在运行代码的时候,需要首先指定参数,--histogram,表示使用直方图特征

1.数据集
数据集我们使用的是AIDS数据集,为内置的数据集,整个数据集大约700张图,每个图少于10个点,每个点由29维的向量组成。标签为图和图的相似度。

2.GCN图卷积特征提取
对于输入数据,一次性输入两个图,标签为两个图之间的相似度。论文中,一个batch为128个图,如果这128个图共有1158个点,则输入向量的维度为[1158,29],然后,经过三层GCN进行特征提取。提取后,特征维度变为[1158,16]。此时我们得到了图的特征表达
3.点和点之间的注意力计算
计算不同batch点的分布
to_dense_batch,将输入的特征向量转换为Batch*N*F的格式,在这个任务中,batch我们设置为128,N为各个图最大的节点数,在此任务为10个节点,F为特征数,经过GCN的提取为16.所以返回值为128*10*16,有些图可能少于10个点,用mask表示ture表示有10个点,False表示没有10个点

获得直方图特征结果
首先,我们需要根据提取到的特征向量,计算相似度评分。相似度评分用点乘表示,得到128*10*10的向量。128表示128张图,首先遍历每一张图,每张图的评分矩阵为10*10,经过sigmoid后得到最终的评分。用直方图统计出特征的分布,得到一个16维的向量,将这个向量进行归一化。此时,这个16维的向量表示两张图10个点的相似度特征。最终,所有图的相似度特征矩阵为128*16。
def calculate_histogram(
self, abstract_features_1, abstract_features_2, batch_1, batch_2
):
"""
Calculate histogram from similarity matrix.
:param abstract_features_1: Feature matrix for target graphs.
:param abstract_features_2: Feature matrix for source graphs.
:param batch_1: Batch vector for source graphs, which assigns each node to a specific example
:param batch_1: Batch vector for target graphs, which assigns each node to a specific example
:return hist: Histsogram of similarity scores.
"""
#----------------------------------------------------------------#
# to_dense_batch,将输入的特征向量转换为Batch*N*F的格式,在这个任务中,
# batch我们设置为128,N为各个图最大的节点数,在此任务为10个节点,F为特征数,
# 经过GCN的提取为16.所以返回值为128*10*16,有些图可能少于10个点,
# 用mask表示ture表示有10个点,False表示没有点的地方
#----------------------------------------------------------------#
abstract_features_1, mask_1 = to_dense_batch(abstract_features_1, batch_1)
abstract_features_2, mask_2 = to_dense_batch(abstract_features_2, batch_2)
B1, N1, _ = abstract_features_1.size()
B2, N2, _ = abstract_features_2.size()
mask_1 = mask_1.view(B1, N1)
mask_2 = mask_2.view(B2, N2)
num_nodes = torch.max(mask_1.sum(dim=1), mask_2.sum(dim=1))
# 用点乘表示得分,此时得分为128*10*10的矩阵
scores = torch.matmul(
abstract_features_1, abstract_features_2.permute([0, 2, 1])
).detach()
hist_list = []
# 最终,直方图特征结果为128*16维的向量
for i, mat in enumerate(scores):
# 用sigmoid对得分进行归一化
mat = torch.sigmoid(mat[: num_nodes[i], : num_nodes[i]]).view(-1)
# 用直方图进行统计,统计出得分的分布,得到16维的向量
hist = torch.histc(mat, bins=self.args.bins)
# 对统计结果进行归一化
hist = hist / torch.sum(hist)
hist = hist.view(1, -1)
hist_list.append(hist)
return torch.stack(hist_list).view(-1, self.args.bins)3.全局特征提取
注意力机制
首先,用图中所有点的特征的平均作为图的全局特征表示。并使用16*16的矩阵进行特征映射。将x的每个点乘以全局特征获得注意力权重(逐元素相乘*)。此时,注意力权重包含每个点对于全局特征的贡献信息。此时,将x乘以注意力权重,即完成的注意力机制加权
class AttentionModule(torch.nn.Module):
"""
SimGNN Attention Module to make a pass on graph.
"""
def __init__(self, args):
"""
:param args: Arguments object.
"""
super(AttentionModule, self).__init__()
self.args = args
self.setup_weights()
self.init_parameters()
def setup_weights(self):
"""
Defining weights.
