1、背景
- 常用于分类器性能评估的指标为:准确率或错误率,也就是代价不敏感学习。
- 【注】代价:一个类别被错误分类到其他类别的惩罚(也称为权重)。
- 代价不敏感学习的前提是:
- 不同类的误分类代价相同。
- 用于学习的训练数据足够完备。
- 但上述的条件在现实中很难被满足,原因是:
- 不同类的误分类代价经常不同。
- 有些训练数据获取困难。
- 所以,提出了新的分类学习方法,即代价敏感学习。
- 代价敏感学习是解决类别不平衡问题的重要方法之一,可以提高小样本分类的准确性。
2、定义
- 代价不敏感学习的目标是最小化分类器的错误率,而代价敏感学习的目标是最小化分类器的总代价。
- 代价使用代价敏感矩阵存储:
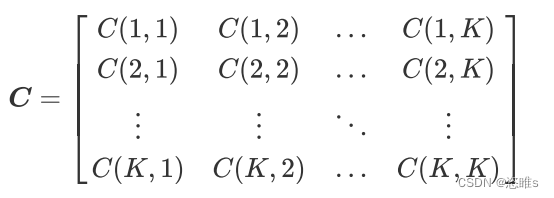 ,其中
,其中 表示类别
表示类别 错分为类别
错分为类别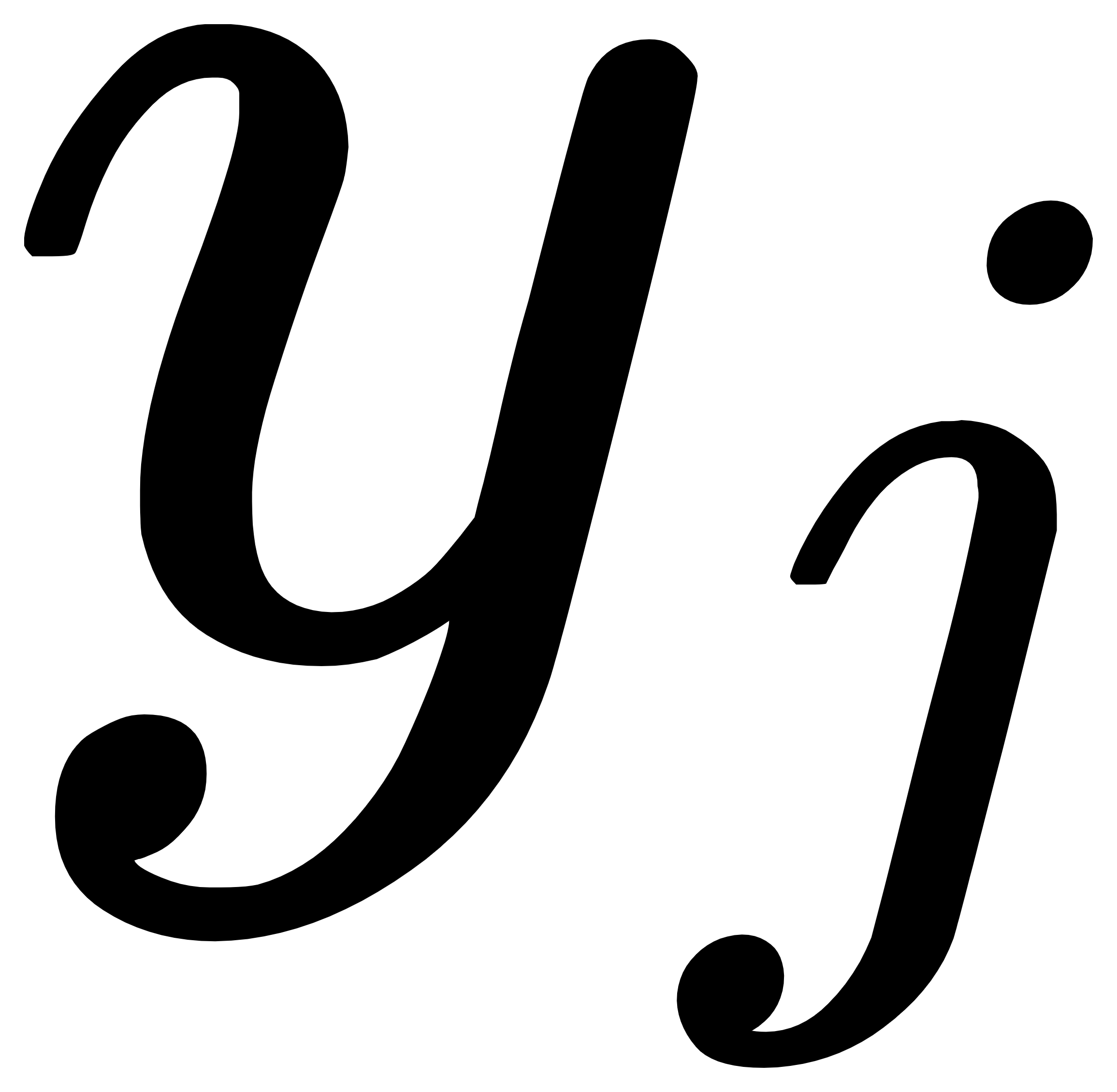 的“惩罚”或“代价”,其值不小于0。当
的“惩罚”或“代价”,其值不小于0。当 时,对应分类 正确的情况。
时,对应分类 正确的情况。
- 误分类代价敏感的分类器采用最小化代价期望之和的原则来进行分类。
- 分类器将一个待测样本 x 分类为第 i 类的代价期望为:

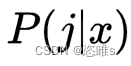 :x 被分类为第 j 类的概率。
:x 被分类为第 j 类的概率。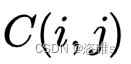 :第 i 类被分类到第 j 类的惩罚。
:第 i 类被分类到第 j 类的惩罚。 :最终目标是选择一个 i,使R最小。
:最终目标是选择一个 i,使R最小。- 如果 x 能被准确分类到类别 i 的话,那么分类到其他类别的概率就越小,(代价*概率)也就越小,代价期望之和R也就越小。
- 也就是说,被错误分类到某类别的惩罚越大,就越不会被分类到这个类别。
3、权重指定方法
- 通过以上描述可发现,代价敏感方法处理不平衡样本问题的前提是需事先指定代价敏感矩阵,其中关键是错分惩罚或错分权重的设定。
- 实际使用中可根据样本比例、分类结果的混淆矩阵等信息指定代价敏感矩阵中错分权重的具体取值。
3.1、按样本比例指定
- 假设训练样本标记共3类:a类、b类和c类,它们的样本数目比例为3 : 2 : 1。
- 则代价敏感矩阵可指定为:
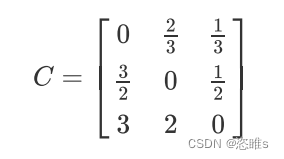
- 简单来说,当 a 类样本被错分为 b 类或 c 类时,由于其样本数较多,对应惩罚权重可设置的小一些,即 b 类或 c 类样本数与 a 类样本数的比值。
- 当 b 类样本被错分为 a 类或 c 类时,对应惩罚权重同样为 a 类或 c 类样本数与 b 类样本数的比值。
- 当样本数最少的 c 类被错分为 a 类或 b 类时,对应惩罚权重应设置大一些,以增加小样本错分代价从而体现小样本数据的重要程度。
- 当然,也可以在上述矩阵的基础上,对矩阵元素都乘上类别数的最小公倍数6,确保有效惩罚权重不小于1,即:

3.2、根据混淆矩阵指定
3.2.1、混淆矩阵
- 用二分分类举例,以下判断食物是不是汉堡。
 ,得到
,得到
- 其中,本身是汉堡,又被正确识别为汉堡的有1个;本身是汉堡,却被错误识别为不是汉堡的有1个;本身不是汉堡,却被错误识别为汉堡的有2个;本身不是汉堡,又被正确识别为不是汉堡的有5个。上述得到的矩阵,即为混淆矩阵。
- 混淆矩阵是总结分类模型预测结果的分析表。
3.2.2、指定方法
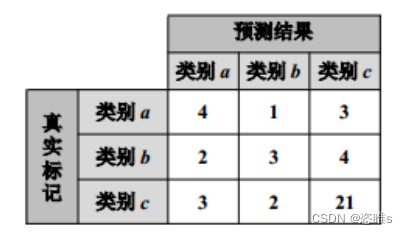
- 仍以a、b、c三类分类为例,有如下混淆矩阵:
- 在上述混淆矩阵中,虽然各类错分的样本数的绝对数值接近(均错分了3个左右的样本)。但相对而言,样本数较少的 a 和 b 类分别有(1+3)/(4+1+3)=50%和(2+4)/(2+3+4)=66.67%样本被分错,比例相当高。而对于样本数较多的 c 类,其错分概率就相对较低,为(3+2)/(3+2+21)=19.23%。
- 该情况下利用代价敏感法处理时,可根据各类错分样本数设置代价敏感矩阵的取值。
- 一种方式可直接以错分样本数为矩阵取值:

- 另一种更优方案则还需考虑各类的错分比例,并以此比例调整各类错分权重。
- 对 a 类而言,a 类错分比例为50%,占所有错分比例50% / (50%+67%+19%)=36.76%。
- 同理,b类占49.26%,c类最少,占13.97%。
- 以此为权重乘上原代价矩阵可得新的代价矩阵(已取整):

4、分类器评估
- 混淆矩阵:

- 性能评估指标:
- 误分类代价=
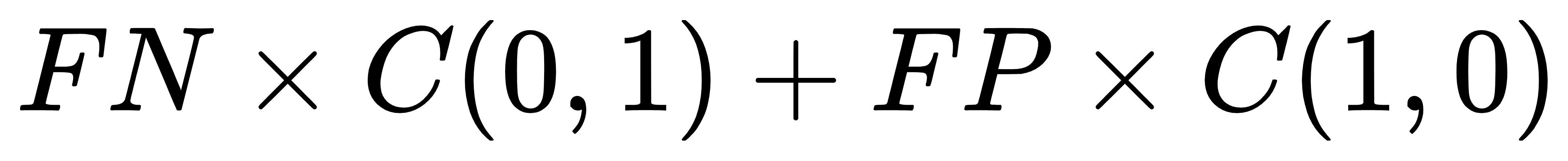 ,其中 表示第 i 类被分类到第 j 类的惩罚。
,其中 表示第 i 类被分类到第 j 类的惩罚。
- 误分类代价=