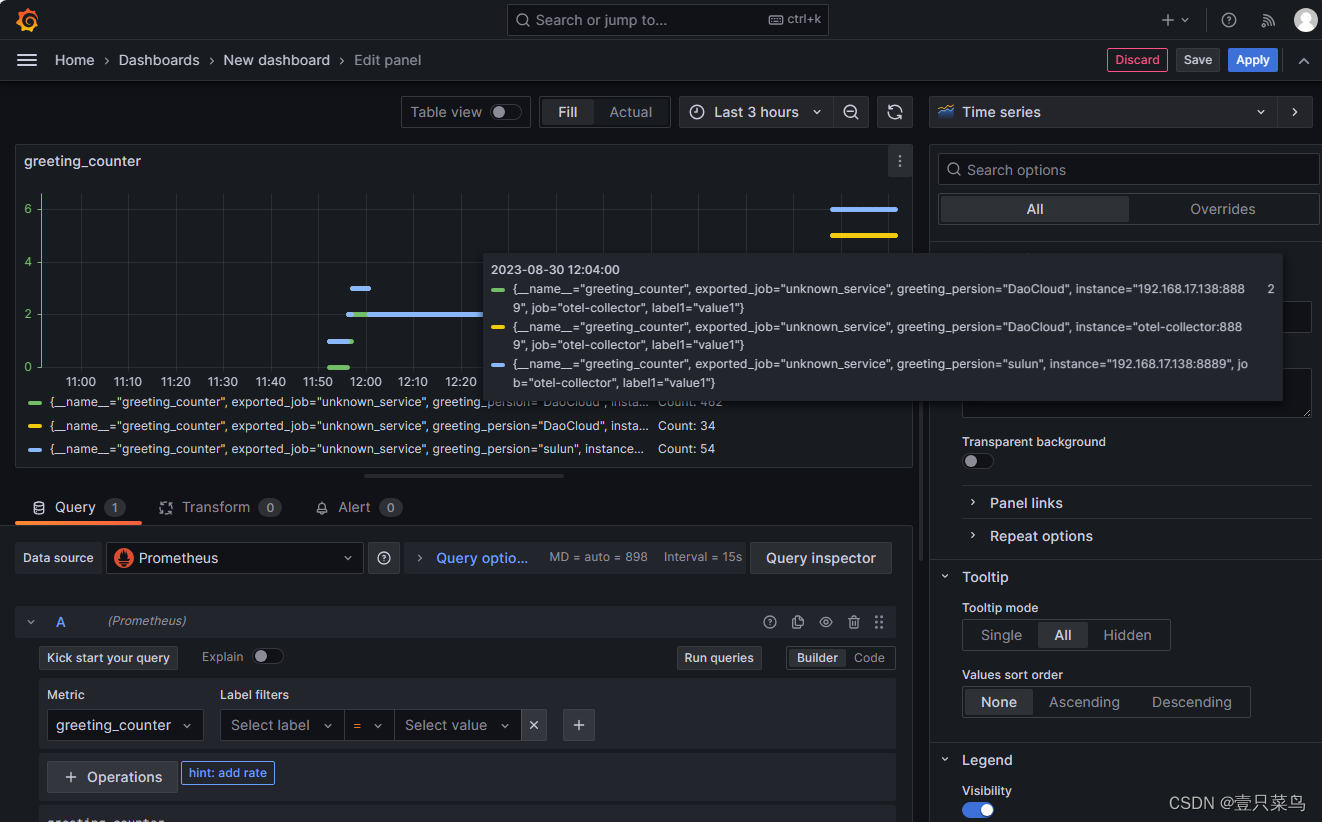
查看占用GPU资源的所属docker 进程,并杀死 docker 中的僵尸进程!