"""
self.weight_matrix = torch.nn.Parameter(
torch.Tensor(self.args.filters_3, self.args.filters_3)
)
def init_parameters(self):
"""
Initializing weights.
"""
torch.nn.init.xavier_uniform_(self.weight_matrix)
def forward(self, x, batch, size=None):
"""
Making a forward propagation pass to create a graph level representation.
:param x: Result of the GNN.
:param size: Dimension size for scatter_
:param batch: Batch vector, which assigns each node to a specific example
:return representation: A graph level representation matrix.
"""
size = batch[-1].item() + 1 if size is None else size
# 对每个点的特征取平均值得到图的全局特征
mean = scatter_mean(x, batch, dim=0, dim_size=size)
# 将全局特征乘以16*16的权重矩阵,得到重构后的全局特征
transformed_global = torch.tanh(torch.mm(mean, self.weight_matrix))
# x上的每一个点乘以重构后的全局特征得到注意力权重,*表示逐元素相乘,表示对每个点的特征进行加权
coefs = torch.sigmoid((x * transformed_global[batch]).sum(dim=1))
# x乘以注意力权重
NTN模块
NTN模块是用来探究两个向量之间的关系的,具体做法是,首先使用一组权重对向量1进行重构。本代码权重矩阵的维度为128*16*16,意思是在18个不同的维度评估两个向量之间的关系。重构后向量1的特征向量的维度为128,16,16。即蕴含了18种不同角度的特征向量。然后用这16种不同角度的特征向量分别于向量2做点积注意力,即计算向量的余弦相似度。此时,我们得到了16种关于向量1和向量2的关系的向量。(向量1和向量2在本算法中分别代表两个图的特征)
将两个图的全局特征向量进行拼接,并通过线性层进行特征映射,加入关系向量和偏置项。
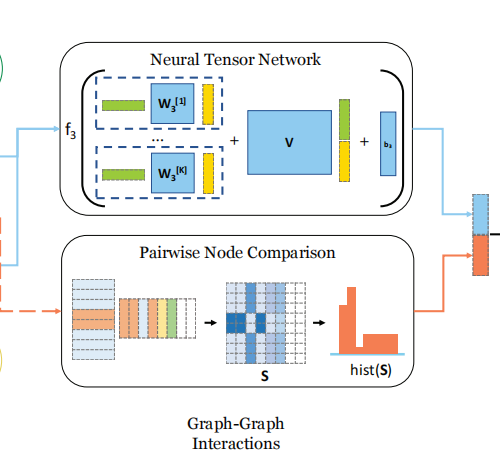
class TensorNetworkModule(torch.nn.Module):
"""
SimGNN Tensor Network module to calculate similarity vector.
"""
def __init__(self, args):
"""
:param args: Arguments object.
"""
super(TensorNetworkModule, self).__init__()
self.args = args
self.setup_weights()
self.init_parameters()
def setup_weights(self):
"""
Defining weights.
"""
self.weight_matrix = torch.nn.Parameter(
torch.Tensor(
self.args.filters_3, self.args.filters_3, self.args.tensor_neurons
)
)
self.weight_matrix_block = torch.nn.Parameter(
torch.Tensor(self.args.tensor_neurons, 2 * self.args.filters_3)
)
self.bias = torch.nn.Parameter(torch.Tensor(self.args.tensor_neurons, 1))
def init_parameters(self):
"""
Initializing weights.
"""
torch.nn.init.xavier_uniform_(self.weight_matrix)
torch.nn.init.xavier_uniform_(self.weight_matrix_block)
torch.nn.init.xavier_uniform_(self.bias)
def forward(self, embedding_1, embedding_2):
"""
Making a forward propagation pass to create a similarity vector.
:param embedding_1: Result of the 1st embedding after attention.
:param embedding_2: Result of the 2nd embedding after attention.
:return scores: A similarity score vector.
