger.info(f"修改企业'{company_name}'密码...")
with allure.step("调用修改企业密码接口"):
modify_company_pwd = rs_resource.modify_company_pwd(cpy_id, user_id, self.company_user_id,
self.company_id, company_new_phone,
company_pwd='654321')
assert modify_company_pwd["a"] == 200
logger.info(f"修改企业'{company_name}'密码成功")
logger.info(f"修改企业'{company_name}'排序...")
with allure.step("调用修改企业排序接口"):
modify_company_sort = rs_resource.modify_company_sort(cpy_id, user_id, self.company_id, sort_id)
assert modify_company_sort["a"] == 200
logger.info(f"修改企业'{company_name}'排序成功")
logger.info(f"查询企业'{company_name}'信息...")
with allure.step("调用查询企业信息接口"):
query_company = rs_resource.query_company(cpy_id, user_id, company_num, company_type)
assert query_company["a"] == 200
logger.info(f"查询企业'{company_name}'信息成功")
logger.info(f"给企业'{company_name}'绑定物料...")
with allure.step("调用企业绑定物料接口"):
get_exist_product_list = rs_resource.get_exist_product_list(cpy_id, user_id, x=1, y=1000)
exist_product_list = get_exist_product_list["d"]
exist_productID_list = []
for i in exist_product_list:
aa = i["aa"]
exist_productID_list.append(aa)
exist_product_id = random.choice(exist_productID_list)
add_company_product = rs_resource.add_company_product(cpy_id, user_id, self.company_id, company_type,
exist_product_id)
assert add_company_product["a"] == 200
select_db = use_db.execute_sql(
f"SELECT * FROM t_r_msds_company WHERE code = {self.company_id}") # 查询数据库是否存在新增的数据
assert str(exist_product_id) in str(select_db)
logger.info(f"企业'{self.company_id}'和物料的绑定关系成功")
logger.info("删除新增企业产生的相关数据")
rs_resource.delete_company_data(use_db=use_db, phone_number=company_new_phone)
except AssertionError as e:
logger.info(f"企业'{company_name}'增改查失败")
raise e
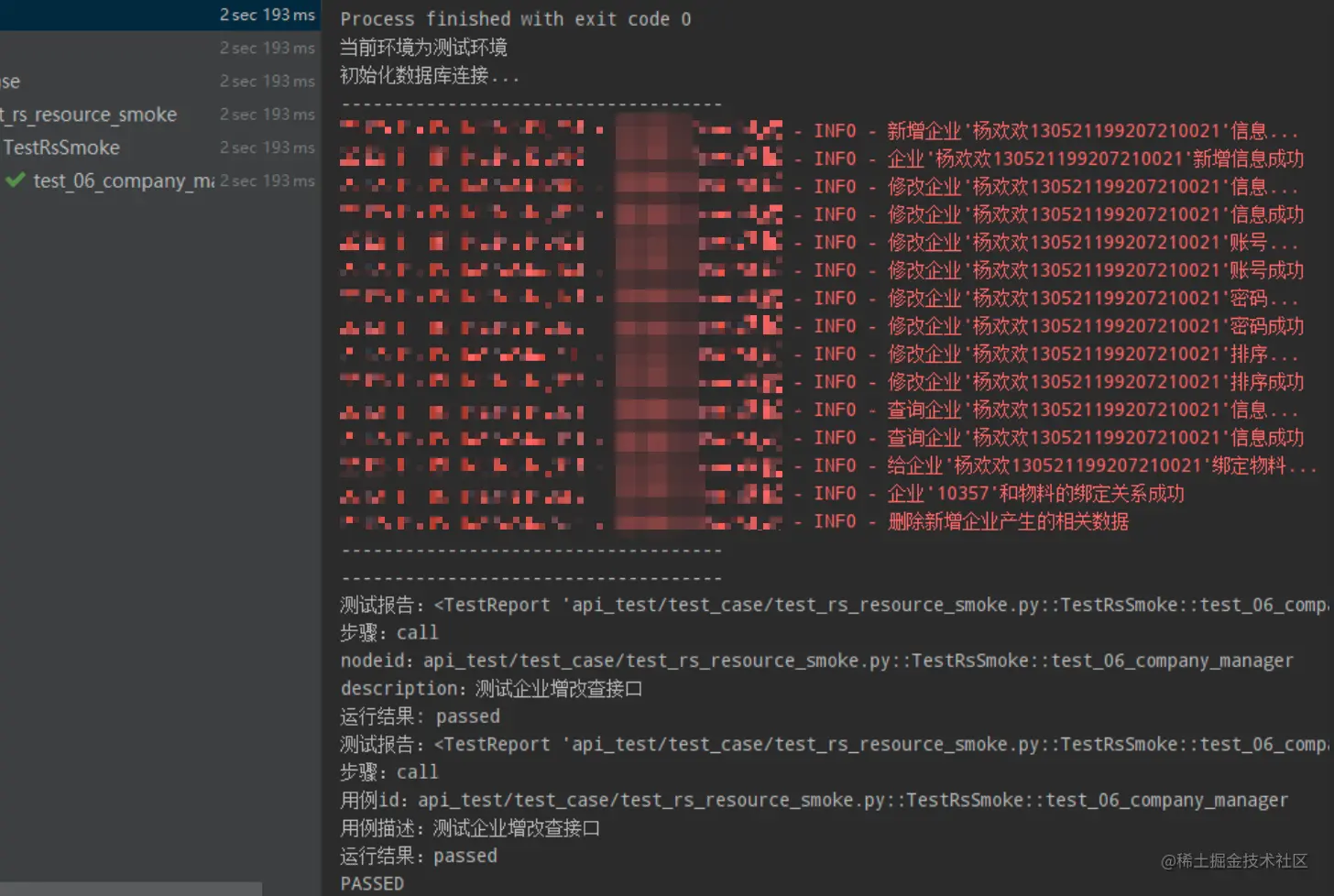
6.运行测试
测试用例运行通过,改造完成。
总结
以上就是结合实际自动化测试案例,对数据恢复的思考和改造实践。下面简单总结一下此次改造过程中的一些心得:
-
配置文件最好写在py文件中,避免单独定义一个方法来读取ini、yml等配置文件,从而加大出错概率;
-
配置文件最好不经常变动,更不要在执行过程中更改(写入)配置文件,避免带来git协同时的重复提交问题;
-
自动化测试设计与编码实现同样重要,不仅要保证业务流程能正常运行,还要保证设计的合理性和健壮性;
-
测试人员不仅要熟悉系统业务流程,还要熟悉后台实现流程,即一个手动操作或接口执行的背后究竟做了哪些动作,如执行了哪些类的哪些方法,查询、写入、更新、删除了哪些表的哪些数据,这个过程可以通过阅览开发代码和后台日志查看和梳理;
-
不要怕麻烦,越是复杂的地方可能越会有不一样的收获,比如我原本以为新增一个企业就是插入一两张表、几条数据这么简单,但实际上它背后涉及了十几张表的关联查询、插入、更新和删除;
当然,以上并不一定就是最优的设计,还存在诸多优化空间,如果你有更好的方案,欢迎留言交流!
如果你不想一个人野蛮生长,找不到系统的资料,问题得不到帮助,坚持几天便放弃的感受的话,可以加入我们的QQ群:746506216,大家可以一起讨论交流,里面会有各种软件测试资料和技术交流。
资源分享
下方这份完整的软件测试视频学习教程已经上传CSDN官方认证的二维码,朋友们如果需要可以自行免费领取 【保证100%免费】