- 问题描述:
- 查看当前占用GPU资源的进程属于哪个Docker容器
- 杀死 docker 中的僵尸进程
问题描述:
- 问题1:一台服务器,每个人在上面
run一个容器,跑各自的代码,虽然通过nvidia-smi可以看到每个进程占用的 GPU,但是不好找进程对应的容器id,就没法确认到底是谁占用了较多GPU。 - 问题2:当我们在自己的
docker容器中使用GPU进行模型训练时,训练完毕后,发现GPU 仍然被占用着,这些占用GPU 的进程就是 僵尸进程,只有kill掉 这些进程,显卡资源才得到释放。
查看当前占用GPU资源的进程属于哪个Docker容器
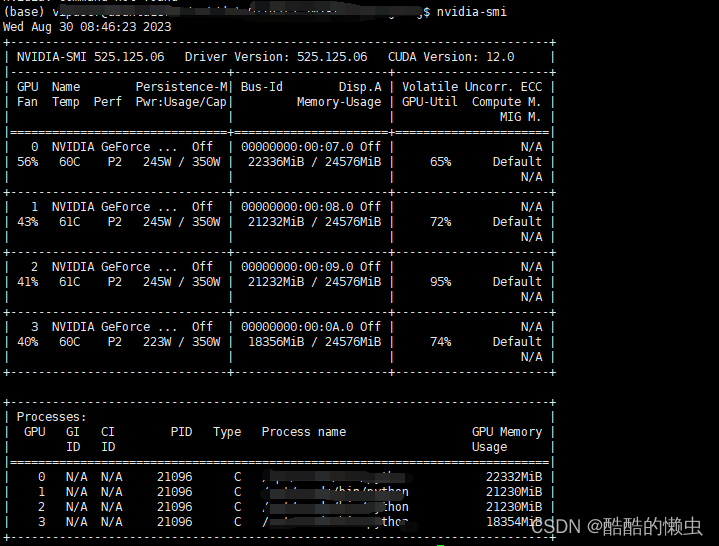
通过 nvidia-smi 查看进程占用GPU情况,但是不好找进程对应的容器id:
- 容器内部,使用
nvidia-smi命令无法看到 GPU 资源详情 nvidia-smi只能在容器外部用户下,进行查看:
通过 docker ps 查看所有运行的容器:

然后一个一个运行docker top containerId | grep PID,根据返回情况判断这个进程在哪个容器里面 ( 注 :containerId 可以是 CONTAINER ID 前四位)。
比如 docker top c34c | grep 21096 ,返回为空,说明不在这个容器里面,接着再试直到找到容器为止。

这么做实在是太麻烦了,可以把上面这个过程写成shell脚本,就看了一个 shell教程 就可以写出来。
shell脚本
#!/bin/bash
# find docker container by process id
processId=
# 提取程序的名字
PROGNAME=$(basename $0)
usage () {
echo " $PROGNAME [-p --processId] or $PROGNAME"