"""
batch_size = len(embedding_1)
# self.weight_matrix原始输入的两个实体都是16维向量,现在用256维表示他们的某种关系
# 重构后的score维度为128*256
scoring = torch.matmul(
embedding_1, self.weight_matrix.view(self.args.filters_3, -1)
)
# 128,16,16,第二个维度16可以理解为两个向量有16种不同的关系
scoring = scoring.view(batch_size, self.args.filters_3, -1).permute([0, 2, 1]) #filters_3可以理解成找多少种关系
# 乘以局部特征向量,相当于16种重构的embedding_1与embedding_2计算相似度特征
scoring = torch.matmul(
scoring, embedding_2.view(batch_size, self.args.filters_3, 1)
).view(batch_size, -1)
# 拼接全局特征和局部特征
combined_representation = torch.cat((embedding_1, embedding_2), 1)
# 对拼接的特征进行特征映射
block_scoring = torch.t(
torch.mm(self.weight_matrix_block, torch.t(combined_representation))
)
# 特征融合
scores = F.relu(scoring + block_scoring + self.bias.view(-1))
return scores输出层:
最后将全局特征和局部特征进行拼接,并连接一层FC层输出结果
class SimGNN(torch.nn.Module):
"""
SimGNN: A Neural Network Approach to Fast Graph Similarity Computation
https://arxiv.org/abs/1808.05689
"""
def __init__(self, args, number_of_labels):
"""
:param args: Arguments object.
:param number_of_labels: Number of node labels.
"""
super(SimGNN, self).__init__()
self.args = args
self.number_labels = number_of_labels
self.setup_layers()
def calculate_bottleneck_features(self):
"""
Deciding the shape of the bottleneck layer.
"""
if self.args.histogram:
self.feature_count = self.args.tensor_neurons + self.args.bins
else:
self.feature_count = self.args.tensor_neurons
def setup_layers(self):
"""
Creating the layers.
"""
self.calculate_bottleneck_features()
if self.args.gnn_operator == "gcn":
self.convolution_1 = GCNConv(self.number_labels, self.args.filters_1)
self.convolution_2 = GCNConv(self.args.filters_1, self.args.filters_2)
self.convolution_3 = GCNConv(self.args.filters_2, self.args.filters_3)
elif self.args.gnn_operator == "gin":
nn1 = torch.nn.Sequential(
torch.nn.Linear(self.number_labels, self.args.filters_1),
torch.nn.ReLU(),
torch.nn.Linear(self.args.filters_1, self.args.filters_1),
torch.nn.BatchNorm1d(self.args.filters_1),
)
nn2 = torch.nn.Sequential(
torch.nn.Linear(self.args.filters_1, self.args.filters_2),
torch.nn.ReLU(),
torch.nn.Linear(self.args.filters_2, self.args.filters_2),
torch.nn.BatchNorm1d(self.args.filters_2),
)
nn3 = torch.nn.Sequential(
torch.nn.Linear(self.args.filters_2, self.args.filters_3),
torch.nn.ReLU(),
torch.nn.Linear(self.args.filters_3, self.args.filters_3),
torch.nn.BatchNorm1d(self.args.filters_3),
)
self.convolution_1 = GINConv(nn1, train_eps=True)
self.convolution_2 = GINConv(nn2, train_eps=True)
self.convolution_3 = GINConv(nn3, train_eps=True)
else:
raise NotImplementedError("Unknown GNN-Operator.")
if self.args.diffpool:
self.attention = DiffPool(self.args)
else:
self.attention = AttentionModule(self.args)
self.tensor_network = TensorNetworkModule(self.args)
self.fully_connected_first = torch.nn.Linear(
self.feature_count, self.args.bottle_neck_neurons
)
self.scoring_layer = torch.nn.Linear(self.args.bottle_neck_neurons, 1)
def calculate_histogram(
self, abstract_features_1, abstract_features_2, batch_1, batch_2
):
"""
Calculate histogram from similarity matrix.
:param abstract_features_1: Feature matrix for target graphs.
:param abstract_features_2: Feature matrix for source graphs.
:param batch_1: Batch vector for source graphs, which assigns each node to a specific example
:param batch_1: Batch vector for target graphs, which assigns each node to a specific example
:return hist: Histsogram of similarity scores.