return
}
# 一个while case用来提取参数
while [[ -n $1 ]]; do
case $1 in
-p | --processId) shift
processId=$1
;;
-h | --help) usage
exit
;;
*) usage >&2
exit 1
;;
esac
shift
done
# 定义一个函数
findCon () {
# $1 是函数的输入
local pId=$1
# awk '{print $1,$NF}' 打印第一列和最后一列,即容器ID和容器Name,awk 'NR != 1' 不打印第一行
# read代表读入变量
docker ps | awk '{print $1,$NF}' | awk 'NR != 1' | while read conId conName; do
# 对pId的grep使用正则表达式,不然的话如果输入进程pId为21则会匹配到21274,通过前后加入空格匹配就可以防止出现这种问题
local temp="[[:space:]]\{1\}${pId}[[:space:]]\{1\}"
if [[ -n $(docker top $conId | grep -e $temp) ]]; then
printf "%s\t\t%s\t\t%s\t\t" $pId $conId $conName
break
fi
done
return
}
# 如果 $processId不为空
if [[ -n $processId ]]; then
# 判断输入是否为数字
if [[ $processId =~ ^[0-9]+$ ]]; then
printf "conId%s\t\t\tconName%s\n" $conId $conName
findCon $processId
else
echo "Please input number"
exit 1
fi