"""
#----------------------------------------------------------------#
# to_dense_batch,将输入的特征向量转换为Batch*N*F的格式,在这个任务中,
# batch我们设置为128,N为各个图最大的节点数,在此任务为10个节点,F为特征数,
# 经过GCN的提取为16.所以返回值为128*10*16,有些图可能少于10个点,
# 用mask表示ture表示有10个点,False表示没有点的地方
#----------------------------------------------------------------#
abstract_features_1, mask_1 = to_dense_batch(abstract_features_1, batch_1)
abstract_features_2, mask_2 = to_dense_batch(abstract_features_2, batch_2)
B1, N1, _ = abstract_features_1.size()
B2, N2, _ = abstract_features_2.size()
mask_1 = mask_1.view(B1, N1)
mask_2 = mask_2.view(B2, N2)
num_nodes = torch.max(mask_1.sum(dim=1), mask_2.sum(dim=1))
# 用点乘表示得分,此时得分为128*10*10的矩阵
scores = torch.matmul(
abstract_features_1, abstract_features_2.permute([0, 2, 1])
).detach()
hist_list = []
# 最终,直方图特征结果为128*16维的向量
for i, mat in enumerate(scores):
# 用sigmoid对得分进行归一化
mat = torch.sigmoid(mat[: num_nodes[i], : num_nodes[i]]).view(-1)
# 用直方图进行统计,统计出得分的分布,得到16维的向量
hist = torch.histc(mat, bins=self.args.bins)
# 对统计结果进行归一化
hist = hist / torch.sum(hist)
hist = hist.view(1, -1)
hist_list.append(hist)
return torch.stack(hist_list).view(-1, self.args.bins)
def convolutional_pass(self, edge_index, features):
"""
Making convolutional pass.
:param edge_index: Edge indices.
:param features: Feature matrix.
:return features: Abstract feature matrix.
"""
features = self.convolution_1(features, edge_index)
features = F.relu(features)
features = F.dropout(features, p=self.args.dropout, training=self.training)
features = self.convolution_2(features, edge_index)
features = F.relu(features)
features = F.dropout(features, p=self.args.dropout, training=self.training)
features = self.convolution_3(features, edge_index)
return features
def diffpool(self, abstract_features, edge_index, batch):
"""
Making differentiable pooling.
:param abstract_features: Node feature matrix.
:param edge_index: Edge indices
:param batch: Batch vector, which assigns each node to a specific example
:return pooled_features: Graph feature matrix.
"""
x, mask = to_dense_batch(abstract_features, batch)
adj = to_dense_adj(edge_index, batch)
return self.attention(x, adj, mask)
def forward(self, data):
"""
Forward pass with graphs.
:param data: Data dictionary.
:return score: Similarity score.
"""
edge_index_1 = data["g1"].edge_index
edge_index_2 = data["g2"].edge_index
#---------------------------------------#
# 输入:两张图,一个batch有128个图,一共有
# 1168个点,每个点是29维向量,标签为这两个图之间的相似度
#----------------------------------------#
features_1 = data["g1"].x
print(features_1.shape)
features_2 = data["g2"].x
batch_1 = (
data["g1"].batch
if hasattr(data["g1"], "batch")
else torch.tensor((), dtype=torch.long).new_zeros(data["g1"].num_nodes)
)
batch_2 = (
data["g2"].batch
if hasattr(data["g2"], "batch")
else torch.tensor((), dtype=torch.long).new_zeros(data["g2"].num_nodes)
)
# 三层GCN进行特征提取
abstract_features_1 = self.convolutional_pass(edge_index_1, features_1)
abstract_features_2 = self.convolutional_pass(edge_index_2, features_2)
# 点的相似度特征,直方图特征提取
if self.args.histogram:
hist = self.calculate_histogram(
abstract_features_1, abstract_features_2, batch_1, batch_2
)
if self.args.diffpool:
pooled_features_1 = self.diffpool(
abstract_features_1, edge_index_1, batch_1
)
pooled_features_2 = self.diffpool(
abstract_features_2, edge_index_2, batch_2
)
else:
pooled_features_1 = self.attention(abstract_features_1, batch_1)
pooled_features_2 = self.attention(abstract_features_2, batch_2)
# NTN层
scores = self.tensor_network(pooled_features_1, pooled_features_2)
# 将全局特征和点和点之间的特征进行拼接
if self.args.histogram:
scores = torch.cat((scores, hist), dim=1)
# FC层
scores = F.relu(self.fully_connected_first(scores))
score = torch.sigmoid(self.scoring_layer(scores)).view(-1)
return score







![[go学习笔记.第十五章.反射,常量] 1.反射的基本介绍以及实践](https://img-blog.csdnimg.cn/45de9293f3564768b6ca6794279c3ffb.png)