else
num=1
printf "PID\t\tconId%s\t\t\tconName%s\t\t\tGPU Memory\n" $conId $conName
# 这一串awk操作为提取进程id和GPU使用情况,然后去掉空格,-F为设定awk分隔符,在命令行输出一边就看懂了
nvidia-smi -q 2>&1| awk '/Process ID|Used GPU Memory/' | awk '{gsub(/[[:blank:]]*/,"",$0);print $0}' | awk -F ":" '{print $NF}' | while read item; do
if [[ $(($num % 2)) != 0 ]]; then
findCon $item
else
printf "%s\n" $item
fi
num=$((num+1))
done
fi
杀死 docker 中的僵尸进程
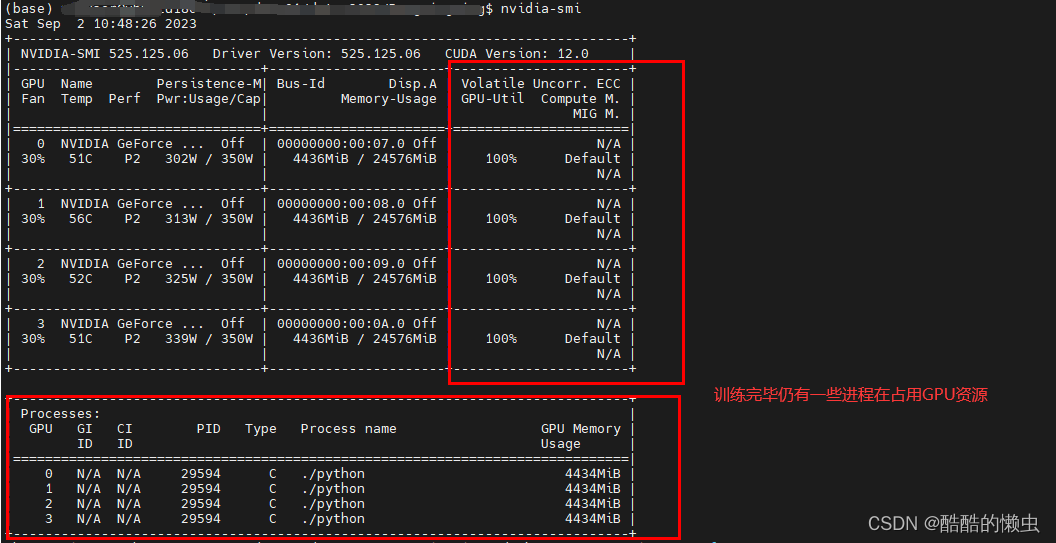
我们在自己的 docker 容器中使用GPU进行模型训练时,训练完毕后,发现GPU 仍然被占用着:
1、 先根据 进程的ID 查询其所属容器

2、使用 jobs -l 或者 ps -ef 查看改容器内的进程 ID,定位僵尸进程
# 在docker 容器外使用一下命令
docker exec 容器名/容器ID ps -ef
# docker 容器内
ps -ef

3、 杀死 父进程
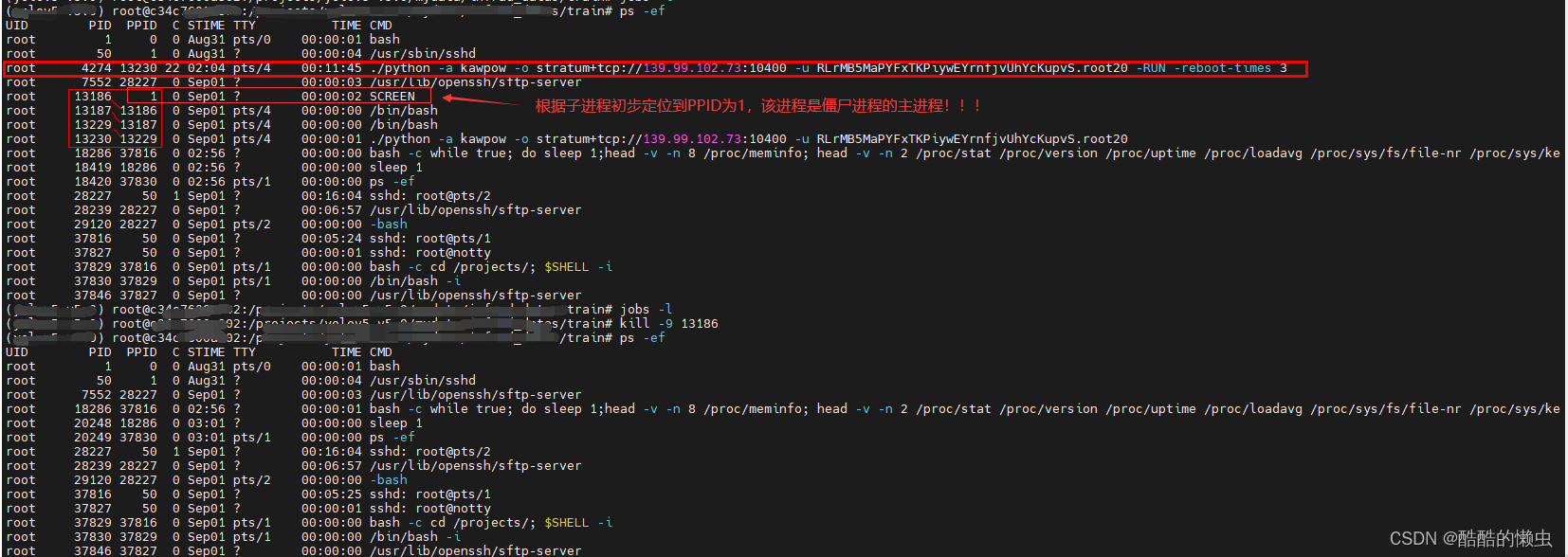
kill -9 父进程的PID
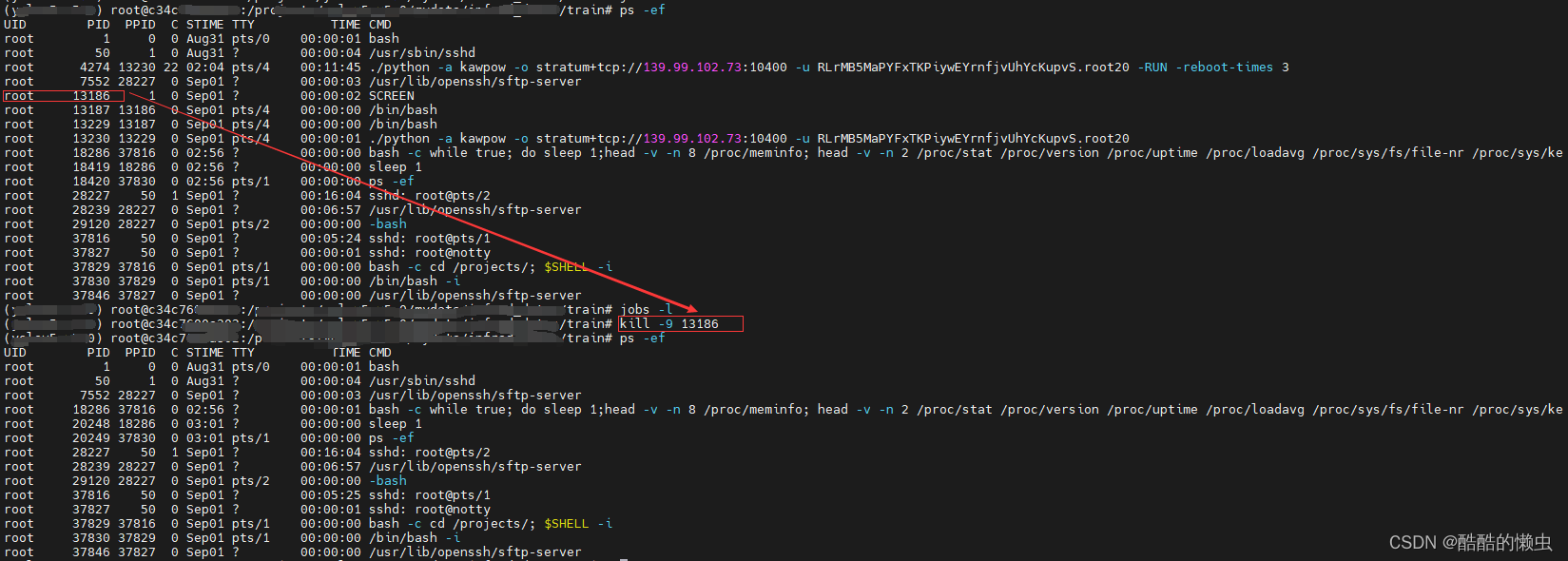
4、再查看GPU占用情况
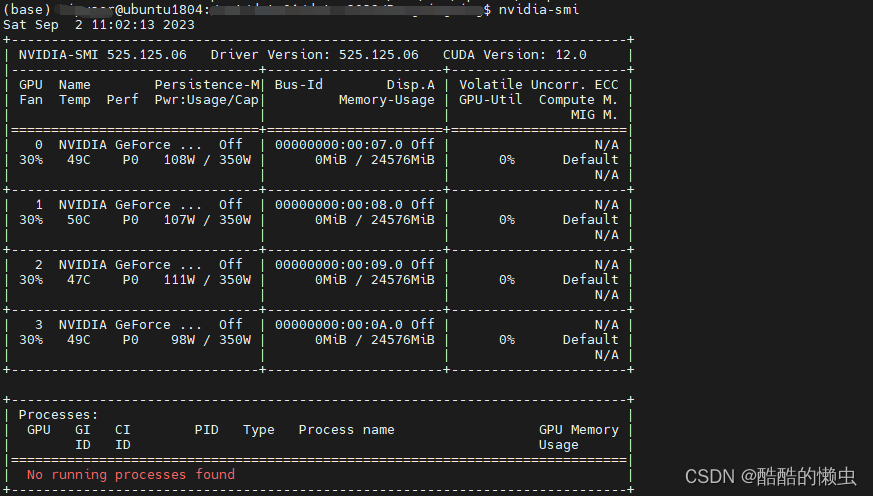
- 此时已经没有僵尸进程占用GPU!!!
注:仅供学习参考,如有不足,欢迎指正!